转自: https://www.cnblogs.com/21207-iHome/p/6048969.html#undefined
迪杰斯特拉(Dijkstra)算法是典型的最短路径的算法,由荷兰计算机科学家迪杰斯特拉于1959年提出,用来求得从起始点到其他所有点最短路径。该算法采用了贪心的思想,每次都查找与该点距离最近的点,也因为这样,它不能用来解决存在负权边的图。解决的问题可描述为:在无向图 G=(V,E) 中,假设每条边 E[i] 的长度为 w[i],找到由顶点vs到其余各点的最短路径。
1) 基本思想:
通过Dijkstra计算图G中的最短路径时,需要指定起点vs(即从顶点vs开始计算)。此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点vs的距离)。初始时,S中只有起点vs;U中是除vs之外的顶点,并且U中顶点的路径是"起点vs到该顶点的路径"。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。重复该操作,直到遍历完所有顶点。
2) 算法步骤:
a.初始时,S只包含源点,即S={vs},vs的距离为0。U包含除vs外的其他顶点,即U={其余顶点},若u不是vs的出边邻接点,则权值为∞;
b.从U中选取一个距离vs最小的顶点k,把k加入S中(该选定的距离就是vs到k的最短路径长度min);
c.以k为新考虑的中间点,修改U中各顶点的距离;若从源点vs到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,即dist[u] = min( dist[u], min + w[k][u] );
d.重复步骤b和c直到所有顶点都包含在S中。
3) 算法实例:
先给出一个无向图
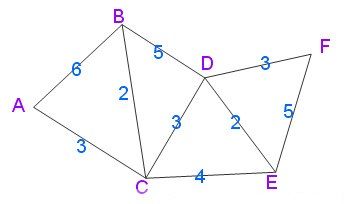
用Dijkstra算法找出以A为起点的单源最短路径步骤如下:

具体实现的代码如下:
#include
#include
#define MAX_LEN 100
#define INFINITE 1000
typedef struct graph
{
int nodenum;
int edgenum;
int matrix[MAX_LEN][MAX_LEN];
}Graph;
typedef struct stack
{
int top;
int printout[MAX_LEN];
}Stack;
void InitStack(Stack *s)
{
s->top = -1;
memset(s->printout,0,sizeof(int)*MAX_LEN);
}
void push(Stack *s,int m)
{
s->printout[++(s->top)] = m;
}
int pop(Stack *s)
{
return s->printout[s->top--];
}
int in[MAX_LEN];
int dist[MAX_LEN];
int prev[MAX_LEN];
void InitGraph(Graph *g,int n)
{
int i, j;
for(i = 1; i <= n; i++)
{
for(j = 1; j <= n;j++)
{
if(i == j) g->matrix[i][j] = 0;
else g->matrix[i][j] = INFINITE;
}
}
for(i=1;i<=n;i++)
{
in[i] = 0;
dist[i] = INFINITE;
prev[i] = 0;
}
}
int main()
{
int n,m,i,I,J,weight,count,min,k,temp;
while(scanf("%d %d",&n,&m))
{
Graph mGraph;
mGraph.edgenum = m;
mGraph.nodenum = n;
InitGraph(&mGraph, n);
for(i = 0; i < m; i++)
{
scanf("%d %d %d", &I, &J, &weight);
mGraph.matrix[I][J] = weight;
mGraph.matrix[J][I] = weight;
}
in[1] = 1;
prev[1] = 1;
dist[1] = 0;
for(i = 2; i <= n; i++)
{
dist[i] = mGraph.matrix[1][i];
if(dist[i] != INFINITE) prev[i] = 1;
}
count = 0;
while(count < n-1)
{
min = INFINITE;
for(i = 1; i <= n; i++)
{
if(in[i] == 0 && dist[i] < min)
{
min = dist[i];
k = i;
}
}
in[k] = 1;
for(i = 1; i <= n; i++)
{
if( in[i]==0 && (min + mGraph.matrix[k][i])<dist[i] )
{
dist[i] = min + mGraph.matrix[k][i];
prev[i] = k;
}
}
count++;
}
Stack s;
for(i = 1; i <= n; i++)
{
temp = i;
InitStack(&s);
if(prev[temp] == 0)
{
printf("no path\n");
continue;
}
