【Python/爬虫】python爬虫快速入门及实战(古诗文,电影,题目数据收集)
目录
- Python爬虫快速入门及实战
-
- 一、requests库的使用
- 二、beautifulsoup4库的使用
- 实战一——静态网站内容爬取
- 实战二——动态网站内容爬取
- 实战三——利用cookie伪装登录状态爬取内容
Python爬虫快速入门及实战
需要提前掌握:html、css基础知识,网络通信基础知识、http请求和响应报文基础知识
主要使用的库:
- requests(发请求和获取响应)
- beautifulsoup4(解析html,它的css选择器很好用)
- fake-useragent(产生虚假的浏览器请求头代理信息)
- PyMySQL(用来把爬到的数据保存到MySQL数据库)
一、requests库的使用
在这个库中,主要使用三个方法:
- get()
- post()
- session()
这三个方法都有几个参数可供配置:
- url 字符串,统一资源定位符,发起请求的地址
- data 一个字典,post请求的请求体内容
- headers 一个字典,其中主要配置user-agent、cookie等信息
- proxies 一个字典,代理ip
- timeout 整数,秒,发起请求后服务器在这个时间内没有响应,报错
这三个方法都会return回一个响应对象(response),这个对象中可以获取以下信息:
- content 响应内容的字节码格式
- text 响应内容的字符串格式
- json 响应内容的json格式
- status_code 响应码
- cookies 响应的cookies
- headers 响应头
- url 响应的url
二、beautifulsoup4库的使用
主要讲解这个库中css选择器的使用。
基本用法如下:
# 导入bs对象
from bs4 import BeautifulSoup
# 构造解析特定Html的bs对象
soup = BeautifulSoup(html_text, "lxml") # “lxml”是c语言的解析器,速度会更快,但是要安装lxml这个库才能使用。pip install lxml
# 使用soup的css选择器解析出html中的标签元素
tag_list = soup.select(".cont > p > a > b") # 类选择器、标签选择器和父子选择器
for tag in tag_list:
print(tag.text) #得到标签元素中的内容
print(tag.attrs["href"]) #得到标签元素中href这个属性的内容
实战一——静态网站内容爬取
目标:收集古诗文网站上李白的100篇诗文,保存到MySQL数据库中。
特点:静态页面获取,分页获取。这是最简单的爬虫。
首先,分析要爬取的界面的信息。
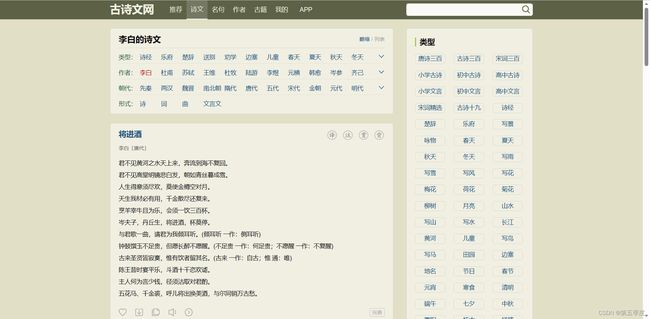
手动点击,切换页面,可以得到每一页的url规律如下:
https://so.gushiwen.cn/shiwens/default.aspx?page=1&tstr=&astr=%e6%9d%8e%e7%99%bd&cstr=&xstr=
https://so.gushiwen.cn/shiwens/default.aspx?page=2&tstr=&astr=%e6%9d%8e%e7%99%bd&cstr=&xstr=
https://so.gushiwen.cn/shiwens/default.aspx?page=3&tstr=&astr=%e6%9d%8e%e7%99%bd&cstr=&xstr=
……
可以很明显看出每一页是由page这个参数进行控制的。
一页有10条内容,按F12打开浏览器控制器,发现诗文的标题在类名为cont的div标签的第一个p标签的a标签中。诗文内容在类名为contson的div标签中。
所以思路是:使用requests发起请求获得每一页的html代码,使用bs4解析html得到诗文的标题和内容,将诗文和内容保存进数据库中。
源码如下:
import requests
import pymysql
import uuid
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
url = "https://so.gushiwen.cn/shiwens/default.aspx?page={}&tstr=&astr=%e6%9d%8e%e7%99%bd&cstr=&xstr="
headers = {
"user-agent": UserAgent().random
}
for i in range(1, 11):
resp = requests.get(url=url.format(i), headers=headers)
soup = BeautifulSoup(resp.text, "lxml")
# 获取诗文标题所在的标签的列表
b_tag_list = soup.select(".cont > p > a > b")
# 获取诗文内容所在的标签的列表
contson_tag_list = soup.select(".contson")
# 创建数据库连接
mysql_connnet = pymysql.connect(host="127.0.0.1",user="root",password="123456",database="spider_db",charset="utf8")
# 由连接创建光标 光标可以执行sql语句
mysql_cursor = mysql_connnet.cursor()
for index in range(len(contson_tag_list)):
print("=" * 50)
print("标题:")
poem_title = b_tag_list[index].text
