二叉树和堆初识
二叉树
目录
二叉树
1.树概念及结构
2.二叉树概念及结构
3.二叉树顺序结构及实现
1.树概念及结构
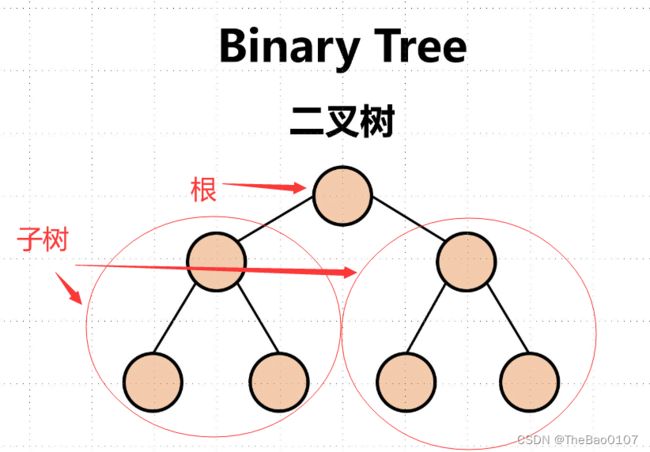
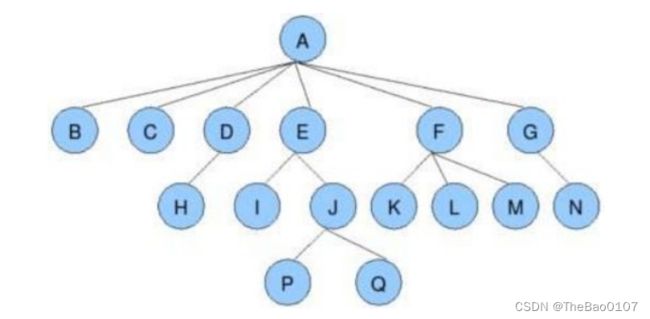
树的表示
typedef int DataType;
struct TreeNode
{
DataType data;
struct TreeNode* firstChild1;//第一个(最左边)孩子节点 ,如果没孩子了就指向NULL;
struct TreeNode* pNextBrother;//指向兄弟 ,如果没兄弟了就指向NULL;
};
这个方法很巧妙,只管一个孩子,其他孩子交给这个孩子去管理--->孩子兄弟表示法(左孩子右兄弟)
二叉树:
树的度为2:计划生育.(二叉树不存在度大于2的结点)
我们可以看到这其实是个链式结构(二叉链),后面我们还会学三叉链(多了一个指向parent的链子)
2.二叉树概念及结构

注意:
1.二叉树不存在度大于2的节点
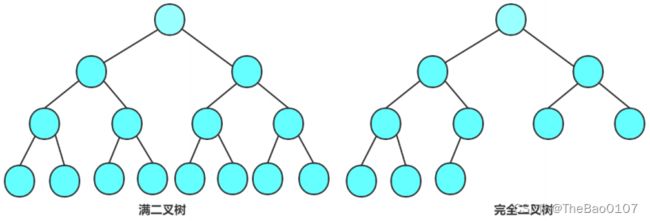

另外,当二叉树为完全二叉树时,一般用顺序存储比较好,因为可以避免空间的浪费。
注意:
当二叉树顺序存储时:
leftchild = parent*2+1;
rightchild = parent*2+2;
parent = (child-1)/2;
3.二叉树顺序结构及实现
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;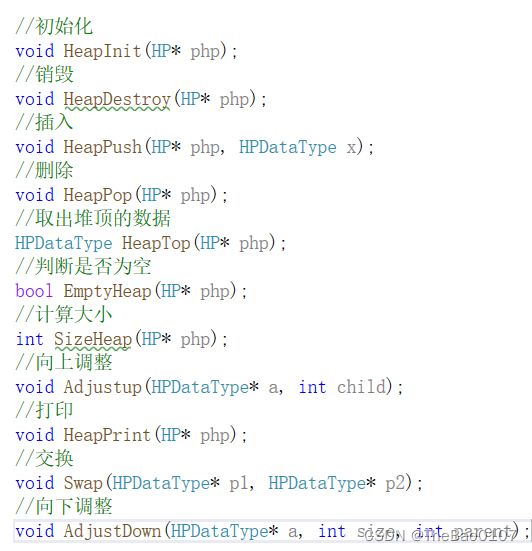
这里我们省略较简单的那些,来看看下面这几个比较特殊的
插入:
插入是插在堆底的
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
int newCapacity = php->capacity == 0 ? 4 : 2 * (php->capacity);
HPDataType* temp = (HPDataType*)realloc(php->a, newCapacity * sizeof(HPDataType));
if (temp == NULL)
{
perror("realloc");
exit(-1);
}
php->a = temp;
php->capacity = newCapacity;
}
php->a[php->size] = x;
php->size++;
//因为插入的数据有可能会影响祖先,所以我们需要在做一个函数:向上调整
Adjustup(php->a, php->size - 1);
}至此和顺序表的插入无异,但是下面这个“向上调整”才是重头戏
先上代码:
void Adjustup(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}向上调整的思路是:(对于小堆),如果所插入的儿子比爸爸小,那么就把儿子和爸爸交换,向上继续调整。如果儿子比爸爸大,那么堆就已经形成好了
通过对于堆性质的理解,我们可以得到parent = (child-1)/2,进而得到第一个parent。
极端情况:插入的这个儿子比所有的爸爸都大,这个时候临界情况就是拿他和作为根的爸爸比较再进行判断交不交换,做完这个动作,就该停止调整了。
同样的 我们来看看删除:
堆的删除一般情况下就是删除堆顶的数据,删除堆尾部的数据较简单也没必要
//删除
void HeapPop(HP* php)
{
assert(php);
assert(php->size > 0);
Swap(&(php->a[0]), &(php->a[php->size - 1]));
php->size--;
AdjustDown(php->a, php->size, 0);//向下调整
//这里想要删除堆顶的数据(根),不能直接前挪覆盖
//可以直接吧第一个跟最后一个交换一下,把size直接--,就删掉了
//剩下的数虽然构成不是一个堆,但是可以向下调整,因为这里左子树和右子树都是小堆,所以效率很高
//向下调整:(小堆情况)兄弟之间比大小,谁小谁上去。
}这里的精华也就在于 向下调整
void AdjustDown(HPDataType * a,int size,int parent)
{
