DLRover:蚂蚁开源大规模智能分布式训练系统

文|沙剑
蚂蚁集团高级技术专家
专注分布式深度学习领域
主要负责蚂蚁大规模分布式训练引擎的设计和开发
本文 4491 字 阅读 12 分钟
本文整体介绍了 DLRover 的项目动机与核心能力,未来我们会发布一系列文章,来从同步/异步弹性训练,优化策略服务,多种集群和训练框架对接,策略定制开发等多个角度来介绍 DLRover 的更多细节,敬请期待。
01
技术背景
2022 年 6 月,蚂蚁集团决定全面引入 ESG 框架,启动并确立了“数字普惠”、“绿色低碳”、“科技创新”、“开放生态”四位一体的可持续发展战略。针对“绿色低碳”,设立了 4 个子议题,包括绿色运营、科技助力产业碳中和、生态保护与修复绿色低碳生活。
在此背景下,绿色 AI 也成为蚂蚁 AI Infra 团队的一个重要工作方向。作为绿色 AI 的重要板块,工程提效项目致力于打造高性能离在线 AI 工程体系,通过提升算力效率和资源利用率,最终达到节省资源降低碳排放的目的。
当前,用户提交分布式训练作业的工具有 Yarn 或者 KubeFlow/Training-Operator。在提交作业时,用户需要在作业中指定作业资源,包括不同角色的节点数量和资源规格(CPU 核数、内存、GPU 等)。
在训练作业提交后,作业可能遇到如下问题:
集群资源不足以启动作业的所有节点,作业只能等待。
训练作业的节点可能会出错,比如被高优任务抢占、机器故障、IO 故障等,导致作业失败。
出现这些问题后,用户只能修改作业资源来重新提交作业。
针对这两个问题,蚂蚁集团早期基于 Kubernetes 开源了 ElasticDL 项目来支持 K8s 上 TF 2.x 分布式训练的弹性容错。在项目落地过程中我们又发现了如下问题:
用户配置的资源可能过少引起 OOM 和训练性能差。
用户为了保障作业成功率和速度,通常会配置超额资源导致利用率低。
越来越多的用户使用 PyTorch 或其他 TF 之外的框架来开发和训练模型。
越来越多的分布式集群开始支持 AI 作业,比如 Ray、Spark 集群,能否适配任意计算集群?
在线学习越来越被广泛采用的情况下,
如何运用一套系统同时解决兼容离在线训练?
前两个问题使得集群 CPU 利用率通常只有 20% 上下,同时算法开发人员需要投入很多人工运维成本,为了解决训练端资源提效的需求,支持在不同集群上针对在离线多种训练模式,给不同框架的分布式训练作业自动地寻找最优资源配置。
蚂蚁 AI Infra 团队基于 ElasticDL 弹性容错的思路,升级扩展并开源了 DLRover,其目标在于提升分布式模型训练的智能性,目前很多公司的训练作业都是跑在混部的集群中,运行环境复杂多变,正如其名,DLRover 作为分布式训练领域的 “路虎”,不管多么崎岖的地形,都可以轻松驾驭。
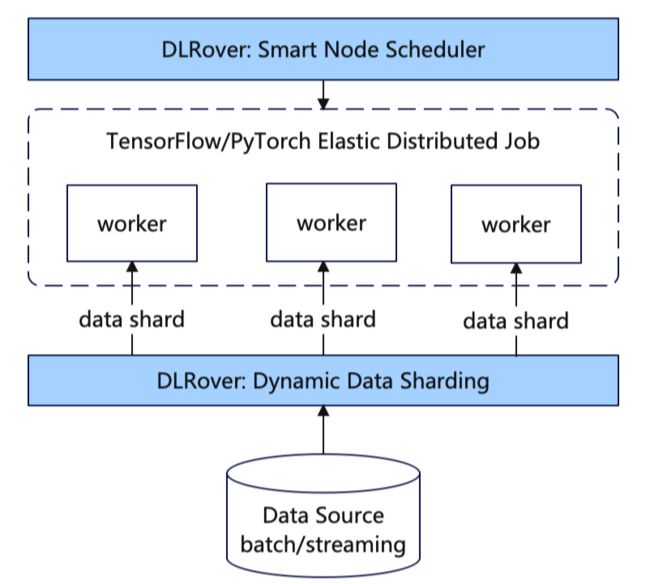
02
整体方案
DLRover 提出了 “ML for System” 的理念来提升分布式训练的智能性,那么这样的系统应该具备哪些能力呢?
