数据分析:数据分析篇
文章目录
-
- 第一章 科学计算库Numpy
-
- 1.1 认识Ndarray
- 1.2 Ndarray的属性
- 1.3 Numpy中的数据类型
- 1.4 Numpy数组
-
- 1.4.1 Numpy数组的创建
- 1.4.2 Numpy数组的基本索引和切片
- 1.4.3 Numpy布尔索引
- 1.4.4 数组运算和广播机制
- 1.4.5 Numpy数组的赋值和Copy复制
- 1.4.6 Numpy数组的形状变换
- 1.4.7 Numpy数组的拼接
- 1.5 Numpy读取文件操作,数组的序列化和反序列化
- 1.6 Numpy中的聚合函数
- 第二章 数据分析处理库Pandas
-
- 2.1 pandas读取和保存excel和csv文件(以及数据结构类型)
- 2.2 序列数据的常用操作
- 2.3 数据框的常用操作
- 2.4 pandas筛选数据
- 2.5 pandas去除重复数据
- 2.6 pandas分组统计
- 2.7 pandas合并表数据
- 2.8 批量自动化读取文件
- 2.9 merge连接操作
- 2.10 pandas数据计算
- 2.11 apply实现快速变换
第一章 科学计算库Numpy
1.1 认识Ndarray
-
定义:
- Ndarray对象是用于存放同类型元素的多维数组
- 它是一系列同类型数据的集合,以0下标开始进行集合中元素的索引;
- Ndarray中的每个元素在内存中都有相同存储大小的区域
-
例子:
-
## 二维 data2 = np.array([[1, 2],[3, 4]]) data2 ## import numpy as np ## 导入numpy,给他起个别名np data = np.array([1, 2, 3, 4]) ## np.array() 创建一个Ndarray print(data) ## [1 2 3 4] type(data) ## 查看数据类型 ## numpy.ndarray ## python写法 ## 对[1, 2, 3, 4]这四个数分别加1 list_data = [1, 2, 3, 4] for i in range(len(list_data)): # list_data[i] = list_data[i] + 1 list_data[i] += 1 print(list_data) ## [2, 3, 4, 5] ## Ndarray 写法 data = np.array([1, 2, 3, 4]) data = data + 1 ## ndarray本身可以当做一个整体来计算 print(data) ## [2 3 4 5] ## 二维 data2 = np.array([[1, 2],[3, 4]]) data2 ## array([[1, 2], [3, 4]]) data2 = data2 + 1 data2 array([[2, 3], [4, 5]])
-
1.2 Ndarray的属性
-
属性及其定义:
属性 含义 Ndarray.ndim 查看ndarray的纬度 Ndarray.shape 查看ndarray的形状 Ndarray.size 查看ndarray的元素个数 Ndarray.dtype 查看ndarray的元素数据类型 Ndarray.itemsize 查看ndarray中的每个元素的字节大小 -
示例:
-
## nidim data = np.array([1, 2, 3, 4]) data2 = np.array([[1, 2, 3],[4, 5, 6]]) data3 = np.array([1, 2, 3, 4, 5, 6, 7.0]) print(data.ndim) print(data2.ndim) ## shape print(type(data.shape)) print(data.shape) print(data2.shape) print(data.shape[0]) ##一定要注意下标 print(data2.shape) print(data2.shape[0]) ## 两个一维数组 print(data2.shape[1]) ## 一个一位数组有三列 ## size print(data.size) print(data2.size) ## dtype print(data.dtype) print(data2.dtype) print(data3.dtype) ## float就是浮点数 print(data3[0]) ## 全部变成浮点数了 ## itemsize print(data3.itemsize) ## 8表示8个字节,每8位为一个字节 64/8=8 print(data2.itemsize) ## 1 2 <class 'tuple'> (4,) (2, 3) 4 (2, 3) 2 3 4 6 int32 int32 float64 1.0 8 4
-
1.3 Numpy中的数据类型
-
数据类型:
-
类型 说明 int8,uint8 有符号和无符号的8位整数 int 16,uint16 有符号和无符号的16位整数 int32,uint32 有符号和无符号的32位整数 int64,uint64 有符号和无符号的64位整数 float16 16位半精度浮点数 float32 32位半精度浮点数 float64 64位半精度浮点数 bool 存储True和False的布尔类型 string 字符串类型 -
8位 = 1字节 16位2 = 2字节 32位 = 4字节 64位 = 8字节 -
优点:
- 用合适的类型存储,可以节约内存空间
- 用尽量小的位数存储,可以加快运算速度
-
-
示例:
-
## int整型 data = np.array([1, 2, 3, 4, 5]) ## 32位4个字节 print(data.dtype) ## int32 data1 = np.array([1, 2, 3, 4, 5], dtype = np.int8) data1 ## array([1, 2, 3, 4, 5], dtype=int8) data1.dtype ## dtype('int8') data.itemsize ## 4 #4个字节 data1.itemsize ## 1 #一个字节 data2 = np.array([1, 2, 3, 4], dtype=np.int16) data2.dtype ## dtype('int16') data2.itemsize ## 2 ## float浮点数 data3 = np.array([1.0, 1.1, 1.2]) data3.dtype ## dtype('float64') data3.itemsize ## 8 data4 = np.array([1.0, 1.1, 1.2], dtype=np.float16) data4 ## array([1. , 1.1, 1.2], dtype=float16) data4.dtype ## dtype('float16') data4.itemsize ## 2 ## bool布尔值 data5 = np.array([True, False, True]) data5.dtype ## dtype('bool') data5.itemsize ## 1 ## 字符串 data6 = np.array(['a', 'b']) data6.dtype ## U1,U2,U3..这些表示unicode字符 ## dtype('
-
1.4 Numpy数组
1.4.1 Numpy数组的创建
-
函数 说明 np.array 将输入的数据(列表、元组、数组或其他序列)转化为ndarray np.asarray 将输入转换为ndarray,如果输入本身是一个ndarray就不进行复制 np.arange 类似于内置的range, 但返回的是一个ndarray而不是列表 np.ones, np.ones_like 根据指定的形状和dtype创建一个全为1的数组,ones_like以另一个数组为参数,根据形状和dtype创建一个全为1的数组 np.zeros, np.zeros_like 类似于ones和ones_like, 只不过产生的是全0的数组 np.empty, np.empty_like 创建新数组,只分配空间而不填充任何数据 np.eye, np.identity 创建一个正方的N*N单位矩阵(对角线为1,其余为0) -
示例:
-
