k8s全栈-笔记6-Prometheus+Alertmanager构建监控系统
k8s全栈-笔记6-Prometheus+Alertmanager构建监控系统
实验环境:
Pormetheus+grafana+alertmanager安装在k8s集群,k8s环境如下
| K8S集群角色 | IP | 主机名 | 安装的组件 |
|---|---|---|---|
| 控制节点(master) | 172.20.252.181 | k8s-master01 | apiserver,controller-manager,schedule, kubelet,etcd,kube-proxy,容器运行时,calico |
| 工作节点(node) | 172.20.252.191 | k8s-node01 | kube-proxy,calico,coredns,容器运行时,kubelet |
| 工作节点(node) | 172.20.252.192 | k8s-node02 | kube-proxy,calico,coredns,容器运行时,kubelet |
Prometheus特点
- 多维度数据模型
每一个时间序列数据由metric度量指标名称和它的标签labels键值对集合唯一确定:
这个metric度量指标名称指定监控目标系统的测量特征(如: http_requests_total– 接受http请求的总计数)
labels开启了Prometheus的多维数据模型: 对于相同的度量名称,通过不同标签结合,会形成特定的度量维度标签.(例如: 所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求).这个查询语言在这些度量和标签列表的基础上进行过滤和聚合.改变任何度量上的任何标签值,则会形成新的时间序列图.
- 灵活的查询语言(PromQL)
可以对采集的metrics指标进行加法,乘法,连接等操作.
- 可以直接在本地部署,不依赖其他分布式存储;
但是一般生产环境都要添加存储
- 通过HTTP的pull方式采集时序数据;
docker pull
-
可以通过中间网关pushgateway 的方式把时间序列数据推送到 prometheus server端;
-
可通过服务发现或者静态配置来发现目标服务对象(targets).
-
有多种可视化图像界面,如Grafana等.
-
高效地存储,每个采样数据占3.5bytes左右,300万的时间序列,30s间隔,保留60天,消耗的磁盘大概200G.
-
做高可用, 可以对数据做异地备份, 联邦集群, 部署多套prometheus, pushgateway 上报数据.
样本
在时间序列中的每一个点称为一个样本(sample), 样本由以下三部分组成:
- 指标(metrics): 指标名称和描述当前样本特征的labelsets;
- 时间戳(timestamp): 一个精确到毫秒的时间戳;
- 样本值(value): 一个folat64的浮点型数据表示当前样本的值.
Prometheus组件介绍
靠Retrieval组件拉取监控指标数据
Prometheus工作流程
要能自己讲出来
Pormetheus和Zabbix对比
zabbix集群规模上限为10000个节点,prometheus支持更大的集群规模,速度也更快
zabbix更适合监控物理机环境. prometheus更适合云环境的监控,对Openstack, Kubernetes有更好的集成
zabbix监控数据存储在关系型数据库内,如MySQL,很难从现有数据中心扩展维度.prometheus监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合.
Prometheus的四种数据类型
Counter
Counter是计数器类型:
- Counter用于累计值,例如记录请求次数,任务完成数,错误发生数.
- 一直增加,不会减少.
- 重启进程后,不会被重置
Gauge
Gauge是测量器类型:
- Gauge是常规数值,例如温度变化,内存使用变化
- 可变大,可变小.
- 重启进程后,会被重置
Histogram
Histogram是柱状图,在Pormetheus系统的查询语言中,有三种作用:
- 在一段时间范围对数据进行采样(通常是请求持续时间或响应大小等),并将其记入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图.
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和
度量指标名称: [basename]_上面三类的作用度量指标
- [basename]_bucket {le=“上边界”},这个值为小于等于上边界的所有采样点数量
- [basename]_sum
- [basename]_count
小结: 如果定义一个度量类型为Histogram, 则Prometheus会自动生成三个对应的指标
思考:为什么需要用histogram柱状图?
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率,页面的平均响应时间.
这种方式的问题也很明显,比如系统调用大多数API请求在100ms的响应时间范围,而个别请求响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题.
