深入理解 python 虚拟机:破解核心魔法——反序列化 pyc 文件
深入理解 python 虚拟机:破解核心魔法——反序列化 pyc 文件
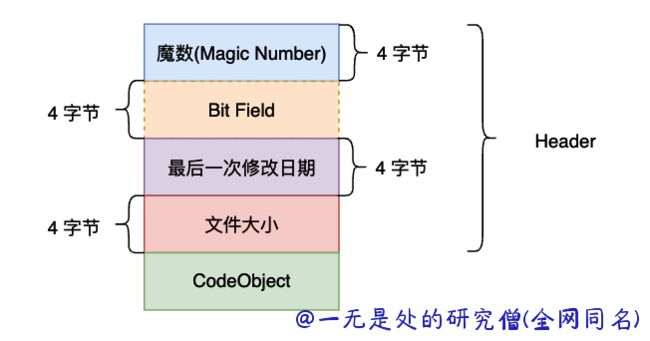
在前面的文章当中我们详细的对于 pyc 文件的结构进行了分析,pyc 文件主要有下面的四个部分组成:魔术、 Bite Filed 、修改日期和 Code Object 组成。在前面的文章当中我们已经对前面三个部分进行了字节角度的分析,直接从 pyc 文件当中读取对应的数据并且打印出来了。而在本篇文章当中我们将主要对 Code Object 进行分析,并且详细它是如何被反序列化的,通过本篇文章我们将能够把握整个 pyc 文件结构。
marshal 模块的魔力
序列化和反序列化 python 对象
marshal 是 python 自带的一个模块,他可以将一些 python 内置对象进行序列化和反序列化操作,甚至我们可以在一个文件当中序列话一个函数的 Code Object 对象,然后在另外一个文件反序列化这个 Code Object 对象并且执行它。
我们可以使用下面的代码将 python 当中的一些对象序列化操作,直接将 python 对边变成一个字节流,保存到磁盘当中:
import marshal
if __name__ == '__main__':
with open("pyobjects.bin", "wb") as fp:
marshal.dump(1, fp)
marshal.dump(1.5, fp)
marshal.dump("Hello World", fp)
marshal.dump((1, 2, 3), fp)
marshal.dump([1, 2, 3], fp)
marshal.dump({1, 2, 3}, fp)
marshal.dump(1+1j, fp)
marshal.dump({1: 2, 3: 4}, fp)
在上面的代码当中需要注意的是需要使用二进制方式 rb 打开文件,上面的程序执行完成之后会生成一个 pyobjects.bin 的二进制文件,我们可以使用 python 代码再将上面的 python 对象,比如整数、浮点数、字符串和列表元组等等反序列化出来。
import marshal
if __name__ == '__main__':
with open("pyobjects.bin", "rb") as fp:
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
print(marshal.load(fp))
上面的代码输出结果如下所示:
1
1.5
Hello World
(1, 2, 3)
[1, 2, 3]
{1, 2, 3}
(1+1j)
{1: 2, 3: 4}
从上面代码的输出结果我们可以看到我们可以将所有的被写入到二进制文件当中的数据全部解析了出来。
序列化和反序列化 CodeObject
除了上面使用 marshal 对 python 的基本对象进行序列化和反序列化,我们可以使用 marshal 模块对 CodeObject 进行同样的操作,如果是这样的话,那么就可以将一个文件的代码序列化,然后另外一个程序反序列化再进行调用:
import marshal
def add(a, b):
print("Hello World")
return a+b
with open("add.bin", "wb") as fp:
marshal.dump(add.__code__, fp)
在上面的代码当中,我们打开了文件 add.bin 然后将 add 函数的 CodeObject 对象写入到文件当中去,而 CodeObject 当中保存了函数 add 的所有执行所需要的信息,因此我们可以在另外一个文件当中打开这个文件,然后将 CodeObject 对象反序列化出来在执行这个代码,我们看下面的代码:
import marshal
def name():
pass
with open("add.bin", "rb+") as fp:
code = marshal.load(fp)
name.__code__ = code
print(name(1, 2))
上面的代码执行结果如下所示:
Hello World
3
可以看到反序列化之后的函数 add 复制到了 name 上,然后我们调用了函数 name 真的实现了打印和相加的效果,从这一点来看确实实现了我们在前面所提到的效果。
Python 对象反序列化
在本节当中将主要分析 python 对象序列化之后的二进制文件格式,我们到底应该如何解析这个文件,解析文件的规则是什么。在 cpython 当中对于每个数据类型的解析都是不一样的,marshal 支持 python 当中所有的基本数据类型,额外还支持 CodeObject ,在上面的验证代码当中我们已经使用 marshal 去做了一些序列化和反序列化操作。
在对 python 对象进行序列化的时候,每一个 python 对象主要是由两个部分组成的:

其中 type 占一个字节,用于表示接下里啊的 python 的对象类型,比如如字典、元组、集合之类的,而后面的 PyObject 就是实际的 python 数据类型了,需要注意的是对于 None、False、True 这种在虚拟机当中只有一个备份的对象,PyObject 是没有的,也就只有 type 这一个字段。