## np.array、np.asarray import numpy as np data = np.array([1,2,3,4,5]) print(data) type(data) ## [1 2 3 4 5] numpy.ndarray data1 = np.array((1,2,3,4,5)) print(data1) type(data1) ## [1 2 3 4 5] numpy.ndarray data2 = np.asarray([1,2,3,4,5]) print(data2) type(data2) ## [1 2 3 4 5] numpy.ndarray id(data), id(data1) ## (2748573991824, 2748574043760) id(data), id(data2), id(data3) ## (2748573991824, 2748573994512, 2748573991824) #通过asarray传进来的不会创建心得数组 data3[0] = 2 data3 ## array([2, 2, 3, 4, 5]) data ## array([2, 2, 3, 4, 5]) #因为data和data3的地址一样,所以都改变数组的值 -
## np.arange data4 = np.arange(10) print(data4) type(data4) ## [0 1 2 3 4 5 6 7 8 9] numpy.ndarray -
## np.ones, np.ones_like data5 = np.ones((5,)) print(data5) data5.dtype ## [1. 1. 1. 1. 1.] dtype('float64') data6 = np.ones_like(data5) ## like就是创建一个跟传入的ndarray相同属性的ndarray print(data5) ## [1. 1. 1. 1. 1.] id(data5), id(data6) ## (2748574061552, 2748574043856) -
## np.zeros, np.zeros_like data7 = np.zeros((5,)) print(data7) data7.dtype ## [0. 0. 0. 0. 0.] dtype('float64') data8 = np.zeros((5,),dtype=np.int16) print(data8) data9 = np.zeros_like(data8) data9 ## [0 0 0 0 0] array([0, 0, 0, 0, 0], dtype=int16) -
## np.empty, np.empty_like data10 = np.empty((5,)) print(data10) data10.dtype ## [0. 0. 0. 0. 0.] dtype('float64') data11 = np.empty((5,),dtype=np.int32) ## 分配的空间不同,出现的值带有随机性 data11 ## array([-242862944, 639, 0, 0, 131074]) data12 = np.empty_like(data11) data12 ## array([-241241376, 639, 0, 0, 1]) -
## np.eye, np.identity data13 = np.eye(4) print(data13) data13.dtype ## [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] dtype('float64') data14 = np.eye(4, dtype = np.int16) data14 ## array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]], dtype=int16) data15 = np.identity(4) print(data15) data15.dtype ## [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] dtype('float64') data16 = np.identity(4, dtype = np.int32) print(data16) data16.dtype ## [[1 0 0 0] [0 1 0 0] [0 0 1 0] [0 0 0 1]] dtype('int32')
-
1.4.2 Numpy数组的基本索引和切片
-
索引示例:
-
## 索引 ## 一维数组 data1 = np.array([1,2,3,4,5]) data1[0] ## [index]进行索引 ## 1 ## 二维数组 data2 = np.array([[1,2],[2,3]]) print(data2[0][1]) data2[0,1] ## 2 2 ## 三维数组 data3 = np.array([[[1,2]],[[2,3]]]) print(data3[0][0][1]) data3[0,0,1] ## 2 2
-
-
切片示例:
-
## 切片 data1 = np.array([1,2,3,4,5]) data1[0:3] ## array([1, 2, 3]) data1[:4] ## array([1, 2, 3, 4]) # 一位数组取出奇数位的数据 data1[::2] ## start_index:end_index:step 从头到尾,步长 array([1, 3, 5]) data4 = np.arange(10) data4[::2] ## array([0, 2, 4, 6, 8]) data4[1::2] ## 取出偶数位的数据 ## array([1, 3, 5, 7, 9]) -
## 操作数据 data4 = np.arange(10) data5 = data4[::2] + 1 data5 ## array([1, 3, 5, 7, 9]) data6 = np.array([[1,2,3],[4,5,6]]) data6.shape ## (2, 3) data6[:,:] ## array([[1, 2, 3], [4, 5, 6]]) data6[:,:2] ## array([[1, 2], [4, 5]]) data6[:1,:1] ## array([[1]]) data7 = np.array([[[1,2],[3,4]]]) data7.shape ## (1, 2, 2) data7[:,:,:1] ## 只保留第三维度的第一列 ## array([[[1], [3]]])
-
1.4.3 Numpy布尔索引
-
示例:
-
# 每个学生对应的成绩,身高,将他们一一索引出来 names = np.array(['小明','小红','小王','小张']) names ## array(['小明', '小红', '小王', '小张'], dtype=' -
# 从一堆数字里面取出负数,并将它们变为0 nums = np.array([[1,2,3,-4],[2,-3,4,5],[3,-4,5,6],[4,5,-6,7]]) nums.shape print(nums) ## [[ 1 2 3 -4] [ 2 -3 4 5] [ 3 -4 5 6] [ 4 5 -6 7]] c = nums < 0 c ## array([[False, False, False, True], [False, True, False, False], [False, True, False, False], [False, False, True, False]]) nums[c] ## array([-4, -3, -4, -6]) nums[c] = 0 nums ## array([[1, 2, 3, 0], [2, 0, 4, 5], [3, 0, 5, 6], [4, 5, 0, 7]]) nums2 = np.array([[1,2,3,-4],[2,-3,4,5],[3,-4,5,6],[4,5,-6,7]]) nums2 ## array([[ 1, 2, 3, -4], [ 2, -3, 4, 5], [ 3, -4, 5, 6], [ 4, 5, -6, 7]]) nums2[nums2<0] = 0 ## 只需要一条语句就搞定了 nums2 ## array([[1, 2, 3, 0], [2, 0, 4, 5], [3, 0, 5, 6], [4, 5, 0, 7]])
-
1.4.4 数组运算和广播机制
-
示例:
-
# 一维数组 data = np.array([1,2,3,4,5]) data ## array([1, 2, 3, 4, 5]) data1 = data + 5 data1 ## array([ 6, 7, 8, 9, 10]) data3 = data * 5 print(data3.dtype) data3 ## int32 array([ 5, 10, 15, 20, 25]) data4 = data * 4.0 print(data4.dtype) data4 ## float64 array([ 4., 8., 12., 16., 20.]) data5 = data / 10 print(data5.dtype) data5 ## float64 array([0.1, 0.2, 0.3, 0.4, 0.5]) data6 = data * np.array([1.0,2.0,3.0,4.0,5.0]) data6 ## array([ 1., 4., 9., 16., 25.]) -
# 二维数组 data = np.array([[1,2],[3,4]]) print(data.shape) data ## (2, 2) array([[1, 2], [3, 4]]) data1 = data + 8 data1 ## array([[ 9, 10], [11, 12]]) data2 = data + np.array([1,2]) data2 ## array([[2, 4], [4, 6]]) data3 = data + np.array([[1,2],[1,2]]) data3 ## array([[2, 4], [4, 6]]) data4 = data * np.array([0.1,0.2]) data4 ## array([[0.1, 0.4], [0.3, 0.8]])
-
1.4.5 Numpy数组的赋值和Copy复制
-
