Linux常用命令for QA-数据脱敏版1
1. 19年cctv春晚 1;ET:SF;ETID:10300;IT:SF;ITID:10301;Q:中央电视台春节联欢晚会2019;BDID:8012530;SHOWID:422625;UID:112233;TIME:1234567890
19年cctv春晚直播 1;ET:SF;ETID:10300;IT:SF;ITID:10301;Q:中央电视台春节联欢晚会2019;BDID:8012530;SHOWID:422625;UID:112233;TIME:1234567890
根据需求,取Q的值
grep -E "Q.*?;" -o sf20190125.txt | tr -d "Q:"|tr -d ";" >3.txt
处理结果
中央电视台春节联欢晚会2019
东方卫视春节联欢晚会2019
tr用一个字符来替换另一个字符,或者可以完全除去一些字符。除去重复字
2.在文件最后一列加,
sed 's/$/\,/g' a.txt
sed 's/$/\,/g' -i a.txt
或者不需要转义 sed 's/$/,/g' a.txt
"^"代表行首,"$"代表行尾
字符g代表每行出现的字符全部替换
如果想导出文件,在命令末尾加"> outfile_name"
sed 's/$/,/g' a.txt > b.txt
vim模式:
:%s/$/,/g
3.
了解 Hadoop,Hive,Hbase。
了解前端技术 html,css 和 javascript 以及基本的使用。
熟练掌握core Java 。
以上文本想实现效果:
了解 Hadoop,Hive,Hbase
了解前端技术 html,css 和 javascript 以及基本的使用
熟练掌握core Java
sed -e "s/ /""/g" -e "s/。/""/g" 1.txt
-e :直接在命令行模式上进行sed动作编辑,此为默认选项 -e : 可以在同一行里执行多条命令
awk '{$1="";print $0}' 1.txt 去除第一列

crontab为每个用户都会创建一个

查看某个用户的 cron 任务: crontab -u username -l

以下脚本则列出所有用户的 cron 任务:
for user in $(cut -f1 -d: /etc/passwd); do echo $user; crontab -u $user -l; done
或者 cat /etc/passwd | cut -f 1 -d : |xargs -I {} crontab -l -u {}
注:与用户相关的系统配置文件主要有/etc/passwd 和/etc/shadow,/etc/passwd 是系统识别用户的一个文件

source ~/.bash_profile文件失效 每次需要手动刷新,写了脚本 定时任务都不可以成功。。。
解决如下:
使用iTerm 安装了oh-my-zsh之后,就不再会每次开iTerm或者终端的时候,执行默认文件 ~/.bash_profile 而是去执行 .zshrc
所以要到 .zshrc文件中加上source ~/.bash_profile
进入到用户目录 /Users/lishan
➜ ~ vim .zshrc
在.zshrc最后加入source ~/.bash_profile
重启iterm 生效
vim模式下
/ 搜索时,n向下,N向上 s? 搜索时,N向下,n向上
w向后 b向前 shift+6 行首 shift+4 行尾 cx删除当前字符
y数字(如5)+x删除含当前字符往后的5个字符
tauqdd删除当前行
数字(如10)dd,删除含当前行往后的10行
删除所有内容 – 方法1 按ggdG 方法2 :%d
wdG:删除光标所在到最后一行的所有数据 gg行首 G或者shift+g行尾
批量替换:把3319全部替换为3318 按esc,输入:%s /3319/3318/g 或者:%s !3319!3318!g 注:不要空格
批量替换,对/转义 :%s /\/Users\/chenyunnan\/apps\/lua\/ailua/\/data\/www\/ailua/g 或者 %s !\/Users\/chenyunnan\/apps\/lua\/ailua!\/data\/www\/ailua!g
vim下跳转到指定行 数字+G 519G 或者 按esc,输入:519,回车
按esc 输入 :set nu 和 :set nonu 显示/不显示行号
在命令行中输入行号然后按回车:
:123
123G 非命令行模式
vim按下V标记选择,再按下=,解决格式错乱
剪切当前行且复制到某个位置DD 光标移动到指定行,按下P
control+C 或者Z终止当前命令 control+D == exit 退出当前服务器
control+A 切换到命令行开始 control+E 切换到命令行末尾 option+左箭头 命令行按字符向前跳转 option+右箭头 命令行按字符向后跳转
翻屏
Ctrl+f: 向下翻一屏 Ctrl+b: 向上翻一屏 Ctrl+d: 向下翻半屏 Ctrl+u: 向上翻半屏
sudo mkdir aiclass/frontlistener -p 建立层级目录
history |grep status|grep -v grep
sudo cp -r 递归拷贝文件
查找文件夹目录名称 sudo find / -name docs 注:/后面一定要加空格
文件名称 sudo find / -name *.sql
Linux which命令用于查找文件 which指令会在环境变量$PATH设置的目录里查找符合条件的文件
whoami 查看当前用户
查看机器对应的外网IP
curl ifconfig.me
curl members.3322.org/dyndns/getip
curl ipinfo.io
查看IP是否可以使用
curl http://httpbin.org/ip
压缩文件夹A为tar包A.tar
sudo tar czvf aiclassapi.tar aiclassapi/
使用Linux shell 命令,查找test.txt文件中以c/x结尾的记录
grep -E 'c|x$' test.txt
使用元字符匹配$ 行尾定位符,匹配输入字符串的结束位置
编写Linux shell脚本,实现如下功能。条件: Android手机已经连接PC ;
功能:截取手机屏幕,并将屏幕截图发送到PC,保存到文件名称是:截图时间.png
adb shell screencap -p /sdcard/01.png #截屏
adb pull /sdcard/01.png home/test/screenshot / # pull
1 查看CPU
1.1 查看CPU个数
# cat /proc/cpuinfo | grep "physical id" | uniq | wc -l
2 **uniq命令:删除重复行;wc –l命令:统计行数**
1.2 查看CPU核数
[lishan@xx-xx-xx-xx ~]$ cat /proc/cpuinfo | grep 'model name' |wc -l
8
1.3 查看CPU型号
[lishan@xx-xx-xx-xx ~]$ cat /proc/cpuinfo | grep 'model name'
model name : Intel Core Processor (Broadwell)
总结:该服务器有2个4核CPU,型号Intel(R) Xeon(R) CPU E5630 @ 2.53GHz
2 查看内存
2.1 查看内存总数
#cat /proc/meminfo | grep MemTotal
MemTotal: 32941268 kB //内存32G
或者
[lishan@xx-xx-xx-xx ~]$ free -h
total used free shared buff/cache available
Mem: 15G 323M 5.1G 112M 10G 14G
Swap: 511M 200M 311M
used=total-free 即 total=used+free
实际内存占用:used-buffers-cached 即 total-free-buffers-cached
实际可用内存:buffers+cached+free
第1行Mem数据:
total 内存总数: 128
used 已经使用的内存数: 119
free 空闲的内存数: 8
shared 当前已经废弃不用,总是0
buffers Buffer Cache内存数: 1
cached Page Cache内存数: 22
第2行-/+ buffers/cache:
-buffers/cache 的内存数:95 (等于第1行的 used - buffers - cached)
+buffers/cache 的内存数: 32 (等于第1行的 free + buffers + cached)
可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
[lishan@xx-xx-xx-xx ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 3.2G 17G 16% /
devtmpfs 7.8G 0 7.8G 0% /dev
tmpfs 7.8G 0 7.8G 0% /dev/shm
tmpfs 7.8G 217M 7.6G 3% /run
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/vdb 120G 9.4G 111G 8% /data
tmpfs 1.6G 0 1.6G 0% /run/user/1002
tmpfs 1.6G 0 1.6G 0% /run/user/1000
tmpfs 1.6G 0 1.6G 0% /run/user/1001
tmpfs 1.6G 0 1.6G 0% /run/user/1004
/dev/vdb 120G 9.4G 111G 8% /data 磁盘挂载在/data下