type 的种类具体如下所示,它只占用一个字节:
class TYPE(Enum):
TYPE_NULL = ord('0')
TYPE_NONE = ord('N')
TYPE_FALSE = ord('F')
TYPE_TRUE = ord('T')
TYPE_STOPITER = ord('S')
TYPE_ELLIPSIS = ord('.')
TYPE_INT = ord('i')
TYPE_INT64 = ord('I')
TYPE_FLOAT = ord('f')
TYPE_BINARY_FLOAT = ord('g')
TYPE_COMPLEX = ord('x')
TYPE_BINARY_COMPLEX = ord('y')
TYPE_LONG = ord('l')
TYPE_STRING = ord('s')
TYPE_INTERNED = ord('t')
TYPE_REF = ord('r')
TYPE_TUPLE = ord('(')
TYPE_LIST = ord('[')
TYPE_DICT = ord('{')
TYPE_CODE = ord('c')
TYPE_UNICODE = ord('u')
TYPE_UNKNOWN = ord('?')
TYPE_SET = ord('<')
TYPE_FROZENSET = ord('>')
FLAG_REF = 0x80
TYPE_ASCII = ord('a')
TYPE_ASCII_INTERNED = ord('A')
TYPE_SMALL_TUPLE = ord(')')
TYPE_SHORT_ASCII = ord('z')
TYPE_SHORT_ASCII_INTERNED = ord('Z')
我们接下来对上面的类型进行一一解释,首先我们需要了解下面几个方法,我们在后面的解析过程当中会使用到下面的内容:
class ByteStreamReader(object):
@staticmethod
def read_int(buf: bytes):
return struct.unpack(", buf)[0]
@staticmethod
def read_byte(buf):
return struct.unpack(", buf)[0]
@staticmethod
def read_float(buf):
return struct.unpack(", buf)[0]
@staticmethod
def read_double(buf):
return struct.unpack(", buf)[0]
@staticmethod
def read_long(buf):
return struct.unpack(", buf)[0]
上面的的几个函数主要是将字节变成 byte、int 或者浮点数。接下来我们会实现一个类 PyObjectLoader,用于对 marshal 序列化之后的文件进行解析。类的构造函数如下所示:
class PyObjectLoader(object):
def __init__(self, filename):
self.fp = open(filename, "rb")
self.flag = 0
self.refs = []
现在来对一个对象进行解析,根据我们前面谈到的内容首先我们需要读入一个字节的内容用于判断是那种数据类型:
def do_parse(self):
c = self.fp.read(1)
assert len(c) != 0, "can not read more data from file descriptor"
t = ByteStreamReader.read_byte(c) & (~TYPE.FLAG_REF.value)
self.flag = ByteStreamReader.read_byte(c) & TYPE.FLAG_REF.value
在上面的代码当中使用函数 do_parse 对一个 python 对象进行解析操作,使用到了 TYPE.FLAG_REF,这个字段的作用表示这个 python 对象是不是一个可引用的,除了 None 、True、False、StopIteration、Ellipsis 是不可引用对象,集合、字典、不可变集合、字符串、字节、CodeObject 等是可引用对象,可引用对象的 type 的最高位是 1(也就是 type 的第 8 个比特位是 1),非可引用对象就是 0 。如果是可引用对象需要将这个对象加入到引用列表当中,因为可能会存在一个对象引用其他对象的情况,需要将对象加入到引用队列当中,如果需要对对象进行引用操作直接使用下标从引用数组当中查找即可。所有的可引用对象在创建完成之后都需要加入到引用列表当中。
- TYPE_NULL,这个在 cpython 虚拟机当中就会直接返回 NULL 。
- TYPE_NONE,返回 python 对象 None 。
- TYPE_FALSE,返回 python 对象 False 。
- TYPE_TRUE,返回 python 对象 True 。
- TYPE_STOPITER,返回 StopIteration 对象。
- TYPE_ELLIPSIS,返回 对象 Ellipsis 。
- TYPE_INT,如果是这个数据类型表示接下来的 4 个字节的数据是一个整数。
- TYPE_INT64,这个类型表示接下来的 8 个字节表示一个整数。