data = np.array([1,2,3,4,5,6]) data ## array([1, 2, 3, 4, 5, 6]) data1 = data ##赋值 data1 ## array([1, 2, 3, 4, 5, 6]) id(data), id(data1) ## id相同,则里面的东西一样 ## (2748591002512, 2748591002512) data[0] = 7 data[2] = 10 data ## 单纯的赋值,两个ndarray都会同时改变 ## array([ 7, 2, 10, 4, 5, 6]) data1 ## array([ 7, 2, 10, 4, 5, 6]) ## 只改变data2 保证data不变 data2 = data.copy() ## copy函数,会复制一个副本 data2 ## array([ 7, 2, 10, 4, 5, 6]) data2[3] = 15 data2 ## array([ 7, 2, 10, 15, 5, 6]) data ## array([ 7, 2, 10, 4, 5, 6]) id(data), id(data2) ## (2748591002512, 2748590984528) # 二维数组 data = np.array([[1,2,3],[4,5,6]]) data ## array([[1, 2, 3], [4, 5, 6]]) data2 = data[:1,:2] data2 ## array([[1, 2]]) data2[0, 0] = 2 data2 ## array([[2, 2]]) data ## data2改变,data也跟着改变 ## array([[2, 2, 3], [4, 5, 6]]) data3 = [1, 2, 3, 4, 5] data4 = data3[:3] ### Python列表的截取操作只是一个副本 data4 ## [1, 2, 3] data4[0] = 10 data4 ## [10, 2, 3] data3 ## 对列表,没有影响 ## [1, 2, 3, 4, 5] data5 = np.array([[1,2,3],[4,5,6]]) data5 ## array([[1, 2, 3], [4, 5, 6]]) data6 = data5[:1,:2].copy() ## 加了copy函数 data6 ## array([[1, 2]]) data6[0] = 2 data6 ## array([[2, 2]]) data5 ## 保持不变,无影响 ## array([[1, 2, 3], [4, 5, 6]])
1.4.6 Numpy数组的形状变换
-
data = np.arange(20) data = np.arange(20) data ## array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,17, 18, 19]) data1 = data.reshape((2, 10)) ## 二维数组 data1 ## array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]]) data2 = data.reshape((2,2,5)) ## 三维数组 data2 ## array([[[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9]], [[10, 11, 12, 13, 14], [15, 16, 17, 18, 19]]]) data2.shape ## (2, 2, 5) data3 = data.reshape(2,1,10) ## reshape指定参数shape绝对不能改变ndarray的元素个数 2 * 1* 10 =20 data3 ## array([[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]], [[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]]]) data1.revel() ## 会把reshape之后的数组变为原来的数组 data1 # array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])
1.4.7 Numpy数组的拼接
-
# np.concatenate([a,b,c,..],axis=0) # data1 = np.arange(5) data1 ## array([0, 1, 2, 3, 4]) data2 = np.arange(10) data2 ## array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) data3 = np.concatenate([data1,data2]) data3 ## array([0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) data4 = np.concatenate([data1,data2],axis=0) ## 一位数组axis=0,沿水平方向拼接 # axis的取值不能大于他的纬度 data4 ## array([0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) data5 = np.arange(8).reshape((4,2)) data5 ## array([[0, 1], [2, 3], [4, 5], [6, 7]]) data6 = np.arange(6).reshape((3,2)) data6 ## array([[0, 1], [2, 3], [4, 5]]) data7 = np.concatenate([data5,data6], axis=0) ## 二维数组axis=0沿竖直方向拼接 data7 ## array([[0, 1], [2, 3], [4, 5], [6, 7], [0, 1], [2, 3], [4, 5]]) data8 = np.arange(8).reshape((4,2)) data8 ## array([[0, 1], [2, 3], [4, 5], [6, 7]]) data9 = np.arange(12).reshape((4,3)) data9 ## array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) data10 = np.concatenate([data8,data9],axis=1) ## 二维数组axis=1沿水平方向拼接 data10 ## array([[ 0, 1, 0, 1, 2], [ 2, 3, 3, 4, 5], [ 4, 5, 6, 7, 8], [ 6, 7, 9, 10, 11]])
1.5 Numpy读取文件操作,数组的序列化和反序列化
-
读取文件操作:
-
## 文件读取 # 在jupyter notebook中新建 scores.csv 文件 # 添加以下内容: 数学,语文,英语 90,86,84 80,76,74 89,72,88 67,65,68 91,86,89 87,85,83 69,70,82 77,78,86 72,71,78 # 并保存 import numpy as np data1 = np.genfromtxt("scores.csv", delimiter=",", skip_header=1, dtype=np.int64, encoding="utf-8") ## 接口的默认分隔符是空格 # 可以读取缺失值 # 注意读取文件的路径 # skip_header=1表示跳过第一行不读取 # dtype=np.int64 将数据类型转换为整型 data2 = np.loadtxt("scores.csv", delimiter=",", skiprows=1, dtype=np.int64, encoding="utf-8") # 不可以读取缺失值 data1 ## array([[90, 86, 84], [80, 76, 74], [89, 72, 88], [67, 65, 68], [91, 86, 89], [87, 85, 83], [69, 70, 82], [77, 78, 86], [72, 71, 78]], dtype=int64) data2 ## array([[90, 86, 84], [80, 76, 74], [89, 72, 88], [67, 65, 68], [91, 86, 89], [87, 85, 83], [69, 70, 82], [77, 78, 86], [72, 71, 78]], dtype=int64) data1.dtype ## dtype('int64') data1 = data1.astype(np.int64) ## astype类型转换的接口 # 即对数据类型进行转变 # 文件保存 data1.shape ## (9, 3) data3 = data1[:3] ## array([[90, 86, 84], [80, 76, 74], [89, 72, 88], [67, 65, 68]], dtype=int64) np.savetxt("tmp.csv", data3, fmt="%.3f") ## %.3f就是保存三位小数 np.savetxt("tmp.csv", data3, fmt="%d", delimiter=",", header="数学,语文,英语", encoding="utf-8", comments="") ##%d代表保存整数 # comments默认是#号 # header是表头
-
