SAS函数学习笔记——字符操作
目录
一、字符变量的存储长度
二、常用函数介绍
1、改变字符大小写的函数
2、从字符串中移除字符的函数
3、查找字符、字符串的函数
4、提取部分字符串的函数
5、连接两个或多个字符串的函数
6、从字符串中删除空格的函数
7、比较字符串的函数
8、将字符串划分为“单词”的函数
9、用于替换字符串中的字母或单词的函数
10、计算字符串长度的函数
11、计算字符串中字母或子字符串数量的函数
12、其他字符串的函数
一、字符变量的存储长度
SAS怎样定义字符变量的存储长度?
DATA EXAMPLE1;
INPUT GROUP $ @10 STRING $3.;
LEFT = 'X '; /* X和4个空格 */
RIGHT = ' X'; /* 4个空格和X */
SUB = SUBSTR(GROUP,1,2);
REP = REPEAT(GROUP,1);
DATALINES;
ABCDEFGH 123
XXX 4
Y 5
;
/*VARNUM选项——要求变量按照它们在SAS数据集中出现的顺序排列,而不是默认的字母顺序。*/
PROC CONTENTS DATA=EXAMPLE1 VARNUM;
TITLE "PROC CONTENTS for Data Set EXAMPLE1";
RUN;
/*用length语句给变量定义长度*/
LENGTH GENDER $ 6;
IF SEX = 1 THEN GENDER = 'MALE';
ELSE IF SEX = 2 THEN GENDER = 'FEMALE';输出结果:
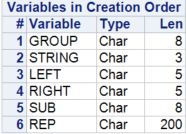
注意:
- 使用列表输入读取GROUP,没有制定长度,默认长度为8。
- 因为STRING是用一个informat读取的,所以长度被设置为informat宽度3。
- LEFT和RIGHT都是用赋值语句创建的。因此,这两个变量的长度等于等号后面的字面值中的字节数。
- 注意,如果一个变量在数据步骤中出现多次,其长度由对该变量的第一次引用决定。
- 确保为字符变量分配适当的长度,最好的方法可能是使用length语句。
二、常用函数介绍
一些通用规则
- 如果没有指定长度,那么结果的长度与参数长度一致。
- character-value:任何SAS字符表达式
- 全局宏变量_CHARACTER_:数据集中所有字符变量
1、改变字符大小写的函数
UPCASE(character-value): 将所有字母更改为大写
LOWCASE(character-value): 将所有字母更改为小写
PROPCASE(character-value): 将字符串中每个单词的第一个字母大写注意:PROPCASE以空格来区分不同单词
举例:
CHAR = "ABCxyz"
Function Returns
——————————————————————————————
UPCASE(CHAR) "ABCXYZ"
UPCASE("a1%m?") "A1%M?"
LOWCASE(CHAR) "abcxyz"
LOWCASE("A1%M?") "a1%m?"
PROPCASE(CHAR) "Abcxyz"
PROPCASE("a1%m?") "A1%m?"
