kafka知识与理解
文章目录
- 背景
- 为什么需要kafka,mysql行不行
- 常识
- 生产者流程
- zookeeper与kafka
- kafka broker的增加和删除
- broker故障
- broker重要参数调优
- 副本位置分配
- 消费者
- 消费者offset
- 消费者参数调优
- 重复消费和漏消费
- 全局特殊情况
- kafka压测
- 存储方案、读写为什么快
- lsm tree
- 有序性
- 硬件资源
- 配置项更新模式
背景
电商网站,前端埋点,写日志服务器,flume能察觉log文件的变化,
双十一时flume采集速度200m/s,而hadoop上传速度100m/s,kafka可以buffer住,
传统上kafka是分布式的发布/订阅模式的消息队列,
现在,kafka是分布式事件流平台。
大数据主要用kafka,java开发则常用rabbit/rocket mq。
kafka可以分为producer,broker,consumer三部分。
为什么需要kafka,mysql行不行
- 时空解耦,异步通信
- 缓冲,削峰
- 高可用,存储群和消费者群都可以部分fail
- 灵活,易扩展
- 有序(单partition内有序)
常识
topic的流量越大,topic的partition越多,通过实现partition selector(直接用murmurhash也算是一种实现)可以指定写入partition。
一个partition对应一个log目录。目录内是该partition分的segment。
partition可以有多个副本,数量由replica参数决定,多个副本中有一个leader。leader挂了就重选leader。这事由zookeeper做。kafka2.8.0后可以不用zookeeper改用kraft。
发布订阅模式下消费后不会删除数据,各消费者独立消费。
单台服务器硬盘一般小于100T。
要先关kafka,后关zookeeper。也很自然,因为启动的时候先zookeeper。
一台服务器一个broker。每个broker的id必须唯一。
除了topic名称,还有topic id。
partition只能增加,不能减少。因为被删分区的数据不好处理。不过最好一开始就想好,不要改。
hadoop、kafka、spark、flink都有自己的序列化器,不用java自带,因为java自带额外字段太多。
生产者流程
一个分区,一个Dqueue队列,位于内存。
kafka的拦截器一般不用,一般用flume的拦截器。
大小和延迟时间是两个重要的参数,与生产者吞吐量有关,吞吐高了延迟就高了。
吞吐量:发送缓冲区从32m调成64m,batch从16k调成32k,linger5-100ms,lz4/snappy压缩。
有序:最多允许5个请求inflight,超过会阻塞。如果设为1,则必有序。开启幂等后缓存5个并排序。
broker有三种ACK级别。0/1都可能丢数,2在follower始种跟不上时会将其踢出ISR(in-sync replica)。
至多一次:ACK级别为0
至少一次:ACK级别为-1,ISR至少为2。ACK为1常用,-1用于钱。
精确一次:幂等性+至少一次,幂等性保证单分区单会话无重复:<会话ID,partitionID,消息序号>
精确一次:如果还嫌不够,开启幂等的基础上再开事务,需要指定事务id。
成功则清理Dqueue,失败则重试,默认一直重试。
需要配置key和value的serializer。
send时可以提供一个callback,获取写入分区的信息。
同步发送在异步写法后面加个get就行。
分区的好处:负载均衡利用大小不同的硬盘,提高并行度。
看producerRecord的构造函数可以发现,可以指定partition,可以指定key,都没有则黏性分区(一直用一个分区,batch满了或者linger到了就换)。当初实习的需求,其实指定key就可以了。
zookeeper与kafka
broker上线,就会在zookeeper注册。
/kafka/brokers/ids:显示broker id
/kafka/brokers/topics/yourTopicName/partitions/partitionNum/state:显示leader和isr
/kafka/controller:率先在此注册的broker controller负责监控各broker状态和后续选举。
选举时看ar队列,,谁在前面选谁,前提是在isr中。ar=isr+osr,isr是可用机,osr是掉线机。
zookeeper describe出来的repilica列表就是ar。ar的右边就是isr。
kafka broker的增加和删除
一般配置两个副本,增加broker可以减缓每个broker的存储压力,比如topic1有三个partition,本来有3个broker,replica=2:
partition0:[0,1,2]
partition1:[0,1,2]
partition2:[0,1,2]
那么此时每个broker上都存了3份。如果加一个broker,可以是:
partition0:[0,1,3]
