小白Python爬虫入门实例1——爬取中国最好大学排名
中国大学慕课python网络爬虫与信息提取——定向爬虫“中国最好大学排名信息爬取”
由于课程中老师给的案例有些许瑕疵,加之至今该网页的首页已经更新,原网址已不存在,因此笔者在老师给的代码基础上进行一些更改。
目录
一、慕课函数及实现展示
二、源代码更新
1、首先是对课程中源代码的执行结果进行分析:
2、网址更新:
3、新的网页源代码分析:
4、更新后的源代码:
三、声明
一、慕课函数及实现展示
所爬取网页的部分代码
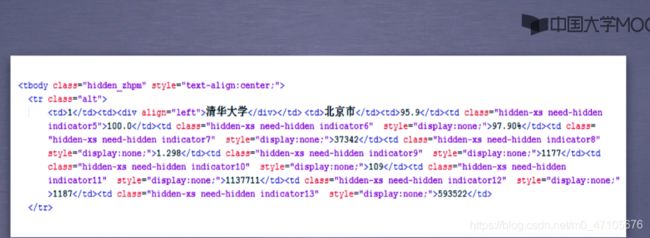
慕课课程上老师给出的源代码
import bs4
from bs4 import BeautifulSoup
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.encoding = r.apparent_encoding
r.raise_for_status()
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])
def printUnivList(ulist,num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校","分数"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uninfo = []
url = 'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uninfo,html)
printUnivList(uninfo,20) #20 univs
main()
老师的运行结果

二、源代码更新
1、首先是对课程中源代码的执行结果进行分析:
根据老师的执行结果来看,总分对应的并不是分数,而是地点,说明老师取到的数据没有对应。根据原网址提供的网页代码我们可以看出,在清华大学所在的“tr”标签中,第一个“td”包含的是大学排名;第二个“td”中包含的是大学名称的信息;第三个“td”中包含的是地点信息;第四个“td”中才是分数信息。
我们再来看老师的代码:此时老师将tds[2]加入到列表中,此处的‘tds[2]’取到的正式“tr”标签中的第三个“td”的信息,因此,此处应该将"tds[2]"改为“tds[3]”才对。
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])2、网址更新:
其次,因为网址的更新,代码中url的网址应该更改为“https://www.shanghairanking.cn/rankings/bcur/2021”
最后的数字“2021”代表的是年份,可按需更改,网址页面如下: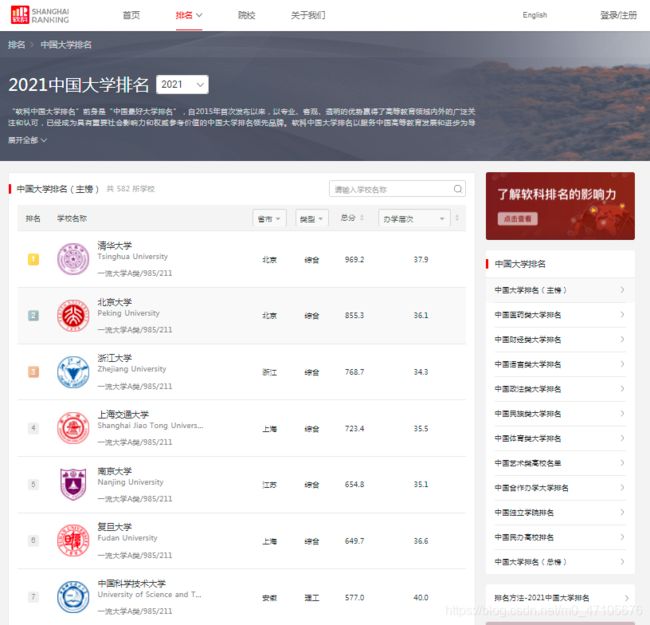
3、新的网页源代码分析:
对网页进行元素检查,可以发现,我们所需要爬取的学校信息依旧是存放在一个“tbody”标签下

每一个“tr”标签包含一所学校的信息,其中我们需要爬取的内容有:第一个“td”标签是学校排名,第二个“td”标签中包含的学校信息,以及第倒数第二个“td”标签所包含的总分信息。

4、更新后的源代码:
import bs4
from bs4 import BeautifulSoup
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.encoding = r.apparent_encoding
r.raise_for_status()
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td') #将tr中的td以列表的形式保存在tds中
a = tr('a') #第二个td标签中的学校名称信息包含在第一个a标签中,此步是为了把所有a标签存放在一个列表中
ulist.append([tds[0].string,a[0].string,tds[4].string])#选取tr中的第一个td作为排名,第一个a作为学校名称,第5个td作为总分。
def printUnivList(ulist,num):
print("{:^10}\t{:^10}\t{:^30}".format("排名","学校","分数"))
for i in range(num):
u = ulist[i]
print(("{:^10}\t{:^10}\t{:^25}".format(u[0].split()[0],u[1].split()[0],u[2].split()[0])))#split()函数是为了将取到值的空格去除,不然输出的结果没有对齐,不够美观
def main():
uninfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
html = getHTMLText(url)
fillUnivList(uninfo,html)
printUnivList(uninfo,20) #20 univs
main()三、声明
本人是学习python爬虫路上的一名小白,如有不当之处(轻喷,小白需要鼓励),欢迎大佬们批评指正。
(ps:爬虫过程中需要先查看该网站是否允许爬虫访问相关内容,具体查询方法为浏览器中输入“网址/robots.txt”)