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组
注意:
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布.注意后面的采样点是包含前面的采样点的
summary
与 Histogram类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算.它也有三种作用:
- 对每个采样点进行统计,并形成分位图.(如: 正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
- 统计班上所有同学的总成绩(sum)
- 统计班上同学的考试总人数(count)
实操
node-exporter组件安装和配置
[root@k8s-master01 ~]# kubectl create ns monitor-sa
namespace/monitor-sa created
# 创建namespace
[root@k8s-master01 prometheus+alertmanager-resources]# scp node-exporter.tar.gz k8s-node01:/root
node-exporter.tar.gz 100% 23MB 77.9MB/s 00:00
[root@k8s-master01 prometheus+alertmanager-resources]# scp node-exporter.tar.gz k8s-node02:/root
node-exporter.tar.gz 100% 23MB 73.7MB/s 00:00
docker load -i node-exporter.tar.gz
# 所有节点导入镜像
# 或者在网上docker pull拉取镜像
[root@k8s-master01 prometheus+alertmanager-resources]# cp node-export.yaml node-export.yaml.bak
[root@k8s-master01 prometheus+alertmanager-resources]# sed -ri "s#node-role.kubernetes.io/master#node-role.kubernetes.io/control-plane#g" node-export.yaml
# 因为kubernetes新版因为种族歧视标签从master改成了control-plane
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f node-export.yaml
daemonset.apps/node-exporter created
# 应用yaml文件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get pods -n monitor-sa -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-c9gxc 1/1 Running 0 5m33s 172.20.252.191 k8s-node01 <none> <none>
node-exporter-nkvhb 1/1 Running 0 5m33s 172.20.252.192 k8s-node02 <none> <none>
node-exporter-zflh7 1/1 Running 0 5m33s 172.20.252.181 k8s-master01 <none> <none>
# 可以看到pod已经全部起来了
[root@k8s-master01 prometheus+alertmanager-resources]# curl 172.20.252.181:9100/metrics
# 测试查看数据
[root@k8s-master01 prometheus+alertmanager-resources]# curl 172.20.252.191:9100/metrics |grep node_load
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.05
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 0.03
100 67790 100 67790 0 0 7764k 0 --:--:-- --:--:-- --:--:-- 8275k
# 过滤查看k8s-node01负载
Prometheus server安装和配置
创建sa账号,对sa做rbac授权
[root@k8s-master01 ~]# kubectl create serviceaccount monitor -n monitor-sa
serviceaccount/monitor created
# 创建一个sa账号monitor
[root@k8s-master01 ~]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created
# 把sa账号monitor通过clusterrolebind绑定到clusterrole上
创建数据存储目录
[root@k8s-node01 ~]# mkdir /data
[root@k8s-node01 ~]# chmod 777 /data/
# 在k8s集群的k8s-node01节点上创建数据存储目录
安装Prometheus server服务
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-cfg.yaml
configmap/prometheus-config created
# 创建一个configmap存储卷,用来存放prometheus配置信息
[root@k8s-master01 prometheus+alertmanager-resources]# grep "\- source_labels: \[__address__]" prometheus-cfg.yaml -A10
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
[root@k8s-master01 prometheus+alertmanager-resources]# grep relabel_configs: prometheus-cfg.yaml
relabel_configs:
relabel_configs:
relabel_configs:
relabel_configs:
# YAML文件要能大致看懂,特别是替换标签,然后为什么要替换.很重要!不懂就去看文档或者看视频
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get configmap -n monitor-sa
NAME DATA AGE
kube-root-ca.crt 1 27h
prometheus-config 1 22h
通过deployment部署prometheus
[root@k8s-master01 prometheus+alertmanager-resources]# scp prometheus-2-2-1.tar.gz k8s-node01:/root
prometheus-2-2-1.tar.gz 100% 109MB 109.4MB/s 00:01
[root@k8s-master01 prometheus+alertmanager-resources]# scp prometheus-2-2-1.tar.gz k8s-node02:/root
prometheus-2-2-1.tar.gz 100% 109MB 109.4MB/s 00:01
# 传输镜像压缩包到工作节点
[root@k8s-node01 ~]# docker load -i prometheus-2-2-1.tar.gz
[root@k8s-node02 ~]# docker load -i prometheus-2-2-1.tar.gz
# 工作节点导入prometheus镜像
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/xianchaonode1/k8s-node01/g" prometheus-deploy.yaml
# 因为前面在node01创建了数据存储目录,所以选择调度到node01
[root@k8s-master01 prometheus+alertmanager-resources]# grep web.enable prometheus-deploy.yaml
- --web.enable-lifecycle
# 意为开启热加载
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-deploy.yaml
deployment.apps/prometheus-server created
# 应用YAML文件
# 要明白yaml文件写的意思,不懂就看文档
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get deployment -n monitor-sa
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-server 1/1 1 1 58s
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get pods -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-c9gxc 1/1 Running 0 24h
node-exporter-nkvhb 1/1 Running 0 24h
node-exporter-zflh7 1/1 Running 0 24h
prometheus-server-7f58cf897b-vlcgh 1/1 Running 0 24m
# 可以看到deployment已经部署成功
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
# 应用YAML文件,需要理解内容
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.105.77.108 <none> 9090:32735/TCP 6s
# 查看service
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl describe svc kube-dns -n kube-system|grep Annotations -A1
Annotations: prometheus.io/port: 9153
prometheus.io/scrape: true
# 意为可以被prometheus抓取信息

上图内容对应prometheus-cfg.yaml 文件内容
Prometheus热加载
使不停止prometheus,就可以使配置生效.
