Linux—进程管理
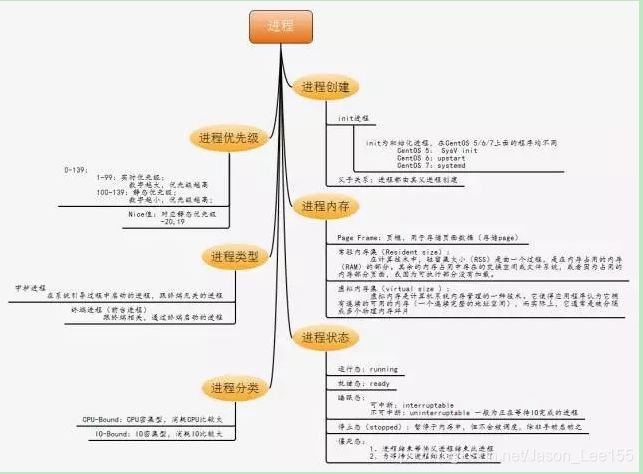
1. 进程的概念
Linux是一个多用户多任务的操作系统。多用户是指多个用户可以在同一时间使用同一个linux系统;多任务是指在Linux下可以同时执行多个任务,更详细的说,linux采用了分时管理的方法,所有的任务都放在一个队列中,操作系统根据每个任务的优先级为每个任务分配合适的时间片,每个时间片很短,用户根本感觉不到是多个任务在运行,从而使所有的任务共同分享系统资源,因此linux可以在一个任务还未执行完时,暂时挂起此任务,又去执行另一个任务,过一段时间以后再回来处理这个任务,直到这个任务完成,才从任务队列中去除。这就是多任务的概念。
上面说的是单CPU多任务操作系统的情形,在这种环境下,虽然系统可以运行多个任务,但是在某一个时间点,CPU只能执行一个进程,而在多CPU多任务的操作系统下,由于有多个CPU,所以在某个时间点上,可以有多个进程同时运行。
进程的的基本定义是:在自身的虚拟地址空间运行的一个独立的程序,从操作系统的角度来看,所有在系统上运行的东西,都可以称为一个进程。
需要注意的是:程序和进程是有区别的,进程虽然有程序产生,但是它并不是程序,程序是一个进程指令的集合,它可以启用一个或多个进程,同时,程序只占用磁盘空间,而不占用系统运行资源,而进程仅仅占用系统内存空间,是动态的、可变的,关闭进程,占用的内存资源随之释放。
例如,用户在linux上打开一个文件、就会产生一个打开文件的进程,关闭文件,进程也随机关闭。如果在系统上启动一个服务,例如启动tomcat服务,就会产生一个对应的java的进程。而如果启动apache服务,许多用户来同时请求http服务,apache服务器将会创建有多个http进程来对其进行服务 。
2. 进程分类
按照进程的功能和运行的程序分类,进程可划分为两大类:
系统进程:可以执行内存资源分配和进程切换等管理工作;而且,该进程的运行不受用户的干预,即使是root用户也不能干预系统进程的运行。
用户进程:通过执行用户程序、应用程序或内核之外的系统程序而产生的进程,此类进程可以在用户的控制下运行或关闭。
针对用户进程,又可以分为交互进程、批处理进程和守护进程三类。
1)交互进程:由一个shell终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台。
2)批处理进程:该进程是一个进程集合,负责按顺序启动其他的进程。
3)守护进程:守护进程是一直运行的一种进程,经常在linux系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。例如http进程,一直处于运行状态,等待用户的访问。还有经常用的crond进程,这个进程类似与windows的计划任务,可以周期性的执行用户设定的某些任务。
3. 进程的属性
进程ID(PID):是唯一的数值,用来区分进程;
父进程和父进程的ID(PPID);
启动进程的用户ID(UID)和所归属的组(GID);
进程状态:状态分为运行R、休眠S、僵尸Z;
进程执行的优先级;
进程所连接的终端名;
进程资源占用:比如占用资源大小(内存、CPU占用量);
使用shell命令:ps -aux
ps命令输出字段的含义
- USER,进程所有者的用户名。
- PID,进程号,可以唯一标识该进程。
- CPU,进程自最近一次刷新以来所占用的CPU时间和总时间的百分比。
- MEM,进程使用内存的百分比。
- VSZ,进程使用的虚拟内存大小,以K为单位。
- RSS,进程占用的物理内存的总数量,以K为单位。
- TTY,进程相关的终端名。
- STAT,进程状态,用(R–运行或准备运行;S–睡眠状态(Sleep);I–空闲(idle);Z–僵死(zombie);D–不间断睡眠;W-进程没有驻留页;T停止或跟踪。)这些字母来表示。
- START,进程开始运行时间。
- TIME,进程使用的总CPU时间。
- COMMAND,被执行的命令行。
4. Linux进程的结构
Linux中一个进程在内存里有三部分数据,就是“数据段”、“堆栈段”和“代码段”。基于I386兼容的中央处理器,都有上述三种段寄存器,以方便操作系统的运行,如图所示:
![]()
代码段:是存放了程序代码的数据,即存放CPU执行指令的集合。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
数据段:存放程序的全局变量、常数及动态数据分配的数据空间,即被执行指令所访问的数据。
堆栈段: 存放的就是子程序的返回地址、子程序的参数及程序的局部变量。堆栈段包含在进程控制块PCB(Process Control Block)中。PCB处于进程核心堆栈的底部,不需要额外分配空间。堆栈段包括堆和栈:
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味这在数据段中存放变量)。除此以外在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也回被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上将我们可以把堆栈看成一个临时数据寄存、交换的内存区。
5. Linux进程的状态
我们先看Linux的进程五态模型及其转换:

这些状态是task_struct结构的一部分:
1、R (task_running) : 可执行状态
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程 处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的 可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
2、S (task_interruptible): 可中断的睡眠状态
处于这个状态的进程因为等待某某事件的发生(比如等待socket连 接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等 待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于task_interruptible状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
3、D (task_uninterruptible): 不可中断的睡眠状态
与task_interruptible状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。但是uninterruptible sleep 状态的进程不接受外来的任何信号,因此无法用kill杀掉这些处于D状态的进程,无论是”kill”, “kill -9″还是”kill -15″,这种情况下,一个可选的方法就是reboot。
处于uninterruptible sleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如挂载的远程文件系统已经不可访问了.