partition1:[0,3,2]
partition2:[0,1,2]
写个json,指明需要调节的topic,
执行kafka-reassign-partitions.sh,提供broker id列表,
就会返回计划,把计划复制到increase-replications-factor里,
然后再次执行kafka-reassign-partitions.sh,指定–execute,计划就会执行。
broker故障
broker 30s没反应就会离开ISR。
follower故障, 离开ISR,其它照常收,且各LEO和HW继续涨
LogEndOffset(LEO),每个副本最后一个offset
HighWatermark(HW),各个副本中LEO的最小值,也是可消费的边界
恢复时,老HW到新HW之间的数据会被删掉,然后与leader同步,追上新HW后加入ISR。
leader故障,从ISR中选出新leader,其它删掉老HW后的数据,与新leader同步。
broker重要参数调优
关闭leader partition再平衡。
日志segment大小,就按默认1G。
稀疏索引,就按默认4kb一条。
日志过期,调为3天,或者数小时。
日志大小,就按默认无穷大。
删除策略,就按删除。
写硬盘线程,大头的核数的1/2,默认为8,可以设为12。
副本拉取线程,大头核数的1/6,默认为1,可以设为4。
数据传输,大头核数的1/3,默认为3,可以设为8。
页缓存强制flush条件,就按默认,不强制flush。
如果机器资源不均,需要手动调整副本位置分配。
关闭自动创建主题。
副本位置分配
kafka会采取类似轮询的方案。如下图。但实际生产时不同的broker可能资源不同,需要手动调整。
手动调整的过程类似broker增删。增加replica的操作也类似broker增删。
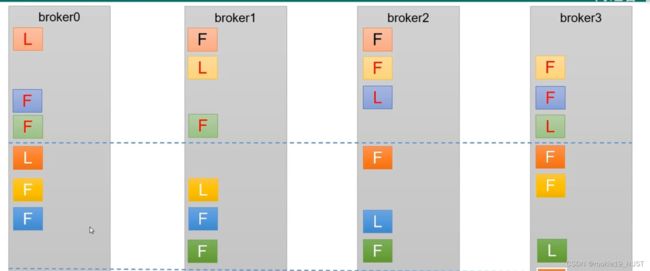
由于读写请求都是leader在受理,所以关键是leader的位置。leader partition会自动平衡,默认开启。
建议关闭,再平衡会拖累性能。
消费者
由于不同消费者的消费速度不同,kafka采取pull消费。
partition和消费者组中的消费者,只能多对一或者一对一,不能一对多。所以消费者组的大小没必要超过partition数,超了就会闲置。
默认增量消费,即只消费consumer启动后来的数据。可以from-beginning消费存量。
目前kafka的offset存在kafka系统主题__consumer_offsets中,以减少kafka和zk的通信。
消费者一定会有groupid,手动指定一个字符串,组里可以只有一个消费者。
消费者组需要向自己的负责broker提交offset和心跳。
心跳3s一次,超过45s没有心跳就会被移除,并且触发再平衡。
如果消费者处理时长超过5min,也会移除触发再平衡。
负责broker需要负责消费者组leader选举,指定partition和消费者的对应关系(即任务分区分配)。
负责broker的选择就靠groupid % 50。
分区分配有四种主要策略,默认策略是range+cooperativeSticky,
- range,对每个topic,按partition数量平均分,除不尽时按字典排序来。
假如某个topic有7个partition,3个consumer,那么:[0,1,2],[3,4],[5,6]
停掉第一个consumer,
0-45秒的任务分配:[0,1,2,3,4],[5,6],会作为整体交给某一个consumer。
45秒后的任务分配:[0,1,2,3],[4,5,6]
topic个数多时,排序靠前的负担会特别大。 - sticky,再平衡时会考虑之前的分配方案,使改动尽可能小
假如某个topic有7个partition,3个consumer,那么:[1,4],[0,3,6],[2,5],个数均匀,id随机。
停掉第二个consumer,
0-45秒的消息:[1,3,4],[0,2,5,6]
45秒后:[2,3,5],[0,1,4,6] - roundrobin,将所有topic的所有partition放一起,然后轮询
假如所有topic共有7个partition,3个consumer,那么:[0,3,6],[1,4],[2,5]
停掉第一个consumer,
0-45秒:[0,1,4,6],[2,3,5]
重平衡后:[0,2,4,6],[1,3,5] - cooperativeSticky。
consumer需要执行assignment方法获取分区分配方案,这个过程需要时间,需要写等待代码。
sticky的实现最为复杂,尤其适合单个group内订阅的topic不同的情况。
类似生产者可以指定分区,消费者也可以指定分区,用assign方法。
消费者offset
以key-value形式存在__consumer_offsets主题中,
key为groupid,topic,分区号,value为offset,
显然会有大量冗余,定期compact,保留最新offset。
系统主题默认是不能看的,需要改配置。
