spark 使用python语言操作(基于pycharm的安装使用)
本文是关于如何使用pycharm下面执行spark相关操作,spark搭建的是单机模式。
1.安装单机模式的spark
1.1 下载spark
下载地址:https://archive.apache.org/dist/spark/

我选取的是spark-3.1.2-bin-hadoop3.2.tgz
1.2 上传压缩包
将下载好的spark压缩包通过xftp传输到hadoop102的/opt/module(集群节点)目录下面

直接拖到过去就行了
1.3 解压缩包
tar -zxvf spark压缩包 -C 解压路径
我使用的是
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/software/
1.4 修改文件名
mv spark-3.1.2-bin-hadoop3.2/ spark
1.5 将spark添加到环境变量
输入命令:sudo vim /etc/profile.d/my_env.sh

上面添加环境变量的目录是我个人创建的,大家可根据自己的情况完成spark的添加到环境变量
1.6 刷新一下环境
source /etc/profile.d/my_env.sh
1.6 启动测试
进入到spark里面 cd /opt/software/spark
执行
bin/spark-shell
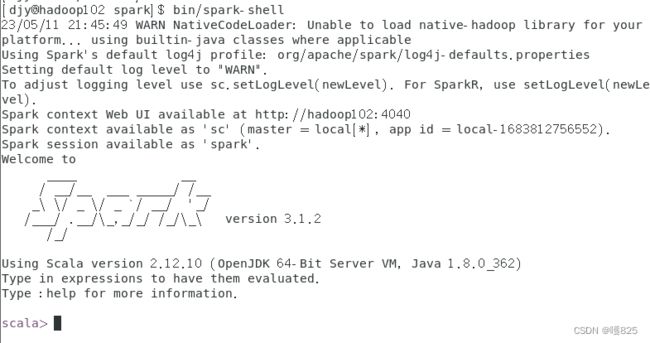
出现以上界面,至此spark的单机安装成功!
2.spark的交互式开发
2.1 交互式开发
交互式开发:通过指令进入交互终端,在命令行直接进行开发
2.2 spark的交互式开发
spark有很多方式可以进行交互式开发
在我们的bin目录下面

其中:
pyspark:支持使用python开发
spark-shell:支持使用scala和java开发
sark-sql:支持sql进行开发
sparR:支持R语言进行开发
注意:在本章中是使用的python语言进行开发
3.使用python对spark进行交互式开发
3.1 执行 pyspark
![]()
报错了,并且说没有python3
因为spark使用python进行交互式开发时,依赖的python版本是python3
3.2 安装python3
python3的安装可以借助anconada工具完成,anconada中自带了python3,同时Anconada还集成了各自python的科学计算库(pandas,numpy等),因此我们选用Anconada安装python3.
3.3 下载Anconada
下载地址:
https://www.anaconda.com/download
3.4 安装Anconada
3.4.1:
将下载好的Anconada通过xftp传输到hadoop102的/opt/software目录下面:

直接拖过来就行
3.4.2:
在Anconada的安装目录下面的software执行**:sh Anaconda3-2023.03-1-Linux-x86_64.sh**
3.4.3:
出现了 >>> 请按 回车

3.4.4:
然后一直回车到有个no >>> 输入yes
3.4.5:
输入yes之后输入**:/opt/software/anconada3**
![]()
此时就会联网按照,下载python3以及一些模块
3.4.5
最后,有个no >>> 输入yes
注意安装完成之后需要重启服务
3.5 再次执行pyspark
bin/pyspark
此时就可以使用python代码执行spark了

出现以上模样,至此使用python对spark进行交互式开发以及完成了!
基于python对spark的三种开发方式
4.1 交互式开发
就是直接通过命令行开发。
比如:

此时data是一个列表
![]()
如果我们想要对data进行spark计算,那么就需要将这个list类型的data转化为spark的RDD。
当我们进入交互模式的时候,会生成一个sc,该sc中的方法可以将python中的数据类型转化为RDD。

此时我们已经转为为了RDD了,那么如果想要数据处理的话,则可以RDD当中提供的各种算子了
当然,这只是简单的了解一下,后面会进行详细的学习解释。
注意:可以使用ctrl + z 退出交互模式
4.2 脚本式开发
脚本式开发其实就是将交互式开发的代码写入文件中,通过运行文件的方式从而允许计算程序。
我们主要了解下面一种开发模式,有兴趣的小伙伴可以自行了解。
4.3 使用pycharm远程开发
4.3.1 导入模块
pip install pyspark==3.1.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
-i 指定安装源为国内的安装源

4.3.2 使用pycharm中的ssh连接服务器
进入到 > tools > SSH Configurations 然后按照下图配置

点击测试

到此 使用pycharm连接ssh就ok了。
注意:我们的pycharm必须是专业版。
4.3.3 使用pycharm执行spark代码
首先pycharm执行的是本地的python环境,我们需要将pycharm的运行环境指定到刚刚我们在虚拟机下载的anconda3里面的python3里面去。
(1)进入到 Python interpreter里面去
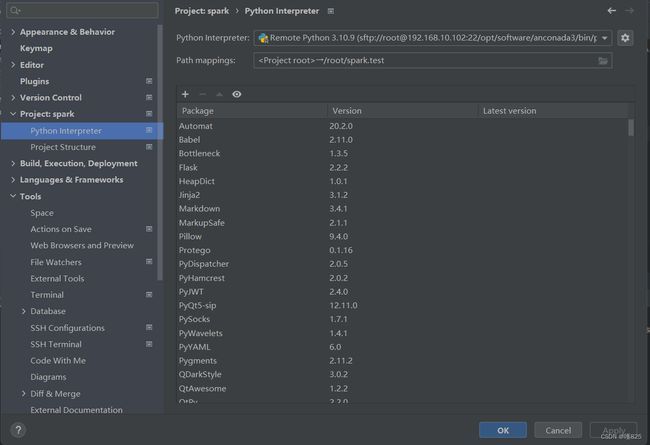
(2)点击 右边Add