-
序列化和反序列化:
-
data = np.array([[1,2,3],[4,5,6]]) data ## array([[1, 2, 3], [4, 5, 6]]) # 序列化存储 np.save("data.npy", data) ## 二进制文件 ## 反序列化读取 data1 = np.load("data.npy") data1 ## array([[1, 2, 3], [4, 5, 6]]) list_data = ["张三", '张三', '王五'] list_data ## ['张三', '张三', '王五'] np.save("list_data.npy",list_data) names = np.load("list_data.npy") print(type(names)) names ## <class 'numpy.ndarray'> array(['张三', '张三', '王五'], dtype='
-
1.6 Numpy中的聚合函数
-
常见的聚合函数
-
函数 说明 np.min 计算数组的最小值 np.max 计算数组的最大值 np.sum 计算数组的总和 np.mean 计算数组的平均值 np.std 计算数组的方差 np.argmax 计算出现最大值的下标 np.argmin 计算出现最小值的下标
-
-
示例:
-
import numpy as np data = np.arange(10) data ## array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) np.min(data) ## 0 np.max(data) ## 9 np.sum(data) ## 45 np.mean(data) ## 4.5 np.std(data) ## 2.8722813232690143 np.argmax(data) ## 9 np.argmin(data) ## 0 names = ['张三', '李四', '王五'] age = np.array([25,27,22]) idx1 = np.argmax(age) idx1 ## 1 names[idx1] ## '李四' idx2 = np.argmin(age) idx2 ## 2 names[idx2] '王五'
-
-
多维数组的聚合:
-
data = np.array([1,2,3,4]) np.sum(data) ## 10 # 二维数组 data1 = np.array([[1, 2, 3],[4, 5, 6]]) data1 ## array([[1, 2, 3], [4, 5, 6]]) a = np.sum(data1, axis=0) ##沿着y轴方向聚合 a ## array([5, 7, 9]) a.shape ## (3,) b = np.sum(data1, axis=1) ##沿着x轴方向聚合 b ## array([ 6, 15]) b.shape ## (2,) data1.shape ## (2, 3) # 三维数组 data3 = np.array([[[1,2,3,4],[5,6,7,8]]]) data3.shape ## array([[[1, 2, 3, 4], [5, 6, 7, 8]]]) a = np.sum(data3, axis=0) ## 三维数组axis=0 与原数组不变 a ## array([[1, 2, 3, 4], [5, 6, 7, 8]]) a.shape ## (2, 4) b = np.sum(data3, axis=1) ## 三维数组axis=1,对应的是y轴竖着看 b ## array([[ 6, 8, 10, 12]]) b.shape ## (1, 4) c= np.sum(data3, axis=2) ## 三维数组axis=2,对应的是x轴横着看 c ## array([[10, 26]]) c.shape ## (1, 2) data1 ## array([[1, 2, 3], [4, 5, 6]]) np.argmax(data1, axis=0) ## 1的下标对应的是 4 、 5 、6 y轴竖着看 ## array([1, 1, 1], dtype=int64) np.argmax(data1, axis=1) ## 2的下标对应的是 3 、 6 x轴横着看 ## array([2, 2], dtype=int64) np.mean(data1, axis=1,dtype=np.int32) ## array([2, 5])
-
第二章 数据分析处理库Pandas
2.1 pandas读取和保存excel和csv文件(以及数据结构类型)
-
excel:
-
import pandas as pd # 读文件数据 data = pd.read_excel("data/学生信息.xlsx",sheet_name="测试") ## sheet_name指定名字叫做测试的那张表,默认读第一张工作表 # pd.read("文件路径",..) data # 导出数据 data.to_excel("数据.xlsx", index=None) ## 表示导出不需要下标
-
-
csv:
-
## 注意excel用记事本打开会乱码,而csv文件用记事本打开不会。excel可读性比csv差 import pandas as pd data = pd.read_csv("data/学生信息.csv", engine="python", encoding='gbk') ## engine=c 的时候读取csv文件会报错,要把它换成python引擎 # 注意有的编码格式是gbk而不是utf-8 data data.to_csv("保存.csv",encoding='gbk', index=None) ## 编码需要改成gbk才不会乱码,视文件编码格式为主
-
-
读写数据库(MySQL)数据:
-
SQLAlchemy连接MySQL数据库
-
from sqlalchemy import create_engin ## 创建一个mysql连接器,用户名为root,密码为1234 ## 地址为127.0.0.1,数据库名称为testdb,编码为utf-8 engine = create_engine('mysql+pymysql://root:[email protected]:3306/meal?charset=utf8') print(engine) ## Engine(mysql+pymysql://root:***@127.0.0.1:3306/meal?charset=utf8)
-
-
使用read_sql_table、read_sql_query、read_sql函数读取数据库数据
-
read_sql_table只能读取数据库的某一张表, 不能执行查询操作; read_sql_query函数只能实现查询,不能读取某张表; read_sql是上面两者的综合,既能读取某张表的数据,又能实现查询操作。 
-
import pandas as pd order1 = pd.read_sql_table("meal_order_detail1", con=engine) order1 ### meal_order_detail1是数据表,engine是连接器
-
-
数据库数据存储:
-
将DataFrame写入到数据库中,同样也要依赖SQLAlchemy库的create_engine函数创建数据库连接。
与数据库读取有3个函数不同,数据库存储只有一个to_sql方法。语法如下:
DataFrame.to_sql(name, con, schema=None, if_exists=‘fail’, index=True index_label=None, dtype=None)
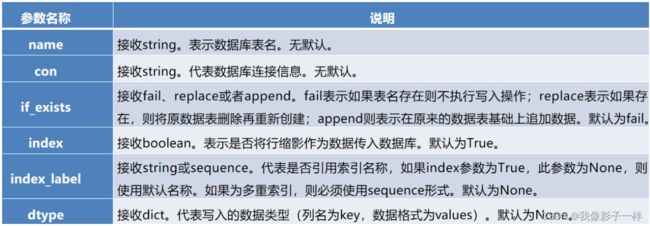
-
### 使用to_sql方法写入数据 import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:123456@localhost:3306/bd20db?charset=utf8') data = pd.read_excel("./data/student_bd20.xlsx") data.to_sql('student_bd20',if_exists='fail',index=False,con=engine)
-
-
-
数据结构类型:
-
## 接上面csv type(data) ## pandas.core.frame.DataFrame #数据框 data['班级'] ## 0 1班 1 1班 2 1班 .. .. 34 4班 Name: 班级, dtype: object type(data['班级']) ## pandas.core.series.Series # 序列数据 type(data['学号']) ## pandas.core.series.Series # 拿取多个字段需要再嵌套一个方括号 data[['班级', '学号', '体重']] type(data[['班级', '学号', '体重']]) ## pandas.core.frame.DataFrame
-
2.2 序列数据的常用操作
- 查看序列数据的数据类型:
-