PROPCASE("mr. george w. bush") "Mr. George W. Bush"
2、从字符串中移除字符的函数
COMPBL(character-value): (压缩空格)可以用一个空格替换多个空格。
COMPRESS(character-value <,'compress-list'>):从字符值中删除指定的字符。注意:
compress-list:
- 是要删除的字符的可选列表。
- 如果省略此参数,则要删除的默认字符为空格。
- 如果包含要删除的值列表,则只会删除这些字符。
- 如果列表中没有包含空格,则空格将不会被删除。
举例:
CHAR = "A C XYZ"
Function Returns
—————————————————————————————
COMPBL(CHAR) "A C XYZ"
COMPBL("X Y Z LAST") "X Y Z LAST"
—————————————————————————————
CHAR = "A C123XYZ"
Function Returns
—————————————————————————————
COMPRESS("A C XYZ") "ACXYZ"
COMPRESS("(908) 777-1234"," (-)") "9087771234"
COMPRESS(CHAR,"0123456789") "A CXYZ"
实例扩充:
data compress_ex;
s="中国AAAbABBBc_134@3$,!.";
s1=s; output;
s1=compress(s,,'d'); output;*除去数字;
s1=compress(s,,'a'); output;*除去字母;
s1=compress(s,,'f'); output;*除去字母、下划线;
s1=compress(s,,'l'); output;*除去小写字母;
s1=compress(s,,'u'); output;*除去大写字母;
s1=compress(s,,'s'); output;*除去特殊字符(目前实例无法验证);
s1=compress(s,,'n'); output;*除去数字、下划线、字母;
s1=compress(s,,'p'); output;*除去标点符号;
s1=compress(s,,'np'); output;*保留中文(基于目前实例);
run;3、查找字符、字符串的函数
ANYALNUM(character-value <,start>):定位第一个出现的字母数字字符并返回其位置。如果没有找到,函数返回0。
NOTALNUM(character-value <,start>)
ANYALPHA(character-value <,start>):定位第一个出现的阿尔法字符(任何大写或小写字母)并返回其位置。如果没有找到,函数返回0。
NOTALPHA(character-value <,start>)
ANYDIGIT(character-value <,start>):定位第一个出现的数字(numeric)并返回其位置。如果没有找到,函数返回0。
NOTDIGIT(character-value <,start>)
ANYPUNCT(character-value <,start>):定位第一个出现的标点字符并返回其位置。如果没有找到,函数返回0。
ANYSPACE(character-value <,start>):定位第一次出现的空格、水平或垂直制表符、回车、换行和换页并返回其位置。如果没有找到,函数返回0。
NOTUPPER(character-value <,start>):定位第一个字符串中非大写字母的字符的位置。如果没有找到,函数返回0。注意:
start:指定开始搜索的字符串位置。默认从字符串的开头开始。
- 如果start^=0,则从该数字的绝对值在字符串中的位置开始搜索。
- 如果start>0,则从左到右进行搜索;
- 如果start<0,则从右到左进行搜索。
- 如果start>字符串长度的负值,会导致从右向左的扫描,从字符串的末尾开始。
- 如果start>字符串长度的正数,如果是0,函数返回0。
标点符号:
! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~
注意:
- find-string:一个字符变量或字符串文字
- modifiers:
i:忽略大小写
t:忽略find-string中的尾随空格。
举例:
STRING = "ABC 123 ?xyz_n_";
Function Returns
————————————————————————————————
ANYALNUM(STRING) 1 (position of "A")
ANYALNUM("??%%") 0 (no alpha-numeric characters)
ANYALNUM(STRING,5) 5 (position of "1")
ANYALNUM(STRING,-4) 3 (position of "C")
ANYALNUM(STRING,6) 6 (position of "2")
NOTALNUM(STRING) 4 (position of the 1st blank)
NOTALNUM("Testing123") 0 (all alpha-numeric values)
NOTALNUM("??%%") 1 (position of the "?")
NOTALNUM(STRING,5) 8 (position of the 2nd blank)
NOTALNUM(STRING,-6) 4 (position of the 1st blank)
NOTALNUM(STRING,8) 9 (position of the "?")
—————————————————————————————————
ANYALPHA(STRING) 1 (position of "A")
ANYALPHA("??%%") 0 (no alpha characters)
ANYALPHA(STRING,5) 10 (position of "x")
ANYALPHA(STRING,-4) 3 (position of "C")
ANYALPHA(STRING,6) 10 (position of "x")
NOTALPHA(STRING) 4 (position of 1st blank)
NOTALPHA("ABCabc") 0 (all alpha characters)
NOTALPHA("??%%") 1 (position of first "?")
NOTALPHA(STRING,5) 5 (position of "1")
NOTALPHA(STRING,-10) 9 (start at position 10 and search left, position of "?")
