python分析视频文件_一起学opencv-python三十六(视频分析:目标跟踪)
上一讲里直接用opencv的stitcher类拼接的话,会损失一部分分辨率,出来的图片是506*1207的,但是这个图像还需要裁剪,也就是列数会小于506。
这个是可以对不同大小的图片进行拼接的。
不过似乎不稳定。有的时候就会报错。
有的时候出来的图片大小不一样:
这个应该是和特征匹配有关系,首先如果用的是二进制描述符,那么它本身是基于概率的,然后在match的时候,又有很多随机的方法,比如随机k-d树,那么就可能出现最后符合条件匹配的点对太少,认为两幅图片拼接不了,也可能是足够拼接的,但是匹配的点对有细微的差别,所以出现图片大小不一样,不过这都是我的猜测了,因为我没看过这个类的源码,我只是猜测它是这么做的。
视频分析之目标追踪
如何追踪视频里的目标呢?如果是单一颜色,并且周围背景没有这种颜色,我们而可以把BGR转到HSV,然后用inRange去追踪,但是前面的一般都不太可能实现的。有一种思路是利用特征匹配,并且用SIFT等方法还有旋转和尺度不变性,但是这种是有问题的,因为前一帧和后一帧的特征匹配结果,我们想要的目标的特征点不一定会匹配得很好,有可能效果很差,完全下一帧匹配得是另一个物体,而且特征点检测匹配整个过程花费时间比较长。不过这是一个思路,还有一个思路就是用直方图去匹配。
参考了:https://blog.csdn.net/chen825919148/article/details/7570246
得到ROI得直方图以后,我们对下一帧图像的每个小区域直方图计算和ROI直方图之间的相似度:
本质上来说,视频目标跟踪就是寻找到上面的相似度值最大的位置,即最佳匹配位置。
这个过程用直方图反向投影可以办到,其实前面我们还学习了模板匹配,模板匹配考虑了空间位置,但是它的旋转不变性和尺度不变性就会很差,视频中的目标一般来说都会有旋转或者尺度的变化,一般摄像头是不动的,即便摄像头运动,也很难保证目标不旋转,大小不变化。就像下面的车。而直方图反向投影反而因为舍弃了位置信息而对旋转和尺度变化都有一定的适应性。