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get pods -n monitor-sa -o wide -l app=prometheus
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-server-7f58cf897b-vlcgh 1/1 Running 0 80m 10.244.85.193 k8s-node01 <none> <none>
[root@k8s-master01 prometheus+alertmanager-resources]# curl -X POST http://10.244.85.193:9090/-/reload
# 修改了想要使配置生效使用以上命令热加载,热加载速度较慢
注意:
线上最好热加载,暴力删除可能造成监控数据的丢失,除非你做了高可用,比如deployment写了两个副本,也就是启两个pod,那修改一个删除再创也不影响业务
Grafana介绍
是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知告警接收方.主要有以下六大特点:
-
展示方式: 快速灵活的客户端图表…
-
数据源: Prometheus,Elasticsearch…
-
通知提醒: 以可视方式定义最重要指标的警报规则…
-
混合展示: …
-
注释: …
安装Grafana
[root@k8s-master01 prometheus+alertmanager-resources]# scp heapster-grafana-amd64_v5_0_4.tar.gz k8s-node01:/root
heapster-grafana-amd64_v5_0_4.tar.gz 100% 164MB 82.1MB/s 00:02
[root@k8s-master01 prometheus+alertmanager-resources]# scp heapster-grafana-amd64_v5_0_4.tar.gz k8s-node02:/root
heapster-grafana-amd64_v5_0_4.tar.gz 100% 164MB 164.2MB/s 00:01
# 传输镜像压缩包到工作节点
# [root@k8s-node01 ~]# docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
# [root@k8s-node02 ~]# docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
# # 工作节点导入镜像,也可docker pull从网上拉取
[root@k8s-node01 ~]# ctr -n k8s.io images import heapster-grafana-amd64_v5_0_4.tar.gz
[root@k8s-node02 ~]# ctr -n k8s.io images import heapster-grafana-amd64_v5_0_4.tar.gz
# 应该使用ctr -n k8s.io images import导入镜像,因为k8s1.26使用容器运行时为containerd
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
# 应用YAML文件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get pods -n kube-system |grep monmonitoring-grafana-5c6bb4b6-phxg5 1/1 Running 0 3m52s
# 可以看到pod已经起来了
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get svc -n kube-system |grep mon
monitoring-grafana NodePort 10.97.75.25 <none> 80:31649/TCP 3m24s