NOTALPHA(STRING,2) 4 (position of 1st blank)
—————————————————————————————————
ANYDIGIT(STRING) 5 (position of "1")
ANYDIGIT("??%%") 0 (no digits)
ANYDIGIT(STRING,5) 5 (position of "1")
ANYDIGIT(STRING,-4) 0 (no digits from position 4 to 1)
ANYDIGIT(STRING,6) 6 (position of "2")
NOTDIGIT(STRING) 1 (position of "A")
NOTDIGIT("123456") 0 (all digits)
NOTDIGIT("??%%") 1 (position of "?")
NOTDIGIT(STRING,5) 8 (position of 2nd blank)
NOTDIGIT(STRING,-6) 4 (position of 1st blank)
NOTDIGIT(STRING,6) 8 (position of 2nd blank)
—————————————————————————————————
ANYSPACE(STRING) 4 (position of the first blank)
ANYSPACE("??%%") 0 (no spaces)
ANYSPACE(STRING,5) 8 (position of the second blank)
ANYSPACE(STRING,-4) 4 (position of the first blank)
ANYSPACE(STRING,6) 8 (position of the second blank)
—————————————————————————————————
STRING = "A!C 123 ?xyz_n_";
Function Returns
—————————————————————————————————
ANYPUNCT(STRING) 2 (position of "!")
ANYPUNCT("?? %%") 1 (position of "?")
ANYPUNCT(STRING,5) 9 (position of "?")
ANYPUNCT(STRING,-4) 2 (starts at position 4 and goes left, positionof "!" )
ANYPUNCT(STRING,-3) 2 (starts at "C" and goes left, position of "!")
——————————————————————————————————
STRING = "ABC 123 ?xyz_n_";
Function Returns
—————————————————————————————————
NOTUPPER("ABCDabcd") 5 (position of "a")
NOTUPPER("ABCDEFG") 0 (all uppercase characters)
NOTUPPER(STRING) 4 (position of 1st blank)
NOTUPPER("??%%") 1 (position of "?")
NOTUPPER(STRING,5) 5 (position of "1")
NOTUPPER(STRING,-6) 6 (position of "2")
NOTUPPER(STRING,6) 6 (position of "2")
—————————————————————————————————
DATA ANYWHERE;
INPUT STRING $CHAR20.;
ALPHA_NUM = ANYALNUM(STRING);
ALPHA_NUM_9 = ANYALNUM(STRING,-999);
ALPHA = ANYALPHA(STRING);
ALPHA_5 = ANYALPHA(STRING,-5);
DIGIT = ANYDIGIT(STRING);
DIGIT_9 = ANYDIGIT(STRING,-999);
PUNCT = ANYPUNCT(STRING);
SPACE = ANYSPACE(STRING);
DATALINES;
Once upon a time 123
HELP!
987654321
;
RUN;结果:
注:第2行和第3行中第一个空格的位置分别是6和10。
STRING ALPHA_NUM ALPHA_NUM_9 ALPHA ALPHA_5 DIGIT DIGIT_9 PUNCT SPACE
————————————————————————————————————————————————————————
Once upon a time 123 1 20 1 4 18 20 0 5
HELP! 1 4 1 4 0 0 5 6
987654321 1 9 0 0 1 9 0 10
FIND/FINDC(character-value, find-string <,'modifiers'> <,start>)
在字符串中搜索给定的子字符串/字符。可以根据起始位置、搜索的方向、忽略大小写、是否尾随空格进行搜索。注意:
find-string:一个字符变量或字符串文字
modifiers:
i:忽略大小写
t:忽略find-string中的尾随空格。
C-v:反向查找
C-o:find-string中的参数只是用一次,之前不再重读find-string变量,详见例子
举例:
STRING1 = "Hello hello goodbye" and STRING2 = "hello"
Function Returns
————————————————————————————
FIND(STRING1, STRING2) 7
FIND(STRING1, STRING2, 'I') 1
FIND(STRING1,"bye") 17
FIND("abcxyzabc","abc",4) 7
FIND(STRING1, STRING2, "i", -99) 7
————————————————————————————
STRING1 = "Apples and Books" and STRING2 = "abcde"
Function Returns
———————————————————————————
FINDC(STRING1, STRING2) 5
FINDC(STRING1, STRING2, 'i') 1
FINDC(STRING1,"aple",'vi') 6
FINDC("abcxyzabc","abc",4) 7
———————————————————————————
DATA O_MODIFIER;
INPUT STRING $15.