df -h 查看系统空间占用情况
如图 一般如果是/dev/vda1 占用100%的话 可以查看下tmp和一些log目录是否是log空间占满了,删减一些没用的日志
du -sh * 看哪个目录占用空间大
du -h --max-depth=1 /路径 查询文件夹占用显示该目录占用空间的总和
find . -type f -size +800M
find . -type f -size +800M -print0 | xargs -0 ls -l 打印文件信息
find . -type f -size +800M -print0 | xargs -0 du -h 显示出大小
find . -type f -size +800M -print0 | xargs -0 du -h | sort -nr 增加排序
lishan@xx-xx-xx-xx:/data/logs/aiclass/stable1$ sudo find /data/logs/aiclass/stable1 -name info.log.20180827 当前路径查找
lishan@xx-xx-xx-xx:/data/logs/aiclass/stable1$ sudo find / -name info.log.20180827 根目录查找
全选高亮显示:按esc后,然后ggvG或者ggVG
【备忘录系列】Vim快速选中、删除、复制引号或括号中的内容
ci’、ci”、ci(、ci[、ci{、ci< - 分别更改这些配对标点符号中的文本内容
di’、di”、di(或dib、di[、di{或diB、di< - 分别删除这些配对标点符号中的文本内容
yi’、yi”、yi(、yi[、yi{、yi< - 分别复制这些配对标点符号中的文本内容
vi’、vi”、vi(、vi[、vi{、vi< - 分别选中这些配对标点符号中的文本内容
复制的命令是y,即yank(提起) ,常用的命令如下:
y 在使用v模式选定了某一块的时候,复制选定块到缓冲区用;
yy 复制整行(nyy或者yny ,复制n行,n为数字);
y^ 复制当前到行头的内容;
y$ 复制当前到行尾的内容;
yw 复制一个word (nyw或者ynw,复制n个word,n为数字);
yG 复制至档尾(nyG或者ynG,复制到第n行,例如1yG或者y1G,复制到档尾)
vim删除全部内容 :%d
dG删除当前后面的全部内容,直接在vi编辑中按下字母dG即删除当前行及后面所有内容
yyp复制当前行且在当前行下一行粘贴
[root@LinServ-1 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda2 140G 27G 106G 21% /
/dev/sda1 996M 61M 884M 7% /boot
tmpfs 1009M 0 1009M 0% /dev/shm
/dev/sdb1 2.7T 209G 2.4T 8% /data1
使用vim的比较模式打开两个文件:
vim -d file1 file2
sudo vimdiff appconf_test.toml appconf.toml
which python 安装路径
输出为/usr/bin/python
根据服务查询端口、进程。
sudo ps -ef|grep aiclass_front|grep -v grep
此次AI8088服务为
upstream frontlistener_qa {
server 127.0.0.1:8088;
}
根据pid查询port
根据进程pid查端口:
netstat -nap | grep pid
根据端口port查进程
netstat -nap | grep port
或sudo netstat -nap | grep aiclass_front 同时查看该服务的pid和port
sudo netstat -nap|grep 13009|grep -v grep
根据进程pid查端口:
lsof -i | grep pid
根据端口port查进程
lsof -i:port
pgrep -l XXX
可以迅速定位包含某个关键字的进程的pid;使用这个命令,再也不用ps aux 以后去对哪个进程的pid了
用法:
pgrep -l XXX
说明:
-l参数,可以显示出pid及进程名字;不加-l只显示pid,谁知道是什么进程的pid
举例:
# pgrep httpd
2092
2094
2096
# pgrep -l httpd
2092 httpd
2094 httpd
2096 httpd
cd ~ 个人目录
./当前目录
linux drwxr-xr-x 什么意思
第一位表示文件类型。d是目录文件,l是链接文件,-是普通文件,p是管道
第2-4位表示这个文件的属主拥有的权限,r是读,w是写,x是执行。
第5-7位表示和这个文件属主所在同一个组的用户所具有的权限。
第8-10位表示其他用户所具有的权限。
不用vim替换文件内容
sed 's/a/A/g' 1.txt > 2.txt
grep 后加单引号、双引号和不加引号的区别
单引号:
可以说是所见即所得:即将单引号内的内容原样输出,或者描述为单引号里面看到的是什么就会输出什么。单引号''是全引用,被单引号括起的内容不管是常量还是变量者不会发生替换。
双引号:
把双引号内的内容输出出来;如果内容中有命令、变量等,会先把变量、命令解析出结果,然后在输出最终内容来。双引号""是部分引用,被双引号括起的内容常量还是常量,变量则会发生替换,替换成变量内容
不加引号:
不会将含有空格的字符串视为一个整体输出, 如果内容中有命令、变量等,会先把变量、命令解析出结果,然后在输出最终内容来,如果字符串中带有空格等特殊字符,则不能完整的输出,需要改加双引号,一般连续的字符串,数字,路径等可以用。
使用规则:
一般常量用单引号''括起,如果含有变量则用双引号""括起。
最大不同:
单引号与双引号的最大不同在于双引号仍然可以保有变数的内容,但单引号内仅能是一般字
元,而不会有特殊符号
使用举例:
“”号里面遇到$,\等特殊字符会进行相应的变量替换
‘’号里面的所有字符都保持原样
对于字符串,两者相同
匹配模式也大致相同
但有一些区别非常容易混淆
grep "$a" file #引用变量a,查找变量a的值
grep '$a' file #查找“$a”字符串
grep "\\" file #grep: Trailing backslash(不知原因)
grep '\\' file #查找‘\’字符
1、$ 美元符
2、\ 反斜杠
3、` 反引号
4、" 双引号
这四个字符在双引号中是具有特殊含义的,其他都没有,而单引号使所有字符都失去特殊含义
如果用双引号,查找一个\,就应该用四个\:
grep "\\\\" file 这样就对了,这样等同于:
grep '\\' file
第一条命令shell把四个\,转义成2个\传递给grep,grep再把2个\转义成一个\查找
第二条命令shell没转义,直接把2个\传递给grep,grep再把2个\转义成一个\查找
其实grep执行的是相同的命令
1. 文件加解密
vim -x file: 开始编辑一个加密的文件。
:X -- 为当前文件设置密码。
:set key= -- 去除文件的密码。
2. vim保存文件”:wq”与“:x”的区别
vim是Unix/Linux系统最常用的编辑器之一,在保存文件时,我通常选择”:wq“,因为最开始学习vim的时候,就只记住了几个常用的命令;也没有细究命令的含义。
但是,在编译代码时发现,在没有修改源文件的情况下,仅仅使用”:wq“命令保存文件,源文件会重新编译。这是因为文件即使没有修改,”:wq”强制更新文件的修改时间,这样会让 make编译整个项目时以为文件被修改过了,然后就得重新编译链接生成可执行文件。这可能会产生让人误解的后果,当然也产生了不必要的系统资源花销。
“:x”和”:wq”的真正区别,如下:
:wq 强制性写入文件并退出。即使文件没有被修改也强制写入,并更新文件的修改时间。
:x 写入文件并退出。仅当文件被修改时才写入,并更新文件修改时间,否则不会更新文件修改时间
服务器开通权限步骤,配置免密码登录
root用户登录Linux后
自己给自己修改密码
输入passwd 可以直接修改自己的密码
sudo adduser lishan
sudo passwd lishan
sudo su build 或者 sudo -u build -H bash # 切换到build用户
sudo visudo
sudo vim /etc/sudoers --开通sudo权限,普通用户不需要
1.useradd在使用该命令创建用户是不会在/home下自动创建与用户名同名的用户目录,而且不会自动选择shell版本,也没有设置密码,那么这个用户是不能登录的,需要使用passwd命令修改密码。
2.adduser在使用该命令创建用户是会在/home下自动创建与用户名同名的用户目录,系统shell版本,会在创建时会提示输入密码,更加友好。
userdel 删除用户,
userdel只能删除用户,并不会删除相关的目录文件。userdel -r 可以删除用户及相关目录
添加用户名,赋sudo的权限
sudo adduser wengjf
sudo passwd wengjf
sudo usermod -G sudo wengjf --usermod -G是指定用户组
sudoers的深入剖析与用户权限控制 - SegmentFault 思否
sudo su username
cd ~
ls -al
想要完全删除用户账号(也就是删除所有与该用户相关的文件),以下这两种方法个人觉得是最好的:
(1)使用 userdel -r xiaoluo命令删除。
(2)先使用userdel xiaoluo 删除账户和组的信息,在使用find查找所有与该用户的相关文件,在使用rm -rf 删除
先演示第一种方法:userdel -r xiaoluo
接下来演示第二种方法: 先使用userdel xiaoluo 删除账户和组的信息,再使用【find / -name "*xiaoluo*"】查找所有于该用户的相关文件,在使用rm -rf 删除
