Spring实例化源码解析之ClassPathBeanDefinitionScanner(五)
Spring实例化源码解析之ClassPathBeanDefinitionScanner(五)
上一章我们分析了ComponentScanAnnotationParser,主要就是分析了@ComponentScan注解内的属性和属性的作用,而注解解析的信息会交给ClassPathBeanDefinitionScanner扫描器使用,也就是本章需要分析的内容。话不多说,直接进入正题。
doScan(String… basePackages)
首先入口就是doScan方法,我们按照规矩还是从注释开始。
在指定的基础包中执行扫描,并返回注册的 Bean 定义。该方法不会注册注解配置处理器,而是将这个责任留给调用者。
解释如下:
-
“Perform a scan within the specified base packages, returning the registered bean definitions.”:在指定的基础包中执行扫描,即扫描这些包及其子包中的类文件,以查找与 Spring 相关的注解(例如
@Component、@Service、@Repository等)标记的类,这些都是上一章节的内容。扫描的结果将会得到注册为 Bean 的定义。 -
“This method does not register an annotation config processor”:这个方法不会注册注解配置处理器。注解配置处理器是负责解析和处理注解配置的组件,例如
@Configuration、@Bean、@ComponentScan等。通常,在 Spring 中会有一个注解配置处理器负责处理这些注解,并将它们转换为相应的 Bean 定义。但是,这个方法并不包含这个处理器的注册过程。@Configuration、@Bean第二章也有分析和介绍。 -
“but rather leaves this up to the caller.”:相反,这个方法将这个责任留给调用者。也就是说,调用者需要自己处理注解配置,包括注册注解配置处理器和执行相应的解析和处理过程。
总结起来,这段话的意思是,该方法提供了执行扫描并返回注册的 Bean 定义的功能,但不包含具体的注解配置处理过程,这个过程需要由调用者自行处理。调用者需要负责注册注解配置处理器,并执行相应的解析和处理操作,以确保扫描到的注解配置能够正确地转换为相应的 Bean 定义。
/**
* Perform a scan within the specified base packages,
* returning the registered bean definitions.
* This method does not register an annotation config processor
* but rather leaves this up to the caller.
* @param basePackages the packages to check for annotated classes
* @return set of beans registered if any for tooling registration purposes (never {@code null})
*/
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
// 这里面的代码看起来很简单,但是他应该是处理了@ComponentScan注解里的所有属性
Assert.notEmpty(basePackages, "At least one base package must be specified");
// 存储所有扫描并注册好的beanDefinitions,set集合
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 我加的,用于输出注释,源码中忽略。
AtomicInteger index = new AtomicInteger();
for (String basePackage : basePackages) {
// 包含过滤器的使用在此
// 根据名称 查询候选的Components,根据包路径,返回的是Bean定义信息集合,所以核心在此。
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 在这里就把我们需要spring管理的类组装BeanDefinition,放到了(BeanDefinitionRegistry)BeanFactory中
System.out.println("当前加载的beanName:"+beanName);
index.addAndGet(1);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
System.out.println("当前加载的所有beanName的个数为:"+ index);
return beanDefinitions;
}
根据方法的源码来看,for循环中的findCandidateComponents方法就是其核心方法。打端点可以看到candidates返回的就是我们自定义的这些bean的定义信息。
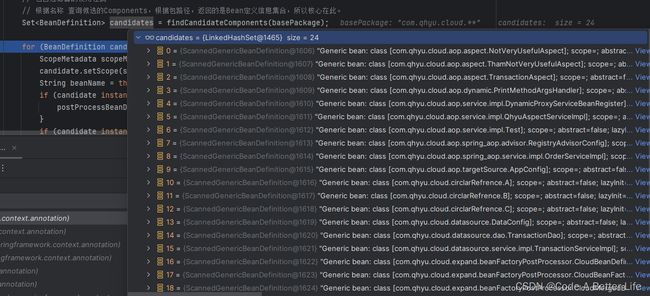
findCandidateComponents
查询候选的Component修饰的class,从方法名称就能判断出其干了什么,spring源码中的方法定义的还是非常优秀。basePackage来源于我的AopConfig类中的注解。默认情况下componentsIndex为null,也就是说默认会走else逻辑。
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 这个basePackage来源于注解类AopConfig
// componentsIndex不知道是什么,应该是一个扩展点,因为spring启动在这里打断点,此处为null
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 默认走这里
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents
scanCandidateComponents方法就是去扫描,根据basePackage去组装包的搜索路径,也就是我们想要被spring管理的bean的路径,然后根据路径去获取resources。
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 根据basePackage组装包的搜索路径,当前是classpath*:com.qhyu.cloud.**/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 获取资源数据,就是具体到文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
// 所以我们平常的日志需要打开trace和debug日志,至少在开发过程中需要这么做
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
// 通过resource获取到元数据
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 通过元数据判断是不是候选component,所以此处是核心
