MySQL-基础
MySQL
1.SQL语句
1.1数据库
-- 创建数据库
create database review character set 字符集
create database if not exists review charset 字符集 collate 比较规则
-- 查看表的创建细节
show create database review
-- 修改数据库
alter database review charset utf8mb4 collate utf8mb4_general_ci
-- 使用数据库
use review
-- 删除数据库
drop database if exists review
排序规则:定义在指定字符集下不同字符的比较规则,若没有指定会有一个默认的排序规则。
- utf8_general_ci:utf8不区分大小写的通用排序规则。适合在英语及部分欧洲语言中使用。主要依赖于字符的编码值进行比较。不区分大小写、特定的语言规则、重音标记等。
- utf8_unicode_ci:utf8不区分大小写的unicode排序规则。在排序比较字符时,使用比较复杂的规则,并考虑特定的语言惯例和规则,将字符转换为unicode规范化形式,然后根据规范化后的字符进行比较。
- utf8_general_cs:utf8区分大小写的通用排序规则。
- utf8_unicode_cs:utf8区分大小写的unicode排序规则。
1.2表
-- 创建表
create table if not exists test_table1
(
字段名1 数据类型 [约束条件] [默认值],
字段名1 数据类型 [约束条件] [默认值],
...
);
-- 查看表的创建信息
show create table test_table1;
-- 显示表的结构
desc test_table1;
-- 添加表字段 [first|after]表示添加在表的某个字段之前或之后
alter table test_table1 add column 字段名 字段类型 [约束条件] [默认值] [first|after] 字段名;
-- 修改表字段
alter table test_table1 modify 字段名 数据类型 [约束条件] [默认值];
-- 重命名字段
alter table test_table1 change column 字段名 新字段名 新数据类型 [约束条件] [默认值];
-- 删除一个列
alter table test_table1 drop column password;
-- 修改表名
rename table test_table1 to test_table;
-- 清空表
truncate table test_table;
-- 删除表
drop table if exists test_table;
注意:约束条件和默认值是可选项。字段名和数据类型是必选项。
1.3增删改查
1.添加
insert into 表名(字段1,字段2,...)
values
(value1, value2),
(value1, value2);
2.删除
delete from 表名 [删除条件]
3.修改数据
update 表名 set 字段名1=value1, 字段名2=value2,.... [更新条件]
4.查询数据
select [查询字段] from 表名 [查询条件]
-- 去重
select distinct [查询字段] from 表名 [查询条件]
1.4排序
使用order by关键字进行排序,asc代表升序,desc代表降序。
-- 单列排序
select .... from 表名 order by 字段名;
-- 多列排序(如果字段名1的值能区分出顺序,就不会去比较字段2的值)
select ... from 表名 order by 字段名1 字段名2 asc;
1.5分页
基本语法:limit [位置偏移量], 行数。
-- 显示查询的前10条数据
select * from test_table limit 10;
-- 指定偏移量10(相当于偏移10条元素,从第11条数据开始输出10条)
select * from test_table limit 10,10;
-- 分页公式:每页展示18条数据。显示第n页的数据。
select * from test_table limit (n-1)*18,18
1.6查询语句的执行顺序
from -> on -> join -> where -> group by -> having -> select -> distinct -> order by -> limit;
2.聚合函数
作用于一组数据,并对该组数据返回一个值。通常使用在经过分组的数据之后。
- AVG():计算组平均值
- SUM():计算组和
- MAX():计算组最大值
- MIN():计算组最小值
- COUNT():计算组的数量
聚合函数的注意事项:
- 不能使用在where语句重
- 如果没有分组那整张表就是一组。
having:通过group by进行了分组,根据一些条件筛选想要的分组,就可以使用having,主要起过滤分组的作用。
使用having的前提条件:
- 需要和group by语句同时使用
- 使用聚合函数进行调节筛选
3.子查询
在一条查询语句中内嵌一条查询语句,内层查询结果作为外层查询的查询条件。
需求:例如有一张表user字段分别为姓名、年龄,查询比obstar年龄更大的有谁。