但是其实直方图匹配的结果一般不会像上面的结果那么好,即使阈值化之后,还是会有很多分散的区域。比如下面文章里面:
得到的结果都是比较分散的,如何从这些分散的区域找到抑恶个最佳匹配区域呢?这就是我们下面要解决的问题,我觉得最终的目标就是最后选择区域里面包含点的值(这个值是直方图反向投影的结果)的和最大。第一种方法是Meanshift,参考了https://blog.csdn.net/jameshater/article/details/50992155
和https://blog.csdn.net/jinshengtao/article/details/30258833
如果这些点是均匀的分布在圆里面,合成向量就是0,也就是不移动,最后的合成向量向哪个方向,说明这个方向的点比较多,为了得到比较好的结果(包含较多的直方图反向投影的较大的值),圆就应该朝这个方向靠近,但是其实这里应该是向质心方向而不是合成向量方向偏移,质心方向和合成向量一般不会在一个方向。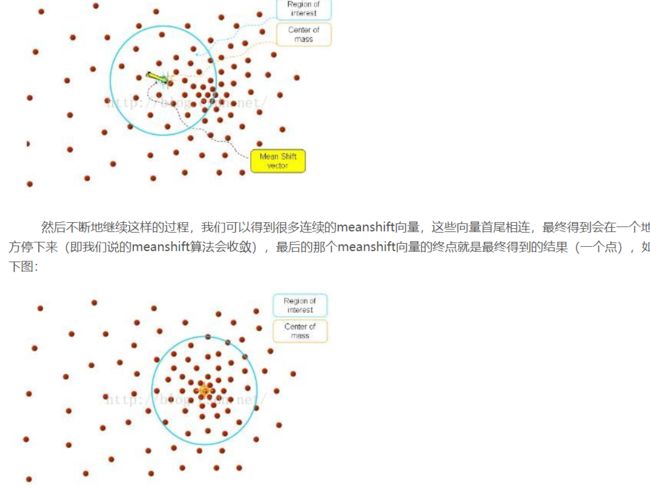
上面点的密度我们可以看做是直方图反向投影结果的密度,也就是点多的地方直方图反向投影的结果比较大。
我补充几点,其实从上面的描述中我们不难看出来,这个算法毕竟是数值算法,它是有缺点的,因为如果恰好在某个密度不是很大的地方,点均匀分布了(比如全是黑色的区域),那么岂不是圆就不会移动了,所以说能不能收敛到全局最优解,这个和初值的关系很大。下面的gif
是一个例子。
下面来看看Meanshift的数学描述和数学原理:


下面这段话叙述了引入核函数和权重系数的原因:

这个核函数别看说的挺麻烦,其实就和卷积核是一个道理,只是给每个位置加了一个权重而已,它遵守的原则就是越接近圆心,权重越大,反之越小。