data["班级"].dtype ## dtype('O') # o 表示字符串 data["学号"].dtype ## dtype('int64') data["性别"].dtype ## dtype('O')
-
查看序列数据的不同取值:
-
data["班级"].unique() ## array(['1班', '2班', '3班', '4班'], dtype=object) data["性别"].unique() ## array(['男', '女'], dtype=object)
-
-
查看序列数据的不同取值对应的数量:
-
data["性别"].value_counts() ## 女 19 男 16 Name: 性别, dtype: int64 data["班级"].value_counts() ## 1班 10 2班 10 3班 10 4班 5 Name: 班级, dtype: int64
-
-
查看序列数据的统计信息:
-
# 最大值 data["身高"].max() ## 195 # 最小值 data["身高"].min() ## 155 # 平均值 data["身高"].mean() ## 174.14285714285714 # 中位数 data["身高"].median() ## 173.0
-
-
序列数据的排序:
-
import pandas as pd data = pd.read_csv("data/学生信息.csv", engine="python", encoding='gbk') data ## 班级 学号 性别 身高 体重 0 1班 1101 男 173 63 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64 5 2班 1201 男 188 68 6 2班 1202 女 176 94 7 2班 1203 男 160 53 8 2班 1204 女 162 63 9 2班 1205 女 167 63 10 3班 1301 男 161 68 11 3班 1302 女 175 57 12 3班 1303 男 188 82 13 3班 1304 男 195 70 14 3班 1305 女 187 69 15 1班 2101 男 174 84 16 1班 2102 女 161 61 17 1班 2103 男 157 61 18 1班 2104 女 159 97 19 1班 2105 男 170 81 20 2班 2201 男 193 100 21 2班 2202 女 194 77 22 2班 2203 男 155 91 23 2班 2204 男 175 74 24 2班 2205 女 183 76 25 3班 2301 女 157 78 26 3班 2302 男 171 88 27 3班 2303 女 190 99 28 3班 2304 女 164 81 29 3班 2305 男 187 73 30 4班 2401 女 192 62 31 4班 2402 男 166 82 32 4班 2403 女 158 60 33 4班 2404 女 160 84 34 4班 2405 女 193 54 -
# 对身高进行排序,取前5条数据,默认从小到大 data["身高"].sort_values().head() # 默认前5条 ## 22 155 17 157 25 157 32 158 18 159 Name: 身高, dtype: int64 # 对身高进行排序,取前5条数据,改为从大到小 data["身高"].sort_values(ascending=False).head() ## 13 195 21 194 34 193 20 193 1 192 Name: 身高, dtype: int64
-
2.3 数据框的常用操作
-
查看数据框的前面几条数据:
-
data.head() # 默认前五条数据 #data.head(10) 前10条数据 ## 班级 学号 性别 身高 体重 0 1班 1101 男 173 63 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64
-
-
查看数据框的基本属性信息:
-
data.info() ## <class 'pandas.core.frame.DataFrame'> # 数据框 RangeIndex: 35 entries, 0 to 34 # 下标0 到 34,即35行数据 Data columns (total 5 columns): # 5列数据 # Column Non-Null Count Dtype --- ------ -------------- ----- 0 班级 35 non-null object # 字符串 1 学号 35 non-null int64 # 整数 2 性别 35 non-null object 3 身高 35 non-null int64 4 体重 35 non-null int64 dtypes: int64(3), object(2) memory usage: 1.5+ KB # 内存占用
-
-
查看数据框的统计信息:
-
data.describe() ## 学号 身高 体重 count 35.00000 35.000000 35.000000 mean 1803.00000 174.142857 74.657143 std 536.87741 13.541098 12.895377 min 1101.00000 155.000000 53.000000 25% 1204.50000 161.000000 63.000000 50% 2103.00000 173.000000 74.000000 75% 2301.50000 187.500000 82.000000 max 2405.00000 195.000000 100.000000 # count 总数 # mean 平均值 # std 方差 # min 最小值 # max 最大值 # 25% 25%中的最小的 # 50% 50%中的最小的 # 75% 50%中的最小的 ## 注意,字符串类型无统计信息
-
-
查看数据框的表头信息:
-
data.columns ## Index(['班级', '学号', '性别', '身高', '体重'], dtype='object') # 拿取第一个表头信息 data.columns[0] ## '班级' # 拿取最后一个表头信息 data.columns[-1] ## '体重' # 修改表头信息 data = data.rename(columns={"体重": "测试"}) data.head() ## 班级 学号 性别 身高 测试 # 可以发现,体重已经改为测试了 0 1班 1101 男 173 63 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64 data = data.rename(columns={"测试": "体重"}) # 改回来
-
-
数据框的排序:
-
# 取前五条数据,按指定身高进行从小到大 data.sort_values(by="身高").head() # by是指定那个字段来排序 ## 班级 学号 性别 身高 体重 22 2班 2203 男 155 91 17 1班 2103 男 157 61 25 3班 2301 女 157 78 32 4班 2403 女 158 60 18 1班 2104 女 159 97 # 取前五条数据,按多个字段进行排序 data.sort_values(by=["身高", "体重"], ascending=False).head() ## 按照身高和体重,并从大到小进行排序 ## 班级 学号 性别 身高 体重 13 3班 1304 男 195 70 21 2班 2202 女 194 77 20 2班 2201 男 193 100 34 4班 2405 女 193 54 1 1班 1102 女 192 73
-
2.4 pandas筛选数据
-
单条件筛选数据:
-
# 依旧用学生信息.csv这个表 # 取出性别为男生的前五条数据 data1 = data["性别"]=="男" data1.head() ## 0 True ## True为男生 1 False 2 True 3 False 4 False Name: 性别, dtype: bool ##返回的序列数据是布尔类型 # 用返回序列传给data,即传给数据框 data[data["性别"]=="男"].head() ## 班级 学号 性别 身高 体重 0 1班 1101 男 173 63 2 1班 1103 男 186 82 5 2班 1201 男 188 68 7 2班 1203 男 160 53 10 3班 1301 男 161 68 # 身高大于180的部分学生筛选出来 data[data["身高"]>180].head() ## 班级 学号 性别 身高 体重 1 1班 1102 女 192 73 2 1班 1103 男 186 82 5 2班 1201 男 188 68 12 3班 1303 男 188 82 13 3班 1304 男 195 70
-
-
多条件筛选数据:
-