# 查看service

Grafana界面接入Prometheus数据源
展示物理机监控数据

添加完点击最下面 “Save & test” 出现绿色Data source is working就成功了

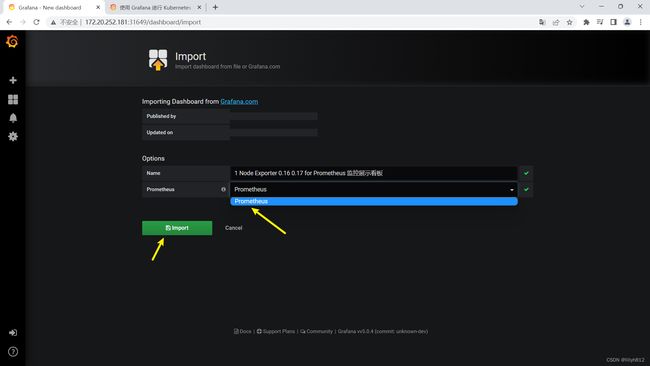

导入的监控模板,可在如下链接搜索
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
可直接导入node_exporter.json监控模板,这个可以把node节点指标显示出来
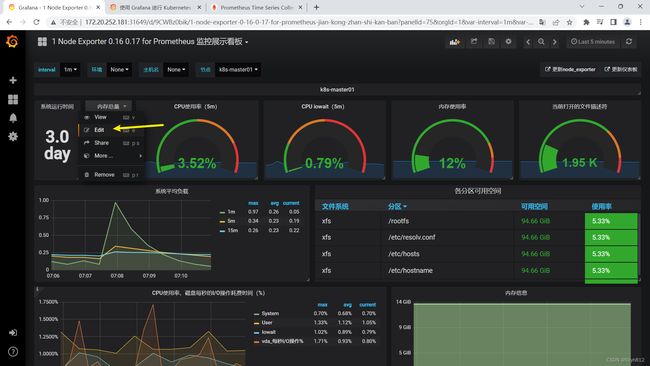
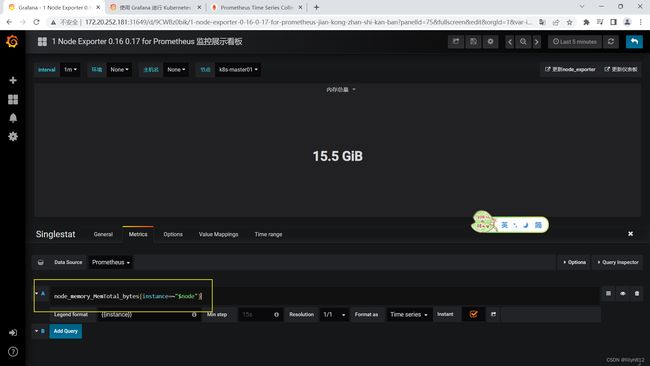
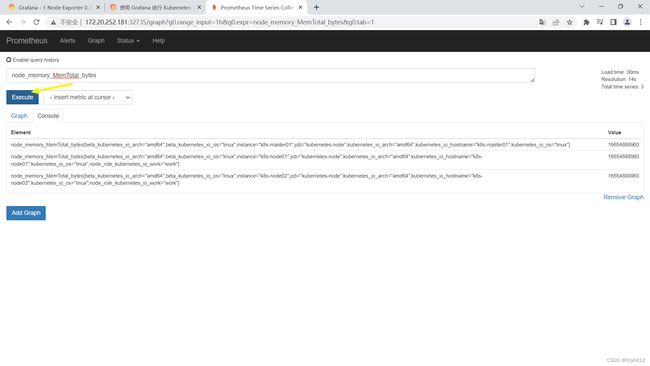
可以看到,grafana展示的数据是接入prometheus的,如果有些数据无法展示,排错可以先去prometheus查一下,看有没有
展示容器监控数据
和以上步骤类似导入docker_rev1.json文件

从官网下载json文件导入
自己玩一下
换成新版grafana镜像,不然很多不支持
安装kube-state-metrics组件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f kube-state-metrics-rbac.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
# 创建sa,授权sa
[root@k8s-master01 prometheus+alertmanager-resources]# scp kube-state-metrics_1_9_0.tar.gz k8s-node01:/root
kube-state-metrics_1_9_0.tar.gz 100% 32MB 83.0MB/s 00:00
[root@k8s-master01 prometheus+alertmanager-resources]# scp kube-state-metrics_1_9_0.tar.gz k8s-node02:/root
kube-state-metrics_1_9_0.tar.gz 100% 32MB 73.1MB/s 00:00
# 传输镜像压缩包到工作节点
[root@k8s-node01 ~]# ctr -n k8s.io images import kube-state-metrics_1_9_0.tar.gz
[root@k8s-node02 ~]# ctr -n k8s.io images import kube-state-metrics_1_9_0.tar.gz
# 导入镜像
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f kube-state-metrics-deploy.yaml
deployment.apps/kube-state-metrics created
# 应用YAML文件创建deployment
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f kube-state-metrics-svc.yaml
service/kube-state-metrics created
# 创建service
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get svc -n kube-system |grep metrics
kube-state-metrics ClusterIP 10.105.7.45 <none> 8080/TCP 4m18s

[root@k8s-master01 prometheus+alertmanager-resources]# curl http://10.244.58.197:8080/metrics
...