while(prev[temp] != 1)
{
push(&s, prev[temp]);
temp = prev[temp];
}
printf("1-->");
while(s.top != -1)
{
printf("%d-->", pop(&s));
}
printf("%d min length is %d\n", i, dist[i]);
}
}
getchar();
return 0;
}
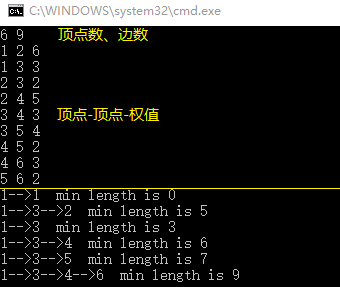
输入和输出如下图所示:
路径规划是指的是机器人的最优路径规划问题,即依据某个或某些优化准则(如工作代价最小、行走路径最短、行走时间最短等),在工作空间中找到一个从起始状态到目标状态能避开障碍物的最优路径。机器人的路径规划应用场景极丰富,最常见如游戏中NPC及控制角色的位置移动,百度地图等导航问题,小到家庭扫地机器人、无人机大到各公司正争相开拓的无人驾驶汽车等。
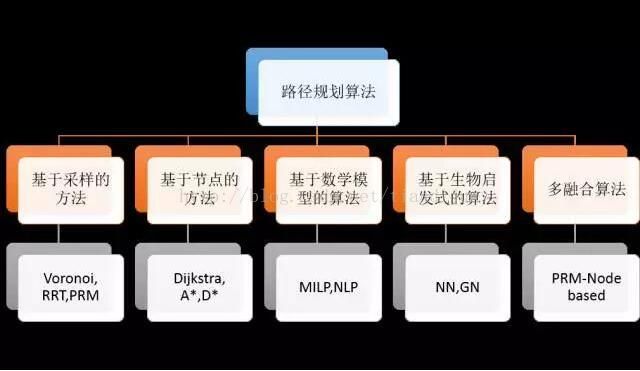
目前路径规划算法分为:
A*算法原理:
在计算机科学中,A*算法作为Dijkstra算法的扩展,因其高效性而被广泛应用于寻路及图的遍历,如星际争霸等游戏中就大量使用。在理解算法前,我们需要知道几个概念:
- 搜索区域(The Search Area):图中的搜索区域被划分为了简单的二维数组,数组每个元素对应一个小方格,当然我们也可以将区域等分成是五角星,矩形等,通常将一个单位的中心点称之为搜索区域节点(Node)。
- 开放列表(Open List):我们将路径规划过程中待检测的节点存放于Open List中,而已检测过的格子则存放于Close List中。
- 父节点(parent):在路径规划中用于回溯的节点,开发时可考虑为双向链表结构中的父结点指针。
- 路径排序(Path Sorting):具体往哪个节点移动由以下公式确定:F(n) = G + H 。G代表的是从初始位置A沿着已生成的路径到指定待检测格子的移动开销。H指定待测格子到目标节点B的估计移动开销。
- 启发函数(Heuristics Function):H为启发函数,也被认为是一种试探,由于在找到唯一路径前,我们不确定在前面会出现什么障碍物,因此用了一种计算H的算法,具体根据实际场景决定。在我们简化的模型中,H采用的是传统的曼哈顿距离(Manhattan Distance),也就是横纵向走的距离之和。
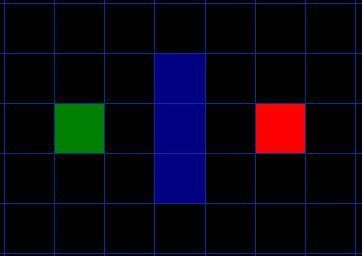
如下图所示,绿色方块为机器人起始位置A,红色方块为目标位置B,蓝色为障碍物。
我们把要搜寻的区域划分成了正方形的格子。这是寻路的第一步,简化搜索区域。这个特殊的方法把我们的搜索区域简化为了 2 维数组。数组的每一项代表一个格子,它的状态就是可走 (walkalbe)或不可走 (unwalkable) 。现用A*算法寻找出一条自A到B的最短路径,每个方格的边长为10,即垂直水平方向移动开销为10。因此沿对角移动开销约等于14。具体步骤如下:
从起点 A 开始,把它加入到一个由方格组成的open list(开放列表) 中,这个open list像是一个购物清单。Open list里的格子是可能会是沿途经过的,也有可能不经过。因此可以将其看成一个待检查的列表。查看与A相邻的8个方格 ,把其中可走的 (walkable) 或可到达的(reachable) 方格加入到open list中。并把起点 A 设置为这些方格的父节点 (parent node) 。然后把 A 从open list中移除,加入到close list(封闭列表) 中,close list中的每个方格都是不需要再关注的。
如下图所示,深绿色的方格为起点A,它的外框是亮蓝色,表示该方格被加入到了close list 。与它相邻的黑色方格是需要被检查的,他们的外框是亮绿色。每个黑方格都有一个灰色的指针指向他们的父节点A。

下一步,我们需要从open list中选一个与起点A相邻的方格。但是到底选择哪个方格好呢?选F值最小的那个。我们看看下图中的一些方格。在标有字母的方格中G = 10 。这是因为水平方向从起点到那里只有一个方格的距离。与起点直接相邻的上方,下方,左方的方格的 G 值都是 10 ,对角线的方格 G 值都是14 。H值通过估算起点到终点 ( 红色方格 ) 的 Manhattan 距离得到,仅作横向和纵向移动,并且忽略沿途的障碍。使用这种方式,起点右边的方格到终点有3 个方格的距离,因此 H = 30 。这个方格上方的方格到终点有 4 个方格的距离 ( 注意只计算横向和纵向距离 ) ,因此 H = 40 。
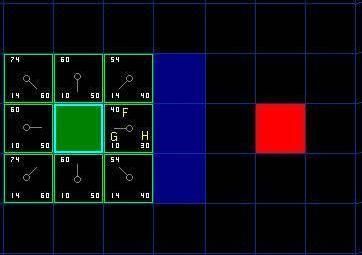
比较open list中节点的F值后,发现起点A右侧节点的F=40,值最小。选作当前处理节点,并将这个点从Open List删除,移到Close List中。
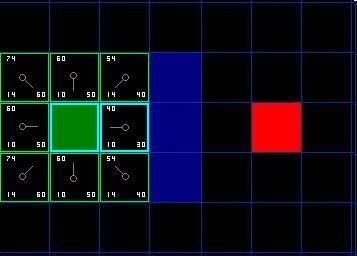
对这个节点周围的8个格子进行判断,若是不可通过(比如墙,水,或是其他非法地形)或已经在Close List中,则忽略。否则执行以下步骤:
- 若当前处理节点的相邻格子已经在Open List中,则检查这条路径是否更优,即计算经由当前处理节点到达那个方格是否具有更小的 G值。如果没有,不做任何操作。相反,如果G值更小,则把那个方格的父节点设为当前处理节点 ( 我们选中的方格 ) ,然后重新计算那个方格的 F 值和 G 值。