这个不一定收敛到全局最优解。



计算目标新位置就是在计算质心位置。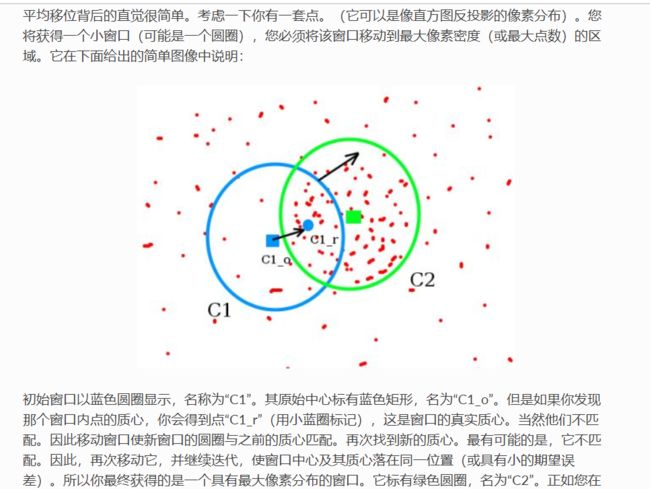
当然opencv里用meanshift只需要从直方图反向投影的结果开始,这个就比较方便了。
opencv代码:
下面的代码是在HSV的Hue(色调)空间做的直方图匹配。为了防止一些亮度比较低的无效的值干扰,这里计算直方图的时候用了inRange的结果做掩码。这里要过滤掉了s和v通道都比较小的点,我觉得这里更可能是因为它们比较没有特色?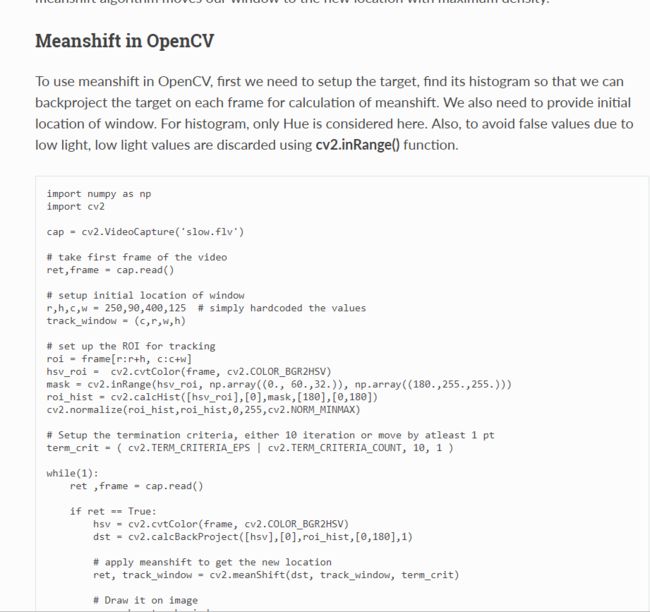

先来看一看里面用到的没见过的函数:
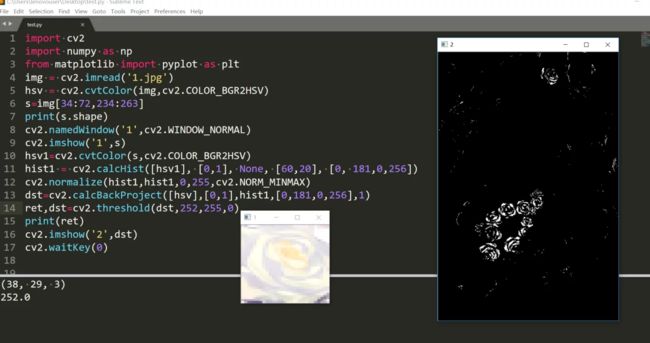
初始搜索窗口的格式应该是左上角坐标和宽高。上面用的是视频,我只用两张图来测试。 q1.jpg
q1.jpg
 q2.jpg
q2.jpg
我就来跟踪这个眼镜清洗液。
首先定位眼镜清洗液。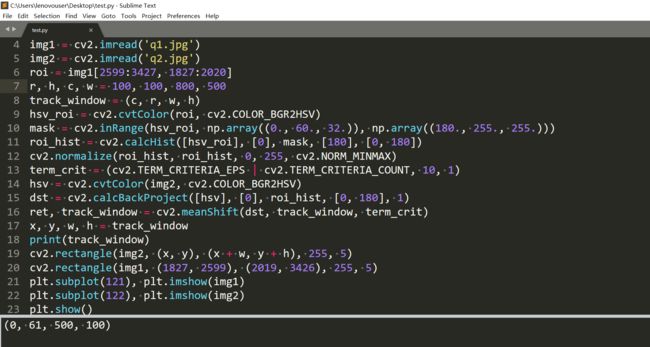
上面的初始窗口是我随便选的位置。结果:
完全不对。我们看一看这个dst:
这下就是因为初始位置选的不好,结果直接给搞到黑色区域了,并且最后的结果和我们的初始窗口大小都不一样。那么我们就再选一个:
结果:
好了很多。不过输出的窗口大小还是和初始的不一样呢,有点搞不懂它是怎么变换窗口大小的。我去掉过滤低亮度和饱和度那一步其实结果也还是挺好的: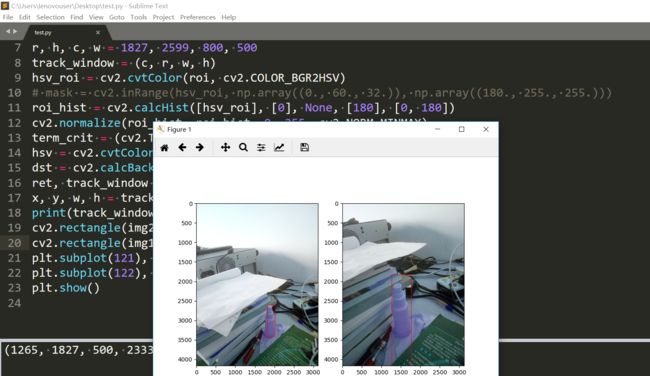
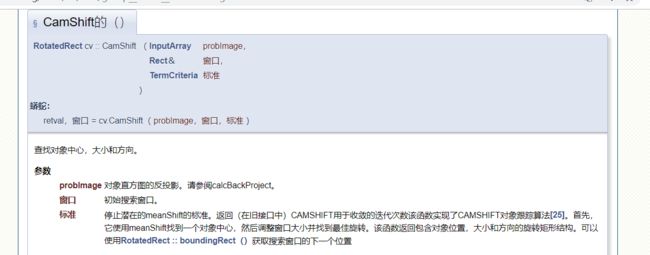
还有一种算法叫做CAMSHIFT,它是基于meanshift算法的。
参考https://blog.csdn.net/qq_15947787/article/details/53161768