[root@xx-xx-xx-xx home]# find / -name "*liyb*"
/var/spool/mail/liyb
/home/liyb
删除用户 user,同时删除他的工作目录
sudo userdel -r chenyn
Nginx
/usr/local/nginx/conf/vhost/ 域名
编译支持ssl的Nginx make install会覆盖所有配置 要注意
./configure --prefix=/usr/local/nginx --with-http_ssl_module
make
cp /usr/local/nginx/sbin/nginx ~/
cp objs/nginx /usr/local/nginx/sbin/ //新编译出来的时候的路径
查看golang编译二进制的版本 md5sum filename
python generate.py -include territory go erro > outer.go
sudo ln -s /usr/bin/python3.5 /usr/bin/python
sudo apt-get install ubuntu-minimal ubuntu-standard ubuntu-desktop
上传文件
target:
sudo nc -l 12345 | tar -zxvf -
source:
sudo tar -zcvf - territory | nc 10.102.xx.xx 12345
GOOS=darwin GOARCH=amd64 go build -o 别名 入口.go ---------Linux下编译Mac可执行文件
要注意接口和数据库的命名规范和一致性,这两项的修改会造成较多的问题
Ubuntu打开其他类型文件命令 xdg-open
循环中通过闭包传递给go 协程的变量,可能会导致前面的协程使用该变量时其已经变成了后面循环中的值
for _, f := range fileNames {
go func(f string){
}(f)
//这种方式可以避免问题 go func(){do(f)} 这种会产生上述问题
}
服务器免密码登录
sudo su lishan 切换到个人用户下
sudo su 切换到root用户
1>创建用户 sudo adduser zhuangyx 默认权限为700 drwx------
2>赋最高权限以便sudo权限进去创建文件 sudo chmod -R 777 zhuangyx
cd zhuangyx/
没有.ssh文件夹,创建 sudo mkdir .ssh
cd .ssh/
在.ssh文件下创建文件sudo touch authorized_keys
3>需要被开通权限的同学提供跳板机个人目录.ssh下id_rsa.pub(如果用户目录.ssh没有公私钥,需要用户自己生成或者上传。如果没有登录跳板机权限,需要找DBA开通),此文件内容后缀必为
username@10-10-123-101
31>OP开通跳板机原理跟QA开通权限原理一样,用户A给DBA公私钥id_rsa和id_rsa.pub,简称1是用于登录跳板机,OP把1放到跳板机A的个人目录.ssh下,把id_rsa.pub内容拷贝到.ssh的authorized_keys ;A在跳板机有公私钥,需要把1的id_rsa.pub提供给QA,QA到目标机器把1放到跳板机A的个人目录.ssh下,把id_rsa.pub内容拷贝到.ssh的authorized_keys --公私钥1对,用于登录跳板机和服务器
32>A在跳板机没有1(被删除了或者OP没有上传,A的.ssh只有authorized_keys),需要A在跳板机重新生成公私钥2,参考博客ssh免密码登录配置方法,(图示加命令)_universe_hao的博客-CSDN博客_ssh免密码登录配置 再把2的id_rsa.pub提供给QA --公私钥2对,1用于登录跳板机,2用于登录服务器
33>A在跳板机只有1的私钥id_rsa,没有公钥,需要A上传当时提供给OP的id_rsa.pub到跳板机个人目录.ssh。或者重新生成2
sudo vim authorized_keys 将公钥id_rsa.pub的内容粘贴到authorized_keys 保存退出
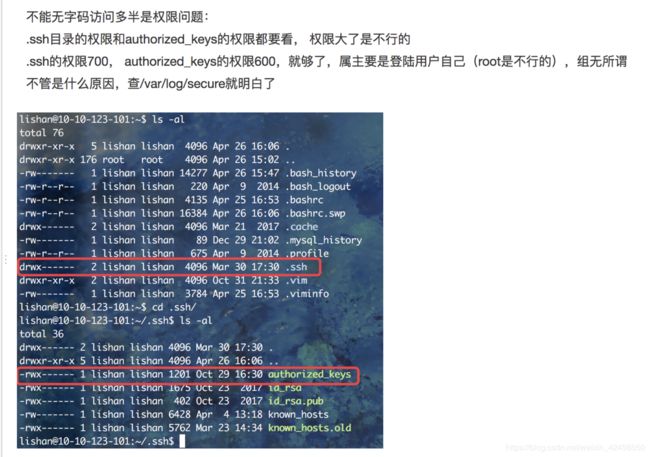
4>此外 .ssh 和 .ssh 下所有文件属主都是当前用户
cd /home/
sudo chown -R zhuangyx:zhuangyx zhuangyx (或者zhuangyx.zhuangyx)赋用户组权限给用户账号,当前.ssh目录以及子目录(-R或-recursive:递归处理,将指定目录下的所有文件及子目录一并处理)s
sudo chmod -R 700 zhuangyx/ 权限都为700,否则无法登录服务器

个人目录cd ~
Linux根目录cd /
新创建的文件夹权限默认为drwxr-xr-x 755
新创建的文件权限默认为-rw-r--r-- 644
umask 022
umask是指定 当前用户在建立文件或目录时候的属性默认值
lishan@10-10-123-101:~$ umask -S
u=rwx,g=rwx,o=rx
lishan@10-10-123-101:~$ umask 022
lishan@10-10-123-101:~$ umask -S
u=rwx,g=rx,o=rx
umask指定的是“该默认值需要减掉的权限” 默认权限777,减去022为755,所以为rwxr-xr-x user group other
查看方式有两种,一种是直接输入umask,可以看到数字类型的权限设置分数,一种是加入 -S(Symbolic)参数,就会以符号类型的方式显示权限
chmod命令是linux上用于改变权限的命令,-R 是递归遍历子目录,因为你要操作的文件使用的*通配符。777,全部权限的模式,即7 7 7 (所有用户都具有读、写和执行权限)。第一个7代表文件所属者的权限,第二个7代表文件所属者所在组的权限,第三个7代表其它用户的权限,7=4+2+1,在linux中权限是可以通过数字来描述的。具体表示如下:
4,执行时设置用户ID,用于授权给基于文件属主的进程,而不是给创建此进程的用户。
2,执行时设置用户组ID,用于授权给基于文件所在组的进程,而不是基于创建此进程的用户。
1,设置粘着位。
authorized_keys 需要 700 还是 600 我觉得是 root 用户可以自定义的,我都开了好多 VPS 了,通常默认 600 是没问题的
参考博客 ssh免密码登录配置方法,(图示加命令)_universe_hao的博客-CSDN博客_ssh免密码登录配置
Mac配置免密码ssh
生成密钥。在终端下执行命令:
ssh-keygen -t rsa
一路回车,各种提示按默认不要改,等待执行完毕。然后执行:
ls ~/.ssh
#
可以看到两个密钥文件:id_rsa(私钥) id_rsa.pub(公钥)
localhost:.ssh qa$ sudo cp id_rsa ~/Desktop/
localhost:.ssh qa$ sudo cp id_rsa.pub ~/Desktop/
106.xx.xx.xx (外) 10.xx.xx.xx(内)
外网访问http://106.xx.xx.xx:8888/login
一键查看系统名称,hostnamectl 比 uname -a 好用

服务器别名配置
编辑本地配置文件
sudo vim ~/.ssh/config
Host jump
HostName 106.xx.xx.xx 跳板机外网IP
User lishan
#IdentityFile /Users/qa/.ssh/id_rsa 私钥路径
lishan@10-10-123-101:~$ cd ~
vim .bashrc
内容如下
alias aiqa='ssh 10.10.xx.xx'
alias aipre='ssh 10.9.xx.xx'
alias aipro1='ssh 10.9.xx.xx
alias aipro2='ssh 10.9.xx.xx'
alias aicmspro='ssh 10.9.xx.xx'
source .bashrc
百度搜索10.12 任何来源,sudo spctl --master-disable 这样Charles等就不会被移至废弃篓
Linux下用户组、文件权限详解 - RoyFans - 博客园
显示filename最后100行, -f 该参数用于监视File文件增长,-n Number 从 Number 行位置读取指定文件
tail -n 20 filename 说明:显示filename最后20行。
tail -n 100 info.log.20180524
tail -100f info.log.20180524 查看文件最后100行,持续监控
查看文件前10行
head -n 10 info.log.20180925(filename)
1. tail Console.log
输出文件最后10行的内容
2. tail -nf Console.log --n为最后n行
输出文件最后n行的内容,同时监视文件的改变,只要文件有一变化就同步刷新并显示出来
3. tail -n 5 filename
输出文件最后5行的内容
3. tail -f filename
输出最后10行内容,同时监视文件的改变,只要文件有一变化就显示出来。
nginx之总结
坑1:nginx reload不起作用。杀了进程再启动nginx 可能就生效了。因为 nginx-test-all.conf 里包含8003端口,先把nginx-test8003.conf起来,再启nginx-test-all.conf就会报nginx: [emerg] bind() to 0.0.0.0:XXXX failed (98: Address already in use)这样的错,因为之前测试环境ng配置本来就有问题