默认每5s自动提交offset。也可以手动同步提交、手动异步提交。
指定offset消费,有三种策略,earliest/latest/none。none要求必须有遗留offset,否则报错。默认latest。
可以用seek函数指定任意中间offset进行消费。
可以指定时间消费,比如某时刻后的数据异常,按时间重新消费。consumer的offsetForTimes方法,将时间转为offset。
消费者参数调优
最小/最大抓取大小(默认1字节/50M)
最大抓取等待(默认500ms)
最大消息条数(默认500条)
以上可适当提高,以提高吞吐量。
关闭自动提交,保精确一次。
consumer数量调大,前提是不超过partition数量。
重复消费和漏消费
就是偏移量修改和落盘先后顺序的问题。先修改就可能漏,先落盘就有可能重。
两种方法,一种是让偏移量修改和落盘组成事务,
另一种是先处理、落盘,然后手动提交,做幂等处理。
重复消费造成问题的例子:
create table if exist drop table,如果被多次消费了,就会导致数据丢失。
数据库查询时的ABA问题。
全局特殊情况
单条日志特别大(>1m):
broker接收每批消息的最大值默认为1m,还有若干最大值为1m,这些参数就需要上调。
服务器挂了:
先尝试重启,
不能重启就加内存、CPU、网络带宽,
如果replica大于等于2,就服役新节点。
kafka压测
kafka官方有生产者压测和消费者压测脚本。
存储方案、读写为什么快
对于 Kafka 来说, 它主要用来处理海量数据流,这个场景的特点主要包括:
写操作:写并发要求非常高,基本得达到百万级 TPS,顺序追加写日志,硬盘连续写很快,不考虑更新操作。
读操作:相对写操作来说,比较简单,只要能按照一定规则高效查询即可(offset或者时间戳)。
多partition,充分利用io资源。
写:顺序追加写。
读:分片,稀疏索引,二分查找。
零拷贝+PageCache,分批发送(批处理有助于消息压缩和顺序存取)
每个partition一个log目录,目录名为topicName-partitionNum,
目录下有多个segment,分片和索引,加快定位数据,
每个segment有.index, .log, .timeindex,
利用kafka-run-class.sh可以肉眼阅读序列化后的上述文件。
默认写4kb的log,有一条稀疏索引。
文件默认保留7天,也就是168小时。时间按segment中最大时间戳算。
删除策略分为delete和compact。压缩是指同一个key,不同的value,只保留最新的value。
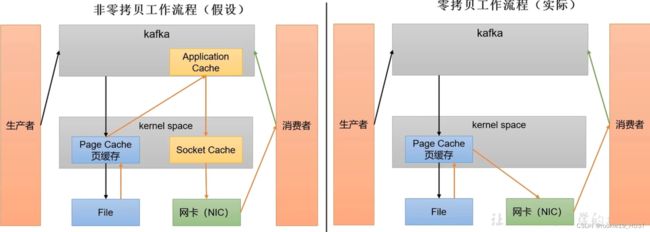
敢零拷贝是因为broker这无需处理数据。
lsm tree
用于Hbase,Cassandra,LevelDB(big table实现),RocksDB,MongoDB,TiDB等NoSQL,
以及kafka。
lsm tree是顺序写入的,适合写多读少。O1写,On读,索引优化后可以达到Ologn读。
而B+树是稳定的On读。
核心数据结构是Sorted String Table,trick是分层存储。
写的时候写memtable,到达大小后落盘,之后逐层compaction。
查的时候从上往下查。
compact会挑闲时。
有序性
Partition 分区内每条消息都会被分配一个唯一的消息 id,即偏移量 Offset,因此kafka 只能保证每个分区内部有序性,并不能保证全局有序性。
不仅要实现producer 的partition selector保证同key写入同partition,
还要保证有序消费。有序消费可以通过phantomThief的亲缘性线程池来实现。
private final KeyAffinityExecutor<Integer> executor = KeyAffinityExecutor.newSerializingExecutor(int parellelism, int queueBufferSize, String threadName);
硬件资源
jstat -gc 进程号可以看gc次数,
jmap可以看堆内存使用。
100万日活,每人每天100条,每天一亿条,每秒一千条,每条1k,平时1mb/s,峰值20mb/s;
台数 = 2 * floor(生产者速率 * 副本数 / 100) + 1 = 3
kafka堆内存占10g,页缓存需要1g;
网卡注意单位换算,bps需要除以8,如果是20MB/s的流量,就需要千兆网卡;
硬盘,每天一亿条,每条1k,两个副本,保留三天,需要1t;
CPU,大头3类,这3类给24核,写硬盘1/2,副本拉取1/6,数据传输1/3。另8核给其它线程。
分区数量的经验公式:目标吞吐量 / min(生产者吞吐量, 消费者吞吐量),后两者可以先用单分区的压测来获得。
配置项更新模式
官网上每个配置都有解释,配置项的update有三种模式,
read-only,per-broker,cluster-wide,
分别是broker需要重启,broker无需重启单broker生效,无需重启全局生效。