//思路:先选出左右孩子中小的那个,然后将这小的孩子和父亲比较,如果比父亲小,就交换,继续向下调整,如果比父亲大,调整结束
int childleft = parent * 2 + 1;
int childright = parent * 2 + 2;
int childlittle = a[childleft] < a[childright] ? childleft : childright;
while (childleft < size)
{
if (childright >= size)//防止出现只有左孩子没有右孩子的情况
{
childlittle = childleft;//当只有左孩子没有右孩子时,小孩子就是左孩子了。
}
if (a[childlittle] < a[parent])//把小孩子和父亲比较,如果比父亲小,就交换,继续向下调整。如果比父亲大,调整结束
{
Swap(&a[childlittle], &a[parent]);
parent = childlittle;
childleft = parent * 2 + 1;
childright = parent * 2 + 2;
childlittle = a[childleft] < a[childright] ? childleft : childright;
}
else
break;
}
}这里我们的思路分为这几个步骤:
1、先把堆顶的节点和堆底节点互换,然后再删除(类似于顺序表的尾删)
2.删除之后对剩余的节点向下调整:先找出父节点的两个孩子中的小的那个(小孩子),再拿小孩子和父亲比较,如果比父亲小,那就交换并继续向下调整;如果比父亲大,那就意味着两个孩子都比父亲大,那堆就已经形成了,调整完毕。
3.注意这里的临界条件是:左孩子到达了堆的底不(顺序表的size-1处也就是最后),这时没有右孩子,这时完成最后一次调整就结束调整
由于大堆、小堆都是对于堆顶元素而建立的,所以我们取堆元素就是取得其堆顶元素。
实现:
HPDataType HeapTop(HP* php)
{
assert(php);
return php->a[0];
}那么,堆的价值在哪里呢?
答:堆的价值在于——选树。
//void HeapSort(int* a, int n)//这样可以用堆来把数组排成有序数组 就是 堆排序
//{/*
// HP hp;
// HeapInit(&hp);
// for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
// {
// HeapPush(&hp, a[i]);
// }
// int i = 0;
// while (!EmptyHeap(&hp))
// {
// a[i++] = HeapTop(&hp);
// HeapPop(&hp);
// }
// HeapDestroy(&hp);*/
// //这样写 有两个缺点: 1.你得自己写一个堆的数据结构然后带入 工程量太大 2.空间复杂度太大O(n)
//}
void HeapSort(int* a, int n)
{
//直接吧数组建成一个堆
//建堆:有两种方式:1.从下往上2.从上往下
//从下往上
//for (int i = 1; i < n; i++)
//{
// Adjustup(a, i);
//}
//从上往下
//向下调整的前提是左子树和右子树都是堆,可是现在他们不满足这个条件。
//因此只能从倒数第一个非叶节点开始调
for (int i = ((n-1)-1)/2; i >= 0; i--)
{
AdjustDown(a,n, i);
}
}
int main()
{
HP hp;
HeapInit(&hp);
int a[] = { 30,27,26,17,13,23,11,9,5,6 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
HeapPush(&hp,a[i]);
}
HeapPrint(&hp);
///
HeapPop(&hp);
HeapPrint(&hp);
//想要升序打印或者降序打印呢?
//可以这样
while (!EmptyHeap(&hp))
{
printf("%d ", HeapTop(&hp));
HeapPop(&hp);//这就是升序打印 如果hp是大堆,那就是降序打印
}
return 0;
}用向下调整的理由:空间复杂度较小