而task_uninterruptible状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设 备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用task_uninterruptible状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的task_uninterruptible状态总是非常短暂的,通过ps命 令基本上不可能捕捉到。
我们通过vmstat 命令中procs下的b 可以来查看是否有处于uninterruptible 状态的进程。该命令只能显示数量。
4、T(task_stoppedor task_traced):暂停状态或跟踪状态
向进程发送一个sigstop信号,它就会因响应该信号而进入task_stopped状态(除非该进程本身处于task_uninterruptible状态而不响应信号)。(sigstop与sigkill信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。)
向进程发送一个sigcont信号,可以让其从task_stopped状态恢复到task_running状态。
当进程正在被跟踪时,它处于task_traced这个特殊的状态。“正 在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于task_traced状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,task_stopped和task_traced状态很类似,都是表示进程暂停下来。
而task_traced状态相当于在task_stopped之上多了一层保护,处于task_traced状态的进程不能响应sigcont信号而被唤醒。只能等到调试进程通过ptrace系统调用执行ptrace_cont、ptrace_detach等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复task_running状态。
5、Z (task_dead -exit_zombie):退出状态,进程成为僵尸进程
在Linux进程的状态中,僵尸进程是非常特殊的一种,它是已经结束了的进程,但是没有从进程表中删除。太多了会导致进程表里面条目满了,进而导致系统崩溃,倒是不占用其他系统资源。
它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在 进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。
进程在退出的过程中,处于TASK_DEAD状态。在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩 下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。
当然,内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收 尸”。父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。
如果他的父进程没安装SIGCHLD信号处理函数调用wait或waitpid()等待子进程结束,又没有显式忽略该信号,那么它就一直保持僵尸状态,子进程的尸体(task_struct)也就无法释放掉。
如果这时父进程结束了,那么init进程自动会接手这个子进程,为它收尸,它还是能被清除的。但是如果如果父进程是一个循环,不会结束, 那么子进程就会一直保持僵尸状态,这就是为什么系统中有时会有很多的僵尸进程。
当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管的进程可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程 存在。除非它是1号进程。1号进程,pid为1的进程,又称init进程。
6. Linux的进程树
他们的关系是管理和被管理的关系,当父进程终止时,子进程也随之而终止。但子进程终止,父进程并不一定终止。比如httpd服务器运行时,我们可以杀掉其子进程,父进程并不会因为子进程的终止而终止。
一个进程创建新进程称为创建了子进程(Child Process)。相反地,创建子进程的进程称为父进程。所有进程追溯其祖先最终都会落到进程号为1的进程身上,这个进程叫做init进程,是内核自举后第一个启动的进程。init进程扮演终结父进程的角色。因为init进程永远不会被终止,所以系统总是可以确信它的存在,并在必要的时候以它为参照。如果某个进程在它衍生出来的全部子进程结束之前被终止,就会出现必须以init为参照的情况。此时那些失去了父进程的子进程就都会以init作为它们的父进程。如果执行一下ps -af命令,可以列出许多父进程ID为1的进程来。Linux提供了一条ps tree命令,允许用户查看系统内正在运行的各个进程之间的继承关系。直接在命令行中输入ps tree即可,程序会以树状结构方式列出系统中正在运行的各进程之间的继承关系。
1. 父进程和子进程
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
父进程和子进程的关系是管理和被管理的关系,当父进程终止时,子进程也随之而终止。但子进程终止,父进程并不一定终止。比如httpd服务器运行时,我们可以杀掉其子进程,父进程并不会因为子进程的终止而终止。
父进程与子进程的差异:下图中,进程 A 为父进程,进程 B 为子进程

2. init进程
整个linux系统的所有进程也是一个树形结构。树根是系统自动构造的,即在内核态下执行的0号进程,它是所有进程的祖先。由0号进程创建1号进程(内核态),1号负责执行内核的部分初始化工作及进行系统配置,并创建若干个用于高速缓存和虚拟主存管理的内核线程。随后,1号进程调用execve()运行可执行程序init,并演变成用户态1号进程,即init进程。
所有进程追溯其祖先最终都会落到进程号为1的init进程。init进程扮演终结父进程的角色。因为init进程永远不会被终止,所以系统总是可以确信它的存在,并在必要的时候以它为参照。
init进程按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号...的若干终端注册进程getty。每个getty进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty进程将通过函数execve()执行注册程序login,此时用户就可输入注册名和密码进入登录过程,如果成功,由login程序再通过函数execv()执行shell,该shell进程接收getty进程的pid,取代原来的getty进程。再由shell直接或间接地产生其他进程。
上述过程可描述为:0号进程->1号内核进程->1号内核线程->1号用户进程(init进程)->getty进程->shell进程

注意,上述过程描述中提到:1号内核进程调用执行init并演变成1号用户态进程(init进程),这里前者是init是函数,后者是进程。两者容易混淆,区别如下:
1.init()函数在内核态运行,是内核代码
2.init进程是内核启动并运行的第一个用户进程,运行在用户态下。
3.init()函数调用execve()从文件/etc/inittab中加载可执行程序init并执行,这个过程并没有使用调用do_fork(),因此两个进程都是1号进程。
linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命:
1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙);
2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作;
init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于task_interruptible状态,“收尸”过程中则处于task_running状态。
进程的树状图:

7. Linux的进程控制
1. 进程的创建
一个进程通过调用fork()系统调用创建一个子进程(调用fork()的是父进程)。调用fork()时,创建的子进程复制父进程的data(数据段),heap(推段),stack段,共享父进程的Text段(Text段只读)。fork调用将执行两次返回,它将从父进程和子进程中分别返回:从父进程返回时的返回值为子进程的PID,而从子进程返回时的返回值为0,并且返回都将执行fork之后的语句。调用出错时,返回值为-1:
//实例:
#include
#include
#include
int main( )
{
pid_t pid;
pid=fork();
if((pid)<0)
{
printf(“fork error!\n”);
exit(1);
}
else if(pid=0)
printf(“child process isprinting.IDis %d\n”,getpid());
else
printf(“parent process is printing. ID is%d\n”,getpid());
} 运行结果:
[root@]# gcc fork_c.c -o fork_c
[root@]# ./ fork_c
I am the child process,ID is 4238 I am the parent process,ID is 4237因为 fork()函数用于从已存在的进程中创建一个新的子进程,在 pid=fork();语句之前只有父进程在运行,而在之后,父进程和新创建的子进程都在运行,子进程拷贝父进程的代码段,所以子进程中同样有:
if(pid<0)
printf("error in fork!");
else if(pid==0)
printf("I am the child process,ID is %d\n",getpid());
else
printf("I am the parent process,ID is %d\n",getpid());我们再看看:
#include
#include
int main( )
{
pid_t pid;
Intcount =0;
pid=fork();
Count++;
Printf(“count=%d\n”,count);
Return 0;
} 将被父子进程各执行一次,但是子进程执行时使自己的数据段里面的(这个数据段是从父进程那 copy过来的一模一样)count+1,同样父进程执行时使自己的数据段里面count+1,互不影响。
输出:Count=1
Count=1
vfork的作用和fork基本相同,区别在于:
vfork并不完全复制父进程的数据段,而是和父进程共享数据段。调用vfork对于父子进程的执行次序有所限制。调用vfork函数将使父进程挂起,直至子进程返回。vfork 保证子进程先运行,在她调用 exec 或 exit 之后父进程才可能被调度运行。
2.进程的执行:
使用exec族的函数执行新的程序,以新的子进程完全替代原有的进程:
int execl(const char *pathname,const char *arg,…);
int execlp(const char *filename,conxt char *arg,…);
int execle(const char *pathname,conxt char *arg,…,char #const encp[]);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *filename, char *const argv[]);