坑2:杀了nginx主进程,如果有子进程的话一并杀掉。(杀了父进程,子进程还存在原因:强行杀父亲(不知道进程间的关系),儿子就成为孤儿了(僵尸进程了),有些子进程比较巩固。用pkill或者killall命令)但再启动nginx的时候报nginx: [emerg] bind() to 0.0.0.0:XXXX failed (98: Address already in use)错,原因:kill再启动表面看没问题,但有时候端口由于某种原因没有释放,但看nginx进程看不出来。杀掉重启,端口没释放,报错是正常的。所有以后 -s reload 不管用,用 -s stop 再启动,不要用kill再启动了
reload后ng进程号不变,如果杀掉ng进程,再启动,进程号就变了
最正确的方式
ps -ef|grep nginx
sudo /opt/openresty/nginx-prew/sbin/nginx -c /opt/openresty/nginx-prew/conf/nginx-prew-all.conf -t
sudo /opt/openresty/nginx-prew/sbin/nginx -c /opt/openresty/nginx-prew/conf/nginx-prew-all.conf -s stop
ps -ef|grep nginx
sudo /opt/openresty/nginx-prew/sbin/nginx -c /opt/openresty/nginx-prew/conf/nginx-prew-all.conf
ps -ef|grep n
nginx -s reload 主进程master不变,子进程号会变
systemctl restart nginx 主进程、子进程号都会变。这两种都是平滑重启,优先考虑这两种
-s reload 没有生效,原因:句柄问题
参考博客nginx 启动,停止和重新加载配置_GE12的博客-CSDN博客
nginx详解nginx.conf文件详解及调优 - 范圣帅 - 博客园
要启动nginx的,运行可执行文件。一旦nginx的启动时,它可以通过与-s参数调用可执行来控制。使用以下语法
nginx -s signal
其中,信号可以是下列之一:
- stop — fast shutdown
- quit — graceful shutdown
- reload — reloading the configuration file
- reopen — reopening the log files
例如,要停止nginx的过程与等待工作进程完成服务的当前请求,下面的命令可以执行:
nginx -s quit
This command should be executed under the same user that started nginx.
在配置文件中所作的更改不会被应用,直到命令重新配置被发送到nginx的或重新启动。要重新加载配置,执行:
nginx -s reload
一旦主处理接收到的信号重新加载配置,它检查新的配置文件的语法正确性并尝试应用在其提供的配置。如果这是一次成功,主进程开始新的工作流程,将消息发送到老的工作进程,要求它们关闭。否则,主进程回滚的变化,继续与旧的配置工作。旧的工作进程,在接收到命令关闭,停止接受新的连接,并继续服务于当前请求,直到所有的要求提供服务。在这之后,老工人处理退出。信号也可发送到nginx的与Unix工具的帮助下过程,如杀工具。在这种情况下,一个信号被直接发送到一个进程与给定的进程ID。nginx的主进程的进程ID写入,默认情况下,该nginx.pid在目录/ usr /本地/ nginx的/日志或/ var /运行。例如,如果主进程ID是1628,送造成的nginx的正常关机的信号QUIT,执行
kill -s QUIT 1628
启动nginx:
nginx -c nginx.conf
用于获取所有正在运行的nginx的进程列表,ps工具可以使用,例如,以下面的方式:
ps -ax | grep nginx
sudo /opt/openresty/nginx-booker_beta/sbin/nginx -c /opt/openresty/nginx-booker_beta/conf/nginx-test-all.conf
ps -ef|grep nginx
grep -nr 'centTestServer' ./ 递归查找
vim ./shark_centTest_upstreams.conf
ps -aux|grep nginx
sudo kill 1034 #杀nginx进程,只需要杀掉主进程,nginx: worker process 是子进程,杀掉主进程 子进程也会被杀掉
ps -aux|grep nginx
sudo /opt/openresty/nginx/sbin/nginx -c /opt/openresty/nginx/conf/nginx-test-all.conf
ps -aux|grep nginx
location ~ "^/parent/learning-center/(get-products|index|my-course-list|get-grade-course)" {
多加了一个/如下,因为
location ~ "^/parent/learning-center/(get-products|index|my-course-list|get-grade-course)/" {
因为三级域名后面是?没有下级域名了,所以不能用/,排查了很久
https://xx.cn:9016/parent/learning-center/index?source=androidRCParent&version=197&token=QSzGi9pibRU2JivSekt9XwUQwERQEF5en3U0IQo0n7iHuUKNEhaSBNaUYkmkoLhxu1DwLjVUFb_E6JyyO6loQUxWA6le_uoaMOGCzWbEoU8%2F&appVersion=1.9.7&platform=Android&appName=RCParent&channel=wandoujia&deviceId=863254036764727&deviceVersion=8.0.0&deviceType=MI%206
https:/xx.cn:9016/parent/learning-center/my-course-list?source=androidRCParent&version=197&token=QSzGi9pibRU2JivSekt9XwUQwERQEF5en3U0IQo0n7iHuUKNEhaSBNaUYkmkoLhxu1DwLjVUFb_E6JyyO6loQUxWA6le_uoaMOGCzWbEoU8%2F&appVersion=1.9.7&platform=Android&appName=RCParent&channel=wandoujia&deviceId=863254036764727&deviceVersion=8.0.0&deviceType=MI%206
https://xx.cn:9016/parent/learning-center/get-grade-course?source=androidRCParent&version=197&token=QSzGi9pibRU2JivSekt9XwUQwERQEF5en3U0IQo0n7iHuUKNEhaSBNaUYkmkoLhxu1DwLjVUFb_E6JyyO6loQUxWA6le_uoaMOGCzWbEoU8%2F&appVersion=1.9.7&platform=Android&appName=RCParent&channel=wandoujia&deviceId=863254036764727&deviceVersion=8.0.0&deviceType=MI%206&grade=1
二级域名,后面还有其他路径可以加/
location ~ "^/dotread/(shelf|book)/" {
shelf|book后面还有其他域名,/是二级域名下所有的
https://xx.cn:9016/dotread/shelf/get-books?source=androidRCStudent&version=197&token=f%2FZZHnLMOIYDeguRJFgef5KhdT%2BpjwUkGg0lqETNH9kMdXZKLLtjoy%2FaFEYjFawC&appVersion=1.9.7&platform=Android&appName=RCStudent&channel=wandoujia&deviceId=863254036764727&umid=&deviceVersion=8.0.0&deviceType=MI6
https://xx.cn:9016/dotread/book/get-book-items?source=androidRCStudent&version=197&token=QSzGi9pibRU2JivSekt9XwUQwERQEF5en3U0IQo0n7iHuUKNEhaSBNaUYkmkoLhxu1DwLjVUFb_E6JyyO6loQUxWA6le_uoaMOGCzWbEoU8%2F&appVersion=1.9.7&platform=Android&appName=RCStudent&channel=wandoujia&deviceId=863254036764727&umid=&deviceVersion=8.0.0&deviceType=MI6&bookid=tape6b_022001
nginx机器:10.xx.xx.xx(测试和预览的nginx配置都在这里)
现有所有启动中的nginx服务有:
sudo /opt/openresty/nginx/sbin/nginx -c /opt/openresty/nginx/conf/nginx-test-all.conf
sudo /opt/openresty/nginx8002/sbin/nginx -c /opt/openresty/nginx8002/conf/nginx-test8002.conf