@16 LOOK_FOR $1.;
POSITION = FINDC(STRING,LOOK_FOR,'IO');
DATALINES;
Capital A here A
Lower a here X
Apple B
;
PROC PRINT DATA=O_MODIFIER NOOBS HEADING=H;
TITLE "Listing of Data Set O_MODIFIER";
RUN;结果:
STRING LOOK_FOR POSITION
—————————————————————————
Capital A here A 2
Lower a here X 7
Apple B 1
—————————————————————————
INDEX(character-value, find-string): 在字符串中搜索给定的子字符串/字符。
可以根据起始位置、搜索的方向、忽略大小写、是否尾随空格进行搜索。
INDEXC(character-value, 'char1','char2','char3',...)
INDEXC(character-value, 'char1char2char3. . .')
INDEXW(character-value, find-string): 在一个字符串中搜索一个单词(空格、字符串的开始、字符串的结束)分隔的一组字母。注意,标点符号不被认为是单词边界。举例:
STRING = "ABCDEFG";
Function Returns
————————————————————————————
INDEX(STRING,'C') 3 (the position of the 'C')
INDEX(STRING,'DEF') 4 (the position of the 'D')
INDEX(STRING,'X') 0 (no "X" in the string)
INDEX(STRING,'ACE') 0 (no "ACE" in the string)
INDEXC(STRING,'F','C','G') 3 (position of the "C")
INDEXC(STRING,'FCG') 3 (position of the "C")
INDEXC(STRING,'X','Y','Z') 0 (no "X", "Y", or "Z" in STRING)
——————————————————————————————
STRING1 = "there is a the here" and STRING2 = "end in the."
Function Returns
————————————————————————————————
INDEXW(STRING1,"the") 12 (the word "the")
INDEXW("ABABAB","AB") 0 (no word boundaries around "AB")
INDEXW(STRING1,"er") 0 (not a word)
INDEXC(STRING2,"the") 0 (punctuation is not a word boundary)
VERIFY(character-value, verify-string):检查字符串是否包含任何不需要的值。举例:
STRING = "ABCXABD" and V = "ABCDE"
Function Returns
——————————————————————————————————
VERIFY(STRING,V) 4 ("X" is not in the verify string)
VERIFY(STRING,"ABCDEXYZ") 0 (no "bad" characters in STRING)
VERIFY(STRING,"ACD") 2 (position of the "B")
VERIFY("ABC ","ABC") 4 (position of the 1st blank)
VERIFY(TRIM("ABC "),"ABC") 0 (no invalid characters)
4、提取部分字符串的函数
SUBSTR(character-value, start <,length>):提取字符串的一部分。当SUBSTR函数在等号的左侧使用时,它可以将指定的字符放入现有字符串中。注意:
length: 为提取部分字符串的字符数。
如果省略此参数,SUBSTR函数将返回从字符串开始位置到字符串结束的所有字符。
if start<0,start=|start|;
length<0或length=0,函数将返回一个长度为0的字符串。
SUBSTR(character-value, start <,length>) = character-value:将一个或多个字符放入现有字符串中。注意:
length:是要放置在该字符串中的字符数。
如果省略length,则等号右边的所有字符替换character-value中的字符。
if start<0,start=|start|;
length<0或length=0,函数将返回一个长度为0的字符串。
举例:
5、连接两个或多个字符串的函数
CALL CATS(result, string-1 <,string-n>): 连接之前删除开头和结尾空白-S
CALL CATT(result, string-1 <,string-n>): 只删除尾部空格-
CALL CATX(separator, result, string-1 <,string-n>):连接之前删除开头和结尾空白,并默认以空格拼接-X
CAT(string-1, string-2 <,string-n>): 保持string-1的所有空格,与连接符||相同注意:
call 提高了性能。例如,CALL CATS(R, X, Y, Z)比R = CATS(R, X, Y, Z)快。
result:该变量如果长度不够,则会发生截断
如果是新变量,则储存拼接后的字符串;
如果是已存在的变量,侧该变量的首尾空格删除后,将结果拼接到该变量中。
string-n:是要连接的字符串。在连接之前,前导和尾随空格将被删除。
separator:分隔符;可以是字符串,用来拼接string-n。默认用空格。
以上函数可以通过连接符||,函数strip,trim,left代替
非call 的函数返回值,如果不定义长度,则默认为200.