int execve(const char *pathname, char *const argv[],char *const envp[]);exec函数族的特点:
用于启动一个指定路径和文件名的进程。 某进程一旦调用了exec类函数,正在执行的程序结束,系统把代码段换成新的程序的代码,原有的数据段和堆栈段也被放弃,新的数据段和堆栈段被分配,但是进程号被保留。
结果为:系统认为正在执行的还是原来的进程,但是进程对应的程序被替换了。
子进程可以通过调用execve()函数来载入和运行另一个程序,这时子进程的Text,Data,Heap,Stack将被新程序对应的东西替换。C library里面有一些exec开头的函数作用是差不多的。fork和exec搭配实现让父进程的代码执行又启动一个新的指定的进程。
execl()使用范例:
#include
#include
#include
main()
{
pid_t pid;
printf("Now only one process\n");
printf("Calling fork...\n");
pid=fork();
if(pid==0) /*进程为子进程*/
{
printf("I am the child\n");
execl("/bin/ls","-l",NULL);/*如果execl返回,说明调用失败*/
perror("execl failed to run ls");
exit(1);
} else if(pid>0) /*进程为父进程*/
{
printf("I'm the parent, my child's pid is %d\n",pid);
execl("/bin/ps","-c",NULL);
/*如果execl返回,说明调用失败*/
perror("execl failed to run ls");
exit(1);
} else {
printf("Fork fall!\n");
}
} 3. 进程的终止和终止状态
1).自杀:调用_exit()(或者相关的library中的exit()函数
2).他杀:给进程传送某种signal
_exit()可以指定终结的状态(终结的状态通常就是一个很小的整数)。通过某种signal终结进程,终结的状态根据signal的种类而不同。父进程通过wait()系统调用函数可以获取子进程终结后的终结状态。
8. Linux进程调度
Linux/UNIX系统是单纯的分时系统,未设置高级调度——作业调度,只设置了中级调度——进程对换和低级调度——进程调度。
1.引起进程调度的原因
首先,由于Linux/UNIX系统是分时系统,因而其时钟中断处理程序须每隔一定时间便对要求进程调度程序进行调度的标志 runrun 予以置位,以引起调度程序重新调度。其次,当进程执行了 wait、exit 及 sleep 等系统调用后要放弃处理机时,也会引起调度程序重新进行调度。此外,当进程执行完系统调用功能而从核心态返回到用户态时,如果系统中又出现了更高优先级的进程在等待处理机时,内核应抢占当前进程的处理机,这也会引起调度。
2.调度算法
采用动态优先数轮转调度算法进行进程调度。调度程序在进行调度时,首先从处于“内存就绪”或“被抢占”状态的进程中选择一个其优先数最小(优先级最高)的进程。若此时系统中(同时)有多个进程都具有相同的最高优先级,则内核将选择其中处于就绪状态或被抢占状态最久的进程,将它从其所在队列中移出,并进行进程上下文的切换,恢复其运行。
3.进程优先级的分类
Linux/UNIX系统把进程的优先级分成两类
第一类是核心优先级,又可进一步把它分为可中断和不可中断两种。当一个软中断信号到达时,若有进程正在可中断优先级上睡眠,该进程将立即被唤醒;若有进程处于不可中断优先级上,则该进程继续睡眠。诸如“对换” 、 “等待磁盘I/O” 、 “等待缓冲区”等几个优先级,都属于不可中断优先级;而“等待输入” 、 “等待终端输出” 、 “等待子进程退出”几个优先级,都是可中断优先级。
另一类是用户优先级, 它又被分成n+1级,其中第0级为最高优先级,第 n级的优先级最低。
4.进程优先数的计算
在进程调度算法中,非常重要的部分是如何计算进程的优先数。在系统Ⅴ中,进程优先数的计算公式可表示如下:
优先数 = CPU的时间最近使用/2 + 基本用户优先数
其中,基本用户优先数即 proc 结构中的偏移值 nice,可由用户将它设置成 0~40 中的任一个数。一旦设定后,用户仅能使其值增加,特权用户才有权减小 nice的值。而最近使用CPU的时间,则是指当前占有处理机的进程本次使用 CPU 的时间。内核每隔 16.667 ms 便对该时间做加 1 操作, 这样,占有 CPU 的进程其优先数将会随着它占有 CPU 时间的增加而加大,相应地,其优先级便随之降低。
5.进程切换
在OS中,凡要进行中断处理和执行系统调用时,都将涉及到进程上下文的保存和恢复问题,此时系统所保存或恢复的上下文都是属于同一个进程的。而在进程调度之后,内核所应执行的是进程上下文的切换,即内核是把当前进程的上下文保存起来,而所恢复的则是进程调度程序所选中的进程的上下文,以使该进程能恢复执行。
8. 进程优先级nice和priority详解
nice
nice值应该是熟悉Linux/UNIX的人很了解的概念了,我们都知它是反应一个进程“优先级”状态的值,其取值范围是-20至19,一共40个级别。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。我们可以通过nice命令来对一个将要执行的命令进行nice值设置,方法是:
[root@]# nice -n 10 bash这样我就又打开了一个bash,并且其nice值设置为10,而默认情况下,进程的优先级应该是从父进程继承来的,这个值一般是0。我们可以通过nice命令直接查看到当前shell的nice值
[root@]# nice
10对比一下正常情况:
[root@]# exit推出当前nice值为10的bash,打开一个正常的bash:
[root@]# bash
[root@]# nice
0另外,使用renice命令可以对一个正在运行的进程进行nice值的调整,我们也可以使用比如top、ps等命令查看进程的nice值,具体方法我就不多说了,大家可以参阅相关manpage。
需要大家注意的是,在这里都在使用nice值这一称谓,而非优先级priority这个说法。当然,nice和renice的man手册中,也说的是priority这个概念,但是要强调一下,请大家真的不要混淆了系统中的这两个概念,一个是nice值,一个是priority值,他们有着千丝万缕的关系,但对于当前的Linux系统来说,它们并不是同一个概念。
我们看这个命令:
[root@~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 8526 8524 0 80 0 - 27116 wait pts/0 00:00:00 bash
4 R 0 12657 8526 0 80 0 - 27033 - pts/0 00:00:00 ps大家是否真的明白其中PRI列和NI列的具体含义有什么区别?同样的,如果是top命令:
top - 11:03:53 up 237 days, 17:24, 1 user, load average: 0.16, 0.14, 0.11
Tasks: 166 total, 1 running, 163 sleeping, 2 stopped, 0 zombie
Cpu(s): 5.0%us, 2.0%sy, 0.0%ni, 91.9%id, 0.7%wa, 0.2%hi, 0.2%si, 0.0%st
Mem: 8058056k total, 7739172k used, 318884k free, 492448k buffers
Swap: 8388600k total, 6444k used, 8382156k free, 1858760k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 大家是否搞清楚了这其中PR值和NI值的差别?如果没有,那么我们可以首先搞清楚什么是nice值。
nice值虽然不是priority,但是它确实可以影响进程的优先级。
在英语中,如果我们形容一个人nice,那一般说明这个人的人缘比较好。什么样的人人缘好?往往是谦让、有礼貌的人。比如,你跟一个nice的人一起去吃午饭,点了两个一样的饭,先上了一份后,nice的那位一般都会说:“你先吃你先吃!”,这就是人缘好,这人nice!但是如果另一份上的很晚,那么这位nice的人就要饿着了。这说明什么?越nice的人抢占资源的能力就越差,而越不nice的人抢占能力就越强。这就是nice值大小的含义,nice值越低,说明进程越不nice,抢占cpu的能力就越强,优先级就越高。在原来使用O1调度的Linux上,我们还会把nice值叫做静态优先级,这也基本符合nice值的特点,就是当nice值设定好了之后,除非我们用renice去改它,否则它是不变的。而priority的值在之前内核的O1调度器上表现是会变化的,所以也叫做动态优先级。
优先级和实时进程
简单了解nice值的概念之后,我们再来看看什么是priority值,就是ps命令中看到的PRI值或者top命令中看到的PR值。本文为了区分这些概念,以后统一用nice值表示NI值,或者叫做静态优先级,也就是用nice和renice命令来调整的优先级;而使用priority值表示PRI和PR值,或者叫动态优先级。我们也统一将“优先级”这个词的概念规定为表示priority值的意思。
在内核中,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是MAX_PRIO,它的值为140。而这个值又是由另外两个值相加组成的,一个是代表nice值取值范围的NICE_WIDTH宏,另一个是代表实时进程realtime优先级范围的MAX_RT_PRIO宏。说白了就是,Linux实际上实现了140个优先级范围,取值范围是从0-139,这个值越小,优先级越高。nice值的-20到19,映射到实际的优先级范围是100-139。新产生进程的默认优先级被定义为:
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)实际上对应的就是nice值的0。正常情况下,任何一个进程的优先级都是这个值,即使我们通过nice和renice命令调整了进程的优先级,它的取值范围也不会超出100-139的范围,除非这个进程是一个实时进程,那么它的优先级取值才会变成0-99这个范围中的一个。这里隐含了一个信息,就是说当前的Linux是一种已经支持实时进程的操作系统。
什么是实时操作系统,我们就不再这里详细解释其含义以及在工业领域的应用了,有兴趣的可以参考一下实时操作系统的维基百科[2]。简单来说,实时操作系统需要保证相关的实时进程在较短的时间内响应,不会有较长的延时,并且要求最小的中断延时和进程切换延时。对于这样的需求,一般的进程调度算法,无论是O1还是CFS都是无法满足的,所以内核在设计的时候,将实时进程单独映射了100个优先级,这些优先级都要高与正常进程的优先级(nice值),而实时进程的调度算法也不同,它们采用更简单的调度算法来减少调度开销。总的来说,Linux系统中运行的进程可以分成两类:
- 实时进程
- 非实时进程
它们的主要区别就是通过优先级来区分的。所有优先级值在0-99范围内的,都是实时进程,所以这个优先级范围也可以叫做实时进程优先级,而100-139范围内的是非实时进程。在系统中可以使用chrt命令来查看、设置一个进程的实时优先级状态。我们可以先来看一下chrt命令的使用:
[root@~]# chrt
chrt - manipulate real-time attributes of a process.