sudo /opt/openresty/nginx8003/sbin/nginx -c /opt/openresty/nginx8003/conf/nginx-test8003.conf
sudo /opt/openresty/nginx1/sbin/nginx -c /opt/openresty/nginx1/conf/nginx-test8009.conf
sudo /opt/openresty/nginx-prew/sbin/nginx -c /opt/openresty/nginx-prew/conf/nginx-prew-all.conf
sudo /opt/openresty/nginx-websocket_beta/sbin/nginx -c /opt/openresty/nginx-websocket_beta/conf/nginx-test-all.conf
sudo /opt/openresty/nginx-booker_beta/sbin/nginx -c /opt/openresty/nginx-booker_beta/conf/nginx-test-all.conf
sudo /opt/openresty/nginx-websocket_prew/sbin/nginx -c /opt/openresty/nginx-websocket_prew/conf/nginx-preview.conf
有些项目nginx启动为/usr/local/nginx/sbin/nginx 没有指定新的配置文件
sudo find / -name nginx
sudo find / -name nginx.conf
查找nginx默认配置文件 vim /usr/local/nginx/conf/nginx.conf 查看conf文件位置
nginx安装目录地址 -c nginx配置文件地址 以下为默认路径
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
sudo find / -name vhosts
位置/usr/local/nginx/conf/vhosts
Linux命令学习 man ls
线上日志文件要赋成 root 666或者build 664 (因为线上supervisor配置文件启动用户为build)
[[email protected] backcms]$ ps -ef|grep backcms
lishan 15338 13473 0 21:00 pts/1 00:00:00 grep --color=auto backcms
build 22935 17811 0 May25 ? 00:00:07 /data/www/aiclass/backcms/aiclass_backcms
shell积累
1.
#!/bin/sh
ADDRESS=‘email地址'
APACHE_ERROR_LOG='/usr/local/apache/logs/error_log'
if [ `/usr/bin/wc -c < ${APACHE_ERROR_LOG}` -ne `/usr/bin/wc -c < ${APACHE_ERROR_LOG}.old` ];
then
diff ${APACHE_ERROR_LOG}.old ${APACHE_ERROR_LOG} | mail -s '194 apache error log' ${ADDRESS}
fi
rm -f ${APACHE_ERROR_LOG}.old
cp ${APACHE_ERROR_LOG} ${APACHE_ERROR_LOG}.old
chmod 666 ${APACHE_ERROR_LOG}.old
MYSQL_SLOW_LOG='/log/mysql-slow-query'
if [ `/usr/bin/wc -c < ${MYSQL_SLOW_LOG}` -ne `/usr/bin/wc -c < ${MYSQL_SLOW_LOG}.old` ];
then
diff ${MYSQL_SLOW_LOG}.old ${MYSQL_SLOW_LOG} | mail -s '194 mysql slow log' ${ADDRESS}
fi
rm -f ${MYSQL_SLOW_LOG}.old
cp ${MYSQL_SLOW_LOG} ${MYSQL_SLOW_LOG}.old
chmod 666 ${MYSQL_SLOW_LOG}.old
将以上代码保存为:notify_error.sh,在apache和myvim sql的log目录下分别建立原文件的备份error_log.old和mysql-slow-query.old文件(用于文件比对)
设定监控程序为守护进行,比如上班时间每小时执行一次:
cd /var/spool/cron/
之后运行crontab -e
键入如下内容,保存
30 8-18 * * * /home/sh/notify_error.sh
以后每当apache 有error 发生,或者mysql有slow query发生,就可以及时收到邮件提醒了
2. 清理前一天log日志
删除logs下非当前日期的日志
tail -n 100 info.log.20180531 |grep -E 'userId:434|userId:417|userId:418|userId:433|userId:434'
ls | grep -v -E "0531|sys.log" | xargs sudo rm -f
ls |grep -E -v '0612|sys.log' |xargs sudo rm -rf
如遇误删今天的日志文件,重启对应项目/服务的supervisor
清理前一天log日志shell
#!/bin/bash
logPathList=`cat <
/data/logs/aiclass/backcms1
/data/logs/aiclass/backop
/data/logs/aiclass/frontlistener
/data/logs/aiclass/frontlistener1
/data/logs/aiclass/gray
/data/logs/aiclass/stable1
/data/logs/aiclass/stable2
/data/logs/aiclass/webfe
STD
`
for logPath in $logPathList;do
if [ -d $logPath ];then
#-----清除目录下1天前的文件
cd $logPath && find . -type f -name '*.log.*' -mtime +0 2>/dev/null -exec rm -f {} \;
echo "cd $logPath && find . -type f -name '*.log.*' -mtime +0 2>/dev/null -exec rm -f {} \;"
fi
done
Linux 有三个特别文件,分别
1)标准输入 即 STDIN , 在 /dev/stdin
一般指键盘输入, shell里代号是 0
2) 标准输出 STDOUT, 在 /dev/stdout
一般指终端(terminal), 就是显示器, shell里代号是 1
3) 标准错误 STDERR, 在 /dev/stderr
也是指终端(terminal), 不同的是, 错误信息送到这里
shell里代号是 2
测试环境aiqa已用此脚本进行删除日志
lishan@xx-xx-xx-xx:/data/logs/shell$ sudo sh /data/logs/shell/log.sh
3. 停止supervisor 启动supervisor清理缓存的命令
awk '{row[NR]=$0;}match($0,"stopped|started|OK"){affect[$0]++;print row[NR-1];print $0;};END{{print "*******statistic*************";}for(i in affect){print i;print affect[i];}}' aiclass.server.`date +'%y%m%d'`.run.log
查找日志中含有www.XXX.com www.XXX.cn的日志
4. 接口耗时一般<=100ms 如果读取redis等缓存 可能1-10ms
awk 统计访问时间超过1000毫秒的接口
awk 统计访问时间超过1000毫秒的接口_andyguo的博客-CSDN博客
日志格式如下:
2013-01-10 15:21:44:868 INFO [catalina-exec-59] com.lietou.common.filter.AbstractIOLogger | status=0, eclipse=17ms, servletPath=/requestResumeInfo/findResume.json, clientIP=10.10.10.22, input={"data":"4874","client_id":"20007","view_id":"32150"}, output={"status":0,"message":"OK","data":{"res_id":4874,"sysResumeDto":{"res_id":4874,"user_id":6112,"delflag":"0","res_caption":"中文简历_20130110","res_tel":"13808080808","res_email":"[email protected]","res_langkind":"0","res_edulevel":"040","res_wo
shell脚本命令如下:
cat eventInfo.log |sed 's/ms,//g' |awk '{ if (substr($8,9) -1000 >0 ) print}'|awk '{print $9}'|sort|uniq -c|sort -nr|head
测试结果如下:
2712 servletPath=/requestResumeInfo/findResumesByUserCId.json,
2626 servletPath=/requestResumeInfo/findResume.json,
2457 servletPath=/requestResumeInfo/findResumes.json,
1084 servletPath=/requestResumeInfo/findSysResume.json,
577 servletPath=/requestResumeInfo/findResumeRefreshTime.json,
340 servletPath=/requestResumeInfo/findResumeIdsByUserCId.json,
131 servletPath=/requestResumeInfo/findResumeContact.json,
5. AI直播课线上问题排查,某个学生一直ws连接断开
[[email protected] stable]$ pwd
/data/logs/aiclass/stable
info.log.20180829:2018-08-29 15:47:52.837 [info][4f4b5fca24671e54][http_access] 10.10.xx.xx GET 200 0 95.418741ms/ws/student?token=gkuDj3RNdwWN9JhPXa7ESx7jZjjLX%2FtOikNI4GRxvY4%3D&sid=64&version=1.5.2-alpha.1
info.log.20180829:2018-08-29 15:48:50.761 [info][4f4b6d462d46285c][http_access] 10.10.xx.xx GET 200 0 104.120105ms /ws/student?token=z6jodlDZFFYe%2FdY8wor%2B0KnRCvSuHsYRDjKUUGce8xk%3D&sid=64&version=1.5.2-alpha.1
接口名在第9个$9
[[email protected] stable]$ grep 'ws/student' *0801 | grep sid=153 | awk '{print $9}' | sort | uniq -c | awk '{if($1>1){print $0}}'|sort -nr|head
打印前2个数据
grep 'ws/student' *0829 | grep sid=64 | awk '{print $9}' | sort | uniq -c | awk '{if($1>1){print $0}}'|sort -nr|head -n 2
$0就表示一个记录,$1表示记录中的第一个字段。
一般 print $0 就是打印整行内容($0前面不需要反斜杠),print $1表示只打印每行第一个字段
121 /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
108 /ws/student?token=SPWoHsDdvxhla8%2F6%2BYqbAcpkuJmQs3doulcSIsp6gTY%3D&sid=153&version=1.4.2
6 /ws/student?token=pFsVjdZ672PXShTgRCLp%2FoflSGVMmNF7P%2Bk8sDv0CGc%3D&sid=153&version=1.4.2
5 /ws/student?token=aJQvhdkoOM4AZxQJH2G9mQ2gUD7oKh7KpyZt3b951Wc%3D&sid=153&version=1.4.2
4 /ws/student?token=eyAZEeC85eVGels%2BgVqJMoM3XffLL8P%2FTY8pkCDONVo%3D&sid=153&version=1.4.2
3 /ws/student?token=SPWoHsDdvxhla8%2F6%2BYqbAT%2F2RzEoR5q1yCE1bSU7z%2Bw%3D&sid=153&version=1.4.2
3 /ws/student?token=GYhFYScEJLfW1SS2ay8KNRyQOgj5BUknkULK7fJYO%2BY%3D&sid=153&version=1.4.2
2 /ws/student?token=SPWoHsDdvxhla8%2F6%2BYqbAak5FjX2pEFMz9jwyXpswcc%3D&sid=153&version=1.4.2
2 /ws/student?token=omGqDPHUoZmqugc1jTOHak0o0IcTJDoDMgpGikASyeY%3D&sid=153&version=1.4.2
2 /ws/student?token=nLEKsZNam8hy9UIbwy8dd3KM5xD49rZqBSpO384JupI%3D&sid=153&version=1.4.2
根据登录次数最多的token,查到requestID(UUID)
[[email protected] stable]$ grep eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D *0801
info.log.20180801:2018-08-01 19:15:13.518 [info][46be707d86c5833c][http_access] 223.104.95.77 GET 200 0 442.672µs /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
info.log.20180801:2018-08-01 19:15:23.937 [info][46be72ea92be1032][http_access] 223.104.95.77 GET 200 0 400.458µs /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
info.log.20180801:2018-08-01 19:15:34.544 [info][46be7562cbe3713a][http_access] 223.104.95.77 GET 200 0 361.949µs /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
info.log.20180801:2018-08-01 19:15:45.448 [info][46be77ecb483f033][http_access] 223.104.95.77 GET 200 0 542.688µs /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
info.log.20180801:2018-08-01 19:15:56.161 [info][46be7a6b46b69a32][http_access] 223.104.95.77 GET 200 0 408.826µs /ws/student?token=eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D&sid=153&version=1.4.2
根据最新的requestID查,查找mobile 如果最新的查不到,拿其他的requestID查询
[[email protected] stable]$ grep 46be7a6b46b69a32 *0801
或者
[[email protected] stable]$ grep eyAZEeC85eVGels%2BgVqJMgWclsDT7Mj11L64SURgzwg%3D *0801 | cut -d" " -f3 | grep -oE '\[[0-9a-z]*\]\[http_access' | xargs -l grep {} *0801 | grep mobile | less
cut -d" " -f3 第三列,第一列为1
6. 统计某个文件某个字符出现的概率
grep -o a 1.txt|wc -l
git tag |wc -l 或者 git tag >1.txt 然后vim统计
7. 统计接口top20访问量
awk '/INNERACCESS/{interface=substr($10,1,index($10,"?")); S[interface]++} END{for(i in S){print i,S[i]}}' info.log.2016-02-22 | sort -nrk2|head -n20
/v1_common/global-info/get-student-global-info? 46488
/v1_answer/student/wrong-topic-catalog? 42930
/v1_class/student/get-chat-list? 41057
/v1_homework/student/get-feed-homework-list? 38125
/v1_common/global-info/get-student-ext? 29752
/v1_common/global-info/get-student-web? 22805
/v1_homework/student/get-homework-list? 20595
/v1_class/student/get-class-list? 20364
/v1_homework/student/get-answer-result? 16737
/v1_homework/student/pre-submit-rank? 14753
8. log监控相关shell
#!/bin/bash
#如果3个小时没有该关键字出现,即刻报警
cat /var/log/messages |grep "key word" > /dev/null
if [ $? -eq 1 ]
then
echo Alert!!!