print(poem_title)
print("内容:")
poem_content = contson_tag_list[index].text.strip().replace("。", "。\n").replace("?","?\n").replace("!","!\n").replace(")",")\n")
print(poem_content)
print("=" * 50)
# 把标题和内容插入表
sql = "insert into poem_spider(poem_id,poem_title,poem_content) values('{0}','{1}','{2}')"
sql = sql.format(uuid.uuid1(), poem_title, poem_content)
mysql_cursor.execute(sql)
# 需要提交事务,不然数据库中不会新增
mysql_connnet.commit()
# 释放mysql光标和连接内容
mysql_cursor.close()
mysql_connnet.close()
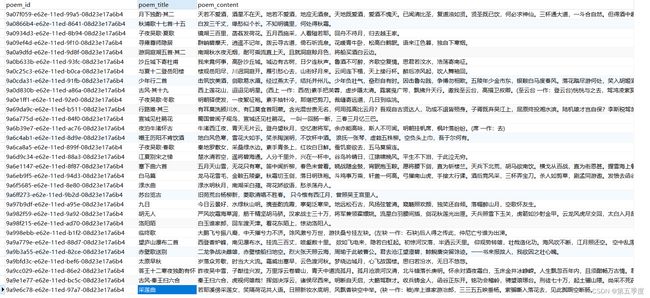
实现效果:
实战二——动态网站内容爬取
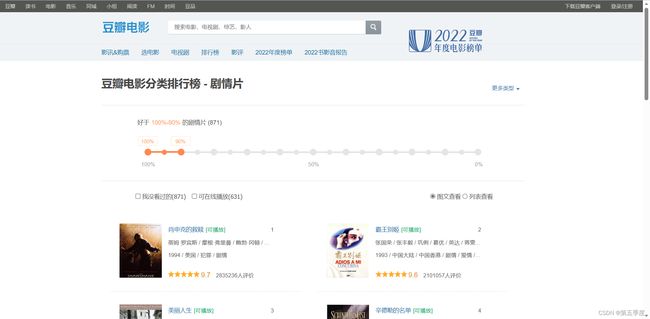
目标:收集豆瓣电影分类排行榜 - 剧情片,好于90%-80%的912部剧情片电影数据:电影名、排名、电影分类、评分、评价人数,并将信息保存到csv文件中。
特点:数据不是一次就加载完毕,需要手动利用鼠标点击、鼠标滑动到页面底部等操作,才能浏览电影信息。这是一个动态页面。
进入网址:
https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
接下来点击页面上的滑块,筛选出好于90%-80%的电影,鼠标滑动到底部,同时按下F12打开控制台,进入网络进行抓包。
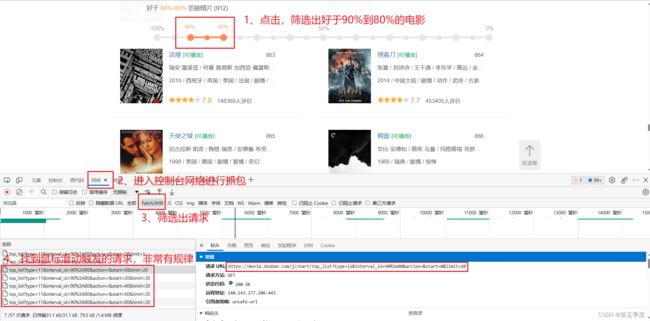
至此,我们已经了解了请求触发的顺序:
# 滑动鼠标的请求
https://movie.douban.com/j/chart/top_list?type=11&interval_id=90%3A80&action=&start=0&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=90%3A80&action=&start=20&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=90%3A80&action=&start=40&limit=20
https://movie.douban.com/j/chart/top_list?type=11&interval_id=90%3A80&action=&start=60&limit=20
……(请求非常有规律)
注意:我们要爬取的内容已经在这些请求的响应中了,所以不需要再去解析Html中的元素获取数据。
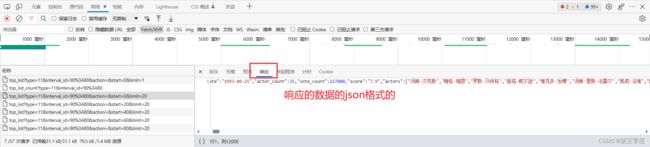
到了这里,就可以编写代码了。思路是:发起请求获取响应,将响应的json数据利用python中的json库解析成字典对象,将字典对象中的数据写入csv文件中。
源码如下:
import requests
import json
from fake_useragent import UserAgent
url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=90%3A80&action=&start={}&limit=20"
headers = {
"user-agent": UserAgent().random
}
# csv文件
csv_file = open(file="../data/movie_csv_data.csv",mode="w",encoding="utf8",newline="\n")
csv_file.write("电影名,电影排名,电影分类,电影评分,电影评价人数\n")
# 一共有912部电影,每次请求得到20部的数据,需要请求46次
for start in range(0, 901, 20):
# 发起请求得到响应
resp = requests.get(url=url.format(start), headers=headers)
movie_data_dict_list = json.loads(resp.text)
for movie_data_dict in movie_data_dict_list:
title = movie_data_dict["title"]
rank = movie_data_dict["rank"]
types = str(movie_data_dict["types"]).replace(",","-").replace("'","")
score = movie_data_dict["score"]
vote_count = movie_data_dict["vote_count"]
print("=" * 50)
print("电影名:{}".format(title))
print("电影排名:{}".format(rank))
print("电影分类:{}".format(types))
print("电影评分:{}".format(score))
print("电影评价人数:{}".format(vote_count))
print("=" * 50)
csv_file.write("{0},{1},{2},{3},{4}\n".format(title,rank,types,score,vote_count))
csv_file.close()
实现效果:


实战三——利用cookie伪装登录状态爬取内容
目标:实现牛客网登录以及登录状态维持,收集C语言30道题
特点:牛客网需要先进行登录之后获取牛客网服务器签发给我们的cookie,之后每次请求都需要携带上这个cookie才能查看题库中的题目。
一种方法是使用requests库中的session函数。思路是:利用session()发送登录请求之后,session()会把响应中的cookie保存起来,之后每次使用session()发送请求都会在请求头中附加上cookie维持登录状态。不过牛客网登录有验证码的存在,不是提交登录请求就可以轻易获取cookie的,所以这种方法实现起来会非常麻烦(需要另外做一些验证码图像识别的工作)。
另外一种方法就是手动获取cookie。思路是:我们自己先登录进去,然后通过抓包查看请求头中的cookie到底是什么样子,之后手动把这个cookie放到我们的请求头中。我们采用这种方法进行实战。
实战步骤
首先,登录进牛客网并且进入它的题库,之后配置题目选项为:每次出30道题。

进入c语言题库,模拟做题,同时按下F12,观察发送的请求中的cookie。注意,这里有不少包,而且一些包中的cookie有可能是不行的。所以要多加鉴别。

接下来观察html的元素结构。我们要获取的内容是题目+选项。选择题目所在的元素,可以看到类名是.commonPaperHtml.tw-flex-1.tw-w-0。选择选项所在的元素可以看到选项所在的类名是.question-select。


根据以上分析,源码如下:
import uuid
import pymysql
import requests
from bs4 import BeautifulSoup
url = "https://www.nowcoder.com/exam/test/68987832/detail?examPageSource=Intelligent&pid=49560691&testCallback=https%3A%2F%2Fwww.nowcoder.com%2Fexam%2Fintelligent%3FquestionJobId%3D10%26tagId%3D21004&testclass=%E8%BD%AF%E4%BB%B6%E5%BC%80%E5%8F%91"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"cookie": "你的cookie",
}
# 数据库连接
mysql_connect = pymysql.connect(host="127.0.0.1",user="root",password="123456",database="spider_db",charset="utf8")
mysql_cursor = mysql_connect.cursor()
# 发送请求获取响应
session = requests.Session()
resp = session.get(url=url, headers=headers)
html_text = resp.text
# 解析html页面
soup = BeautifulSoup(html_text, "lxml")
question_tag_list = soup.select(".commonPaperHtml.tw-flex-1.tw-w-0")
option_tag_list = soup.select(".question-select")
for index in range(len(question_tag_list)):
question_content = question_tag_list[index].text.replace("()", "()\n").replace("'","’").replace('"','”')
question_select = option_tag_list[index].text.replace("A ", " A、").replace("B ", " B、").replace("C "," C、").replace("D ", " D、").replace("'","‘").replace('"','”')
print("=" * 50)
print("题目:{}".format(question_content))
print("选项:{}".format(question_select))
print("=" * 50)
# 把数据添加进数据库
sql = "insert into question_spider(question_id,question_content,question_select) values('{0}','{1}','{2}')"
sql = sql.format(uuid.uuid1(),question_content,question_select)
mysql_cursor.execute(sql)
mysql_connect.commit()
mysql_cursor.close()
mysql_connect.close()
效果如下:

本来是想要收集300道题的,但是我发现每一次点击进C语言题库做题,url中的两个参数都会改变,而且这两个参数我没有找到什么规律。如果有小伙伴知道如何解决这个问题,欢迎在评论区留言~