# 测试请求
grafana导入两个json文件: "Kubernetes Cluster (Prometheus)-1577674936972.json"和 “Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json”
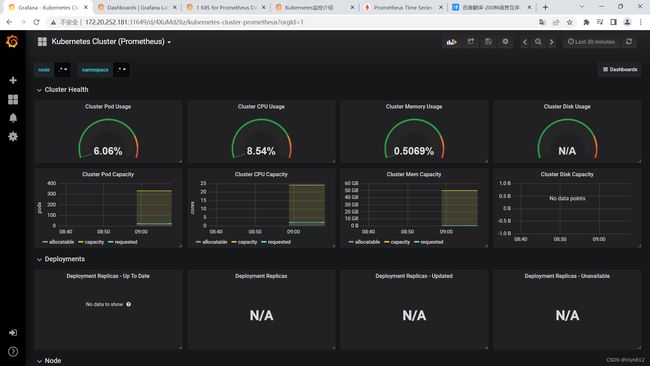
N/A错误排查思路
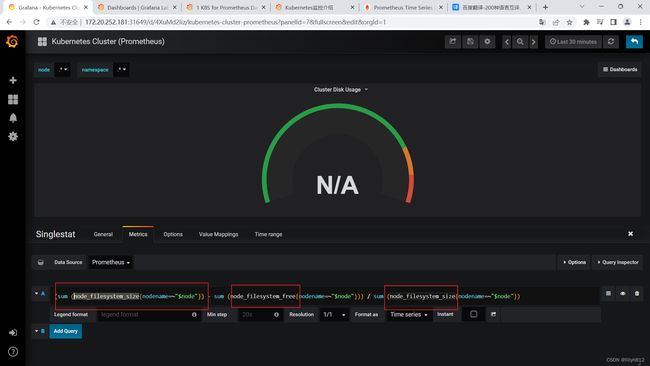
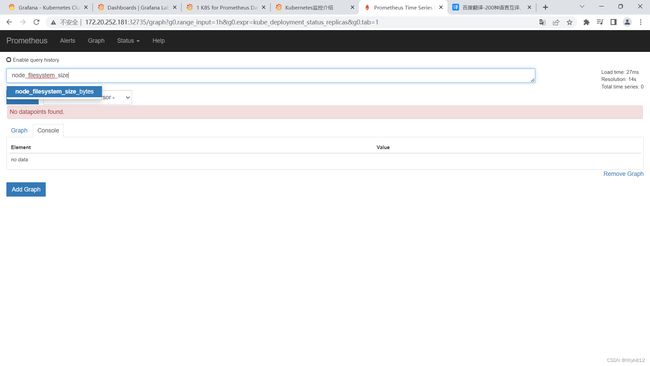

可以看到N/A已经变成正常采集到的数据
Alertmanager配置详解
配置alertmanager–发送报警
报警: 指prometheus将检测到的异常事件发送给alertmanager
通知: alertmanager将报警信息发送到邮件,微信,钉钉等
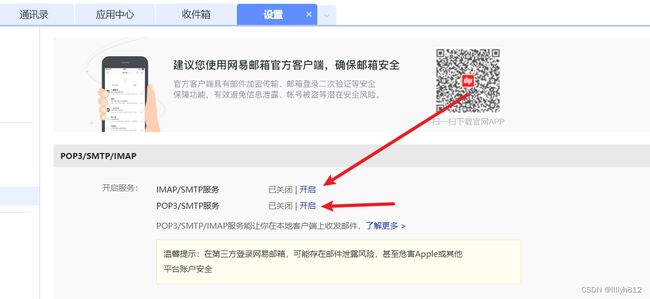
将上述服务开启
[root@k8s-master01 prometheus+alertmanager-resources]# grep global alertmanager-cm.yaml -A5
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
# 163邮箱的SMTP服务器地址+端口
smtp_from: '15××××××××@163.com'
# 这是指定从哪个邮箱发生告警
smtp_auth_username: '15×××××××××'
# 这是发送邮箱的认证用户,不是邮件名
smtp_auth_password: 'BGWHYUOS××××××××'
# 这是发送邮箱的授权码而不是登录密码
# 将上述内容替换为自己想要发送告警邮件的账户邮箱
[root@k8s-master01 prometheus+alertmanager-resources]# grep email_configs alertmanager-cm.yaml -A1
email_configs:
- to: '19×××××××××@qq.com'
# 用于接收告警邮件的邮箱
# 将上述内容替换为自己想要接收告警邮件的账户邮箱
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f alertmanager-cm.yaml
configmap/alertmanager created
# 应用YAML文件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get configmap -n monitor-sa |grep alert
alertmanager 1 15s
Prometheus触发告警流程
需要理解

同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里由alertmanager的route路由规则进行配置
监控etcd组件
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/192.168.40.180/172.20.252.181/g" prometheus-alertmanager-cfg.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/'192.168.40.181:10249'\]/'172.20.252.191:10249','172.20.252.192:10249'\]/g" prometheus-alertmanager-cfg.yaml
# 替换IP为自己的云主机IP地址
告警规则配置
[root@k8s-master01 prometheus+alertmanager-resources]# sed -n "178p" prometheus-alertmanager-cfg.yaml
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0
# 手动制造一个告警,将> 90改为> 0
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-alertmanager-cfg.yaml
configmap/prometheus-config configured
# 应用YAML文件,需要理解文件内容
Alertmanager发送报警到qq邮箱
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl delete -f prometheus-cfg.yaml
configmap "prometheus-config" deleted
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl create -f prometheus-alertmanager-cfg.yaml
configmap/prometheus-config created
# 之前的yaml文件没有rules.yml
[root@k8s-master01 prometheus+alertmanager-resources]# scp alertmanager.tar.gz k8s-node01:/root
alertmanager.tar.gz 100% 32MB 65.9MB/s 00:00
[root@k8s-master01 prometheus+alertmanager-resources]# scp alertmanager.tar.gz k8s-node02:/root