- 若当前处理节点的相邻格子不在Open List中,那么把它加入,并将它的父节点设置为该节点。
按照上述规则我们继续搜索,选择起点右边的方格作为当前处理节点。它的外框用蓝线打亮,被放入了close list 中。然后我们检查与它相邻的方格。它右侧的3个方格是墙壁,我们忽略。它左边的方格是起点,在 close list 中,我们也忽略。其他4个相邻的方格均在 open list 中,我们需要检查经由当前节点到达那里的路径是否更好。我们看看上面的方格,它现在的G值为14 ,如果经由当前方格到达那里, G值将会为20( 其中10为从起点到达当前方格的G值,此外还要加上从当前方格纵向移动到上面方格的G值10) ,因此这不是最优的路径。看图就会明白直接从起点沿对角线移动到那个方格比先横向移动再纵向移动要好。
当把4个已经在 open list 中的相邻方格都检查后,没有发现经由当前节点的更好路径,因此不做任何改变。接下来要选择下一个待处理的节点。因此再次遍历open list ,现在open list中只有 7 个方格了,我们需要选择F值最小的那个。这次有两个方格的F值都是54,选哪个呢?没什么关系。从速度上考虑,选择最后加入 open list 的方格更快。因此选择起点右下方的方格,如下图所示。
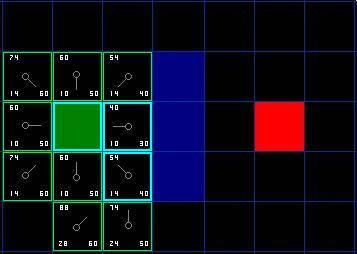
接下来把起点右下角F值为54的方格作为当前处理节点,检查其相邻的方格。我们发现它右边是墙(墙下面的一格也忽略掉,假定墙角不能直接穿越),忽略之。这样还剩下 5 个相邻的方格。当前方格下面的 2 个方格还没有加入 open list ,所以把它们加入,同时把当前方格设为他们的父亲。在剩下的 3 个方格中,有 2 个已经在 close list 中 ( 一个是起点,一个是当前方格上面的方格,外框被加亮的 ) ,我们忽略它们。最后一个方格,也就是当前方格左边的方格,检查经由当前方格到达那里是否具有更小的 G 值。没有,因此我们准备从 open list 中选择下一个待处理的方格。
不断重复这个过程,直到把终点也加入到了 open list 中,此时如下图所示。注意在起点下方 2 格处的方格的父亲已经与前面不同了。之前它的G值是28并且指向它右上方的方格。现在它的 G 值为 20 ,并且指向它正上方的方格。这是由于在寻路过程中的某处使用新路径时G值更小,因此父节点被重新设置,G和F值被重新计算。

那么我们怎样得到实际路径呢?很简单,如下图所示,从终点开始,沿着箭头向父节点移动,直至回到起点,这就是你的路径。

A*算法总结:
1. 把起点加入 open list 。
2. 重复如下过程:
a. 遍历open list ,查找F值最小的节点,把它作为当前要处理的节点,然后移到close list中
b. 对当前方格的 8 个相邻方格一一进行检查,如果它是不可抵达的或者它在close list中,忽略它。否则,做如下操作:
□ 如果它不在open list中,把它加入open list,并且把当前方格设置为它的父亲
□ 如果它已经在open list中,检查这条路径 ( 即经由当前方格到达它那里 ) 是否更近。如果更近,把它的父亲设置为当前方格,并重新计算它的G和F值。如果你的open list是按F值排序的话,改变后你可能需要重新排序。
c. 遇到下面情况停止搜索:
□ 把终点加入到了 open list 中,此时路径已经找到了,或者
□ 查找终点失败,并且open list 是空的,此时没有路径。
3. 从终点开始,每个方格沿着父节点移动直至起点,形成路径。
根据算法描述,伪代码如下:
function A*(start, goal)
closedSet := {}
openSet := {start}
cameFrom := the empty map
gScore := map with default value of Infinity
gScore[start] := 0
fScore := map with default value of Infinity
fScore[start] := heuristic_cost_estimate(start, goal)
while openSet is not empty
current := the node in openSet having the lowest fScore[] value
if current = goal
return reconstruct_path(cameFrom, current)
openSet.Remove(current)
closedSet.Add(current)
for each neighbor of current
if neighbor in closedSet
continue
tentative_gScore := gScore[current] + dist_between(current, neighbor)
if neighbor not in openSet
openSet.Add(neighbor)
else if tentative_gScore >= gScore[neighbor]
continue
cameFrom[neighbor] := current
gScore[neighbor] := tentative_gScore
fScore[neighbor] := gScore[neighbor] + heuristic_cost_estimate(neighbor, goal)