Set policy:
chrt [options] { | [ ...]}
Get policy:
chrt [options] { | [ ...]}
Scheduling policies:
-b | --batch set policy to SCHED_BATCH
-f | --fifo set policy to SCHED_FIFO
-i | --idle set policy to SCHED_IDLE
-o | --other set policy to SCHED_OTHER
-r | --rr set policy to SCHED_RR (default)
Options:
-h | --help display this help
-p | --pid operate on existing given pid
-m | --max show min and max valid priorities
-v | --verbose display status information
-V | --version output version information 我们先来关注显示出的Scheduling policies部分,会发现系统给个种进程提供了5种调度策略。但是这里并没有说明的是,这五种调度策略是分别给两种进程用的,对于实时进程可以用的调度策略是:SCHED_FIFO、SCHED_RR,而对于非实时进程则是:SCHED_OTHER、SCHED_OTHER、SCHED_IDLE。
系统的整体优先级策略是:如果系统中存在需要执行的实时进程,则优先执行实时进程。直到实时进程退出或者主动让出CPU时,才会调度执行非实时进程。实时进程可以指定的优先级范围为1-99,将一个要执行的程序以实时方式执行的方法为:
[root@ ~]# chrt 10 bash
[root@ ~]# chrt -p $$
pid 18914's current scheduling policy: SCHED_RR
pid 18914's current scheduling priority: 10可以看到,新打开的bash已经是实时进程,默认调度策略为SCHED_RR,优先级为10。如果想修改调度策略,就加个参数:
[root@ ~]# chrt -f 10 bash
[root@ ~]# chrt -p $$
pid 19697's current scheduling policy: SCHED_FIFO
pid 19697's current scheduling priority: 10刚才说过,SCHED_RR和SCHED_FIFO都是实时调度策略,只能给实时进程设置。对于所有实时进程来说,优先级高的(就是priority数字小的)进程一定会保证先于优先级低的进程执行。SCHED_RR和SCHED_FIFO的调度策略只有当两个实时进程的优先级一样的时候才会发生作用,其区别也是顾名思义:
SCHED_FIFO:以先进先出的队列方式进行调度,在优先级一样的情况下,谁先执行的就先调度谁,除非它退出或者主动释放CPU。
SCHED_RR:以时间片轮转的方式对相同优先级的多个进程进行处理。时间片长度为100ms。
这就是Linux对于实时进程的优先级和相关调度算法的描述。整体很简单,也很实用。而相对更麻烦的是非实时进程,它们才是Linux上进程的主要分类。对于非实时进程优先级的处理,我们首先还是要来介绍一下它们相关的调度算法:O1和CFS。
O1调度
O1调度算法是在Linux 2.6开始引入的,到Linux 2.6.23之后内核将调度算法替换成了CFS。虽然O1算法已经不是当前内核所默认使用的调度算法了,但是由于大量线上的服务器可能使用的Linux版本还是老版本,所以我相信很多服务器还是在使用着O1调度器,那么费一点口舌简单交代一下这个调度器也是有意义的。这个调度器的名字之所以叫做O1,主要是因为其算法的时间复杂度是O1。
O1调度器仍然是根据经典的时间片分配的思路来进行整体设计的。简单来说,时间片的思路就是将CPU的执行时间分成一小段一小段的,假如是5ms一段。于是多个进程如果要“同时”执行,实际上就是每个进程轮流占用5ms的cpu时间,而从1s的时间尺度上看,这些进程就是在“同时”执行的。当然,对于多核系统来说,就是把每个核心都这样做就行了。而在这种情况下,如何支持优先级呢?实际上就是将时间片分配成大小不等的若干种,优先级高的进程使用大的时间片,优先级小的进程使用小的时间片。这样在一个周期结速后,优先级大的进程就会占用更多的时间而因此得到特殊待遇。O1算法还有一个比较特殊的地方是,即使是相同的nice值的进程,也会再根据其CPU的占用情况将其分成两种类型:CPU消耗型和IO消耗性。典型的CPU消耗型的进程的特点是,它总是要一直占用CPU进行运算,分给它的时间片总是会被耗尽之后,程序才可能发生调度。比如常见的各种算数运算程序。而IO消耗型的特点是,它经常时间片没有耗尽就自己主动先释放CPU了,比如vi,emacs这样的编辑器就是典型的IO消耗型进程。为什么要这样区分呢?因为IO消耗型的进程经常是跟人交互的进程,比如shell、编辑器等。当系统中既有这种进程,又有CPU消耗型进程存在,并且其nice值一样时,假设给它们分的时间片长度是一样的,都是500ms,那么人的操作可能会因为CPU消耗型的进程一直占用CPU而变的卡顿。可以想象,当bash在等待人输入的时候,是不占CPU的,此时CPU消耗的程序会一直运算,假设每次都分到500ms的时间片,此时人在bash上敲入一个字符的时候,那么bash很可能要等个几百ms才能给出响应,因为在人敲入字符的时候,别的进程的时间片很可能并没有耗尽,所以系统不会调度bash程度进行处理。为了提高IO消耗型进程的响应速度,系统将区分这两类进程,并动态调整CPU消耗的进程将其优先级降低,而IO消耗型的将其优先级变高,以降低CPU消耗进程的时间片的实际长度。已知nice值的范围是-20 - 19,其对应priority值的范围是100-139,对于一个默认nice值为0的进程来说,其初始priority值应该是120,随着其不断执行,内核会观察进程的CPU消耗状态,并动态调整priority值,可调整的范围是+-5。就是说,最高其优先级可以呗自动调整到115,最低到125。这也是为什么nice值叫做静态优先级而priority值叫做动态优先级的原因。不过这个动态调整的功能在调度器换成CFS之后就不需要了,因为CFS换了另外一种CPU时间分配方式,这个我们后面再说。
再简单了解了O1算法按时间片分配CPU的思路之后,我们再来结合进程的状态简单看看其算法描述。我们都知道进程有5种状态:
- S(Interruptible sleep):可中断休眠状态。
- D(Uninterruptible sleep):不可中断休眠状态。
- R(Running or runnable):执行或者在可执行队列中。
- Z(Zombie process):僵尸。
- T(Stopped):暂停。
在CPU调度时,主要只关心R状态进程,因为其他状态进程并不会被放倒调度队列中进行调度。调度队列中的进程一般主要有两种情况,一种是进程已经被调度到CPU上执行,另一种是进程正在等待被调度。出现这两种状态的原因应该好理解,因为需要执行的进程数可能多于硬件的CPU核心数,比如需要执行的进程有8个而CPU核心只有4个,此时cpu满载的时候,一定会有4个进程处在“等待”状态,因为此时有另外四个进程正在占用CPU执行。
根据以上情况我们可以理解,系统当下需要同时进行调度处理的进程数(R状态进程数)和系统CPU的比值,可以一定程度的反应系统的“繁忙”程度。需要调度的进程越多,核心越少,则意味着系统越繁忙。除了进程执行本身需要占用CPU以外,多个进程的调度切换也会让系统繁忙程度增加的更多。所以,我们往往会发现,R状态进程数量在增长的情况下,系统的性能表现会下降。系统中可以使用uptime命令查看系统平均负载指数load average:
[zorro@zorrozou-pc0 ~]$ uptime