alertmanager.tar.gz 100% 32MB 104.9MB/s 00:00
# 传输镜像压缩包到工作节点
[root@k8s-node01 ~]# ctr -n k8s.io images import alertmanager.tar.gz
[root@k8s-node02 ~]# ctr -n k8s.io images import alertmanager.tar.gz
# 工作节点导入镜像
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/xianchaonode1/k8s-node02/g" prometheus-alertmanager-deploy.yaml
# 替换为自己的工作节点
这里不能替换为k8s-node02,详情见下方错误解决
应调度到k8s-node01
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/k8s-node02/k8s-node01/g" prometheus-alertmanager-deploy.yaml
# 修改调度为k8s-node01节点
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
secret/etcd-certs created
# 生成一个etcd-certs,这个在部署prometheus需要
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl delete -f prometheus-deploy.yaml
deployment.apps "prometheus-server" deleted
# 删除旧的deployment
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-alertmanager-deploy.yaml
deployment.apps/prometheus-server created
# 应用新的YAML文件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f alertmanager-svc.yaml
service/alertmanager created
# 创建service,需要理解yaml文件
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get svc -n monitor-sa |grep alert
alertmanager NodePort 10.108.21.13 <none> 9093:30066/TCP 2m22s
# 查看service
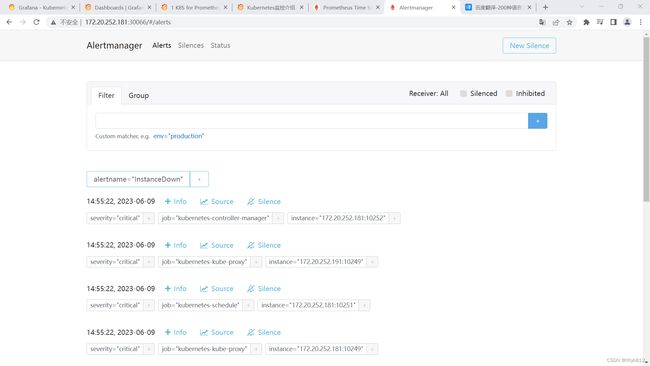
报错解决
本次报错解决方法基于询问chatgpt文件内容以及报错日志加上个人思路成功解决
[root@k8s-master01 ~]# kubectl get pods -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-c9gxc 1/1 Running 0 2d2h
node-exporter-nkvhb 1/1 Running 0 2d2h
node-exporter-zflh7 1/1 Running 0 2d2h
prometheus-server-bbc5986db-vf7zm 1/2 NotReady 5 (88s ago) 3m3s
[root@k8s-master01 ~]# kubectl describe pod prometheus-server-bbc5986db-vf7zm -n monitor-sa
Normal Started 20s kubelet Started container alertmanager
Normal Pulled 1s (x3 over 21s) kubelet Container image "prom/prometheus:v2.2.1" already present on machine
Normal Created 1s (x3 over 21s) kubelet Created container prometheus
Normal Started 1s (x3 over 20s) kubelet Started container prometheus
Warning BackOff 0s (x3 over 18s) kubelet Back-off restarting failed container prometheus in pod prometheus-server-bbc5986db-vf7zm_monitor-sa(7aea906d-1ae7-4013-a391-98a5364bdc3e)
[root@k8s-master01 ~]# kubectl logs prometheus-server-bbc5986db-vf7zm -n monitor-sa
level=error ts=2023-06-09T14:23:29.505932807Z caller=main.go:582 err="Opening storage failed open DB in /prometheus: open /prometheus/482935685: permission denied"
level=info ts=2023-06-09T14:23:29.50599337Z caller=main.go:584 msg="See you next time!"
