操作系统的地址、数据存储和大小端问题
文章目录
- 基本概念
-
-
- 什么是位,什么是字节?
- 地址总线
- 内存地址
-
- 物理地址
- 虚拟地址
- 寻址空间
- 存储单元
- CPU位数
- CPU寻址
- 大端存储和小端存储
-
- 原理
- 为什么会有大小端模式的区分
-
基本概念
什么是位,什么是字节?
- 位表示的是二进制位,一般称为比特,即0或1,是计算机存储的最小单位;
- 字节是计算机中数据处理的基本单位,计算机进行数据存储的基本单位是字节。
地址总线
是CPU或有DMA能力的单元,用来沟通这些单元想要访问(读取/写入)计算机内存组件/地方的物理地址;简单来说地址总线是专门用来传送地址的,决定了将信息送往何处。
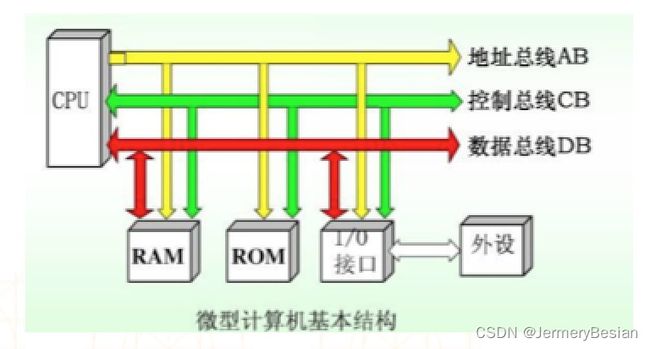
地址总线AB是专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。地址总线的位数决定了CPU可直接寻址的内存空间大小,比如8位微机的地址总线为16位,则其最大可寻址空间为216=64KB,16位微型机的地址总线为20位,其可寻址空间为220=1MB。一般来说,若地址总线为n位,则可寻址空间为2^n位。
举例来说:一个 16位元 宽度的位址总线 (通常在 1970年 和 1980年早期的 8位元处理器中使用) 到达 2 的 16 次方 = 65536 = 64 KB 的内存位址,而一个 32位单元位址总线 (通常在像现今 2004年 的 PC 处理器中) 可以寻址到 4,294,967,296 = 4 GB 的位址
总结
(1)CPU是通过地址总线来指定存储单元的。
(2)地址总线决定了cpu所能访问的最大内存空间的大小。
(3)地址总线是地址线数量之和。
内存地址
物理地址
内存中的数据是按照字节连续排布的,每个存储的数据都有一个索引与之对应,这个索引就是内存的地址。
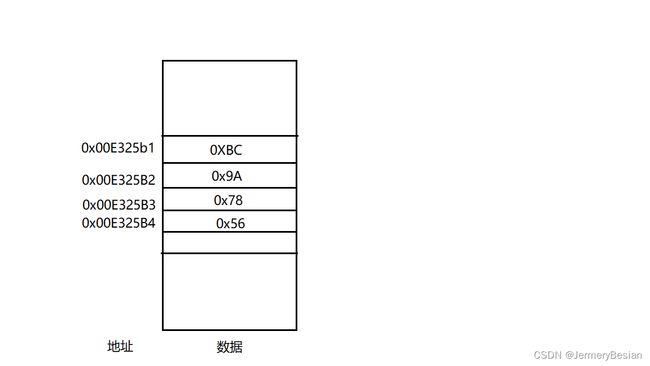
如果我们的CPU想要访问内存,最朴素的想法就是CPU直接指定一个内存的地址就可以了,这个地址就是物理地址,即Physical Address,简称PA。

虚拟地址
直接使用物理地址虽然方便,但是在操作系统上直接用物理地址访问内存产生了一些问题,比如:
- 地址之间不隔离:难以避免一个程序恶意写入另一个程序所使用的内存。
- 内存容易不够用:当同时运行的程序比较多时,内存很容易就不够用了。
- 内存使用效率低:即使当一个程序执行完毕后释放了自己的内存,它留下的“内存空洞”不太可能完全匹配另一个程序所需要的内存大小,可能会产生一些难以利用的“内存碎片”
后来,人们设计出了虚拟地址来解决这些问题。虚拟地址和物理地址之间经过了一层转换,软件或者说CPU通过虚拟地址来访问内存,并不能看到真实的地址,而在中间起到转换作用的是一个专用的模块——MMU(Memory Management Unit)。
当CPU发起对一个虚拟地址的访问时,MMU会去查询页表,将虚拟地址转换为物理地址,这个过程如下图所示:

一般情况下MMU都是被集成在CPU内部的,所以以后的图中我们会把MMU放到CPU中。
页表本身也储存在内存当中,每个进程都有一份,也就是每个进程都有一份虚拟-物理地址的映射关系。当不同的进程访问相同的地址时,最终对应的内存的物理地址是不同的。
寻址空间
寻址空间一般指的是CPU对于内存寻址的能力。通俗地说,就是能最多用到多少内存的一个问题。数据在存储器(RAM)中存放是有规律的 ,CPU在运算的时候需要把数据提取出来就需要知道数据存放在哪里 ,这时候就需要挨家挨户的找,这就叫做寻址,但如果地址太多超出了CPU的能力范围,CPU就无法找到数据了。 CPU最大能查找多大范围的地址叫做寻址能力 ,CPU的寻址能力以字节为单位 。
对于32位操作系统而言,一共可以表示的地址范围为0~2^32次方,其中,每个地址对应内存中的一块数据。而内存中数据存储的最小单位为字节,也就是8bit为一个整体一起存储。所以在32位操作系统中,能寻址的内存大小为:
2^32 * 1B
=4 * 2^10 * 2^10 * 2^10 *1B
由于1KB = 2^10B
1MB = 2^10KB
1GB = 2^10MB
所以上式
=4GB
这也是为什么32位的CPU最大能搭配4G内存的原因 ,再多的话CPU就找不到了。
存储单元
1)8位二进制(1字节)作为一个存储单元,这是由历史原因决定的,早期的ASCII是7位,后来又有IBM的8位EBCDIC得到广泛使用
2)每一个存储单元有一个地址编号,地址总线可以确定每个地址单元的编号,所以CPU的最小可寻址单位就是1字节(Byte)
3)内存也是数据存储器的一种,所以内存也是以1字节为单位的
CPU位数
32位CPU表示CPU一次最多能够处理数据的位数为32bit,即机器字长为32bit
CPU寻址
1)寻址空间一般指的是CPU对于内存寻址的能力。通俗地说,就是能最多用到多少内存的一个问题。
2)每个CPU的寻址能力是要看其地址线的数量,32位CPU一般有32根地址总线,那么就一共可以寻232个地址=也就是4x1024x1024x1024=4G个地址,1个地址对应1字节的存储单位,对应到内存上就是4GB(4GByte)
大端存储和小端存储
原理
-
大端模式:就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
(其实,大端模式才是我们直观上认为的模式,但实际并不是这样)
-
小端模式:就是低字节排放在内存的低地址端,高位字节排放在内存的高地址端。
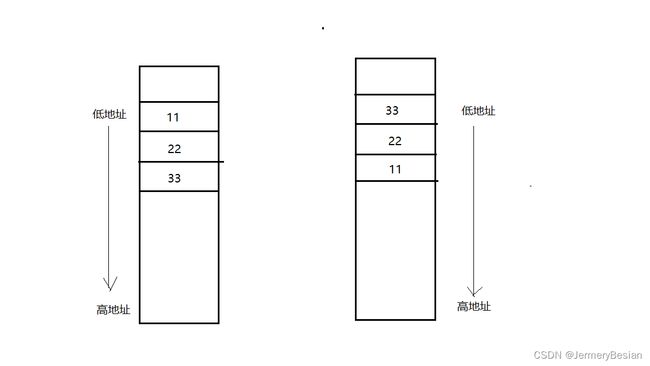
下面我们看个例子

数据本来在内存中存储是由高地址到低地址的 ,但图中可以看到它是由高字节序到低字节序存储的,也就是小端存储。
为什么会有大小端模式的区分
在计算机系统中我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit,但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题,因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式,很多的ARM,DSP都为小端模式,有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式,很多的ARM,DSP都为小端模式,有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
目前的Windows、linux系统下基本都是小端存储的模式