RabbitMQ核心知识
本文包含以下内容,总结了一些 RabbitMQ 的核心知识,让你快速熟悉起 RabbitMQ,如有遗漏或有误,非常感激能在评论区中指出来。
一、基本概念、优缺点
二、特点之 Exchange 类型
三、消息丢失场景分析和解决方案
四、持久化
五、高可用之镜像队列
六、重复消费
七、消费端限流
八、死信队列
一、基本概念
1、Message :由消息头和消息体组成,消息体是不透明的,而消息头则是由一系列的可选参数组成,这些属性包括 routing-key、priorty(优先级,优先被消费),delivery-mode(是否持久性存储)等。
2、Publisher:消息生产者
3、Binding:将 Exchange 和 Queue 关联,这样 Exchange 就知道消息路由到哪个 Queue 中。
4、Queue:存储消息,队列的特性是先进先出。一个消息可分发到一个或多个队列。
5、Virtual host :每个 vhost 本质上就是一个 mini 版 的 RabbitMQ 服务器,拥有自己的队列、交换机、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接是指定,RabbitMQ 默认的 vhost 是 /。当不同的用户使用同一个 RabbitMQ server 提供的服务时,可以划分多个vhost ,每个用户在自己的 vhost 创建 Exchange 和 Queue。
——多个用户使用同一消息队列,可以使用这个进行管理
6、Broker :消息队列服务器的实体。
缺点:
elang 开发不利于二次开发和维护;性能较 kafka 差,持久化消息和 ACK 确认的情况下生产和消费消息吞吐量大约在 1-2 W左右,kafka 的单机吞吐量在 10 W 级别。
优点:
有管理界面,方便使用,可靠性高,功能丰富,支持消息持久化,消息确认机制,多种分发机制。
二、特点之 Exchange 类型
目前四种:direct,fanoout ,topic ,headers
direct :定向,指定 route-key 全匹配,Binding 的交换机和消息队列,以及指定的 route-key 全匹配才会分发。
fanout:广播,有绑定在其交换机的队列都会受到。(消息最快)
topic:可以模糊匹配,route-key 使用「#」匹配多个单词,「*」匹配一个单词
headers:同 direct ,指定关系由 Message 的 headers 属性路由决定。性能较差,一般不使用。
三、消息丢失场景分析和解决方案
1、外界环境问题导致:网络丢包,网络故障。
——解决方案:生产者确认机制。
2、代码层面,配置层面,考虑不完整导致。
如
(1)原生Mq 操作的交换机、队列没有持久化(AQMQ 有默认持久化)
(2)没有与交换机路由的队列,或是队列无处理等。
(3)代码实现处理未完成,错误未完成消费。
——解决方案
(1)针对消息确认机制,是否发送到 Exchange
#配置增加
spring.rabbitmq.publisher-confirms=true。
#代码:
#定义确认机制的异常处理。
final RabbitTemplate.ConfirmCallback confirmCallback = (CorrelationData correlationData, boolean ack, String cause) -> {
log.info("correlationData: " + correlationData);
log.info("ack: " + ack);
if(!ack) {
log.info("异常处理....");
}
};
#设置 ack 处理犯法
rabbitTemplate.setConfirmCallback(confirmCallback);
(2)Return 消息机制,路由不可达处理方式一
#配置参数
spring.rabbitmq.template.mandatory=true
#代码
final RabbitTemplate.ReturnCallback returnCallback = (Message message, int replyCode, String replyText, String exchange, String routingKey) ->
//若是交换机没有找到对应的路由的队列就会进行回调,正常不进入
//日志数据:return exchange: mytopic, routingKey: unAckTest, replyCode: 312, replyText: NO_ROUTE
log.info("return exchange: " + exchange + ", routingKey: "
+ routingKey + ", replyCode: " + replyCode + ", replyText: " + replyText);
#发起时设置回调。
rabbitTemplate.setReturnCallback(returnCallback);
(3)备份交换机。路由不可达处理方式一