举例:
A = "Bilbo" (no blanks)
B = " Frodo" (leading blanks)
C = "Hobbit " (trailing blanks)
D = " Gandalf " (leading and trailing blanks)
C1-C5是五个字符变量,分别为'A'、'B'、'C'、'D'和'E'。
Function Returns
————————————————————————————————
CALL CATS(RESULT, A, B) "BilboFrodo"
CALL CATS(RESULT, B, C, D) "FrodoHobbitGandalf"
CALL CATS(RESULT, "Hello", D) "HelloGandalf"
CALL CATT(RESULT, A, B) "Bilbo Frodo"
CALL CATT(RESULT, B, C, D) " FrodoHobbit Gandalf"
CALL CATT(RESULT, "Hello", D) "Hello Gandalf"
CALL CATX(" ", RESULT, A, B) "Bilbo Frodo"
CALL CATX(",", RESULT, B, C, D) "Frodo,Hobbit,Gandalf"
CALL CATX(":", RESULT, "Hello", D) "Hello:Gandalf"
CALL CATX(", ", RESULT, "Hello", D) "Hello, Gandalf"
CALL CATX("***", RESULT, A, B) "Bilbo***Frodo"
CAT(A, B) "Bilbo Frodo"
CAT(B, C, D) " FrodoHobbit Gandalf "
CAT("Hello", D) "Hello Gandalf "
CAT(OF C1-C5) "ABCDE"
CATS(A, B) "BilboFrodo"
CATS(B, C, D) "FrodoHobbitGandalf"
CATS("Hello", D) "HelloGandalf"
CATS(OF C1-C5) "ABCDE"
CATT(A, B) "Bilbo Frodo"
CATT(B, C, D) " FrodoHobbit Gandalf"
CATT("Hello", D) "Hello Gandalf"
CATT(OF C1-C5) "ABCDE"
CATX(" ", A, B) "Bilbo Frodo"
CATX(":"B, C, D) "Frodo:Hobbit:Gandalf"
CATX("***", "Hello", D) "Hello***Gandalf"
CATX("," ,OF C1-C5) "A,B,C,D,E"
————————————————————————————————
RESULT = " 123 "(leading and trailing blanks)
Function Returns
—————————————————————————————————
CALL CATS(RESULT, A, B) "123BilboFrodo"
CALL CATS(RESULT, B, C, D) "123FrodoHobbitGandalf"
CALL CATS(RESULT, "Hello", D) "123HelloGandalf"
CALL CATT(RESULT, A, B) " 123Bilbo Frodo"
CALL CATT(RESULT, B, C, D) " 123 FrodoHobbit Gandalf"
CALL CATT(RESULT, "Hello", D) " 123Hello Gandalf"
CALL CATX(" ", RESULT, A, B) "123 Bilbo Frodo"
CALL CATX(",", RESULT, B, C, D) "123,Frodo,Hobbit,Gandalf"
CALL CATX(":", RESULT, "Hello", D) "123:Hello:Gandalf"
CALL CATX(", ", RESULT, "Hello", D) "123, Hello, Gandalf"
CALL CATX("***", RESULT, A, B) "123***Bilbo***Frodo"
6、从字符串中删除空格的函数
LEFT(character-value): 函数会将第一个非空格字符移到第一个位置,并将多余的空格移到末尾;
right(character-value):函数将把非空格文本移到右边,把多余的空格移到左边。
TRIM(character-value): 删除尾部空格。返回的变量的长度将与实参的长度相同,除非这个变量的长度已经在前面定义过。