(3)点击 SSH Interpreter > 第二个按钮 > 选择远程连接

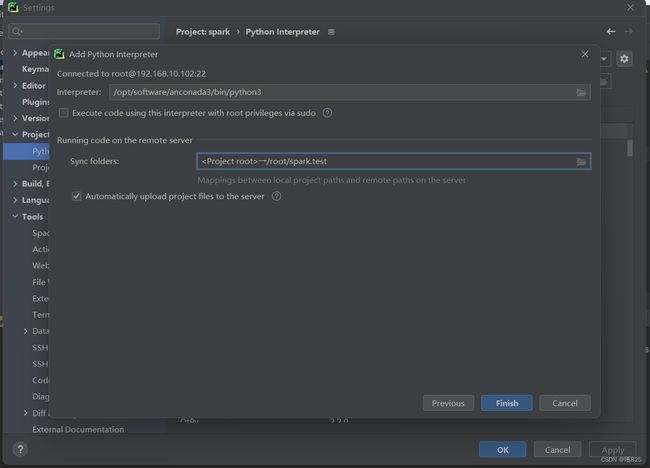
(3)python环境和目录连接
Interpreter中配置你的python3路径
Sync folders 中配置本地项目路径 和 远程连接的虚拟机目录建立连接(在opt下面创建目录spark),点击Finish,那么这样我们在本地py文件,就能同步到远程目录下面了
4.3.4 pycharm连接xftp
一旦当我们配置好了python3的环境之后,pycharm就会自动创建一个远程的映射目录,
如下图所示进行查看:

点击,我们就可以操作并且查看远程目录
5.测试
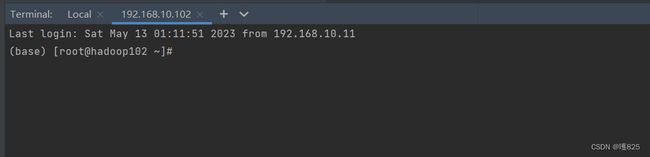
5.1 ssh连接测试
点击terminal,然后如下图所示点击进去
连接成功!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-INzFGZcF-1684251602180)(安装+9a111f3b-3ba0-4521-b3ab-ad057d3dcd17/image 6.png)]](http://img.e-com-net.com/image/info8/df8dbc7bd820410588e190a3e3e2b964.jpg)
5.2 spark运行代码测试
直接在pycharm里面编写代码
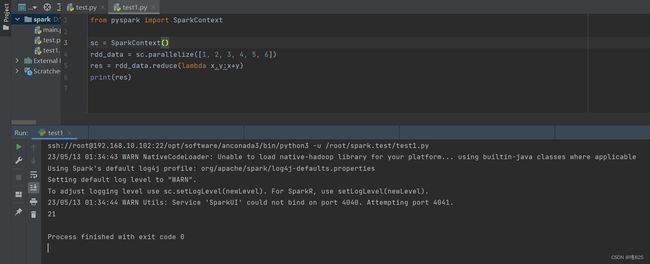
运行成功 结果为 21!
5.3 xftp测试
查看远程目录,如下图右方所示
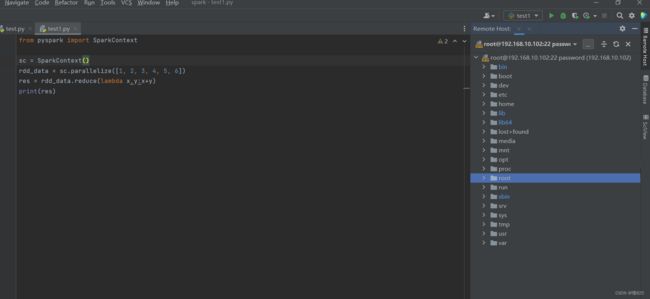
进入/root/spark.test

此时已经同步了test1代码了
点击 test1查看代码
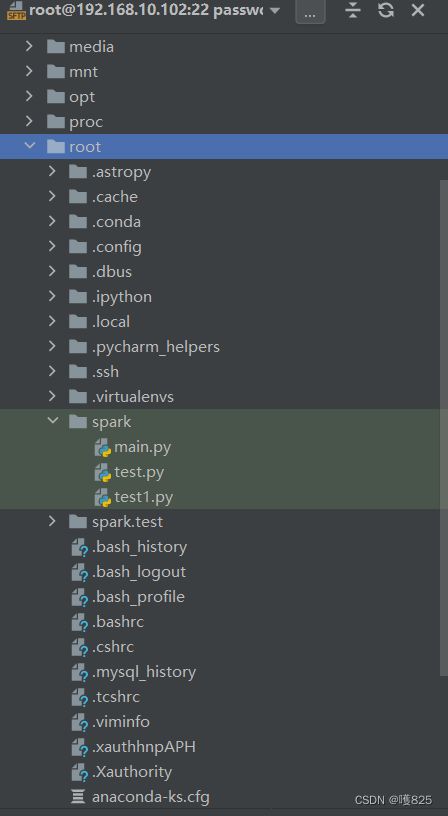
至此 pycharm关于spark单机模式下的基本配置已经完成!
注意事项:
上述安装的所有都必须在root用户下面所有,用户名和所属组都要为root,因为远程连接的时候是以root用户身份连接的。