Scrapy爬取B站小姐姐入门教程,结果万万没想到!
scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
它的作用有下:
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
scrapy框架的传送门:https://scrapy.orgscrapy框架运行原理
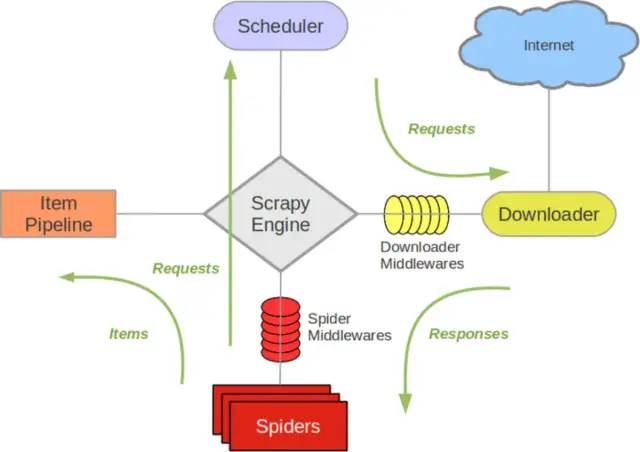

Scrapy Engine(引擎):负者Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据转递等。
Scheduler(调度器) :它负责接受引擊发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader (下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎) ,由引擎交给Spider来处理。
Spider (爬虫) :它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道) :它负责处理Spider 中获取到的Item ,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares (下载中间件) : 你可以当作是一个可以自定义扩 展下载功能的组件。
Spider Middlewares (Spider中间件) : 你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests )
不知道大家是否还记得,在我们平时写爬虫的时候一般都是划分三个函数。
# 获取网页信息
def get_html():
pass
# 解析网页
def parse_html():
pass
# 保存数据
def save_data():
pass
这三个函数基本上没有说谁调用谁的这种说法,最后只能通过主函数来将这些函数调用起来。
很显然,我们的scrapy框架也正是这样的原理,只不过它是把这三部分的功能保存在不同的文件之中,通过scrapy引擎来调用它们。

当我们使用scrapy写好代码并运行的时候就会出现如下的对话。
引擎:兄弟萌,辣么无聊,爬虫搞起来啊!
Spider:好啊,老哥,早就想搞了,今天就爬xxx网站好不好?
引擎:没有问题,入口URL发过来!
Spider:呐,入口的URL是:https://www.xxx.com
引擎:调度器老弟,我这有requests请求你帮我排序入队一下吧。
调度器:引擎老哥,这是我处理好的requests
引擎:下载器老弟,你按照下载中间件的设置帮我下载一下这个requests请求
下载器:可以了,这是下载好的内容。(如果失败:sorry,这个requests下载失败了,然后引擎告诉调度器,这个requests下载失败了,你记录一下,我们待会儿再下载)
引擎:爬虫老弟,这是下载好的东西,下载器已经按照下载中间件处理过了,你自己处理一下吧。
Spider:引擎老哥,我的数据已经处理完毕了,这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的item数据。
引擎:管道老弟,我这有个item,你帮我处理一下。
引擎:调度器老弟,这是需要跟进的URL你帮我处理一下。(然后从第四步开始循环,直到获取完全部信息)
制作 Scrapy 爬虫 一共需要4步:

新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
辣么今天我们就以B站小姐姐为例,带大家亲自体验一下scrapy的强大之处!
首先我们来看看scrapy的常用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
scrapy genspider 爬虫名 域名 # 在项目下创建一个爬虫spider类
scrapy runspider 爬虫文件 #运行一个爬虫spider类
scrapy list # 查看当前项目有多少个爬虫
scrapy crawl 爬虫名称 # 通过名称指定运行爬取信息
scrapy shell url/文件名 # 使用shell进入scrapy交互环境
1.第一步我们创建一个scrapy工程, 进入到你指定的目录下,使用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程

此时可以看到该目录下多了一个叫BliBli的文件夹.

2. 当我们创建完项目之后,它会有提示,那么我们就按照它的提示继续操作。
You can start your first spider with:
cd BliBli
scrapy genspider example example.com
当你按照上面的操作,之后你就会发现,在spiders文件夹下就会出现spider_bl.py这个文件。这个就是我们的爬虫文件。
后面的 https://search.bilibili.com/ 就是我们要爬取的目标网站

BliBli
|—— BliBli
| |—— __init__.py
| |—— __pycache__.
| |—— items.py # Item定义,定义抓取的数据结构
| |—— middlewares.py # 定义Spider和Dowmloader和Middlewares中间件实现
| |—— pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
| |—— settings.py # 它定义项目的全局配置
| |__ spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
|—— __init__.py
|—— spider_bl.py # 爬虫实现
|—— __pycache__
|—— scrapy.cfg # scrapy部署时的配置文件,定义了配置文件的路径、部署相关的信息内容。
3.接下来我们打开B站搜索 '小姐姐'如下,作为入门级crapy教程.我们今天的任务很简单,爬取视频链接,标题还有up主即可.

