从输入URL到页面加载的全过程-- 前端理解
1、浏览器的地址栏输入URL并按下回车。
2、浏览器查找当前URL是否存在缓存,并比较缓存是否过期。
3、DNS解析URL对应的IP。
4、根据IP建立TCP连接(三次握手)。
5、HTTP发起请求。
6、服务器处理请求,浏览器接收HTTP响应。
7、渲染页面,构建DOM树。
8、关闭TCP连接(四次挥手)。
说完整个过程的几个关键点后我们再来展开的说一下。
一、URL
我们常见的RUL是这样的:http://www.baidu.com,这个域名由三部分组成:协议名、域名、端口号,这里端口是默认所以隐藏。除此之外URL还会包含一些路径、查询和其他片段,例如:http://www.tuicool.com/search?kw=%E4%。我们最常见的的协议是HTTP协议,除此之外还有加密的HTTPS协议、FTP协议、FILe协议等等。URL的中间部分为域名或者是IP,之后就是端口号了。通常端口号不常见是因为大部分的都是使用默认端口,如HTTP默认端口80,HTTPS默认端口443。说到这里可能有的面试官会问你同源策略,以及更深层次的跨域的问题,我今天就不在这里展开了。
二、缓存
说完URL我们说说浏览器缓存,HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类,我将其分为强制缓存,对比缓存。
强制缓存判断HTTP首部字段:cache-control,Expires。
Expires是一个绝对时间,即服务器时间。浏览器检查当前时间,如果还没到失效时间就直接使用缓存文件。但是该方法存在一个问题:服务器时间与客户端时间可能不一致。因此该字段已经很少使用。
cache-control中的max-age保存一个相对时间。例如Cache-Control: max-age = 484200,表示浏览器收到文件后,缓存在484200s内均有效。 如果同时存在cache-control和Expires,浏览器总是优先使用cache-control。
对比缓存通过HTTP的last-modified,Etag字段进行判断。
last-modified是第一次请求资源时,服务器返回的字段,表示最后一次更新的时间。下一次浏览器请求资源时就发送if-modified-since字段。服务器用本地Last-modified时间与if-modified-since时间比较,如果不一致则认为缓存已过期并返回新资源给浏览器;如果时间一致则发送304状态码,让浏览器继续使用缓存。
Etag:资源的实体标识(哈希字符串),当资源内容更新时,Etag会改变。服务器会判断Etag是否发生变化,如果变化则返回新资源,否则返回304。

三、DNS域名解析
我们知道在地址栏输入的域名并不是最后资源所在的真实位置,域名只是与IP地址的一个映射。网络服务器的IP地址那么多,我们不可能去记一串串的数字,因此域名就产生了,域名解析的过程实际是将域名还原为IP地址的过程。
首先浏览器先检查本地hosts文件是否有这个网址映射关系,如果有就调用这个IP地址映射,完成域名解析。
如果没找到则会查找本地DNS解析器缓存,如果查找到则返回。
如果还是没有找到则会查找本地DNS服务器,如果查找到则返回。
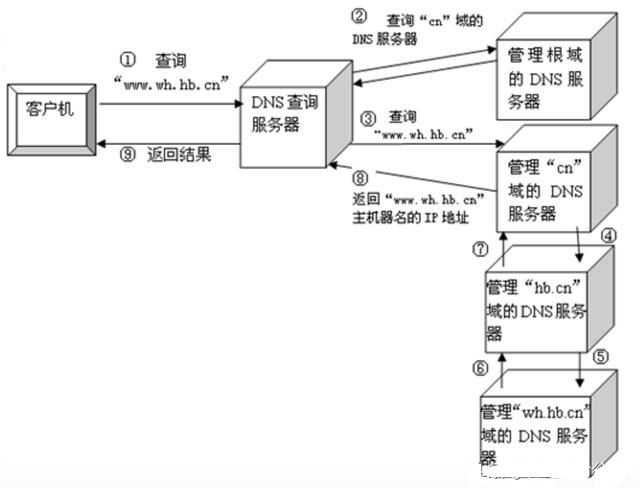
最后迭代查询,按根域服务器 ->顶级域,.cn->第二层域,hb.cn ->子域,www.hb.cn的顺序找到IP地址。

递归查询,按上一级DNS服务器->上上级->....逐级向上查询找到IP地址。
四、TCP连接
在通过第一步的DNS域名解析后,获取到了服务器的IP地址,在获取到IP地址后,便会开始建立一次连接,这是由TCP协议完成的,主要通过三次握手进行连接。
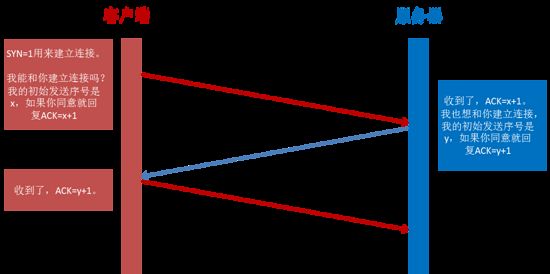
第一次握手: 建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;
第二次握手: 服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手: 客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
五、浏览器向服务器发送HTTP请求
完整的HTTP请求包含请求起始行、请求头部、请求主体三部分。