return failure
function reconstruct_path(cameFrom, current)
total_path := [current]
while current in cameFrom.Keys:
current := cameFrom[current]
total_path.append(current)
return total_path
根据上面的伪代码,用Python实现一个简单的最短路径搜寻。使用二维数组表示地图,其中1表示有障碍节点,0表示无障碍节点。
import numpy
from heapq import heappush,heappop
def heuristic_cost_estimate(neighbor, goal):
x = neighbor[0] - goal[0]
y = neighbor[1] - goal[1]
return abs(x) + abs(y)
def dist_between(a, b):
return (b[0] - a[0]) ** 2 + (b[1] - a[1]) ** 2
def reconstruct_path(came_from, current):
path = [current]
while current in came_from:
current = came_from[current]
path.append(current)
return path
def astar(array, start, goal):
directions = [(0,1),(0,-1),(1,0),(-1,0),(1,1),(1,-1),(-1,1),(-1,-1)]
close_set = set()
came_from = {}
gscore = {start:0}
fscore = {start:heuristic_cost_estimate(start, goal)}
openSet = []
heappush(openSet, (fscore[start], start))
while openSet:
current = heappop(openSet)[1]
if current == goal:
return reconstruct_path(came_from, current)
close_set.add(current)
for i, j in directions:
neighbor = current[0] + i, current[1] + j
if 0 <= neighbor[0] < array.shape[0]:
if 0 <= neighbor[1] < array.shape[1]:
if array[neighbor[0]][neighbor[1]] == 1:
continue
else:
continue
else:
continue
if neighbor in close_set:
continue
tentative_gScore = gscore[current] + dist_between(current, neighbor)
if neighbor not in [i[1] for i in openSet]:
heappush(openSet, (fscore.get(neighbor, numpy.inf), neighbor))
elif tentative_gScore >= gscore.get(neighbor, numpy.inf):
continue
came_from[neighbor] = current
gscore[neighbor] = tentative_gScore
fscore[neighbor] = tentative_gScore + heuristic_cost_estimate(neighbor, goal)
return False
if __name__ == "__main__":
nmap = numpy.array([
[0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[1,1,1,1,1,1,1,1,1,1,1,1,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[1,0,1,1,1,1,1,1,1,1,1,1,1,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[1,1,1,1,1,1,1,1,1,1,1,1,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[1,0,1,1,1,1,1,1,1,1,1,1,1,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[1,1,1,1,1,1,1,1,1,1,1,1,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0]])
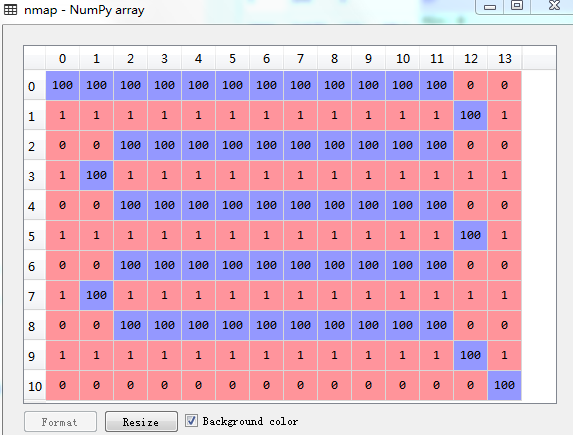
path = astar(nmap, (0,0), (10,13))
for i in range(len(path)):
nmap[path[i]] = 100
使用Spyder IDE可以在Variable explorer中查看和修改二维数组,数组中的值根据大小以不同颜色显示。将搜寻到的路径节点赋予一个较大的值,可以直观地看出从起点到终点的路径。