# 这里会有这些报错是因为我们只在k8s-node01创建了data目录,部署在k8s-master02会导致找不到data目录导致无法挂载
# 因此我们改成调度到k8s-node01
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl delete -f prometheus-alertmanager-deploy.yaml
deployment.apps "prometheus-server" deleted
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl apply -f prometheus-alertmanager-deploy.yaml deployment.apps/prometheus-server created
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get pods -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-c9gxc 1/1 Running 0 2d2h
node-exporter-nkvhb 1/1 Running 0 2d2h
node-exporter-zflh7 1/1 Running 0 2d2h
prometheus-server-84b4f49c8c-9zf5t 2/2 Running 0 20s
# 可以看到pod正常running了
网页端口状态为down解决方法
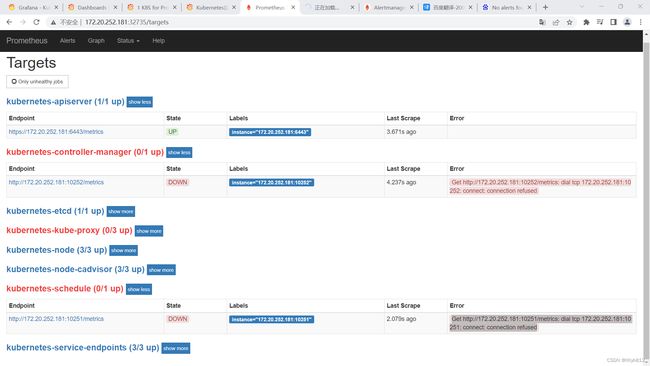
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/127.0.0.1/172.20.252.181/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/127.0.0.1/172.20.252.181/g" /etc/kubernetes/manifests/kube-scheduler.yaml
# 替换监控本机为指定ip
[root@k8s-master01 prometheus+alertmanager-resources]# systemctl restart kubelet
# 所有节点重启kubelet
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "https://127.0.0.1:10259/healthz": dial tcp 127.0.0.1:10259: connect: connection refused
controller-manager Unhealthy Get "https://127.0.0.1:10257/healthz": dial tcp 127.0.0.1:10257: connect: connection refused
etcd-0 Healthy {"health":"true","reason":""}
# 状态Unhealthy
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/172.20.252.181/127.0.0.1/g" /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/172.20.252.181/127.0.0.1/g" /etc/kubernetes/manifests/kube-
kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# sed -i "s/172.20.252.181/127.0.0.1/g" /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# systemctl restart kubelet
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
# 替换回来就Healthy,不知道为什么
邮件告警报错解决
[root@k8s-master01 prometheus+alertmanager-resources]# kubectl logs prometheus-server-84b4f49c8c-7zgrd -c alertmanager -n monitor-sa
level=debug ts=2023-06-10T06:41:34.420118006Z caller=notify.go:605 component=dispatcher msg="Notify attempt failed" attempt=1 integration=email receiver=default-receiver err=EOF
level=error ts=2023-06-10T06:41:34.420240641Z caller=notify.go:303 component=dispatcher msg="Error on notify" err=EOF
level=error ts=2023-06-10T06:41:34.420257671Z caller=dispatch.go:266 component=dispatcher msg="Notify for alerts failed" num_alerts=5 err=EOF
level=debug ts=2023-06-10T06:41:34.420333301Z caller=dispatch.go:429 component=dispatcher aggrGroup="{}:{alertname=\"InstanceDown\"}" msg=Flushing alerts="[InstanceDown[7116edc][active] InstanceDown[35a6665][active] InstanceDown[4a9b5ab][active] InstanceDown[f1add7c][active] InstanceDown[a4fa09b][active]]"