// 此处用到了排除过滤器和包含过滤器
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (FileNotFoundException ex) {
if (traceEnabled) {
logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
根据basePackage组装的包搜索路径,获取到文件资源。
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath)

拿到所有的resources之后循环判断是不是候选的Component类,如果是就执行candidates.add。
isCandidateComponent
这里就使用到了排除过滤器和包含过滤器。作用是根据给定的 MetadataReader 对象,结合排除过滤器和包含过滤器,判断该组件是否符合候选组件的条件。过滤器可以用于排除或包含特定的组件类型或特征,以实现组件的筛选和过滤。
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
如果和excludeFilters有匹配就直接返回false,并且至少与一个includeFilters匹配,同时需要满足没有@Condition注解。
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
判断注解元数据是否符合候选组件的条件,返回布尔值。
- metadata.isIndependent(): 判断注解元数据表示的类是否是独立的,即不依赖于其他类。如果是独立的,则继续下面的判断条件。
- metadata.isConcrete(): 判断注解元数据表示的类是否是具体的类,即非抽象类。如果是具体类,则返回 true。
- (metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName())): 判断注解元数据表示的类是否是抽象类,并且是否具有被 @Lookup 注解标注的方法。如果是抽象类且具有 @Lookup 注解的方法,则返回 true。
registerBeanDefinition
拿到了bean的定义信息之后,就往工厂DefaultListableBeanFactory中注册,也就是put进beanDefinitionMap中。
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
// lazyinit在这里,getBean之后才用
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 设置beanDefinition的属性信息,后续用
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
// 组装holder
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 在这里就把我们需要spring管理的类组装BeanDefinition,放到了(BeanDefinitionRegistry)BeanFactory中
System.out.println("当前加载的beanName:"+beanName);
index.addAndGet(1);
//DefaultListableBeanFactory中的beanDefinitionMap中
registerBeanDefinition(definitionHolder, this.registry);
}
}
这段代码是一个循环遍历,对一组候选的 BeanDefinition 进行处理和注册。让我们逐行进行分析:
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
解析候选的 BeanDefinition 的作用域(scope)元数据。candidate.setScope(scopeMetadata.getScopeName());
设置候选的 BeanDefinition 的作用域为解析得到的作用域名称。String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
使用 BeanNameGenerator 生成候选 BeanDefinition 的唯一名称。if (candidate instanceof AbstractBeanDefinition) { ... }
如果候选的 BeanDefinition 是 AbstractBeanDefinition 的实例,执行下面的代码块。postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
对 AbstractBeanDefinition 进行后处理,例如设置懒加载等属性。
if (candidate instanceof AnnotatedBeanDefinition) { ... }
如果候选的 BeanDefinition 是 AnnotatedBeanDefinition 的实例,执行下面的代码块。AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
处理通用的注解定义,例如处理@Lazy、@Primary、@DependsOn等注解。
if (checkCandidate(beanName, candidate)) { ... }
检查候选 BeanDefinition 是否符合要求,即是否满足注册的条件。BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
创建一个 BeanDefinitionHolder 对象,用于持有候选 BeanDefinition 和其对应的名称。definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
根据作用域元数据,应用相应的代理模式(如创建作用域代理)。beanDefinitions.add(definitionHolder);
将 BeanDefinitionHolder 添加到 beanDefinitions 集合中,用于后续的处理。registerBeanDefinition(definitionHolder, this.registry);
将 BeanDefinition 注册到 BeanDefinitionRegistry 中,即将其添加到 BeanFactory 的 beanDefinitionMap 中,以便后续的获取和使用。
该代码片段的作用是将一组候选的 BeanDefinition 进行处理和注册,将它们转化为完整的 BeanDefinition,并添加到 BeanFactory 中以便后续的实例化和管理。在处理过程中,会解析作用域元数据、生成唯一的 Bean 名称、处理注解定义、应用代理模式等操作,以确保注册的 BeanDefinition 符合预期的配置和行为。
总结
至此,我们所有需要被spring管理的bean的定义信息都被注册到工厂中,后续bean的初始化实例化都是后续的工作了。invokeBeanFactoryPostProcessors(beanFactory)这句代码就分析了五章,后续将开始BeanFactoryPostProcessors的注册源码分析。