select name, age from user where age>(select age from user where name = 'obstar')
单比较操作符:
- =:比较相等
- >:大于
- <=:小于等于
- <:小于
- =>:大于等于
- <>:不等
多行比较操作符:
- in:等于结果中的任意一个即可。
- any:和查询集的某一个值比较(需要和单行比较操作符一起使用)
- all:和查询集的所有值比较(需要和单行比较操作符一起使用)
= any:和结果集中的任意一个相等即为真。
>any:比结果集中的任意一个大即为真。
<> any:和结果集中的任意一个不相等即为真。
= all:和结果集中的所有相等即为真。
> all:大于结果集中的所有即为真
<> all:和结果集中的所有不相等即为真
4.多表查询
多个表或单张表之间进行关联查询。一般是多张表之间存在关联关系使用的方式。
内连接(INNER JOIN):它返回两个表中匹配的行。只有当两个表中的指定列具有相同的值时,它才会返回行。
外连接(OUTER JOIN):即使其中一个表中没有匹配的行。根据你选择的类型(左、右或全外连接),未匹配的行将包含NULL值。
联合连接(UNION ):操作用于组合两个或多个SELECT语句的结果集,但每个SELECT语句必须具有相同的数量的列和相似的数据类型。它默认删除重复的行,但可以使用UNION ALL来保留重复的行。
需求:存在一张表student表字段分别为st_id、st_name,grade,存在一张表成绩表(scores),字段分别为st_id、sc_type、sc_score。查询名为obstar同学的成绩。
create table students(
st_id int,
st_name varchar(16),
grade varchar(8)
);
insert into students
values
(1, 'tom', '1'),
(2, 'jary', '2'),
(3, 'michael', '1'),
(4, 'obstar', '2');
create table scores(
st_id int,
sc_type varchar(16),
sc_score double
);
insert into scores
values
(1, '语文', 92.5),
(1, '数学', 82),
(1, '英语', 100),
(2, '语文', 80),
(2, '数学', 82),
(2, '英语', 60),
(3, '语文', 99.5),
(3, '数学', 84),
(3, '英语', 66),
(4, '语文', 88),
(4, '数学', 78),
(4, '英语', 98);
SELECT sc.sc_type, sc.sc_score, st.grade FROM students st INNER JOIN scores sc on sc.st_id = st.st_id where
st.st_id in (select st_id FROM students WHERE st_name = 'obstar');
需求:查询每个同学的总分是多少
SELECT st.st_id, st.st_name, st.grade, sa.sum FROM students st LEFT JOIN (SELECT st_id, SUM(sc_score) sum FROM scores GROUP BY st_id) sa ON st.st_id = sa.st_id;
5.数据类型
5.1整型
tinyint、smallint、mediumint、int(integer)、bigint。
- tinyint(1字节):-128-127。
- smallint(2字节):-32768-32767。
- mediumint(3字节):-8388608-8388607
- int(4字节):-2147483648-2147483647
- bigint(8字节):-9223372036854775808-9223372036854775807
可选属性:
- M:显示宽度,可以理解为显示的时候看到的最少数字个数,需要配合zerofill一起使用,否则不生效。
- unsigned:修饰整形,代表该整形是无符号的整形。
- zerofill:用0来填充宽度,配合M使用。
5.2浮点类型
float(4字节)、double(8字节)。
5.3定点类型
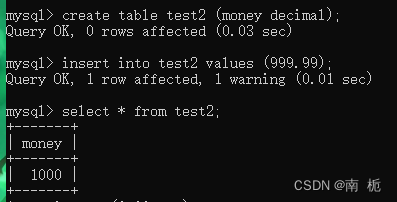
decimal(M,D):表示高精度的小数,M为精度,D为标度(小数点的位数)。1<=M<=65。D必须小于M。
decimal(6,3):表示最多可以存储6为数字,其中3位是小数,最大值为999.999。
decimal在MySQL内部是以字符串的形式进行存储,这就决定了它一定是精准的。
注意:当DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0)。当数据的精度超出了定点数类型的
精度范围时,则MySQL会进行四舍五入处理。
5.4日期时间类型
year、time、date、datetime、timestamp。
- date:用于存储日期值,不包括时间部分。取值范围是’1000-01-01’到’9999-12-31’。
- time:用于存储时间值,不包括日期部分。取值范围是’-838:59:59’到’838:59:59’。
- datetime:用于存储日期和时间值,包括年、月、日、时、分、秒。取值范围是’1000-01-01 00:00:00’到’9999-12-31 23:59:59’。