fi
0 */3 * * * /root/test.sh
redis积累
批量删除多条手机号记录
选择数据结库
redis-cli -h xx.xx.xx.44 -p 6379 -n 2
redis-cli -h xx.xx.xx.44 -p 6379 keys SSParent:ParentInfoByMobile:* | xargs -i redis-cli -h xx.xx.xx.44 del {}
redis-cli -h xx.xx.xx.44 -p 6379 -n 5 keys patriarch:articleInfo:* | xargs -i redis-cli -h xx.xx.xx.44 -p 6379 -n 5 del {}选择数据库
如果不清楚,redis-cli —help
加密码需要在-n之前加 -a
测试环境
redis-cli -h xx.xx.xx.44 -a RedisUINr -p 6379 -n 0 keys aiclass:websocket:* | xargs -i redis-cli -h xx.xx.xx.44 -a RedisUINr -p 6379 -n 0 del {}
redis-cli -h xx.xx.xx.104 -p 6379 -a RedisUINr 携密码登录redis
或者
redis-cli -h xx.xx.xx.104 -p 6379
auth RedisUINr 密码认证
auth RedisUINr
hgetall "aiclass:websocket:store:hash:context:student:3240"
线上环境
redis-cli -h xx.xx.xx.104 -a RedisUINr -p 6379 -n 0 keys aiclass:* | xargs -i redis-cli -h xx.xx.xx.104 -a RedisUINr -p 6379 -n 0 del {}
redis的五种类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB
awk积累
grep userId:17402 *0908 | grep -E '19:0|19:1' | grep -vE 'ping|pong' | awk '{print $2,$7}'| grep -o '"action":[0-9]*' | uniq -c | vim -
批量杀supervisor进程
ps -ef|grep aiclass -i|grep -v grep|awk '{print $2}'|xargs sudo kill -9
ps -ef|grep -i -E 'node|comic_book_answer|quick_cal|aiclass' |grep -v grep|awk '{print $2}'|xargs sudo kill -9
批量杀进程命令
搜索WorkerMan,忽略大小写,把第二列进程号打印出来,全部杀掉
ps -ef | grep WorkerMan -i|grep -v grep|awk '{print $2}'|xargs sudo kill -9
grep -v 是反向查找的意思,比如 grep -v grep 就是查找不含有 grep 字段的行
xargs之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了xargs命令,例如:
find /sbin -perm +700 |ls -l 这个命令是错误的
find /sbin -perm +700 |xargs ls -l 这样才是正确的
查询日志中userId:472
grep userId:472 tail -n 50 info.log.20180606 |grep action |awk '{print $5}'
grep -C 前后n行 -A 前n行 -B 后n行
查询日志中在{}里的action ,以,分割
awk -F '","' '{if ($2 !="") print $2;}' info.log.20180606
查询日志中既含有userId有含有action,正则表达式以[, \t]逗号,空格,制表符分割
cat info.log.20180606 | grep userId | awk -F '[, \t]+' '{print $5,$8}'|tail -n 5
打印某个字符后面的所有内容
cat filename | awk '{for (i=3;i awk '{$1="";print $0}' 1.txt awk默认是以行为单位处理文本的,对1.txt中的每一行都执行后面 "{ }" 中的语句。 grep '\"code\":905' *0612 | cut -d" " -f3 | grep -oE '\[3.*\]\[' | grep -o '[A-Za-z0-9]*' | xargs -i grep {} *0612 grep http_token *0612 | grep '2018-06-12 11'| grep krrQjM0tFI6HlSujBGWLY3EQIeKxRP3mKsJNEa6hwqQ= | grep -oE 'debug\]\[.*]\[http_token' | grep -o 3[a-z0-9]* | xargs -i grep {} *0612 sed命令积累 sudo sed -i 's/stable8001/stable8010/g' ./appconf.toml sudo sed -i 's/8011/8031/g' ./appconf.toml 若对某日志路径替换,/前面加\转义 sed -i 's/\/aiclass\/backcms/\/aiclass\/backcms8001/g' appconf.toml sed -i 直接修改读取的文件内容,而不是输出到终端 -n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来 格式: sed -i "s/查找字段/替换字段/g" `grep 查找字段 -rl 路径` 文件名 -i 表示inplace edit,就地修改文件 -r 表示搜索子目录 -l 表示输出匹配的文件名 示例:sed -i "s/shan/hua/g" lishan.txt 把当前目录下lishan.txt里的shan都替换为hua 为方便QA环境搭建多套灰度测试环境,RD调整QA代码, vim /data/www/ailua/loadbalance/proxy_ups.lua 增加如下内容 if port ~= 80 and port ~= 443 then ngx.log(ngx.INFO, "default sid proxy" .. ups_choose) sed -n /2018-06-12\ 11:4[678]/p *0612 | grep login sed -n '/^2018-08-16 15:38/,/^2018-08-16 15:39/p' info.log.20180816 |grep -E '\/teacher\/course\/start|\/ws\/teacher' 查询老师开课http接口到建立websocket长连接的时间 sed -n '/^2018-08-17 14:29/,/^2018-08-17 14:30/p' info.log.20180817|grep 5000 查询老师端下发消息的action sed -n '/^2018-08-20 16:51/,/^2018-08-20 16:52/p' info.log.20180820|grep 5000 同一毫秒,老师端下发多次5000的action收取聊天信息 sed -n '/^2018-08-27 15:17/,/^2018-08-27 15:19/p' info.log.20180827 |grep -i -E 'ping|pong' --line-buffered|grep '422' 查询日志业务积累 查看端口开放情况 yum install telnet telnet IP port telnet xx.xx.xx.234 3306 查看端口号占用情况 sudo netstat -tunlp |grep 8088 frontlistener日志 grep userId:473 info.log.20180605| grep 'action":5011' grep userId:474 tail -n 5 info.log.20180606 |grep 'action":5051' cat info.log.20180606 |grep userId:472 |grep action > 1.log tail -n 5 1.log 查询满足A且满足B的最新20条日志 grep A tail -n 20 filename |grep B grep userId:472 tail -n 20 info.log.20180606 |grep 'action' cat info.log.20180607 |grep userId:433 |grep 'action":5010' |tail -n 50 查询已有日志里A且B的日志 grep 'userId:813' *29|grep 1025 查询实时日志A且B的日志 tail -f *30 |grep --line-buffered 'userId:812'|grep action tail -f *30 |grep --line-buffered 'userId:812'|grep --line-buffered action 以上两个命令的作用一致,第一个grep的时候输出流缓冲,在前面加grep时后面相当于展示第一个grep输出流的结 解决查询满足A且满足B的最新20条日志时有延迟的问题 linux下文件缓冲详解 - Linux操作系统:Ubuntu_Centos_Debian - 红黑联盟 问题请教:使用tail -f|grep 筛选日志带来的显示延迟问题 - Linux系统管理-Chinaunix tail -f *0816|grep --line-buffered '"action":6030'|grep --line-buffered 'cellId' line buffered:遇到换行或者缓冲区满再做flush fully buffered:缓冲区满做flush 学生端调用https登录接口后,建立wss长链接。