- TYPE_BINARY_FLOAT,浮点数对象,表示接下里啊的 8 个字节表示一个浮点数。
- TYPE_BINARY_COMPLEX,复数对象,表示接下来有两个 8 个字节的浮点数,分别表示实部和虚部。
- TYPE_STRING,这个表示一个 bytes 对象,接下来的四个字节表示一个整数 size ,整数 size 的含义表示还需要读取的字节个数,因此接下来的 size 个字节就是 bytes 对象的内容。
- TYPE_INTERNED,表示一个需要缓存到字符串常量池的字符串,解析方法和 TYPE_STRING 一样首先读取四个字节得到一个整数 size,然后在读取 size 个字节,表示字符串的内容,我们在 python 当中可以直接使用
.decode("utf-8")进行编码。 - TYPE_REF,表示需要引用一个对象,读取四个字节作为整数 size,然后从引用列表当中获取下标为 size 的对象。
- TYPE_TUPLE,表示一个元组,首先读取四个字节的数据得到一个整数 size ,然后使用 for 循环递归调用 do_parse 函数获取 size 的对象。
- TYPE_LIST,解析方式和 TYPE_TUPLE 一样,只不过返回列表对象。
- TYPE_DICT,这个解析的方式不断的调用 do_parse 函数,从 1 开始计数,奇数对象当作 key,偶数对象当中 val,直到遇到 NULL,跳出循环停止解析,这个类型可以直接看下面的解析代码,非常清晰。
- TYPE_CODE,这个类型表示一个 CodeObject 对象,见下面的解析代码,这部分代码可以结合 CodeObject 的字段分析,前面24 个字节表示整数对象,用于表示 CodeObject 的 6 个字段,接下来的是 8 个 PyObject 对象,因此需要调用 do_parse 函数进行解析,然后再解析一个 4 字节的整数表示第一行代码的行号,最后再读取一个 PyObject 对象。
- TYPE_UNICODE,表示一个字符串,读取方式和 TYPE_INTERNED 一样。
- TYPE_SET,前 4 个自己表示集合当中元素的个数 size,接下来使用 for 循环读取(调用 do_parse) size 的元素加入到集合当中。
- TYPE_FROZENSET,和 TYPE_SET 读取方式一样,只不过返回 frozen set 。
- TYPE_ASCII,和 TYPE_UNICODE 读取方式一样,也可以使用 utf-8 编码,虽然读取的是 ASCII 编码的字符,但是 utf-8 兼容 ASCII 因此也可以。
- TYPE_ASCII_INTERNED,和 TYPE_ASCII 解析方式一样。
- TYPE_SMALL_TUPLE,读取一个字节的数据表示元组当中的数据个数,然后读取对应个数的对象。
- TYPE_SHORT_ASCII,之前是读取四个字节作为长度,现在只读取一个字节作为字节个数。
- TYPE_SHORT_ASCII_INTERNED,和 TYPE_SHORT_ASCII 读取方式一样,只不过加入到字符串常量池子。
余下的对象的解析不在一一解释,大家可以直接看下方代码,都是比较清晰易懂的。
class PyObjectLoader(object):
def __init__(self, filename):
self.reader = ByteStreamReader()
self.fp = open(filename, "rb")
self.flag = 0
self.refs = []
def do_parse(self):
c = self.fp.read(1)
assert len(c) != 0, "can not read more data from file descriptor"
t = ByteStreamReader.read_byte(c) & (~TYPE.FLAG_REF.value)
self.flag = ByteStreamReader.read_byte(c) & TYPE.FLAG_REF.value
match t:
case TYPE.TYPE_NULL.value:
return None
case TYPE.TYPE_NONE.value:
return None
case TYPE.TYPE_FALSE.value:
return False
case TYPE.TYPE_TRUE.value:
return True
case TYPE.TYPE_STOPITER.value:
return StopIteration
case TYPE.TYPE_ELLIPSIS.value:
return Ellipsis
case TYPE.TYPE_INT.value:
ret = ByteStreamReader.read_int(self.fp.read(4))
self.refs.append(ret)
return TYPE.TYPE_INT, ret
case TYPE.TYPE_INT64.value:
ret = ByteStreamReader.read_long(self.fp.read(8))
self.refs.append(ret)
return TYPE.TYPE_INT64, ret
case TYPE.TYPE_FLOAT.value:
raise RuntimeError("Unsupported TYPE TYPE_FLOAT")