4. 设置item模板,定义我们要获取的信息. 就跟java中定义的model类一样.
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BlibliItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 视频标题
url = scrapy.Field() # 视频链接
author = scrapy.Field() # 视频up主
5. 然后我们在我们创建的spider_bl.py文件中写我们爬虫函数的具体实现.
import scrapy
from BliBli.items import BlibliItem
class SpiderBlSpider(scrapy.Spider):
name = 'spider_bl'
allowed_domains = ['https://search.bilibili.com']
start_urls = ['https://search.bilibili.com/all?keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&from_source=web_search']
# 定义爬虫方法
def parse(self, response):
# 实例化item对象
item = BlibliItem()
lis = response.xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li')
for items in lis:
item['title'] = items.xpath('./a/@title').get()
item['url'] = items.xpath('./a/@href').get()
item['author'] = items.xpath('./div/div[3]/span[4]/a/text()').get()
yield item
6.我们现在pipeline中打印一下,没问题我们再将其保存到本地.
scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
它的作用有下:
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
scrapy框架的传送门:https://scrapy.orgscrapy框架运行原理

Scrapy Engine(引擎):负者Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据转递等。
Scheduler(调度器) :它负责接受引擊发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader (下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎) ,由引擎交给Spider来处理。
Spider (爬虫) :它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道) :它负责处理Spider 中获取到的Item ,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares (下载中间件) : 你可以当作是一个可以自定义扩 展下载功能的组件。
Spider Middlewares (Spider中间件) : 你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests )
不知道大家是否还记得,在我们平时写爬虫的时候一般都是划分三个函数。
# 获取网页信息
def get_html():
pass
# 解析网页
def parse_html():
pass
# 保存数据
def save_data():
pass
这三个函数基本上没有说谁调用谁的这种说法,最后只能通过主函数来将这些函数调用起来。
很显然,我们的scrapy框架也正是这样的原理,只不过它是把这三部分的功能保存在不同的文件之中,通过scrapy引擎来调用它们。
当我们使用scrapy写好代码并运行的时候就会出现如下的对话。
引擎:兄弟萌,辣么无聊,爬虫搞起来啊!
Spider:好啊,老哥,早就想搞了,今天就爬xxx网站好不好?
引擎:没有问题,入口URL发过来!
Spider:呐,入口的URL是:https://www.xxx.com
引擎:调度器老弟,我这有requests请求你帮我排序入队一下吧。
调度器:引擎老哥,这是我处理好的requests
引擎:下载器老弟,你按照下载中间件的设置帮我下载一下这个requests请求
下载器:可以了,这是下载好的内容。(如果失败:sorry,这个requests下载失败了,然后引擎告诉调度器,这个requests下载失败了,你记录一下,我们待会儿再下载)
引擎:爬虫老弟,这是下载好的东西,下载器已经按照下载中间件处理过了,你自己处理一下吧。
Spider:引擎老哥,我的数据已经处理完毕了,这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的item数据。
引擎:管道老弟,我这有个item,你帮我处理一下。
引擎:调度器老弟,这是需要跟进的URL你帮我处理一下。(然后从第四步开始循环,直到获取完全部信息)
制作 Scrapy 爬虫 一共需要4步:

新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容

辣么今天我们就以B站小姐姐为例,带大家亲自体验一下scrapy的强大之处!
首先我们来看看scrapy的常用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
scrapy genspider 爬虫名 域名 # 在项目下创建一个爬虫spider类
scrapy runspider 爬虫文件 #运行一个爬虫spider类
scrapy list # 查看当前项目有多少个爬虫
scrapy crawl 爬虫名称 # 通过名称指定运行爬取信息
scrapy shell url/文件名 # 使用shell进入scrapy交互环境
1.第一步我们创建一个scrapy工程, 进入到你指定的目录下,使用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
此时可以看到该目录下多了一个叫BliBli的文件夹.
2. 当我们创建完项目之后,它会有提示,那么我们就按照它的提示继续操作。
You can start your first spider with:
cd BliBli
scrapy genspider example example.com
当你按照上面的操作,之后你就会发现,在spiders文件夹下就会出现spider_bl.py这个文件。这个就是我们的爬虫文件。
后面的 https://search.bilibili.com/ 就是我们要爬取的目标网站
BliBli
|—— BliBli
| |—— __init__.py
| |—— __pycache__.
| |—— items.py # Item定义,定义抓取的数据结构
| |—— middlewares.py # 定义Spider和Dowmloader和Middlewares中间件实现
| |—— pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
| |—— settings.py # 它定义项目的全局配置
| |__ spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
|—— __init__.py
|—— spider_bl.py # 爬虫实现
|—— __pycache__
|—— scrapy.cfg # scrapy部署时的配置文件,定义了配置文件的路径、部署相关的信息内容。
3.接下来我们打开B站搜索 '小姐姐'如下,作为入门级crapy教程.我们今天的任务很简单,爬取视频链接,标题还有up主即可.