# 性别为女生,身高大于180的 # & 两个条件都要满足 data[(data["性别"]=="女") & (data["身高"]>180)] ## 班级 学号 性别 身高 体重 1 1班 1102 女 192 73 14 3班 1305 女 187 69 21 2班 2202 女 194 77 24 2班 2205 女 183 76 27 3班 2303 女 190 99 30 4班 2401 女 192 62 34 4班 2405 女 193 54 # | 至少有一个条件成立就行 # 取前五条数据 data[(data["性别"]=="女") & (data["身高"]>180)].head() ## 班级 学号 性别 身高 体重 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64 5 2班 1201 男 188 68 # 性别为女生,身高大于180,并且为一班的 data[(data["性别"]=="女") & (data["身高"]>180) & (data["班级"]=='1班')] ## 班级 学号 性别 身高 体重 1 1班 1102 女 192 73
-
2.5 pandas去除重复数据
-
计算重复数据的数量:
-
## 所用数据data文件夹的重复数据样本.xlsx 文件 data = pd.read_excel("data/重复数据样本.xlsx") data ## 用户编号 下单日期 下单数量 0 10001 2019-10-01 10 1 10002 2019-10-04 8 2 10003 2019-09-23 15 3 10004 2019-10-12 9 4 10005 2019-10-14 20 5 10006 2019-10-15 17 6 10007 2019-08-26 19 7 10001 2019-10-01 10 8 10008 2019-09-16 6 9 10009 2019-10-08 14 10 10010 2019-10-02 7 11 10011 2019-10-03 11 12 10012 2019-10-05 12 13 10013 2019-10-06 13 14 10014 2019-10-24 23 15 10005 2019-10-14 20 16 10007 2019-08-26 19 17 10001 2019-10-01 10 18 10015 2019-08-26 15 19 10016 2019-10-07 4 -
# 计算重复数据 data.duplicated() ## 0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 True 8 False 9 False 10 False 11 False 12 False 13 False 14 False 15 True 16 True 17 True 18 False 19 False dtype: bool # 返回的序列数据是布尔类型,True出现的是重复性数据 data.duplicated().sum() ## 4 # 返回的是4,即有4条重复数据
-
-
快速去除重复数据:
-
# 去掉重复性数据 data1 = data.drop_duplicates() data1 ## 用户编号 下单日期 下单数量 0 10001 2019-10-01 10 1 10002 2019-10-04 8 2 10003 2019-09-23 15 3 10004 2019-10-12 9 4 10005 2019-10-14 20 5 10006 2019-10-15 17 6 10007 2019-08-26 19 8 10008 2019-09-16 6 9 10009 2019-10-08 14 10 10010 2019-10-02 7 11 10011 2019-10-03 11 12 10012 2019-10-05 12 13 10013 2019-10-06 13 14 10014 2019-10-24 23 18 10015 2019-08-26 15 19 10016 2019-10-07 4 # 没去除前 data.shape ## (20, 3) # 去除后 data1.shape ## (16, 3)
-
2.6 pandas分组统计
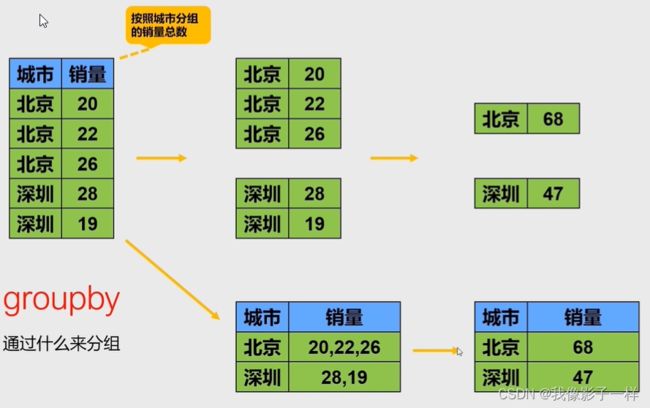
-
分组统计:
-
## data文件夹下的分组统计数据.xlsx 文件 import pandas as pd data = pd.read_excel("data/分组统计数据.xlsx") data ## 城市 订单数 销售额 0 北京 18 32000 1 北京 16 30000 2 北京 20 48000 3 北京 15 28000 4 深圳 24 40000 5 深圳 18 30000 6 深圳 14 24000 7 广州 16 26000 8 广州 14 24000 9 上海 22 46000 10 上海 18 40000 # groupby data.groupby("城市") ### 返回的是一个object对象 group = data.groupby("城市") group.groups ## {'上海': [9, 10], '北京': [0, 1, 2, 3], '广州': [7, 8], '深圳': [4, 5, 6]} #里面的数该城市所对应的下标 # 看分组之后某个组的数据 group.get_group("北京") ## 城市 订单数 销售额 0 北京 18 32000 1 北京 16 30000 2 北京 20 48000 3 北京 15 28000 group.get_group("北京")["订单数"] ## 0 18 1 16 2 20 3 15 Name: 订单数, dtype: int64 # 计算北京的总订单数 group.get_group("北京")["订单数"].sum() ## 69 # 计算所有组的总订单数 group["订单数"].sum() ## 城市 上海 40 北京 69 广州 30 深圳 56 Name: 订单数, dtype: int64 data.groupby("城市")["订单数"].sum() ## 城市 上海 40 北京 69 广州 30 深圳 56 Name: 订单数, dtype: int64 # 计算所有组的销售额 data.groupby("城市")["销售额"].sum() ## 城市 上海 86000 北京 138000 广州 50000 深圳 94000 Name: 销售额, dtype: int64
-
-
分组统计练习:
-
## data下面的 学生信息.xlsx 文件 import pandas as pd data = pd.read_excel("data/学生信息.xlsx") data ## 班级 学号 性别 身高 体重 0 1班 1101 男 173 63 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64 5 2班 1201 男 188 68 6 2班 1202 女 176 94 7 2班 1203 男 160 53 8 2班 1204 女 162 63 9 2班 1205 女 167 63 10 3班 1301 男 161 68 11 3班 1302 女 175 57 12 3班 1303 男 188 82 13 3班 1304 男 195 70 14 3班 1305 女 187 69 15 1班 2101 男 174 84 16 1班 2102 女 161 61 17 1班 2103 男 157 61 18 1班 2104 女 159 97 19 1班 2105 男 170 81 20 2班 2201 男 193 100 21 2班 2202 女 194 77 22 2班 2203 男 155 91 23 2班 2204 男 175 74 24 2班 2205 女 183 76 25 3班 2301 女 157 78 26 3班 2302 男 171 88 27 3班 2303 女 190 99 28 3班 2304 女 164 81 29 3班 2305 男 187 73 30 4班 2401 女 192 62 31 4班 2402 男 166 82 32 4班 2403 女 158 60 33 4班 2404 女 160 84 34 4班 2405 女 193 54 -
## 练习 # 1、按照班级分组,算学生的身高的统计信息 data.groupby("班级")["身高"].max().reset_index() # reset_index() 重置下标 #max() 最大值 ## 班级 身高 0 1班 192 1 2班 194 2 3班 195 3 4班 193 data.groupby("班级")["身高"].min().reset_index() # reset_index() 重置下标 ## 班级 身高 0 1班 157 1 2班 155 2 3班 157 3 4班 158 # 改变字段 a = data.groupby("班级")["身高"].max().reset_index() a.columns = ["班级","身高的最大值"] a ## 班级 身高的最大值 0 1班 192 1 2班 194 2 3班 195 3 4班 193 # 2、按班级,计算体重的统计信息 # 体重的最大值 b = data.groupby("班级")["体重"].max().reset_index() b.columns = ["班级", "体重的最大值"] b ## 班级 体重的最大值 0 1班 97 1 2班 100 2 3班 99 3 4班 84 # 3、每个班级里面男生跟女生的身高情况的统计信息(多个字段分组) # 按照班级性别分组,算出各个班男女的身高的最大值 c = data.groupby(["班级","性别"])["身高"].max().reset_index() c.columns = ["班级", "性别", "身高的最大值"] c ## 班级 性别 身高的最大值 0 1班 女 192 1 1班 男 186 2 2班 女 194 3 2班 男 193 4 3班 女 190 5 3班 男 195 6 4班 女 193 7 4班 男 166
-
