论文笔记 Unified Language Model Pre-training for Natural Language Understanding and Generation
一、干啥用的?
一个新的预训练语言模型(UNILM),它可以用于自然语言理解NLU和生成任务NLG。
UNILM由多个语言建模目标共同预训练,共享相同的参数。
二、和别的pre-train模型有啥区别?
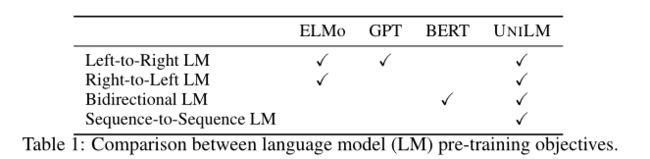
UNILM是一个多层Transformer网络,使用三种类型的语言建模任务进行预训练:单向(包括l-to-r 和r-to-l)、双向和seq2seq预测。该模型在大量文本上联合预训练,针对三种类型的无监督语言建模目标进行优化。
三、怎么做的?
与BERT类似,可以对预先训练的UNILM进行微调(如有必要,还可以添加特定于任务的层),以适应各种下游任务。
但与主要用于NLU任务的BERT不同的是,UNILM可以通过配置的方式来使用不同的自注意力的mask机制,为不同类型的语言模型聚合上下文,从而既可以被用在自然语言理解任务上,又可以被用在自然语言生成任务上.

通过图示很容易明白,对于不同的语言模型,设置不同的mask方式以控制attention的范围。

好家伙,这不就是transformer公式吗,就加了个M(mask),其余的动也没动!
3.1 input
首先我们看到了他的输入是 [x1,x2,x3…xn],整个输入字符串也可以有两种格式,一个句子-单项语言模型用(unidirectional LMs) 或者一对句子,给双向(bidirectional LM)或者seq-t-seq用,每个x就是一个英文单词儿或者说是一个汉字,总之就是基本语言单位,然后和bert一样一样的,每个基本语言单位的向量表示都包括了三个部分,分别是字符表示向量,位置表示向量,句子序号表示向量.
然后在输入开头加入[SOS] token(start-of-sequence), 表示句子输入开始啦,然后在每一句末尾加[EOS] token(end-of-sequence),这个标签不仅在自然语言理解任务中表示句子边界,还在自然语言生成任务中标示着到这个点儿了就该结束解码过程了,让模型学习该怎么停止,还有就是他的英文处理的时候参照bert,(比如会把playing切成两个词play和##ing) , 中文? UNILM好像还没中文的预训练模型, 现在好像就出了一个预训练模型, 用的bert-large的参数初始化的。
3.2 咋做完形填空
咱们都知道, 预训练的语言模型是不需要标注的,他会随机的遮住一些基本的语言单位 ,也就是把一些字符替换成[MASK]这个特殊token, 然后让模型通过上下文信息去猜这个盖住的是什么字, 然后和真实的做对比求loss, 然后照着loss降低的方向去优化模型参数。
因为unilm他本质上存在四种不同的语言模型结构嘛.所以他共有四种完形填空的方式,接下来咱们一一道来.
Unidirectional LM : 单向的语言模型, 包括从左到右和从右到左,这里就单说从左到右, 在考虑每个基本字符单位的向量表示的时候,只考虑他本身及本身左边的基本字符单位, 打个比方 “我 是 大 [MASK] 哥 呀” ,这句话, 使用单向语言模型的时候 , 我们在预测被遮住的mask的时候所能使用的上下文信息只有 “我 是 大 [MASK]” , 就是只有MASK和他左边的所有基本字符单位, 那他是怎么实现的呢? 大家往上看 , 对, 就是上一个图片 , left-to-right LM对应的那个矩阵 , 看见没, 对角线往左下包括对角线都是白色的 , 就代表了Mask Matrix这些位置是0 ,就是不做改变(回想一下上上图的公式2) , 灰黑色的块儿就代表这里是无穷小,就是在Q乘以K的转置并缩放以后的结果响应位置上加上无穷小,就是变不可见了呗.
Bidirectional LM : 双向的语言模型可以在每一次预测mask的时候都获得完整的上下文信息,两个方向的所有的基本字符单位信息都会编码进他的上下文信息中 , 相比于单向的语言模型 , 他这样做肯定可以会有更好的上下文表示(但是这样就搞不好生成任务了,为啥 ? 你还没生成后面的内容呢,就要用后面的内容表征这个基本字符单位的向量了,能掐还是会算啊?) . 还用上个栗子 “我 是 大 [MASK] 哥 呀” 这句话 (当然两句话也行,反正就是全局视野,都互相可见), 整个的一句话都会参与进mask的预测过程. 还是抬头看图片 , 全是白框框,就代表这时候整个mask矩阵都是0 , 所有的表征都相互可见 .
Sequence-to-Sequence LM : 我们都知道 , seq-to-seq的场景中语料是一对儿, 有个source有个target , 在source里的基本字符单位对互相都可见 , 但是在target里面的基本字符单位只能见到自己和自己左边的基本字符单位 , 举个栗子来说的话 ,比如 “[SOS]你 瞅 啥 [EOS] 瞅 你 咋 滴 [EOS]” 这句话如果喂进去的话(source是你瞅啥,target是瞅你咋滴) , 那source的[SOS], 你 , 瞅 , 啥 ,[EOS]他们五个互相可见 , target 里的 “咋” 就只能看见source里的所有字符和自己以及自己左边的俩字儿 : 瞅 , 你 .咋 . 还是抬头看么 , 图也画的很清楚了 , s1是source , s2是target。
3.3 咋训练
那我们现在知道了他一共有三种不同的完形填空手段, 那这是一个模型呀 , 怎么用这三种完形填空的手段呢? 在论文中作者是这样描述的 , 在一个训练batch中 , 三分之一的时间用Bidirectional LM ,三分之一的时间用Sequence-to-Sequence LM, 然后从左到右的单向和从右到左的单向各占六分之一的时间 。
同时为了和bert[large]进行公平比较, 他的模型结构和bert[large]相同(高情商:公平比较。低情商:我抄的), 激活参数用的gelu, 具体来说就是24层的transformer , 每层1024个节点, 使用了16个自注意力头 ,大概一共340M左右,他的参数初始化自bert[large],然后使用的English Wikipedia2 和 BookCorpus 进行的模型的预训练 , 词汇量大小是28996个 , 语料最大长度是512 , 他随机选取mask的几率是15%,在这些选出的mask中, 有80%的是直接替换成[MASK]字符, 有10%的是替换成随机基本字符单位,剩下的10%不动他, 让他保持原样. 此外,还有一个手段, 就是在替换mask时, 80%的几率是只替换一个基本字符单位 , 还有20%的几率是替换一个二元组或者三元组。
四、优点
论文说了,UNILM主要有三个优点:
1、他统一的预训练过程,使用一个transformer语言模型囊括了了不同类型的语言模型的的参数和结构(bi, left-t-right,right-t-left,seq-t-seq),从而不需要分开训练多个语言模型。
2、因为他囊括了多种语言模型参数和结构呀,所以参数共享使得他学习到的文本表征更加通用化了,他会针对不同的语言建模目标进行联合优化,上下文信息会以不同的方式去使用,所以可以减少自然语言任务训练中的过拟合。
3、因为UNILM有seq-to-seq的用法,所以他天生适用自然语言生成任务,比如摘要提取,问题生成。