TRIMN(character-value):同上
STRIP(character-value):去掉首尾空格。注意:
如果TRIM函数的结果被赋值给一个长度比TRIM参数长的变量,得到的变量将被填充空白。
TRIM和TRIMN之间的区别是,TRIM函数为一个空白字符串返回一个空白,而TRIMN返回一个空字符串(零空白)。
举例:
STRING1 = " ABC"
STRING2 = "ABC "
STRING3 = "ABC "
STRING4 = " XYZ"
STRING = " abc "
Function Returns
————————————————————————————————
LEFT(STRING1) "ABC "
LEFT(" 123 ") "123 "
RIGHT(STRING2) " ABC"
RIGHT(" 123 ") " 123"
TRIM(STRING3) "ABC"
TRIM(STRING4) " XYZ"
TRIM("A B C ") "A B C"
TRIM("A ") || TRIM("B ") "AB"
TRIM(" ") " " (length = 1)
TRIM(" ") "" (length = 0)
STRIP(STRING) "abc" (如果之前为result分配的长度为3,则会添加尾随空格)
STRIP(" LEADING AND TRAILING ") "LEADING AND TRAILING"
7、比较字符串的函数
COMPARE(string-1, string-2 <,'modifiers'>): 根据modifiers比较两个字符串;相同返回0,不同则返回不同的位数,正负取决于ASCII码的前后。
CALL COMPCOST('operation-1', cost-1 <,'operation-2', cost-2 ...>):确定两个字符串之间的相似性,使用一种称为广义编辑距离的方法。
COMPGED(string-1, string-2 <,maxcost> <,'modifiers'>): 计算两个字符串之间的相似度
COMPLEV(string-1, string-2 <,maxcost> <,'modifiers'>): 计算两个字符串之间的相似度
SOUNDEX(character-value): 创建与文本字符串等价的语音字符串。通常用于尝试匹配可能有一些拼写差异的名称。
SPEDIS(word-1, word-2): 计算两个单词之间的拼写距离。两个单词越相似,得分越低。分数为0表示精确匹配。注意:
modifiers:
I:忽略大小写
L:删除引导空格
N:一般用于无效的SAS名。
:(冒号):截断较长的字符串,长度为较短的字符串的长度。等同于=:
举例:
string1 = "AbC"
string2 = " ABC"
string3 = " 'ABC'n"
string4 = "ABCXYZ"
Function Returns
—————————————————————————————
COMPARE(string1,string4) 2 ("B" comes before "b")
COMPARE(string4,string1) -2
COMPARE(string1,string2,'i') 1
COMPARE(string1,string4,':I') 0
COMPARE(string1,string3,'nl') 4
COMPARE(string1,string3,'ln') 1
8、将字符串划分为“单词”的函数
SCAN(character-value, n-word <,'delimiter-list'>): 从字符表达式中提取指定的单词,其中单词定义为由一组指定的分隔符分隔的字符。
SCANQ(character-value, qn-word <,'delimiter-list'>):
CALL SCAN(character-value, n-word, position, length <,'delimiter-list'>)
CALL SCAN(character-value, n-word, position, length <,'delimiter-list'>)注意:
1、返回变量的长度为200,除非前面定义过。
2、n-word:是字符串中的第n个“单词”;
如果n大于单词数,则返回一个不包含字符的值。
如果n为负数,则从右向左扫描字符值。值为零无效。
n-word是字符串中的第n个“单词”。
如果n为负,则从右向左进行扫描。
如果n大于单词数或0,SCANQ函数将返回一个空白值。
位于第一个单词之前或最后一个单词之后的分隔符将被忽略。
如果两个或多个分隔符位于两个单词之间,则将它们视为一个分隔符。