2.7 pandas合并表数据
-
按行方向合并数据:
-
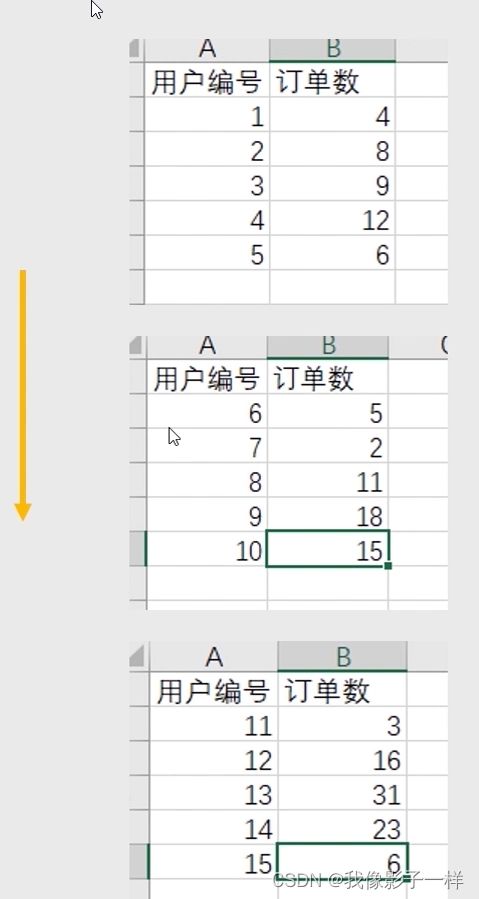
按照行方向合并,数据要具有相同的字段
-
# data文件夹下的行拼接数据文件夹下有4个xlsx文件 import pandas as pd data1 = pd.read_excel("data/行拼接数据/用户数据1.xlsx") data2 = pd.read_excel("data/行拼接数据/用户数据2.xlsx") data3 = pd.read_excel("data/行拼接数据/用户数据3.xlsx") data4 = pd.read_excel("data/行拼接数据/用户数据4.xlsx") data1 ## 用户编号 订单数 0 1 4 1 2 8 2 3 9 3 4 12 4 5 6 data2 ## 用户编号 订单数 0 6 5 1 7 2 2 8 11 3 9 18 4 10 15 data3 ## 用户编号 订单数 0 11 3 1 12 16 2 13 31 3 14 23 4 15 6 data4 ## 用户编号 订单数 0 16 6 1 17 34 2 18 9 3 19 12 4 20 6 -
## 行拼接 data = pd.concat([data1,data2,data3,data4]).reset_index() data ## 用户编号 订单数 0 1 4 1 2 8 2 3 9 3 4 12 4 5 6 0 6 5 1 7 2 2 8 11 3 9 18 4 10 15 0 11 3 1 12 16 2 13 31 3 14 23 4 15 6 0 16 6 1 17 34 2 18 9 3 19 12 4 20 6
-
-
按列方向合并数据:

按照列方向合并,数据的数量必须要相同
-
# data文件夹下的列拼接数据文件夹下有3个xlsx文件 import pandas as pd data5 = pd.read_excel("data/列拼接数据/用户信息1.xlsx") data6 = pd.read_excel("data/列拼接数据/用户信息2.xlsx") data7 = pd.read_excel("data/列拼接数据/用户信息3.xlsx") data5 ## 用户编号 用户性别 0 1 男 1 2 女 2 3 男 3 4 男 4 5 女 data6 ## 身高 0 167 1 174 2 184 3 154 4 167 data7 ## 职业 爱好 0 学生 唱歌 1 白领 旅行 2 农民 看视频 3 学生 看小说 4 学生 唱歌 -
## 列拼接 data = pd.concat([data5,data6,data7], axis=1) ## axis=1 按照列方向拼接 data ## 用户编号 用户性别 身高 职业 爱好 0 1 男 167 学生 唱歌 1 2 女 174 白领 旅行 2 3 男 184 农民 看视频 3 4 男 154 学生 看小说 4 5 女 167 学生 唱歌
-
2.8 批量自动化读取文件
-
# 在data文件夹下的合并练习数据的 文件 import pandas as pd import os ## 操作系统库 os.listdir("data/列拼接数据/") ## os.listdit() 返回该目录下的所有的数据文件的名字,并且返回的是一个列表结构 ## ['用户信息1.xlsx', '用户信息2.xlsx', '用户信息3.xlsx'] import pandas as pd import os ## 操作系统库 files = os.listdir("data/合并练习数据/") len(files) ## 1000 # 1000个文件 data_list = [] ## 定义一个列表,专门用来存放我们在for循环里面读进来的每一个数据文件 for file in files: ## file指的是每个数据文件的名字,用for循环迭代files这一千个个数据文件的名字传入file data = pd.read_excel("data/合并练习数据/" + file) # data里面现在就存放了每个数据文件读进来的那些数据 data_list.append(data) len(data_list) ## 1000 all_data1 = pd.concat(data_list) ## 按照行拼接 all_data1[["用户编号","订单数"]] # 拿多个数据记得嵌套列表 ## 用户编号 订单数 0 0 40 0 1 81 0 10 45 0 100 50 0 101 11 ... ... ... 0 995 70 0 996 60 0 997 71 0 998 84 0 999 62 1000 rows × 2 columns -
## 改进 # 1、 import pandas as pd import os data_dir = "data/合并练习数据/" files = os.listdir(data_dir) data_list = [] for file in files: ## file指的是每个数据文件的名字,用for循环迭代files这一千个个数据文件的名字传入file data = pd.read_excel("data/合并练习数据/" + file) # data里面现在就存放了每个数据文件读进来的那些数据 data_list.append(data) ## 将data的数据追加进定义好的data_list列表中 all_data = pd.concat(data_list) all_data[["用户编号", "订单数"]] ## 用户编号 订单数 0 0 40 0 1 81 0 10 45 0 100 50 0 101 11 ... ... ... 0 995 70 0 996 60 0 997 71 0 998 84 0 999 62 1000 rows × 2 columns # 2、 import pandas as pd import os data_dir = r"C:\Users\24998\数据分析\第十五章 数据分析处理库pandas\data\合并练习数据" # 在路径前面加r,即保持字符原始值的意思,否则报错 files = os.listdir(data_dir) data_list = [] for file in files: ## file指的是每个数据文件的名字,用for循环迭代files这一千个个数据文件的名字传入file data = pd.read_excel(os.path.join(data_dir, file)) # data里面现在就存放了每个数据文件读进来的那些数据 # os下的path下的join()方法,只需要传入绝对路径,和for循环遍历的文件名 # data_dir 是之前的绝对路径 data_list.append(data) ## 将data的数据追加进定义好的data_list列表中 all_data = pd.concat(data_list) all_data[["用户编号", "订单数"]] ## 用户编号 订单数 0 0 40 0 1 81 0 10 45 0 100 50 0 101 11 ... ... ... 0 995 70 0 996 60 0 997 71 0 998 84 0 999 62 1000 rows × 2 columns
2.9 merge连接操作
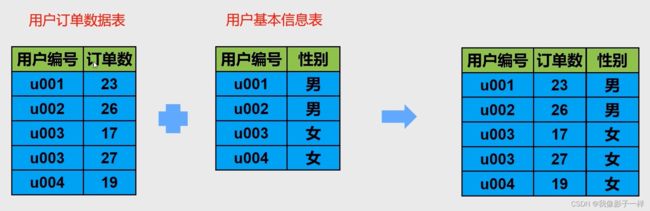
将一张数据表和另一张数据表关联起来,形成一个新的数据表
-
merge连接数据
-
# data文件夹下merge目录下的两xlsx个文件 import pandas as pd data1 = pd.read_excel("data/merge连接数据/用户订单信息.xlsx") data1 ## 用户编号 订单数 0 u001 23 1 u002 35 2 u002 24 3 u003 14 4 u004 20 5 u005 40 data2 = pd.read_excel("data/merge连接数据/用户基本属性.xlsx") data2 ## 用户编号 性别 职业 0 u001 男 学生 1 u002 女 会计师 2 u003 男 程序员 3 u004 男 学生 4 u005 女 律师 -
# 将以上两张表拼接起来(两种方法) # 1、 data = pd.merge(data1,data2,on="用户编号") # 用on连接 data ## 用户编号 订单数 性别 职业 0 u001 23 男 学生 1 u002 35 女 会计师 2 u002 24 女 会计师 3 u003 14 男 程序员 4 u004 20 男 学生 5 u005 40 女 律师 # 2、 data3 = data1.merge(data2,on="用户编号") data3 ## 用户编号 订单数 性别 职业 0 u001 23 男 学生 1 u002 35 女 会计师 2 u002 24 女 会计师 3 u003 14 男 程序员 4 u004 20 男 学生 5 u005 40 女 律师 ## 判断性别是否影响了用户下单数 data.groupby("性别")["订单数"].mean().reset_index() ## 性别 订单数 0 女 33.0 1 男 19.0
-