16:40:56 up 2:12, 1 user, load average: 0.05, 0.11, 0.16其中load average中分别显示的是1分钟,5分钟,15分钟之内的平均负载指数(可以简单认为是相映时间范围内的R状态进程个数)。但是这个命令显示的数字是绝对个数,并没有表示出不同CPU核心数的实际情况。比如,如果我们的1分钟load average为16,而CPU核心数为32的话,那么这个系统的其实并不繁忙。但是如果CPU个数是8的话,那可能就意味着比较忙了。但是实际情况往往可能比这更加复杂,比如进程消耗类型也会对这个数字的解读有影响。总之,这个值的绝对高低并不能直观的反馈出来当前系统的繁忙程度,还需要根据系统的其它指标综合考虑。
O1调度器在处理流程上大概是这样进行调度的:
- 首先,进程产生fork的时候会给一个进程分配一个时间片长度。这个新进程的时间片一般是父进程的一半,而父进程也会因此减少它的时间片长度为原来的一半。就是说,如果一个进程产生了子进程,那么它们将会平分当前时间片长度。比如,如果父进程时间片还剩100ms,那么一个fork产生一个子进程之后,子进程的时间片是50ms,父进程剩余的时间片是也是50ms。这样设计的目的是,为了防止进程通过fork的方式让自己所处理的任务一直有时间片。不过这样做也会带来少许的不公平,因为先产生的子进程获得的时间片将会比后产生的长,第一个子进程分到父进程的一半,那么第二个子进程就只能分到1/4。对于一个长期工作的进程组来说,这种影响可以忽略,因为第一轮时间片在耗尽后,系统会在给它们分配长度相当的时间片。
- 针对所有R状态进程,O1算法使用两个队列组织进程,其中一个叫做活动队列,另一个叫做过期队列。活动队列中放的都是时间片未被耗尽的进程,而过期队列中放时间片被耗尽的进程。
- 如1所述,新产生的进程都会先获得一个时间片,进入活动队列等待调度到CPU执行。而内核会在每个tick间隔期间对正在CPU上执行的进程进行检查。一般的tick间隔时间就是cpu时钟中断间隔,每秒钟会有1000个,即频率为1000HZ。每个tick间隔周期主要检查两个内容:1、当前正在占用CPU的进程是不是时间片已经耗尽了?2、是不是有更高优先级的进程在活动队列中等待调度?如果任何一种情况成立,就把则当前进程的执行状态终止,放到等待队列中,换当前在等待队列中优先级最高的那个进程执行。
以上就是O1调度的基本调度思路,当然实际情况是,还要加上SMP(对称多处理)的逻辑,以满足多核CPU的需求。目前在我的archlinux上可以用以下命令查看内核HZ的配置:
[zorro@zorrozou-pc0 ~]$ zgrep CONFIG_HZ /proc/config.gz
# CONFIG_HZ_PERIODIC is not set
# CONFIG_HZ_100 is not set
# CONFIG_HZ_250 is not set
CONFIG_HZ_300=y
# CONFIG_HZ_1000 is not set
CONFIG_HZ=300我们发现我当前系统的HZ配置为300,而不是一般情况下的1000。大家也可以思考一下,配置成不同的数字(100、250、300、1000),对系统的性能到底会有什么影响?
CFS完全公平调度
O1已经是上一代调度器了,由于其对多核、多CPU系统的支持性能并不好,并且内核功能上要加入cgroup等因素,Linux在2.6.23之后开始启用CFS作为对一般优先级(SCHED_OTHER)进程调度方法。在这个重新设计的调度器中,时间片,动态、静态优先级以及IO消耗,CPU消耗的概念都不再重要。CFS采用了一种全新的方式,对上述功能进行了比较完善的支持。
其设计的基本思路是,我们想要实现一个对所有进程完全公平的调度器。又是那个老问题:如何做到完全公平?答案跟上一篇IO调度中CFQ的思路类似:如果当前有n个进程需要调度执行,那么调度器应该再一个比较小的时间范围内,把这n个进程全都调度执行一遍,并且它们平分cpu时间,这样就可以做到所有进程的公平调度。那么这个比较小的时间就是任意一个R状态进程被调度的最大延时时间,即:任意一个R状态进程,都一定会在这个时间范围内被调度相应。这个时间也可以叫做调度周期,其英文名字叫做:sched_latency_ns。进程越多,每个进程在周期内被执行的时间就会被平分的越小。调度器只需要对所有进程维护一个累积占用CPU时间数,就可以衡量出每个进程目前占用的CPU时间总量是不是过大或者过小,这个数字记录在每个进程的vruntime中。所有待执行进程都以vruntime为key放到一个由红黑树组成的队列中,每次被调度执行的进程,都是这个红黑树的最左子树上的那个进程,即vruntime时间最少的进程,这样就保证了所有进程的相对公平。
在基本驱动机制上CFS跟O1一样,每次时钟中断来临的时候,都会进行队列调度检查,判断是否要进程调度。当然还有别的时机需要调度检查,发生调度的时机可以总结为这样几个:
- 当前进程的状态转换时。主要是指当前进程终止退出或者进程休眠的时候。
- 当前进程主动放弃CPU时。状态变为sleep也可以理解为主动放弃CPU,但是当前内核给了一个方法,可以使用sched_yield()在不发生状态切换的情况下主动让出CPU。
- 当前进程的vruntime时间大于每个进程的理想占用时间时(delta_exec > ideal_runtime)。这里的ideal_runtime实际上就是上文说的sched_latency_ns/进程数n。当然这个值并不是一定这样得出,下文会有更详细解释。
- 当进程从中断、异常或系统调用返回时,会发生调度检查。比如时钟中断。
CFS的优先级
当然,CFS中还需要支持优先级。在新的体系中,优先级是以时间消耗(vruntime增长)的快慢来决定的。就是说,对于CFS来说,衡量的时间累积的绝对值都是一样纪录在vruntime中的,但是不同优先级的进程时间增长的比率是不同的,高优先级进程时间增长的慢,低优先级时间增长的快。比如,优先级为19的进程,实际占用cpu为1秒,那么在vruntime中就记录1s。但是如果是-20优先级的进程,那么它很可能实际占CPU用10s,在vruntime中才会纪录1s。CFS真实实现的不同nice值的cpu消耗时间比例在内核中是按照“每差一级cpu占用时间差10%左右”这个原则来设定的。这里的大概意思是说,如果有两个nice值为0的进程同时占用cpu,那么它们应该每人占50%的cpu,如果将其中一个进程的nice值调整为1的话,那么此时应保证优先级高的进程比低的多占用10%的cpu,就是nice值为0的占55%,nice值为1的占45%。那么它们占用cpu时间的比例为55:45。这个值的比例约为1.25。就是说,相邻的两个nice值之间的cpu占用时间比例的差别应该大约为1.25。根据这个原则,内核对40个nice值做了时间计算比例的对应关系,它在内核中以一个数组存在:
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};我们看到,实际上nice值的最高优先级和最低优先级的时间比例差距还是很大的,绝不仅仅是例子中的十倍。由此我们也可以推导出每一个nice值级别计算vruntime的公式为:
delta vruntime = delta Time * 1024 / load
这个公式的意思是说,在nice值为0的时候(对应的比例值为1024),计算这个进程vruntime的实际增长时间值delta vruntime为:CPU占用时间delta Time* 1024 / load。在这个公式中load代表当前sched_entity的值,其实就可以理解为需要调度的进程(R状态进程)个数。load越大,那么每个进程所能分到的时间就越少。CPU调度是内核中会频繁进行处理的一个时间,于是上面的delta vruntime的运算会被频繁计算。除法运算会占用更多的cpu时间,所以内核编程中的一个原则就是,尽可能的不用除法。内核中要用除法的地方,基本都用乘法和位移运算来代替,所以上面这个公式就会变成:
delta vruntime = delta time * 1024 * (2^32 / (load * 2^32)) = (delta time * 1024 * Inverse(load)) >> 32
内核中为了方便不同nice值的Inverse(load)的相关计算,对做好了一个跟prio_to_weight数组一一对应的数组,在计算中可以直接拿来使用,减少计算时的CPU消耗:
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};具体计算细节不在这里细解释了,有兴趣的可以自行阅读代码:kernel/shced/fair.c(Linux 4.4)中的__calc_delta()函数实现。
根据CFS的特性,我们知道调度器总是选择vruntime最小的进程进行调度。那么如果有两个进程的初始化vruntime时间一样时,一个进程被选择进行调度处理,那么只要一进行处理,它的vruntime时间就会大于另一个进程,CFS难道要马上换另一个进程处理么?出于减少频繁切换进程所带来的成本考虑,显然并不应该这样。CFS设计了一个sched_min_granularity_ns参数,用来设定进程被调度执行之后的最小CPU占用时间。
[zorro@zorrozou-pc0 ~]$ cat /proc/sys/kernel/sched_min_granularity_ns
2250000一个进程被调度执行后至少要被执行这么长时间才会发生调度切换。
我们知道无论到少个进程要执行,它们都有一个预期延迟时间,即:sched_latency_ns,系统中可以通过如下命令来查看这个时间:
[zorro@zorrozou-pc0 ~]$ cat /proc/sys/kernel/sched_latency_ns
18000000在这种情况下,如果需要调度的进程个数为n,那么平均每个进程占用的CPU时间为sched_latency_ns/n。显然,每个进程实际占用的CPU时间会因为n的增大而减小。但是实现上不可能让它无限的变小,所以sched_min_granularity_ns的值也限定了每个进程可以获得的执行时间周期的最小值。当进程很多,导致使用了sched_min_granularity_ns作为最小调度周期时,对应的调度延时也就不在遵循sched_latency_ns的限制,而是以实际的需要调度的进程个数n * sched_min_granularity_ns进行计算。当然,我们也可以把这理解为CFS的”时间片”,不过我们还是要强调,CFS是没有跟O1类似的“时间片“的概念的,具体区别大家可以自己琢磨一下。
新进程的VRUNTIME值
CFS是通过vruntime最小值来选择需要调度的进程的,那么可以想象,在一个已经有多个进程执行了相对较长的系统中,这个队列中的vruntime时间纪录的数值都会比较长。如果新产生的进程直接将自己的vruntime值设置为0的话,那么它将在执行开始的时间内抢占很多的CPU时间,直到自己的vruntime追赶上其他进程后才可能调度其他进程,这种情况显然是不公平的。所以CFS对每个CPU的执行队列都维护一个min_vruntime值,这个值纪录了这个CPU执行队列中vruntime的最小值,当队列中出现一个新建的进程时,它的初始化vruntime将不会被设置为0,而是根据min_vruntime的值为基础来设置。这样就保证了新建进程的vruntime与老进程的差距在一定范围内,不会因为vruntime设置为0而在进程开始的时候占用过多的CPU。
新建进程获得的实际vruntime值跟一些设置有关,比如:
[zorro@zorrozou-pc0 ~]$ cat /proc/sys/kernel/sched_child_runs_first
0这个文件是fork之后是否让子进程优先于父进程执行的开关。0为关闭,1为打开。如果这个开关打开,就意味着子进程创建后,保证子进程在父进程之前被调度。另外,在源代码目录下的kernel/sched/features.h文件中,还规定了一系列调度器属性开关。而其中:
/*
* Place new tasks ahead so that they do not starve already running
* tasks
*/
SCHED_FEAT(START_DEBIT, true)这个参数规定了新进程启动之后第一次运行会有延时。这意味着新进程的vruntime设置要比默认值大一些,这样做的目的是防止应用通过不停的fork来尽可能多的获得执行时间。子进程在创建的时候,vruntime的定义的步骤如下,首先vruntime被设置为min_vruntime。然后判断START_DEBIT位是否被值为true,如果是则会在min_vruntime的基础上增大一些,增大的时间实际上就是一个进程的调度延时时间,即上面描述过的calc_delta_fair()函数得到的结果。这个时间设置完毕之后,就检查sched_child_runs_first开关是否打开,如果打开(值被设置为1),就比较新进程的vruntime和父进程的vruntime哪个更小,并将新进程的vruntime设置为更小的那个值,而父进程的vruntime设置为更大的那个值,以此保证子进程一定在父进程之前被调度。
IO消耗型进程的处理
根据前文,我们知道除了可能会一直占用CPU时间的CPU消耗型进程以外,还有一类叫做IO消耗类型的进程,它们的特点是基本不占用CPU,主要行为是在S状态等待响应。这类进程典型的是vim,bash等跟人交互的进程,以及一些压力不大的,使用了多进程(线程)的或select、poll、epoll的网络代理程序。如果CFS采用默认的策略处理这些程序的话,相比CPU消耗程序来说,这些应用由于绝大多数时间都处在sleep状态,它们的vruntime时间基本是不变的,一旦它们进入了调度队列,将会很快被选择调度执行。对比O1调度算法,这种行为相当于自然的提高了这些IO消耗型进程的优先级,于是就不需要特殊对它们的优先级进行“动态调整”了。
但这样的默认策略也是有问题的,有时CPU消耗型和IO消耗型进程的区分不是那么明显,有些进程可能会等一会,然后调度之后也会长时间占用CPU。这种情况下,如果休眠的时候进程的vruntime保持不变,那么等到休眠被唤醒之后,这个进程的vruntime时间就可能会比别人小很多,从而导致不公平。所以对于这样的进程,CFS也会对其进行时间补偿。补偿方式为,如果进程是从sleep状态被唤醒的,而且GENTLE_FAIR_SLEEPERS属性的值为true,则vruntime被设置为sched_latency_ns的一半和当前进程的vruntime值中比较大的那个。sched_latency_ns的值可以在这个文件中进行设置:
[zorro@zorrozou-pc0 ~]$ cat /proc/sys/kernel/sched_latency_ns
18000000因为系统中这种调度补偿的存在,IO消耗型的进程总是可以更快的获得响应速度。这是CFS处理与人交互的进程时的策略,即:通过提高响应速度让人的操作感受更好。但是有时候也会因为这样的策略导致整体性能受损。在很多使用了多进程(线程)或select、poll、epoll的网络代理程序,一般是由多个进程组成的进程组进行工作,典型的如apche、nginx和php-fpm这样的处理程序。它们往往都是由一个或者多个进程使用nanosleep()进行周期性的检查是否有新任务,如果有责唤醒一个子进程进行处理,子进程的处理可能会消耗CPU,而父进程则主要是sleep等待唤醒。这个时候,由于系统对sleep进程的补偿策略的存在,新唤醒的进程就可能会打断正在处理的子进程的过程,抢占CPU进行处理。当这种打断很多很频繁的时候,CPU处理的过程就会因为频繁的进程上下文切换而变的很低效,从而使系统整体吞吐量下降。此时我们可以使用开关禁止唤醒抢占的特性。