如果字符值包含一组引号,则忽略这些引号内的任何分隔符。
3、delimiter-list: 可选参数。如果省略,则默认定界符集为(对于ASCII环境):空格 . < ( + & ! $ * ) ; ^ - / , % |
第一个单词之前的分隔符不起作用。两个或多个连续分隔符被视为一个。
举例:
STRING1 = "ABC DEF"
STRING2 = "ONE?TWO THREE+FOUR|FIVE"
Function Returns
—————————————————————————
SCAN(STRING1,2) "DEF"
SCAN(STRING1,-1) "DEF"
SCAN(STRING1,3) no characters
SCAN(STRING2,4) "FIVE"
SCAN(STRING2,2," ") "THREE+FOUR|FIVE"
SCAN(STRING1,0) An error in the SAS log
—————————————————————————
STRING1 = "ABC DEF"
STRING2 = "ONE TWO THREE FOUR FIVE"
STRING3 = "'AB CD' 'X Y'"
STRING4 = "ONE# ::TWO"
Function Returns
—————————————————————————————————
SCANQ(STRING1,2) "DEF"
SCANQ(STRING1,-1) "DEF"
SCANQ(STRING1,3) no characters
SCANQ(STRING2,4," ") "FOUR"
SCANQ(STRING3,2) "'X Y'"
SCANQ(STRING1,0) no characters
SCANQ(STRING4,2," #:") "TWO"
CALL SCAN(STRING1,2,POSITION,LENGTH) 5 3
CALL SCAN(STRING1,-1,POSITION,LENGTH) 5 3
CALL SCAN(STRING1,3,POSITION,LENGTH) 0 0
CALL SCAN(STRING2,1,POSITION,LENGTH) 1 7
CALL SCAN(STRING2,4,POSITION,LENGTH) 20 4
CALL SCAN(STRING2,2,POSITION,LENGTH," ") 9 15
CALL SCAN(STRING1,0,POSITION,LENGTH) missing missing
CALL SCANQ(STRING1,2,POSITION,LENGTH) 5 3
CALL SCANQ(STRING1,-1,POSITION,LENGTH) 5 3
CALL SCANQ(STRING1,3,POSITION,LENGTH) 0 0
CALL SCANQ(STRING2,4,POSITION,LENGTH) 5 3
CALL SCANQ(STRING2,2,POSITION,LENGTH," ") 9 15
CALL SCANQ(STRING1,0,POSITION,LENGTH) 0 0
CALL SCANQ(STRING3,2,POSITION,LENGTH) 9 5
9、用于替换字符串中的字母或单词的函数
TRANSLATE(character-value, to-1, from-1 <,… to-n, from-n>):用一个字符值交换另一个字符值。from-n中列出的每个字符都被更改为to-n中相应的值。如果字符值没有在-n中列出,它将不受影响。
例如,您可能希望将值1-5更改为值A-E。
TRANWRD(character-value, from-string, to-string):注意:
to-n:一个单个字符或一列字符值。
from-n:单个字符或字符列表。
from-string:一个或多个您想要替换为字符串中的一个或多个字符的字符。
to-string:替换整个from-string的一个或多个字符。
举例:
CHAR = "12X45", ANS = "Y"
STRING = "123 Elm Road"
FROM = "Road"
TO = "Rd."
Function Returns
—————————————————————————————————————
TRANSLATE('13254',"abcde","12345") "acbed"
TRANSLATE(CHAR,"ABCDE","12345") "ABXDE"
TRANSLATE(CHAR,'A','1','B','2','C','3','D','4','E','5') "ABXDE"
TRANSLATE(ANS,"10","YN") "1"
TRANWRD(STRING,FROM,TO) "123 Elm Rd."