2.10 pandas数据计算
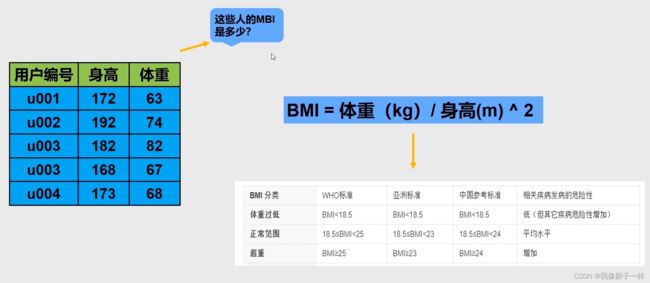
-
# data文件夹下的学生.xlsx文件 import pandas as pd data = pd.read_excel("data/学生信息.xlsx") data ## 班级 学号 性别 身高 体重 0 1班 1101 男 173 63 1 1班 1102 女 192 73 2 1班 1103 男 186 82 3 1班 1104 女 167 81 4 1班 1105 女 159 64 5 2班 1201 男 188 68 6 2班 1202 女 176 94 7 2班 1203 男 160 53 8 2班 1204 女 162 63 9 2班 1205 女 167 63 10 3班 1301 男 161 68 11 3班 1302 女 175 57 12 3班 1303 男 188 82 13 3班 1304 男 195 70 14 3班 1305 女 187 69 15 1班 2101 男 174 84 16 1班 2102 女 161 61 17 1班 2103 男 157 61 18 1班 2104 女 159 97 19 1班 2105 男 170 81 20 2班 2201 男 193 100 21 2班 2202 女 194 77 22 2班 2203 男 155 91 23 2班 2204 男 175 74 24 2班 2205 女 183 76 25 3班 2301 女 157 78 26 3班 2302 男 171 88 27 3班 2303 女 190 99 28 3班 2304 女 164 81 29 3班 2305 男 187 73 30 4班 2401 女 192 62 31 4班 2402 男 166 82 32 4班 2403 女 158 60 33 4班 2404 女 160 84 34 4班 2405 女 193 54-
# 计算学生的BMI ## 先把身高换成以米为单位 data["身高"].values #values就是序列数据的一个属性 # 返回一个array ## array([173, 192, 186, 167, 159, 188, 176, 160, 162, 167, 161, 175, 188, 195, 187, 174, 161, 157, 159, 170, 193, 194, 155, 175, 183, 157, 171, 190, 164, 187, 192, 166, 158, 160, 193], dtype=int64) type(data["身高"].values) ## numpy.ndarray # 所以pandas里面的每一列的序列数据其实就是底层封装的numpy里面的数组 # 由以上可知,我们可以直接按照numpy的计算方式 # BMI a = data["体重"] / ((data["身高"]/100) * (data["身高"]/100)) a ## 0 21.049818 1 19.802517 2 23.702162 3 29.043709 4 25.315454 5 19.239475 6 30.346074 7 20.703125 8 24.005487 9 22.589551 10 26.233556 11 18.612245 12 23.200543 13 18.408941 14 19.731762 15 27.744748 16 23.533043 17 24.747454 18 38.368735 19 28.027682 20 26.846358 21 20.459135 22 37.877211 23 24.163265 24 22.694019 25 31.644286 26 30.094730 27 27.423823 28 30.116002 29 20.875633 30 16.818576 31 29.757585 32 24.034610 33 32.812500 34 14.497033 dtype: float64 # 新增一列BMI指数,显示前五条数据 data["BMI指数"] = a data.head() ## 班级 学号 性别 身高 体重 BMI指数 0 1班 1101 男 173 63 21.049818 1 1班 1102 女 192 73 19.802517 2 1班 1103 男 186 82 23.702162 3 1班 1104 女 167 81 29.043709 4 1班 1105 女 159 64 25.315454
-
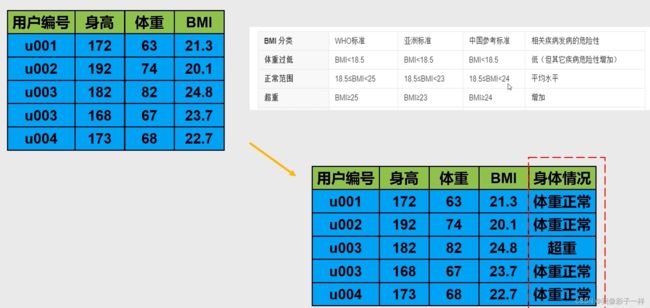
2.11 apply实现快速变换
-
一般方法(for循环)
-
# 接pandas数据计算 # 实现新增身体情况的一列,体重过低,体重正常,超重 # 一般方法 list_data = [] # 定义一个列表,存放BMI所对应的情况 for bmi in data["BMI指数"]: if bmi < 18.5: a = "体重过低" #list_data.append(a) elif bmi < 24: a = "体重正常" #list_data.append(a) else: a = "超重" #list_data.append(a) list_data.append(a) list_data ### 存放了所有人的身体情况 ## ['体重正常', '体重正常', '体重正常', '超重', '超重', '体重正常', '超重', '体重正常', '超重', '体重正常', '超重', '体重正常', '体重正常', '体重过低', '体重正常', '超重', '体重正常', '超重', '超重', '超重', '超重', '体重正常', '超重', '超重', '体重正常', '超重', '超重', '超重', '超重', '体重正常', '体重过低', '超重', '超重', '超重', '体重过低'] data["身体情况"] = list_data data.head() ## 默认显示前五条数据 ## 班级 学号 性别 身高 体重 BMI指数 身体情况 0 1班 1101 男 173 63 21.049818 体重正常 1 1班 1102 女 192 73 19.802517 体重正常 2 1班 1103 男 186 82 23.702162 体重正常 3 1班 1104 女 167 81 29.043709 超重 4 1班 1105 女 159 64 25.315454 超重
-
-
apply:
-
# apply # 相当于已经自动实现了一个for循环了 data["BMI指数"].apply(lambda x: x).head() ## apply的意思是运用,运用了什么函数。lambda x: x 函数指的是他自己,apply(lambda x: x)就是运用它本身,所以传他本身的数据 ## 0 21.049818 1 19.802517 2 23.702162 3 29.043709 4 25.315454 Name: BMI指数, dtype: float64 # 实现新增身体情况的一列,体重过低,体重正常,超重 def body(bmi): if bmi < 18.5: return "体重过低" elif bmi<24: return "体重正常" else : return "超重" b = data["BMI指数"].apply(body).head() #默认查询前五条数据 b ## 0 体重正常 1 体重正常 2 体重正常 3 超重 4 超重 Name: BMI指数, dtype: object data["身体情况_apply"] = b data.head() ## 班级 学号 性别 身高 体重 BMI指数 身体情况 身体情况_apply 0 1班 1101 男 173 63 21.049818 体重正常 体重正常 1 1班 1102 女 192 73 19.802517 体重正常 体重正常 2 1班 1103 男 186 82 23.702162 体重正常 体重正常 3 1班 1104 女 167 81 29.043709 超重 超重 4 1班 1105 女 159 64 25.315454 超重 超重 -
#用apply将男生变成1,女生变成2 def sex(x): if x == "男": return 1 elif x == "女": return 2 c = data["性别"].apply(sex) c.head() ## 0 1 1 2 2 1 3 2 4 2 Name: 性别, dtype: int64 data["新增列性别"] = c data.head() ## 班级 学号 性别 身高 体重 BMI指数 身体情况 身体情况_apply 新增列性别 0 1班 1101 男 173 63 21.049818 体重正常 体重正常 1 1 1班 1102 女 192 73 19.802517 体重正常 体重正常 2 2 1班 1103 男 186 82 23.702162 体重正常 体重正常 1 3 1班 1104 女 167 81 29.043709 超重 超重 2 4 1班 1105 女 159 64 25.315454 超重 超重 2 # lambda函数也可以实现 data["性别"].apply(lambda x: 1 if x == "男" else 2).head() ## 0 1 1 2 2 1 3 2 4 2 Name: 性别, dtype: int64
-