camshift就是让这个窗口的大小是变化的,来适应尺度和旋转变化,它在1988年被提出。它先用meanshift直到收敛,然后更新窗口大小,它还计算最佳拟合椭圆,然后在更新一次大小?官方里没说,不知道它拟合椭圆是要干嘛?我觉得可以根据拟合的椭圆更新这个窗口的大小和方向。然后再利用新的窗口继续用meanshift直到收敛或者满足停止条件。
关于调整的s大小,我查了其它地方说的不太一样。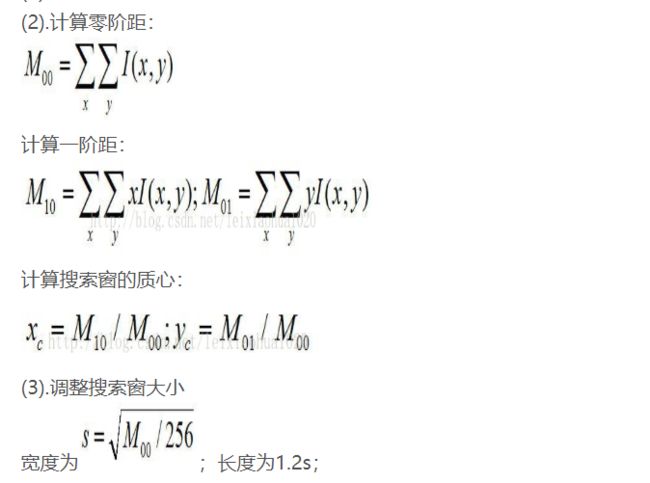
这个更新的大小怎么推到出来的我还真的是不知道,如果收敛到全是255的里面的话,如果一开始的窗口大小是a×a,后来就变成了(255/256)**0.5*a×1.2*s,不知道是怎么来的,不过里面用了M00,也就是用了统计信息,虽然还是不知道这个形式怎么来的。下面gif显示了这个过程。
代码:
其实meanshift已经用了camshift的方法来放大了,看官方文档的解释,所以上面用meanshift才会出现结果和初始窗口大小不一样。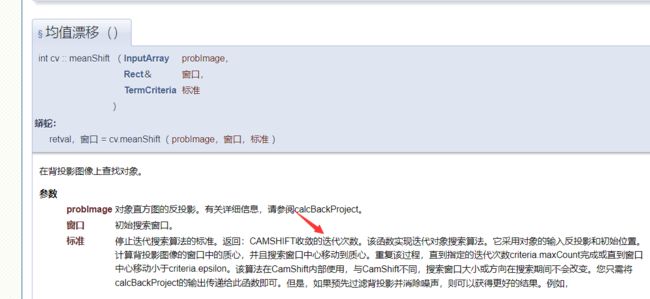
试一下camshift: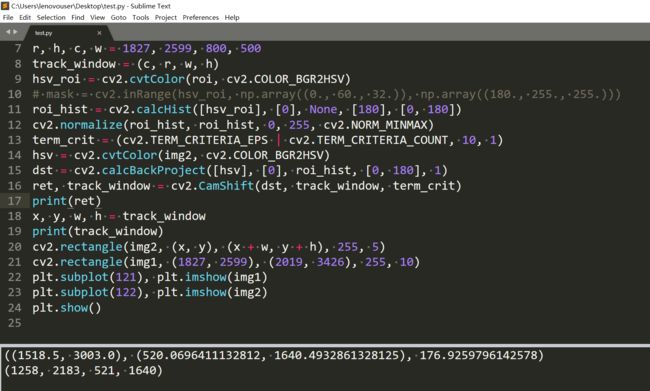
结果还是和meanshift有所不同的。这个ret里面应该是存放着的是旋转过后的信息,参考


根据ret的信息我们也可以画一个矩形框,这个矩形应该是根据拟合椭圆的最小面积外接矩形来的。所以可以出现斜的:

结果:
这断断续续的感觉是因为取整,原来的小数在一条直线上,取整之后,这些点就可能不再一条直线上了,因为取整的舍入量不一样。
用meanshift试一下: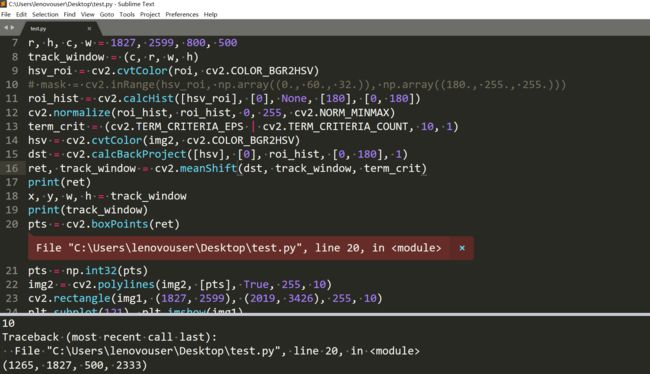
它的ret返回的是迭代次数,所以meanshift的结果不能是斜的。