case TYPE.TYPE_BINARY_FLOAT.value:
ret = ByteStreamReader.read_double(self.fp.read(8))
self.refs.append(ret)
return TYPE.TYPE_FLOAT, ret
case TYPE.TYPE_COMPLEX.value:
raise RuntimeError("Unsupported TYPE TYPE_COMPLEX")
case TYPE.TYPE_BINARY_COMPLEX.value:
ret = complex(self.do_parse(), self.do_parse())
self.refs.append(ret)
return TYPE.TYPE_BINARY_COMPLEX, ret
case TYPE.TYPE_LONG.value:
raise RuntimeError("Unsupported TYPE TYPE_LONG")
case TYPE.TYPE_STRING.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = self.fp.read(size)
self.refs.append(ret)
return TYPE.TYPE_STRING, ret
case TYPE.TYPE_INTERNED.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_INTERNED, ret
case TYPE.TYPE_REF.value:
size = ByteStreamReader.read_int(self.fp.read(4))
return TYPE.TYPE_REF, self.refs[size]
case TYPE.TYPE_TUPLE.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = []
self.refs.append(ret)
for i in range(size):
ret.append(self.do_parse())
return TYPE.TYPE_TUPLE, tuple(ret)
case TYPE.TYPE_LIST.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = []
self.refs.append(ret)
for i in range(size):
ret.append(self.do_parse())
return TYPE.TYPE_LIST, ret
case TYPE.TYPE_DICT.value:
ret = dict()
self.refs.append(ret)
while True:
key = self.do_parse()
if key is None:
break
val = self.do_parse()
if val is None:
break
ret[key] = val
return TYPE.TYPE_DICT, ret
case TYPE.TYPE_CODE.value:
ret = dict()
idx = len(self.refs)
self.refs.append(None)
ret["argcount"] = ByteStreamReader.read_int(self.fp.read(4))
ret["posonlyargcount"] = ByteStreamReader.read_int(self.fp.read(4))
ret["kwonlyargcount"] = ByteStreamReader.read_int(self.fp.read(4))
ret["nlocals"] = ByteStreamReader.read_int(self.fp.read(4))
ret["stacksize"] = ByteStreamReader.read_int(self.fp.read(4))
ret["flags"] = ByteStreamReader.read_int(self.fp.read(4))
ret["code"] = self.do_parse()
ret["consts"] = self.do_parse()
ret["names"] = self.do_parse()
ret["varnames"] = self.do_parse()
ret["freevars"] = self.do_parse()
ret["cellvars"] = self.do_parse()
ret["filename"] = self.do_parse()
ret["name"] = self.do_parse()
ret["firstlineno"] = ByteStreamReader.read_int(self.fp.read(4))
ret["lnotab"] = self.do_parse()
self.refs[idx] = ret
return TYPE.TYPE_CODE, ret
case TYPE.TYPE_UNICODE.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_INTERNED, ret
case TYPE.TYPE_UNKNOWN.value:
raise RuntimeError("Unknown value " + str(t))
case TYPE.TYPE_SET.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = set()
self.refs.append(ret)
for i in range(size):
ret.add(self.do_parse())
return TYPE.TYPE_SET, ret
case TYPE.TYPE_FROZENSET.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = set()
idx = len(self.refs)
self.refs.append(None)
for i in range(size):
ret.add(self.do_parse())
self.refs[idx] = ret
return TYPE.TYPE_SET, frozenset(ret)
case TYPE.TYPE_ASCII.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_INTERNED, ret
case TYPE.TYPE_ASCII_INTERNED.value:
size = ByteStreamReader.read_int(self.fp.read(4))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_ASCII_INTERNED, ret
case TYPE.TYPE_SMALL_TUPLE.value:
size = ByteStreamReader.read_byte(self.fp.read(1))
ret = []
self.refs.append(ret)
for i in range(size):
ret.append(self.do_parse())
return TYPE.TYPE_SMALL_TUPLE, tuple(ret)
case TYPE.TYPE_SHORT_ASCII.value:
size = ByteStreamReader.read_byte(self.fp.read(1))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_SHORT_ASCII, ret
case TYPE.TYPE_SHORT_ASCII_INTERNED.value:
size = ByteStreamReader.read_byte(self.fp.read(1))
ret = self.fp.read(size).decode("utf-8")
self.refs.append(ret)
return TYPE.TYPE_SHORT_ASCII_INTERNED, ret
case _:
raise RuntimeError("can not parse " + str(t))
def __del_(self):
self.fp.close()
我们现在使用下面的代码生成一些二进制文件:
import marshal
def add(a, b):
print("Hello World")
return a+b
if __name__ == '__main__':
with open("add.bin", "wb") as fp:
marshal.dump(add.__code__, fp)
with open("int.bin", "wb") as fp:
marshal.dump(1, fp)
with open("float.bin", "wb") as fp:
marshal.dump(1.5, fp)
with open("tuple.bin", "wb") as fp:
marshal.dump((1, 2, 3), fp)
with open("set.bin", "wb") as fp:
marshal.dump({1, 2, 3}, fp)
with open("list.bin", "wb") as fp:
marshal.dump([1, 2, 3], fp)
with open("dict.bin", "wb") as fp:
marshal.dump({1: 2, 3: 4}, fp)
with open("code.bin", "wb") as fp:
marshal.dump(add.__code__, fp)
with open("string.bin", "wb") as fp:
marshal.dump("Hello World", fp)
当我们使用 marshal 对函数 add 的 code 进行序列化的时候实际上就是序列化一个 CodeObject 对象,这个对象的结果实际上和 pyc 的结构是一样的。
我们使用下面的代码进行反序列化:
if __name__ == '__main__':
assert sys.version_info.major == 3 and sys.version_info.minor == 10, "only python3.10 works"
loader = PyObjectLoader("int.bin")
print(loader.do_parse())
loader = PyObjectLoader("float.bin")