升级成功后,服务端自己打的日志 http升级为websocket长链接 info.log.20180822:2018-08-22 15:41:12.563 [info][4d24f2a45e68217e][ws_student] connId:4d24f2a45e68217e userId:3226 1 websocket upgrade success 排查问题定位服务端下发的消息:通过 2018-06-06 12:08:06.418 [info][3576a1ea24772921][ws_response] connId:357562b3f96f0b2f userId:476 [3576a1ea24772921]为RequestID(每个ws_request和ws_response用一个),[ws_request]为客户端请求,[ws_response]为服务端下发 根据RequestID找到connId,根据connId找到此用户服务端下发的所有请求,connId为客户端与服务端建立的长链接,在用户退出、重新登录或者supervisor挂掉时,connId重新生成一个新的 grep "357608c01594ea24" info.log.20180606 根据服务端下发的[info][4b99753615a6cb06][ws_response] 找到connId:4b98e5048045d209 lishan@xx-xx-xx-xx:/data/logs/aiclass/stable1$ tail -f *17|grep --line-buffered answer|grep '"action":5031' 根据connId找到客户端所有[ws_request] lishan@xx-xx-xx-xx:/data/logs/aiclass/stable1$ grep 4b98e5048045d209 |grep ws_request info.log.20180817 php不需要编译,没有部署日志。Java需要编译,所以部署的时候需要看Tomcat(必须重启) 2017-03-22 20:42:53 [111.200.192.10][58d2714d2aa0d797][info][cow_access] INNERACCESS 58 androidStudent 1329461 0 1.1.0 Appstore http://beta.cow.api.xx.cn:8002 /ugc/word/get-detail?kbparam=11D46C3866DA3FE249DA3EDEDA7B837B&channel=Appstore&source=androidStudent&version=1.1.0&token=zkKZSwz+3sMJfkimx3t/rWTswfZTkGZ8fJsYxcRAyY8jxC+0OSxydY7mTb3fZUL3&word_id=267 {"requestId":"58d2714d2aa0d797","get":{"kbparam":"11D46C3866DA3FE249DA3EDEDA7B837B","channel":"Appstore","source":"androidStudent","version":"1.1.0","token":"zkKZSwz 3sMJfkimx3t\/rWTswfZTkGZ8fJsYxcRAyY8jxC 0OSxydY7mTb3fZUL3","word_id":"267"},"post":[],"userId":1329461,"mobile":"15004780775","userType":0,"timeUsed":0.058,"success":"true"} in /data/www/cowbeta2/cow/cow/components/Log.php:17 in /data/www/cowbeta2/cow/cow/components/EventHandler.php:32 IP(用户生成的IP)、标识(每次的请求都会生成一个,唯一标识,便于RD排查问题。也就是postman里的"requestId")、访问的类、标识(统计)、35是耗时--毫秒(服务端执行开始-执行结束)、0可能是学生端发出来的、请求参数、URL、请求类型、最后两行是执行的日志(倒着看) 速算.env发布流程以及查找redis具体常量 【env_config】env_config项目已迁移到企业QA组下面,git地址变更为:https://gitee.com/xx.git 项目结构和权限保持不变。代码已拉去到本地的小伙伴们,请通过 git remote set-url origin https://gitee.com/xx.git 命令修改自己本地库的git源地址 vim /data/www/patriarch/patriarch4/psservice/config/paramsConfig.php --此文件是redis的节点以及常量配置,根据报错'class:student'(节点:常量)找到此常量全程,在当前目录下.env文件搜索常量,没有的话,从线上同步 1>先去cow下查询结算异常的日志 cat /data/www/cowbeta0/gym/Applications/Log/cow.log|grep "immediate-end-pk"|grep 1330778 cat cow.log|grep "immediate-end-pk"|grep 1330778|grep questionSetID --color questionSetID=2699867 //两个学生对战过程产生的唯一ID 2>根据questionSetID去API服务查找日志,查看耗时, grep 2699867 info.log.20170516|grep timeUsed --color "timeUsed”:33.184 //API接口耗时,是指的提交结算数据的耗时 timeUsed正常情况肯定是1s以内,单位秒 当时在执行sql,变更表结构,锁表了,数据写入延迟 后端接口的幂等性_jks456的博客-CSDN博客_后端接口幂等 1.全局唯一ID如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、redis等。如果存在则表示该方法已经执行。2.去重表这种方法适用于在业务中有唯一标的插入场景中,比如在以上的支付场景中,如果一个订单只会支付一次,所以订单ID可以作为唯一标识。这时,我们就可以建一张去重表,并且把唯一标识作为唯一索引,在我们实现时,把创建支付单据和写入去去重表,放在一个事务中,如果重复创建,数据库会抛出唯一约束异常,操作就会回滚。3.多版本控制这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号,来做幂等 boolean updateGoodsName(int id,String newName,int version); 软件快捷键 iterm2分屏快捷键 command+D 左右窗口 command+shift+D 上下窗口 command+W 关闭窗口 command+T 当前窗口新开窗口 command+N 新开窗口 mac 下command+F失效解决办法,快捷键冲突,钉钉登录后默认的查找快捷键为command+F,删除 设置完要关闭系统偏好设置 ip,mac,路由表:网络传输中MAC地址表、ARP表和路由表详解_dbdoing的博客-CSDN博客_路由表和arp表的区别 http中keep-alive是什么含义:HTTP keep-alive详解_尐葮阿譽的博客-CSDN博客_keep-alive websocket相对于http有什么优点:WebSocket的原理与优缺点_json-zhou的博客-CSDN博客_websocket优缺点 什么是websocket协议?请进行说明。看完让你彻底搞懂Websocket原理 - 扶强 - 博客园 nginx进程模型:master和work进程:Nginx深入详解之多进程网络模型 - whitesky-root - 博客园 curl命令 post请求 curl -i -X POST -H "'Content-type':'application/x-www-form-urlencoded', 'charset':'utf-8', 'Accept': 'text/plain'" -d '{"appName":"aiclass","action":102,"callType":0,"data":{"classId":248,"courseId":"36"}}' http://127.0.0.1:8013/census/task/add get请求 遇到中文加反斜杠 \ lishan@xx-xx-xx-xx:~$ curl https://qaaiclass.xx.cn/grayscale/upstream/update?ups=10.10.xx.xx:8500\&desc=测试数据 或者加单引号 '' lishan@xx-xx-xx-xx:~$ curl 'https://qaaiclass.xx.cn/grayscale/upstream/update?ups=10.10.xx.xx:8500&desc=测试数据' PHP学习 PHP——底层运行机制与原理_lili0710432的博客-CSDN博客_php运行机制 PHP内核中的神器之HashTable_上帝禁区的博客-CSDN博客_hashtable php 项目代码用到的redis,看日志查,以后再也不用问RD了。涉及到的redis的配置在psservice 日志为:更新数据库readNum的数量,后面是对redis日志进行操作, [readNum]1,是给key为[readNum]的加1
awk中的两个术语:
记录(默认就是文本的每一行)
字段 (默认就是每个记录中由空格或TAB分隔的字符串)
$0就表示一个记录,$1表示记录中的第一个字段。
一般 print $0 就是打印整行内容($0前面不需要反斜杠),print $1表示只打印每行第一个字段。
s表示替换,d表示删除
ups_choose = "default_aiclass_upstream_" .. port
end
平常为了查看日志,都是使用“tail -f”方式查看文件,为了便于筛选日志,我会选择使用“cut”、“grep”进行筛选,但这就带来了一个问题,那就是延迟
进行筛选之后,写到文件中的满足筛选条件的日志不会立马显示出来,而是数目达到一定量的(例如日志达到了十几行,或者是几百个字节),才会显示出来
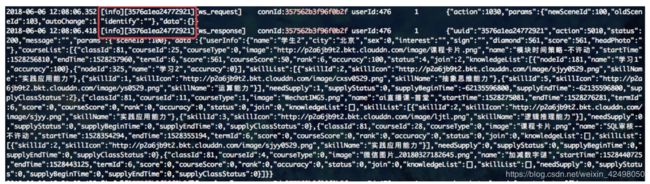

根据日志查询redis的key, 2018-06-20 20:50:47 [106.120.244.35][-][-][info][application] [RedisGet] [useCache:1]|redisKey= [common:saleCountByProductId:1204]|redisValue=
in /data/beta/washgold16/psservice/libs/Redis.php:74
in /data/beta/washgold16/backend/services/activity/ApiService.php:492
in /data/beta/washgold16/backend/modules/activity/controllers/ApiController.php:250
在psservice 的common下 /data/beta/washgold16/psservice/config/common 的 CommonCacheKey.php /data/beta/washgold16/psservice/config 的paramsConfig.php 找到common的key PS_COMMON_REDIS_HOST_1,在/data/beta/washgold16/psservice/config 的.env下找到此key 查找到对应的实例
单词部落

接口测试
接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的。有些接口可以天然的实现幂等性,比如查询接口,对于查询来说,查询一次和两次,对于系统来说,没有任何影响,查出的结果也是一样。除了查询功能具有天然的幂等性之外,增加、更新、删除都要保证幂等性。那么如何来保证幂等性呢