4. 设置item模板,定义我们要获取的信息. 就跟java中定义的model类一样.
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BlibliItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 视频标题
url = scrapy.Field() # 视频链接
author = scrapy.Field() # 视频up主
5. 然后我们在我们创建的spider_bl.py文件中写我们爬虫函数的具体实现.
import scrapy
from BliBli.items import BlibliItem
class SpiderBlSpider(scrapy.Spider):
name = 'spider_bl'
allowed_domains = ['https://search.bilibili.com']
start_urls = ['https://search.bilibili.com/all?keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&from_source=web_search']
# 定义爬虫方法
def parse(self, response):
# 实例化item对象
item = BlibliItem()
lis = response.xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li')
for items in lis:
item['title'] = items.xpath('./a/@title').get()
item['url'] = items.xpath('./a/@href').get()
item['author'] = items.xpath('./div/div[3]/span[4]/a/text()').get()
yield item
6.我们现在pipeline中打印一下,没问题我们再将其保存到本地.
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class BlibliPipeline:
def process_item(self, item, spider):
print(item['title'])
print(item['url'])
print(item['author'])
# 保存文件到本地
with open('./BliBli.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
return item
7. settings.py找到以下字段,取消字段的注释。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : str(UserAgent().random),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BliBli.pipelines.BlibliPipeline': 300,
}
使用如下命令运行程序:
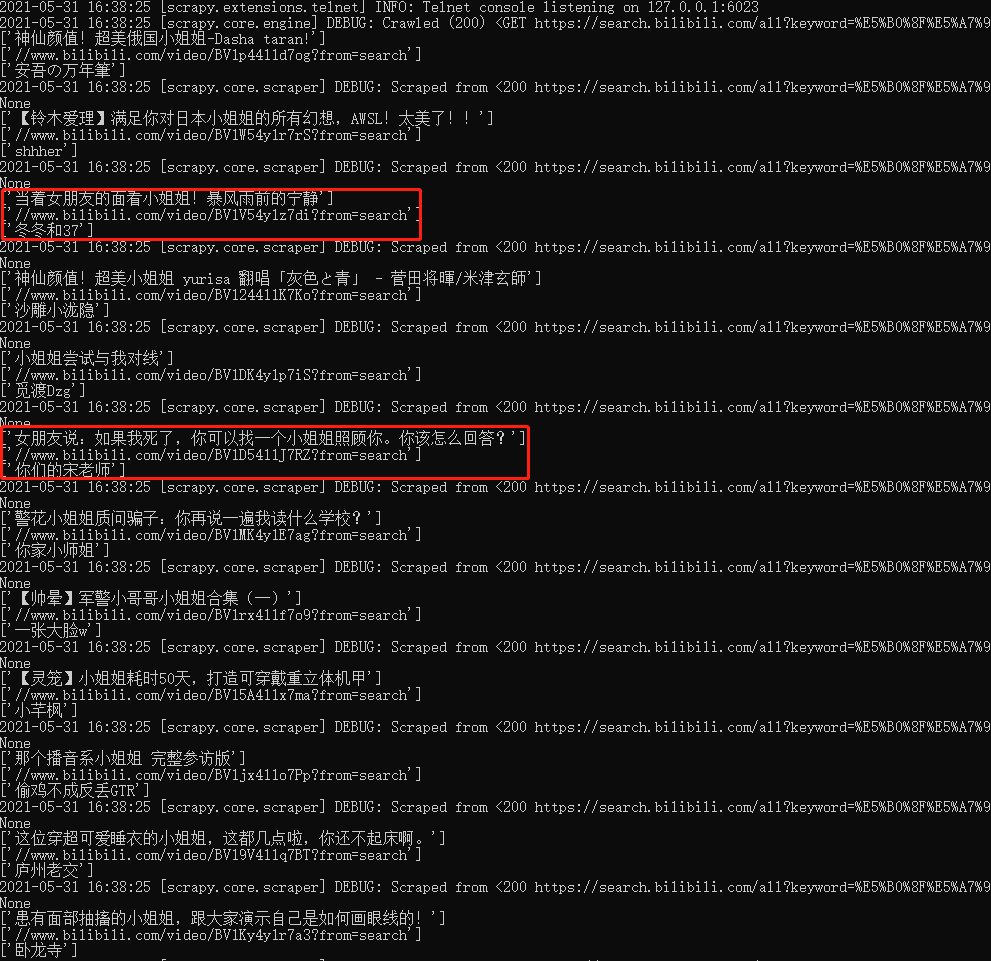
scrapy crawl spider_bl可以看到产生了一个json文件.

打开文件可以看到已经成功的获取到了我们想要的数据.

那么多页数据如何获取呢? 下期分解~
7. settings.py找到以下字段,取消字段的注释。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : str(UserAgent().random),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BliBli.pipelines.BlibliPipeline': 300,
}
使用如下命令运行程序:
scrapy crawl spider_bl可以看到产生了一个json文件.
打开文件可以看到已经成功的获取到了我们想要的数据.
那么多页数据如何获取呢? 下期分解~