设置一个备用的交换机,当原有的队列找不到时,就会转发到备用交换机。
利用备用的交换机绑定的队列进行处理,这个备用交换机是一个普通的交换机,类型常用:fanout
#创建 mytopic 并指定一个备用交换机。
Map<String, Object> args = new HashMap<>();
args.put("alternate-exchange", "alternate-exchange");
return ExchangeBuilder.topicExchange("mytopic").withArguments(args).build();
#常规创建 alternate-exchange 交换机即可
@Bean
public FanoutExchange alternateExchange(){
return new FanoutExchange("alternate-exchange");
}
tips:备用机和 mandatory 同时设置时,mandatory 无效。
(4)消费者手动消息确认。
确认消费成功,相对比于消息事务,选择此来操作更佳,注意消费失败的处理,避免消息堵塞。
#设置消费端手动 ack
spring.rabbitmq.listener.simple.acknowledge-mode=manual
@RabbitListener(queues = RabbitMqConfig.MAIL_QUEUE)
public void onMessage(MessageDTO dto,Message message, Channel channel) throws IOException {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
log.error("消费确认失败:{}",e);
}
long deliveryTag = message.getMessageProperties().getDeliveryTag();
//手工ack;第二个参数是multiple,设置为true,表示deliveryTag序列号之前(包括自身)的消息都已经收到,设为false则表示收到一条消息
//常设置为 false ,业务确认,false 确认本条的消息确认消费成功。
channel.basicAck(deliveryTag, true);
//basicNack(delivery,false,false);
//为不确认deliveryTag对应的消息,第二个参数是否应用于多消息,第三个参数是否requeue,与basic.reject区别就是同时支持多个消息,可以nack该消费者先前接收未ack的所有消息。nack后的消息也会被自己消费到。
//basicReject(deliveryTag,false);
//拒绝deliveryTag对应的消息,第二个参数是否requeue,true则重新入队列,否则丢弃或者进入死信队列。
//basicRecover(requeue);
//是否恢复消息到队列,参数是是否requeue,true则重新入队列,并且尽可能的将之前recover的消息投递给其他消费者消费,而不是自己再次消费。false则消息会重新被投递给自己。
}
四、持久化
1、消息持久化。发布消息前,设置投递模式 delivery mode 为 2 ,表示消息需要持久化。
点进 rabbitTemplate.convertAndSend(queue,mail); 中看到aqmq 的默认消息是持久化的

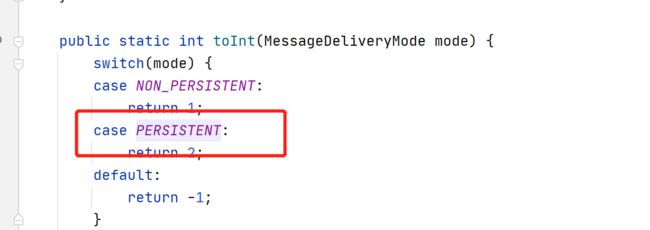
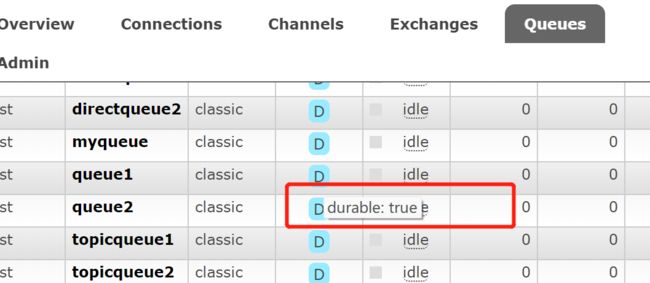
2、Queue 设置持久化,设置 durable=true,aqmq创建默认持久化。
3、交换机设置持久化,设置 durable=true,aqmq创建默认持久化。
查看自己设置的交换机、队列是否持久化,可以到管理台一探究竟。
以下就是成功的设置持久化,不信也可以重启 rabbitmq 尝试是否还存在。
五、高可用之镜像队列
1、设置 RabbitMQ 的高可用。
当 MQ 发生故障时,会导致服务不可用,将 Queue 分布到集群的其他点中,当节点不可用时,集群就会切换到其他节点,由于各个节点的都同样保存了 Queue ,所以服务不影响。
每个镜像对了都包括一个 master 和多个 slave。
2、问题:这并不是分布式,而是由每个镜像 copy master 的队列,也会存在存储的问题。
3、宕机反应
当slave宕掉了,除了与slave相连的客户端连接全部断开之外,没有其他影响。
当master宕掉时,会有以下连锁反应:
(1)与master相连的客户端连接全部断开;
(2)选举最老的slave节点为master。若此时所有slave处于未同步状态,则未同步部分消息丢失;
(3)新的master节点requeue所有unack消息,因为这个新节点无法区分这些unack消息是否已经到达客户端,亦或是ack消息丢失在老的master的链路上,亦或者是丢在master组播ack消息到所有slave的链路上。所以处于消息可靠性的考虑,requeue所有unack的消息。此时客户端可能有重复消息;