[root@zorrozou-pc0 zorro]# cat /sys/kernel/debug/sched_features
GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK LB_BIAS NONTASK_CAPACITY TTWU_QUEUE RT_PUSH_IPI NO_FORCE_SD_OVERLAP RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD上面显示的这个文件的内容就是系统中用来控制kernel/sched/features.h这个文件所列内容的开关文件,其中WAKEUP_PREEMPTION表示:目前的系统状态是打开sleep唤醒进程的抢占属性的。可以使用如下命令关闭这个属性:
[root@zorrozou-pc0 zorro]# echo NO_WAKEUP_PREEMPTION > /sys/kernel/debug/sched_features
[root@zorrozou-pc0 zorro]# cat /sys/kernel/debug/sched_features
GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY NO_WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK LB_BIAS NONTASK_CAPACITY TTWU_QUEUE RT_PUSH_IPI NO_FORCE_SD_OVERLAP RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD其他相关参数的调整也是类似这样的方式。其他我没讲到的属性的含义,大家可以看kernel/sched/features.h文件中的注释。
系统中还提供了一个sched_wakeup_granularity_ns配置文件,这个文件的值决定了唤醒进程是否可以抢占的一个时间粒度条件。默认CFS的调度策略是,如果唤醒的进程vruntime小于当前正在执行的进程,那么就会发生唤醒进程抢占的情况。而sched_wakeup_granularity_ns这个参数是说,只有在当前进程的vruntime时间减唤醒进程的vruntime时间所得的差大于sched_wakeup_granularity_ns时,才回发生抢占。就是说sched_wakeup_granularity_ns的值越大,越不容易发生抢占。
CFS和其他调度策略
SCHED_BATCH
在上文中我们说过,CFS调度策略主要是针对chrt命令显示的SCHED_OTHER范围的进程,实际上就是一般的非实时进程。我们也已经知道,这样的一般进程还包括另外两种:SCHED_BATCH和SCHED_IDLE。在CFS的实现中,集成了对SCHED_BATCH策略的支持,并且其功能和SCHED_OTHER策略几乎是一致的。唯一的区别在于,如果一个进程被用chrt命令标记成SCHED_OTHER策略的话,CFS将永远认为这个进程是CPU消耗型的进程,不会对其进行IO消耗进程的时间补偿。这样做的唯一目的是,可以在确认进程是CPU消耗型的进程的前提下,对其尽可能的进行批处理方式调度(batch),以减少进程切换带来的损耗,提高吞度量。实际上这个策略的作用并不大,内核中真正的处理区别只是在标记为SCHED_BATCH时进程在sched_yield主动让出cpu的行为发生是不去更新cfs的队列时间,这样就让这些进程在主动让出CPU的时候(执行sched_yield)不会纪录其vruntime的更新,从而可以继续优先被调度到。对于其他行为,并无不同。
SCHED_IDLE
如果一个进程被标记成了SCHED_IDLE策略,调度器将认为这个优先级是很低很低的,比nice值为19的优先级还要低。系统将只在CPU空闲的时候才会对这样的进程进行调度执行。若果存在多个这样的进程,它们之间的调度方式跟正常的CFS相同。
SCHED_DEADLINE
最新的Linux内核还实现了一个最新的调度方式叫做SCHED_DEADLINE。跟IO调度类似,这个算法也是要实现一个可以在最终期限到达前让进程可以调度执行的方法,保证进程不会饿死。目前大多数系统上的chrt还没给配置接口,暂且不做深入分析。
另外要注意的是,SCHED_BATCH和SCHED_IDLE一样,只能对静态优先级(即nice值)为0的进程设置。操作命令如下:
[zorro@zorrozou-pc0 ~]$ chrt -i 0 bash
[zorro@zorrozou-pc0 ~]$ chrt -p $$
pid 5478's current scheduling policy: SCHED_IDLE
pid 5478's current scheduling priority: 0
[zorro@zorrozou-pc0 ~]$ chrt -b 0 bash
[zorro@zorrozou-pc0 ~]$ chrt -p $$
pid 5502's current scheduling policy: SCHED_BATCH
pid 5502's current scheduling priority: 0多CPU的CFS调度
在上面的叙述中,我们可以认为系统中只有一个CPU,那么相关的调度队列只有一个。实际情况是系统是有多核甚至多个CPU的,CFS从一开始就考虑了这种情况,它对每个CPU核心都维护一个调度队列,这样每个CPU都对自己的队列进程调度即可。这也是CFS比O1调度算法更高效的根本原因:每个CPU一个队列,就可以避免对全局队列使用大内核锁,从而提高了并行效率。当然,这样最直接的影响就是CPU之间的负载可能不均,为了维持CPU之间的负载均衡,CFS要定期对所有CPU进行load balance操作,于是就有可能发生进程在不同CPU的调度队列上切换的行为。这种操作的过程也需要对相关的CPU队列进行锁操作,从而降低了多个运行队列带来的并行性。不过总的来说,CFS的并行队列方式还是要比O1的全局队列方式要高效。尤其是在CPU核心越来越多的情况下,全局锁的效率下降显著增加。
CFS对多个CPU进行负载均衡的行为是idle_balance()函数实现的,这个函数会在CPU空闲的时候由schedule()进行调用,让空闲的CPU从其他繁忙的CPU队列中取进程来执行。我们可以通过查看/proc/sched_debug的信息来查看所有CPU的调度队列状态信息以及系统中所有进程的调度信息。内容较多,我就不在这里一一列出了,有兴趣的同学可以自己根据相关参考资料(最好的资料就是内核源码)了解其中显示的相关内容分别是什么意思。
在CFS对不同CPU的调度队列做均衡的时候,可能会将某个进程切换到另一个CPU上执行。此时,CFS会在将这个进程出队的时候将vruntime减去当前队列的min_vruntime,其差值作为结果会在入队另一个队列的时候再加上所入队列的min_vruntime,以此来保持队列切换后CPU队列的相对公平。
9. Linux进程间通信
linux下的进程通信手段基本上是从Unix平台上的进程通信手段继承而来的。而对Unix发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。前者对Unix早期的进程间通信手段进行了系统的改进和扩充,形成了“system V IPC”,通信进程局限在单个计算机内;后者则跳过了该限制,形成了基于套接口(socket)的进程间通信机制。Linux则把两者继承了下来,如图示:
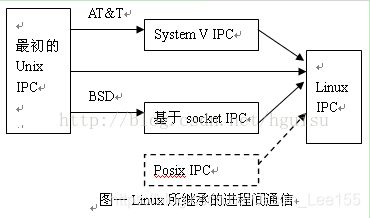
其中,
1、最初Unix IPC包括:管道、FIFO、信号;
2、System V IPC包括:System V消息队列、System V信号灯、System V共享内存区;
3、Posix IPC包括:Posix消息队列、Posix信号灯、Posix共享内存区。
有两点需要简单说明一下:
1)由于Unix版本的多样性,电子电气工程协会(IEEE)开发了一个独立的Unix标准,这个新的ANSI Unix标准被称为计算机环境的可移植性操作系统界面(PSOIX)。现有大部分Unix和流行版本都是遵循POSIX标准的,而Linux从一开始就遵循POSIX标准;
2)BSD并不是没有涉足单机内的进程间通信(socket本身就可以用于单机内的进程间通信)。事实上,很多Unix版本的单机IPC留有BSD的痕迹,如4.4BSD支持的匿名内存映射、4.3+BSD对可靠信号语义的实现等等。
图中给出了linux 所支持的各种IPC手段,在本文接下来的讨论中,为了避免概念上的混淆,在尽可能少提及Unix的各个版本的情况下,所有问题的讨论最终都会归结到Linux环境下的进程间通信上来。并且,对于Linux所支持通信手段的不同实现版本(如对于共享内存来说,有Posix共享内存区以及System V共享内存区两个实现版本),将主要介绍Posix API。
linux下进程间通信的几种主要手段简介:
管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
10. Linux进程管理工具:ps,top,dstat,htop
ps:用于显示当前进程的状态(非动态)
ps [options]:
常用组合之一:aux
-
a:所有与终端相关的进程
-
x:所有与终端无关的进程
-
u:以用户为中心组织进程状态信息显示

CPU%:cpu时间占用比率;MEM%:内存占用百分比;VSZ:virtual size虚拟内存集;RSS:Resident Size,常驻内存集;
STAT:
-
R:running 运行
-
S:interruptable sleeping 可中断睡眠
-
D:uninterruptable sleeping 不可中断睡眠
-
T:Stopped 停止
-
Z:zombie 僵死态
-
+:前台进程
-
l:多线程进程
-
N:低优先级进程
-
<:高优先级进程
-
s:session leader 进程领导者
常用组合之二:-ef
-
-e:显示所有进程
-
-f:显示完整格式的进程信息
常用组合之三:-eFH
-F:显示完整格式的进程信息;
-
C: cpu utilization cpu占用百分比
-
PSR:运行于哪颗CPU之上
-H:以层级结构显示进程的相关信息;
常用组合之四:-eo, axo
o field1, field2,…:自定义要显示的字段列表,以逗号分隔
常用的field:pid, ni, priority, psr, pcpu, stat, comm, tty, ppid, rtprio
-
pid:进程的pid号
-
ni:nice值
-
priority:优先级
-
psr:运行在那颗cpu
-
pcpu:cpu利用率
-
ppid:父进程的id号
-
rtprio:实时优先级
dstat:系统资源统计命令(动态)
dstat:系统资源统计命令(动态)
dstat [-afv] [options..] [delay [count]]

常用选项:
-
-c, –cpu:显示cpu相关信息;
-
-C #,#,…,total:显示第一个cpu,第二个cpu或者总共的
-
-d, –disk:显示磁盘的相关信息
-
-D sda,sdb,…,tobal:显示指定硬盘设备,总空间
-
-g:显示page相关的速率数据;
-
-m:Memory的相关统计数据
-
-n:Interface的相关统计数据;
-
-p:显示process的相关统计数据;
-
-r:显示io请求的相关的统计数据;
-
-s:显示swapped的相关统计数据;

–tcp:显示tcp套接字
–udp:显示udp连接
–raw:显示裸套接字
–socket:套接字
–ipc:进程间通信信息
–top-cpu:显示最占用CPU的进程;
–top-io:最占用io的进程;
–top-mem:最占用内存的进程;
top:列出inux进程
top为动态显示进程
top命令个参数具体含义:
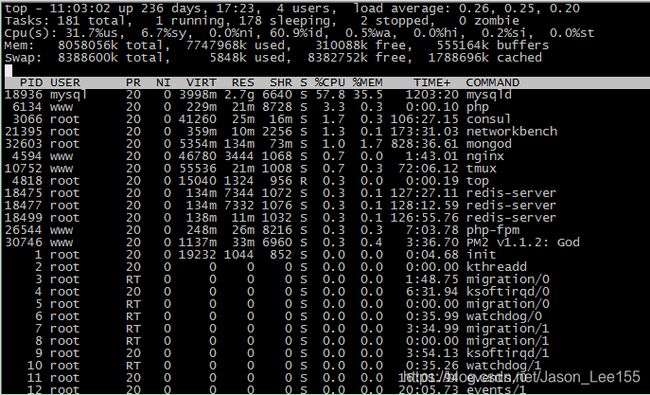
top - 11:03:29 up 236 days, 17:23, 4 users, load average: 0.25, 0.25, 0.20
-
11:03:29:当前时间
-
up:运行时长
-
users:登录当前系统上的用户数
-
load average:0.25, 0.25, 0.20:平均负载(1分钟、5分钟、15分钟的负载情况)
Tasks: 179 total, 1 running, 176 sleeping, 2 stopped, 0 zombie
-
Tasks:任务
-
total:一共运行多少进程
-
running:几个处于运行
-
sleeping:多少个睡眠
-
stopped:多少个停止
-
zombie:多少个僵死
Cpu(s): 4.2%us, 2.0%sy, 0.0%ni, 93.5%id, 0.2%wa, 0.2%hi, 0.0%si, 0.0%st
-
Cpu:cpu占用百分比
-
us:用户空间占用的百分比
-
sy:内核空间占用时间的百分比
-
ni:对nice调整占用的内存百分比
-
id:空闲百分比
-
wa(wait):等待IO完成所消耗的百分比
-
hi:处理硬件中断所占用的百分比
-
si:处理软件中断所占用的百分比
-
st:被偷走的百分比(虚拟化程序)
Mem: 8058056k total, 7731476k used, 326580k free, 555164k buffers
-
Mem:内存空间占用,以KB为单位:
-
total:总内存空间
-
free:剩余内存空间
-
used:已用内存空间
-
buff/cache:用于缓存和缓冲的内存空间
Swap: 8388600k total, 5848k used, 8382752k free, 1786780k cached
-
KiB Swap:swap空间占用,以KB为单位
-
total:总空间
-
free:剩余空间
-
0 used:已用空间
-
698100 avail Mem :有效swap大小
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
-
PID:用户pid
-
USER:用户名称
-
PR:优先级
-
NI:nice值
-
VIRT:virtual size虚拟内存集
-
RES:常驻内存集
-
SHR:共享内存空间
-
S:当前状态
-
%CPU:占据CPU百分比
-
%MEM:占据MEM百分比
-
TIME+:运行时长
-
COMMAND:命令
top内排序:
-
P:以占据CPU百分比排序
-
M:以占据内存百分比排序
-
T:累积占用CPU时间排序
常用:
(1) 一个屏幕下的进程:$ top –b
(2) 控制刷新频率(默认是3秒):$ top –d 3
(3) 线程信息:$ top –H
(4) 某个用户的进程: $ top –u root
(5) 最耗时的进程:$ top 然后使用hotkey ‘S’(计算进程的总时间) hotkey ‘T’(按时间排序)
htop:交互式进程查看器
htop:交互式进程查看器
htop [-dus]
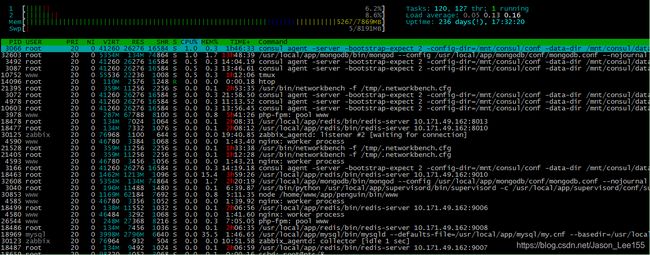
# htop 是一个非常强大的工具,下面从F1到F10可以看到具体的参数信息。
# F1 :帮助信息
选项:
-
-d #:指定延迟时间间隔
-
-u UserName:仅显示指定用户的进程
-
-s COLUME:以指定字段进行排序
常用子命令:
-
l:显示选定的进程打开的文件列表
-
s:跟踪选定的进程的系统调用
-
t:以层级关系显示各进程状态
-
a:将选定的进程绑定至某指定的CPU核心
# 此处可以添加指定项到显示屏幕上面,显示方式可以是[Bar] [Text] [Graph] [LED]
htop Bar|Text|Graph|LED