TRANWRD("Now is the time","is","is not") "Now is not the time"
TRANWRD("one two three","four","4") "one two three"
TRANWRD("Mr. Rogers","Mr."," ") " Rogers"
TRANWRD("ONE TWO THREE","ONE TWO","A B") "A B THREE"
10、计算字符串长度的函数
LENGTH(character-value): 确定字符值的长度,不包括尾随空格。null参数返回值为1。
LENGTHN(character-value):确定字符值的长度,不包括尾随空格。null参数返回值为0。
LENGTHC(character-value):确定字符值(包括尾随空格)的长度
LENGTHM(character-value):确定内存中字符变量的长度。举例:
CHAR = "ABC "
Function Returns
——————————————————————
LENGTH("ABC") 3
LENGTH(CHAR) 3
LENGTH(" ") 1
LENGTH("ABC") 3
LENGTH(CHAR) 3
LENGTH(" ") 0
LENGTHC("ABC") 3
LENGTHC(CHAR) 6
LENGTHC(" ") 1
LENGTHM("ABC") 3
LENGTHM(CHAR) 6
LENGTHM(" ") 1
11、计算字符串中字母或子字符串数量的函数
COUNT(character-value, find-string <,'modifiers'>):计算给定子字符串在字符串中出现的次数,如果没有找到该子字符串,函数将返回0
COUNTC(character-value, characters <,'modifiers'>):注意:
modifiers:
I:忽略大小写
T:忽略尾部空格。
举例:
STRING1 = "How Now Brown COW" and STRING2 = "ow"
Function Returns
———————————————————————————————
COUNT(STRING1, STRING2) 3
COUNT(STRING1,STRING2,'I') 4
COUNT(STRING1, "XX") 0
COUNT("ding and dong","g ") 1
COUNT("ding and dong","g ","T") 2
COUNTC("AaBbbCDE","CBA") 3
COUNTC("AaBbbCDE","CBA",'I') 7
COUNTC(STRING1, STRING2) 6
COUNTC(STRING1,STRING2,'I') 8
COUNTC(STRING1, "XX") 0
COUNTC("ding and dong","g ") 4 (2 g's and 2 blanks)
COUNTC("ding and dong","g ","T") 2 (blanks trimmed)
COUNTC("ABCDEabcde","BCD",'VI') 4 (A, E, a, and e)
12、其他字符串的函数
MISSING(variable): 确定参数是否缺失(字符或数字)值。如果该值是缺失值,则返回1 (true),否则返回0 (false)。
RANK(letter): 获取ASCII(或EBCDIC)字符的相对位置。
REPEAT(character-value, n):复制一个字符串的多个副本。
REVERSE(character-value): 颠倒字符值的文本顺序。注意:
如果您想要将每个字符与数字关联起来,以便数组的下标可以指向特定的字符,RANK是非常有用的。
举例:
NUM1 = 5, NUM2 = ., CHAR1 = "ABC", and CHAR2 = " "
Function Returns
———————————————————————————
MISSING(NUM1) 0
MISSING(NUM2) 1
MISSING(CHAR1) 0
MISSING(CHAR2) 1
———————————————————————————
STRING1 = "A" and STRING2 = "XYZ"
Function Returns
——————————————————————————
RANK(STRING1) 65
RANK(STRING2) 88
RANK("X") 88
RANK("a") 97
——————————————————————————
STRING = "ABC"
Function Returns
——————————————————————————————
REPEAT(STRING,1) "ABCABC"
REPEAT("HELLO ",3) "HELLO HELLO HELLO HELLO"
REPEAT("*",5) "******"
——————————————————————————————
STRING1 = "ABCDE" and STRING2 = "XYZ "
Function Returns
——————————————————————————————
REVERSE(STRING1) "EDCBA"
REVERSE(STRING2) " ZYX"
REVERSE("1234") "4321"