(4)如果客户端连着slave,并且Basic.Consume消费时指定了x-cancel-on-ha-failover参数,那么客户端会受到一个Consumer Cancellation Notification通知,Java SDK中会回调Consumer接口的handleCancel方法,故需覆盖此方法。如果未指定x-cancal-on-ha-failover参数,那么消费者就无法感知master宕机,会一直等待下去。
4、镜像队列的恢复
前提:两个节点A和B组成以镜像队列。
场景1:A先停,B后停
该场景下B是master,只要先启动B,再启动A即可。或者先启动A,再在30s之内启动B即可恢复镜像队列。(如果没有在30s内回复B,那么A自己就停掉自己)
场景2:A,B同时停
该场景下可能是由掉电等原因造成,只需在30s内联系启动A和B即可恢复镜像队列。
场景3:A先停,B后停,且A无法恢复。
因为B是master,所以等B起来后,在B节点上调用rabbitmqctl forget_cluster_node A以接触A的cluster关系,再将新的slave节点加入B即可重新恢复镜像队列。
场景4:A先停,B后停,且B无法恢复
该场景比较难处理,旧版本的RabbitMQ没有有效的解决办法,在现在的版本中,因为B是master,所以直接启动A是不行的,当A无法启动时,也就没版本在A节点上调用rabbitmqctl forget_cluster_node B了,新版本中forget_cluster_node支持-offline参数,offline参数允许rabbitmqctl在离线节点上执行forget_cluster_node命令,迫使RabbitMQ在未启动的slave节点中选择一个作为master。当在A节点执行rabbitmqctl forget_cluster_node -offline B时,RabbitMQ会mock一个节点代表A,执行forget_cluster_node命令将B提出cluster,然后A就能正常启动了。最后将新的slave节点加入A即可重新恢复镜像队列
场景5:A先停,B后停,且A和B均无法恢复,但是能得到A或B的磁盘文件
这个场景更加难以处理。将A或B的数据库文件($RabbitMQ_HOME/var/lib目录中)copy至新节点C的目录下,再将C的hostname改成A或者B的hostname。如果copy过来的是A节点磁盘文件,按场景4处理,如果拷贝过来的是B节点的磁盘文件,按场景3处理。最后将新的slave节点加入C即可重新恢复镜像队列。
场景6:A先停,B后停,且A和B均无法恢复,且无法得到A和B的磁盘文件
无解。
3,4点引用地址
六、重复消费
1、场景:(1)生产时消息重复(2)消费时重复。
2、产生原由
生产时重复情况:如网络抖动,MQ 确认没有被生产者收到重发。
消费时重复情况:网络抖动,消费成功后确认,MQ 没有收到,保证数据不丢失,重新发送。
3、解决方案:发送消息时让每个消息携带一个全局的唯一ID,在消费消息时先判断消息是否已经被消费过,保证消息消费逻辑的幂等性。具体消费过程为。
七、消费端限流
场景:当MQ 服务器积压大量消息时,队列里会出现大量消息涌入消费端,那就很可能导致消费端的服务器奔溃。
解决方案:设置 prefetch 限制 unack 的最大数量。
如:
spring.rabbitmq.listener.simple.prefetch=2
八、死信队列。
消费失败的消息存放的队列。
1、消费失败的原因:
(1)消息被拒绝,且消息没有重新进入队列(requeue=false)
(2)消息超时未消费
(3)达到最大队列长度
2、创建业务队列时,绑定死信队列,已创建 「dead-exchange」交换机和「dead-queue」队列
Map<String,Object> arguments = new HashMap<>(2);
// 绑定该队列到私信交换机
arguments.put("x-dead-letter-exchange", "dead-exchange");
arguments.put("x-dead-letter-routing-key", "dead-queue");
return new Queue(RabbitMqConfig.MAIL_QUEUE, true, false, false, arguments);
作用:
(1)避免业务代码出现的问题,导致业务未处理,导致丢失。
可以通过死信队列进行业务处理,或是存储排查后重新消费死信队列,恢复业务操作。
(2)延时队列,RabbitMQ 本身不支持延时,需要后续版本可用加载插件实现,在未处理可以通过死信队列作为延时队列操作。
在生产端发送消息的时候可以给消息设置过期时间,单位为毫秒(ms)
rabbitTemplate.convertAndSend(queue, msg, new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setExpiration("3000");
return message;
}
});