六、浏览器接收响应
服务器在收到浏览器发送的HTTP请求之后,会将收到的HTTP报文封装成HTTP的Request对象,并通过不同的Web服务器进行处理,处理完的结果以HTTP的Response对象返回,主要包括状态码,响应头,响应报文三个部分。
状态码主要包括以下部分
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
响应头主要由Cache-Control、 Connection、Date、Pragma等组成。
响应体为服务器返回给浏览器的信息,主要由HTML,css,js,图片文件组成。
七、页面渲染
浏览器内核拿到内容后,渲染步骤大致可以分为以下几步:
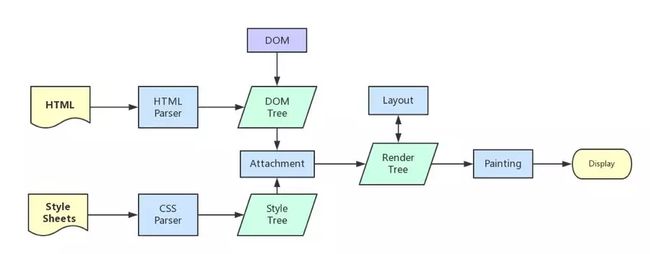
解析HTML,构建DOM树
解析CSS,生成CSS规则树
合并DOM树和CSS规则树,生成render树
布局render树(layout/reflow),负责各元素尺寸、位置的计算
绘制render树(paint),绘制页面像素信息
浏览器会将各层的信息发送给GUI,GUI会将各层合成(composite),显示在屏幕上。
如下图:
遇到CSS样式资源(特点):
CSS下载时异步,不会阻塞浏览器构建DOM树
但是会阻塞渲染,也就是在构建render树时,会等到css下载解析完毕后才进行(这点与浏览器优化有关,防止css规则不 断改变,避免了重复的构建)。有例外,media query声明的CSS是不会阻塞渲染的。
遇到JS脚本资源(特点):
阻塞浏览器的解析,也就是说发现一个外链脚本时,需等待脚本下载完成并执行后才会继续解析html;
浏览器的优化,在脚本阻塞时,也会继续下载其他资源(当然有并发上限),但是虽然脚本可以并行下载,解析过程仍然是阻塞的,也就是说必须这个脚本执行完毕后才会接下来的解析,并行下载只是一种优化而已。
defer(延迟执行)与async(异步执行),普通的脚本是会阻塞浏览器解析的,但是可以加上defer和async属性,这样脚本就变成异步了,可以等到解析完成后再执行。
遇到img图片类资源:
遇到图片等资源时,直接就是异步下载,不会阻塞解析,下载完毕后直接用图片替换原有src的地方。
如果说响应的内容是HTML文档的话,就需要浏览器进行解析渲染呈现给用户。整个过程涉及两个方面:解析和渲染。在渲染页面之前,需要构建DOM树和CSSOM树。

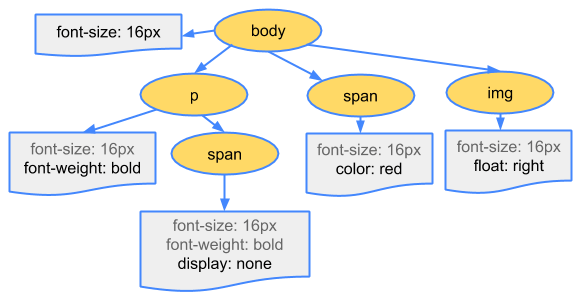
在浏览器还没接收到完整的 HTML 文件时,它就开始渲染页面了,在遇到外部链入的脚本标签或样式标签或图片时,会再次发送 HTTP 请求重复上述的步骤。在收到 CSS 文件后会对已经渲染的页面重新渲染,加入它们应有的样式,图片文件加载完立刻显示在相应位置。在这一过程中可能会触发页面的重绘或重排。这里就涉及了两个重要概念:Reflow和Repaint。
Reflow,也称作Layout,中文叫回流,一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树,这个过程称为Reflow。
Repaint,中文重绘,意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就OK了,这个过程称为Repaint。
所以说Reflow的成本比Repaint的成本高得多的多。DOM树里的每个结点都会有reflow方法,一个结点的reflow很有可能导致子结点,甚至父点以及同级结点的reflow。
下面这些动作有很大可能会是成本比较高的:
-
增加、删除、修改DOM结点时,会导致Reflow或Repaint
-
移动DOM的位置,或是搞个动画的时候
-
内容发生变化
-
修改CSS样式的时候
-
Resize窗口的时候(移动端没有这个问题),或是滚动的时候
-
修改网页的默认字体时
基本上来说,reflow有如下的几个原因:
-
Initial,网页初始化的时候
-
Incremental,一些js在操作DOM树时
-
Resize,其些元件的尺寸变了
-
StyleChange,如果CSS的属性发生变化了
-
Dirty,几个Incremental的reflow发生在同一个frame的子树上
八、关闭TCP连接或继续保持连接
通过四次挥手关闭连接(FIN ACK, ACK, FIN ACK, ACK)。
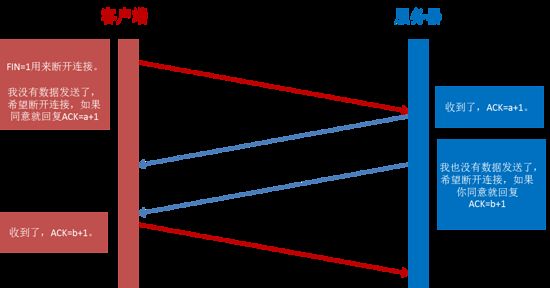
第一次挥手是浏览器发完数据后,发送FIN请求断开连接。
第二次挥手是服务器发送ACK表示同意,如果在这一次服务器也发送FIN请求断开连接似乎也没有不妥,但考虑到服务器可能还有数据要发送,所以服务器发送FIN应该放在第三次挥手中。
这样浏览器需要返回ACK表示同意,也就是第四次挥手。