Alertmanager发送报警到钉钉群
[root@k8s-master01 prometheus+alertmanager-resources]# tar -zxvf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz -C /opt
prometheus-webhook-dingtalk-0.3.0.linux-amd64/
prometheus-webhook-dingtalk-0.3.0.linux-amd64/default.tmpl
prometheus-webhook-dingtalk-0.3.0.linux-amd64/prometheus-webhook-dingtalk
[root@k8s-master01 prometheus+alertmanager-resources]# cd /opt/prometheus-webhook-dingtalk-0.3.0.linux-amd64/
[root@k8s-master01 prometheus-webhook-dingtalk-0.3.0.linux-amd64]# nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --ding.profile="cluster1=https://oapi.dingtalk.com/robot/send?access_token=8377378c45a74f97676c7c93132c76f52a20ec02010a7a4365b26e5faa48a341" &
[root@k8s-master01 prometheus+alertmanager-resources]# cp alertmanager-cm.yaml alertmanager-dingding.yaml
[root@k8s-master01 prometheus+alertmanager-resources]# tail -n7 alertmanager-dingding.yaml
repeat_interval: 10m
receiver: cluster1
receivers:
- name: 'cluster1'
webhook_configs:
- url: 'https://oapi.dingtalk.com/robot/send?access_token=8377378c45a74f97676c7c93132c76f52a20ec02010a7a4365b26e5faa48a341'
send_resolved: true
# 修改为上述内容
Alertmanager发送报警到企业微信
prometheus PromQL语法
支持的数据类型有:
-
瞬时向量(Instant vector): 一组时序,每个时序只有一个采样值
-
区间向量(Range vector): 一组时序,每个时序包含一段时间内的多个采样值
-
标量数据(Scalar): 一个浮点数
-
字符串(String): 一个字符串,暂时未用
瞬时向量选择器
匹配标签纸可以是等于,也可以使用正则表达式.总共有下面几种匹配操作符:
- = 完全相等
- != 不相等
- =~ 正则表达式匹配
- !~ 正则表达式不匹配
container_processes{container=~"kube-scheduler|proxy|kube-apiserver"}
# 以当前为标准,瞬间的采样值
区间向量选择器
不支持Graph图表
apiserver_request_total{job="kubernetes-apiserver",resource="pods"}[1m]
# 以当前为标准,一分钟内的采样值
偏移向量选择器
apiserver_request_total{job="kubernetes-apiserver",resource="pods"} [5m] offset 1w
# 以当前为标准,在5分钟前的采样值
聚合操作符
sum: 求和
min: 最小值 …
sum(container_memory_usage_bytes{instance=~"k8s-master01"})/1024/1024/1024
# 计算k8s-master01节点所有容器总计内存
函数
abs(): 绝对值
sqrt(): 平方根 …
瞬时向量选择器
匹配标签纸可以是等于,也可以使用正则表达式.总共有下面几种匹配操作符:
- = 完全相等
- != 不相等
- =~ 正则表达式匹配
- !~ 正则表达式不匹配
container_processes{container=~"kube-scheduler|proxy|kube-apiserver"}
# 以当前为标准,瞬间的采样值
区间向量选择器
不支持Graph图表
apiserver_request_total{job="kubernetes-apiserver",resource="pods"}[1m]
# 以当前为标准,一分钟内的采样值
偏移向量选择器
apiserver_request_total{job="kubernetes-apiserver",resource="pods"} [5m] offset 1w
# 以当前为标准,在5分钟前的采样值
聚合操作符
sum: 求和
min: 最小值 …
sum(container_memory_usage_bytes{instance=~"k8s-master01"})/1024/1024/1024
# 计算k8s-master01节点所有容器总计内存
函数
abs(): 绝对值
sqrt(): 平方根 …