print(loader.do_parse())
loader = PyObjectLoader("set.bin")
print(loader.do_parse())
loader = PyObjectLoader("dict.bin")
print(loader.do_parse())
loader = PyObjectLoader("tuple.bin")
print(loader.do_parse())
loader = PyObjectLoader("list.bin")
print(loader.do_parse())
loader = PyObjectLoader("string.bin")
print(loader.do_parse())
loader = PyObjectLoader("code.bin")
pprint(loader.do_parse())
需要注意的是本篇文章代码需要在 python 3.10 上运行,如果需要在 3.8 3.9 运行的话可以将 match 语句改成 if-else 语句。但是由于 python 3.11 当中的 CodeObject 对象的字段发生了一些微小的变化,因此上面的代码是不能在 python 3.11 上执行的。上面的代码执行结果如下所示:
(<TYPE.TYPE_INT: 105>, 1)
(<TYPE.TYPE_FLOAT: 102>, 1.5)
(<TYPE.TYPE_SET: 60>, {(<TYPE.TYPE_INT: 105>, 1), (<TYPE.TYPE_INT: 105>, 2), (<TYPE.TYPE_INT: 105>, 3)})
(<TYPE.TYPE_DICT: 123>, {(<TYPE.TYPE_INT: 105>, 1): (<TYPE.TYPE_INT: 105>, 2), (<TYPE.TYPE_INT: 105>, 3): (<TYPE.TYPE_INT: 105>, 4)})
(<TYPE.TYPE_SMALL_TUPLE: 41>, ((<TYPE.TYPE_INT: 105>, 1), (<TYPE.TYPE_INT: 105>, 2), (<TYPE.TYPE_INT: 105>, 3)))
(<TYPE.TYPE_LIST: 91>, [(<TYPE.TYPE_INT: 105>, 1), (<TYPE.TYPE_INT: 105>, 2), (<TYPE.TYPE_INT: 105>, 3)])
(<TYPE.TYPE_SHORT_ASCII: 122>, 'Hello World')
(<TYPE.TYPE_CODE: 99>,
{'argcount': 2,
'cellvars': (<TYPE.TYPE_REF: 114>, 'print'),
'code': (<TYPE.TYPE_STRING: 115>,
b't\x00d\x01\x83\x01\x01\x00|\x00|\x01\x17\x00S\x00'),
'consts': (<TYPE.TYPE_SMALL_TUPLE: 41>,
(None, (<TYPE.TYPE_SHORT_ASCII: 122>, 'Hello World'))),
'filename': (<TYPE.TYPE_SHORT_ASCII: 122>,
'/Users/xxxxxxx/Desktop/workdir/dive-into-cpython/code/marshal_demos/add.py'),
'firstlineno': 5,
'flags': 67,
'freevars': (<TYPE.TYPE_SMALL_TUPLE: 41>, ()),
'kwonlyargcount': 0,
'lnotab': (<TYPE.TYPE_STRING: 115>, b'\x08\x01\x08\x01'),
'name': (<TYPE.TYPE_SHORT_ASCII_INTERNED: 90>, 'add'),
'names': (<TYPE.TYPE_SMALL_TUPLE: 41>,
((<TYPE.TYPE_SHORT_ASCII_INTERNED: 90>, 'print'),)),
'nlocals': 2,
'posonlyargcount': 0,
'stacksize': 2,
'varnames': (<TYPE.TYPE_SMALL_TUPLE: 41>,
((<TYPE.TYPE_SHORT_ASCII_INTERNED: 90>, 'a'),
(<TYPE.TYPE_SHORT_ASCII_INTERNED: 90>, 'b')))})
从上面的解析结果来看我们是实现了正确的解析的。
总结
在本篇文章当中主要给大家分析了 python 对象序列化之后我们该如何反序列化这些对象,并且使用 python 对二进制文件进行了分析,可以成功的将 python 对象解析出来,但是我们忽略了两个稍微复杂一点的对象,他们的解析稍微有点复杂,但是我们平时的变成当中很少使用到,因此本文的代码解析一般的文件都是可以的。
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址:https://github.com/Chang-LeHung/dive-into-cpython
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。