使用Pillow、OpenCV或Matplotlib等图像处理库,可以在自己绘制的图片上进行寻路:
import numpy as np
from heapq import heappush,heappop
def heuristic_cost_estimate(neighbor, goal):
x = neighbor[0] - goal[0]
y = neighbor[1] - goal[1]
return abs(x) + abs(y)
def dist_between(a, b):
return (b[0] - a[0]) ** 2 + (b[1] - a[1]) ** 2
def reconstruct_path(came_from, current):
path = [current]
while current in came_from:
current = came_from[current]
path.append(current)
return path
def astar(array, start, goal):
directions = [(0,1),(0,-1),(1,0),(-1,0),(1,1),(1,-1),(-1,1),(-1,-1)]
close_set = set()
came_from = {}
gscore = {start:0}
fscore = {start:heuristic_cost_estimate(start, goal)}
openSet = []
heappush(openSet, (fscore[start], start))
while openSet:
current = heappop(openSet)[1]
if current == goal:
return reconstruct_path(came_from, current)
close_set.add(current)
for i, j in directions:
neighbor = current[0] + i, current[1] + j
if 0 <= neighbor[0] < array.shape[0]:
if 0 <= neighbor[1] < array.shape[1]:
if array[neighbor[0]][neighbor[1]] == 0:
continue
else:
continue
else:
continue
if neighbor in close_set:
continue
tentative_gScore = gscore[current] + dist_between(current, neighbor)
if neighbor not in [i[1] for i in openSet]:
heappush(openSet, (fscore.get(neighbor, np.inf), neighbor))
elif tentative_gScore >= gscore.get(neighbor, np.inf):
continue
came_from[neighbor] = current
gscore[neighbor] = tentative_gScore
fscore[neighbor] = tentative_gScore + heuristic_cost_estimate(neighbor, goal)
return False
if __name__ == "__main__":
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('C:\Users\Administrator\Desktop\map.bmp')
map = np.array(img)
path = astar(map, (0,0), (260,260))
img = np.array(img.convert('RGB'))
for i in range(len(path)):
img[path[i]] = [0,0,255]
plt.imshow(img)
plt.axis('off')
plt.show()
在画图程序中绘制一个300×300像素的地图,填充黑色表示障碍,并将其存为灰度图。计算出路径后转换为彩色图,并绘制出路线:
上面产生的路径贴着障碍物边缘,如果对实际机器人或者游戏中的角色进行路径规划,要考虑其实际大小,将地图上的障碍物尺寸扩大(inflate),避免与障碍物发生碰撞。
参考:
Dijkstra算法(一)之 C语言详解
最短路径—Dijkstra算法和Floyd算法
A*,Dijkstra,BFS算法性能比较及A*算法的应用
用python实现基本A*算法
http://theory.stanford.edu/~amitp/GameProgramming/
Introduction to A*
implementation guide
PYTHON A* PATHFINDING (WITH BINARY HEAP)
http://www.policyalmanac.org/games/aStarTutorial.htm
A-Star (A*) Implementation in C# (Path Finding, PathFinder)
Implementing A Star (A*) Path Planning Algorithm On A 3-DOF PR2 Robot In Python