- teimstamp:用于存储日期和时间值,但它会自动将存储的值转换为UTC(世界标准时间)。取值范围是’1970-01-01 00:00:01’UTC到’2038-01-19 03:14:07’UTC。
- year:year类型用于存储年份值,可以使用2位(‘YY’)或4位(‘YYYY’)格式。取值范围是’1901’到’2155’,或者’00’到’99’(如果使用2位格式)
5.5文本类型
- char:用于存储固定长度的字符串,可以指定长度,取值范围是1到255。如果存储的字符串长度小于指定长度,MySQL会用空格进行填充。
- varchar:用于存储可变长度的字符串,也可以指定长度,取值范围是1到65535。与CHAR类型不同,VARCHAR类型只会存储实际长度的字符串,不会进行填充。
- tinytext:用于存储较小的文本数据,最大长度为255个字符。
- text:用于存储中等大小的文本数据,最大长度为65535个字符。
- mediumtext:用于存储较大的文本数据,最大长度为16777215个字符。
- longtext:用于存储非常大的文本数据,最大长度为4294967295个字符。
6.约束
- 主键约束(primary key):唯一标识表中的一行数据。
- 唯一约束(unique):唯一约束用于确保表中的某个字段或字段组合是唯一的。
- 外键约束(foreign key):用于建立表之间的关联关系。
- 非空约束(not null):确保字段的值不能为空
- 检查约束(check):检查字段的值是否符合要求。
- 默认约束(default):插入时给某个字段设置默认值。
6.1主键约束
主键约束的字段值是唯一的且不能为空。
create table test(
phone char(11),
username char(32),
primary key(phone, username)
);
注意:一个表中只能有一个主键约束,主键约束可以由多个字段组成。
6.2唯一约束
限制表中某个/多个字段值是唯一的。
create table test(
phone char(11),
username char(32),
unique(phone, username)
);
注意:在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
6.3外键约束
例如有一张学生表(主表)、成绩表(从表)。成绩表中的成绩对应的一定是一个同学,因此成绩表可以设置外键约束。
create table students(
st_id int unique not null,
st_name varchar(16),
grade varchar(8)
);
create table scores(
st_id int,
sc_type varchar(16),
sc_score double,
foreign key (st_id) references students(st_id)
);
注意:从表引用的外键字段一定是主表的主键/唯一约束字段。
6.4非空约束
关键字:not null。
注意:在MySQL中,所有的数据类型都可以是null。只能对单独的字段设置为空,不能组合非空。
6.5检查约束
MySQL8.0.16版本之前可以使用check约束,但check约束对数据验证没有任何作用。添加数据时,没有任何错误或警告但是MySQL 8.0.16中可以使用check约束了。
限制字段只能为男女。
create table users (
gender char check('男' or '女')
);
限制字段值范围
create table users (
age tinyint unsigned ,
check(age<=150)
);
6.6默认约束
关键字:default。
7.存储引擎
存储引擎是组织数据的一种方式
查看数据库支持的存储引擎。
show engines;

Transactions:事务
XA:分布式事务。
Savepoints:中断点。
7.1设置默认存储引擎
-- 查询系统默认存储引擎
show variables like '%storage_engine%';
-- 修改默认存储引擎
set default_storage_engine = InnoDB;
-- 永久修改 修改my.cnf文件,然后重启服务
default-storage-engine=InnoDB
7.2表的存储引擎
-- 设置表的存储引擎
create table test(
字段名 数据类型 [约束条件] [默认值],
...
)engine = InnoDB;
-- 修改表的存储引擎(谨慎修改)
alter table test engine = MyISAM;
ransactions:事务
XA:分布式事务。
Savepoints:中断点。
7.1设置默认存储引擎
-- 查询系统默认存储引擎
show variables like '%storage_engine%';
-- 修改默认存储引擎
set default_storage_engine = InnoDB;
-- 永久修改 修改my.cnf文件,然后重启服务
default-storage-engine=InnoDB
7.2表的存储引擎
-- 设置表的存储引擎
create table test(
字段名 数据类型 [约束条件] [默认值],
...
)engine = InnoDB;
-- 修改表的存储引擎(谨慎修改)
alter table test engine = MyISAM;