我们认为主要体现在如下几个方面:
解耦:不和底层训练框架耦合在一起,只依赖接口抽象,遵循依赖倒置原则。(i.e. Elastic Runtime)
资源调度:具备上帝视角的资源调度管控能力。和建立在对作业精准画像的决策能力。
数据驱动:同时收集掌握集群资源数据,也掌握训练作业数据。以数据驱动智能。
作业交互:以对训练作业以及模型白盒化的理解,动态根据实际情况,对训练作业进行优化调整。超越简单机械的弹性容错!
智能:通过对集群以及作业信息的收集,结合算法模型+固定策略产出精准的作业优化策略。
我们希望设计并实现一个系统,让用户完全摆脱资源配置的束缚,专注于模型训练本身。在没有任何资源配置输入的情况下,DLRover 仍然可以为每个训练作业提供最佳资源配置。考虑到用户可能会以不同的方式运行他们的训练作业,DLRover 除了面向训练平台进行作业统一管理的 Cluster Mode,也提供 Single-Job Mode 方便独立的算法开发者也能享受到弹性容错等基本特性。
03
系统架构
DLRover 由四个主要组件组成:ElasticJob、Elastic Trainer、Brain 服务和 Cluster Monitor。
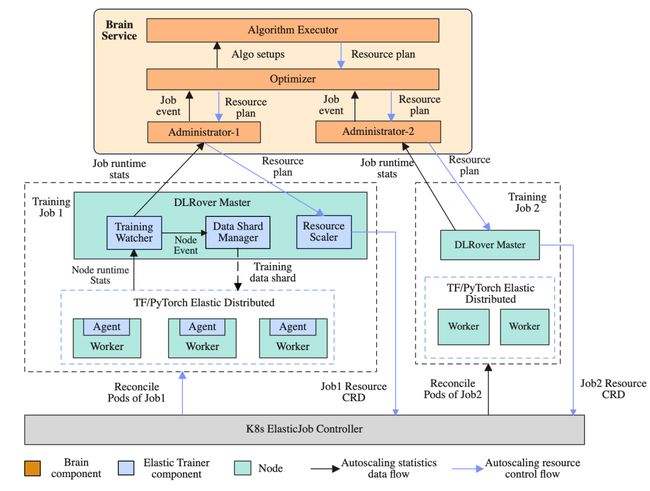
上图显示了 DLRover 如何在 K8s 集群上管理深度学习训练作业。DLRover 以 ElasticJob CRD 的形式将作业提交到集群。收到 CRD 后,ElasticJob Operator 会拉起一个 Master Pod 作为 Elastic Trainer。其从 Brain 服务中获取初始资源计划。Elastic Trainer 用它来创建 Scale CRD,并应用 Scale CRD 通知 ElasticJob Controller 启动所需的 Pod,每个 Pod 将在其上启动一个 Elastic Agent。
在训练过程中,Elastic Trainer 的 Training Master 将数据分片分发给 Worker。同时,Cluster Monitor 监控每个作业的运行状态(i.e.每个节点的 Workload)和集群状态(i.e. 资源水位)。这些数据将定期报告给 Brain,Brain 将数据持久化到数据库中。
然后 DLRover Brain 根据作业的运行状态,选择合适的算法生成新的资源计划,并通知 Elastic Trainer 开始资源调整。
总的来讲,DLRover 可以帮助分布式训练作业自动化运行在集群中,可以看作分布式作业的自动驾驶,模型开发者只需要关注模型的算法设计,DLRover 目前开源版则可以为用户提供如下能力:
自动资源推导:帮助用户自动初始化训练资源,提升资源利用率与作业稳定性。
动态训练数据分片:针对不同 Worker 性能不通造成的木桶效应,根据实际消费速度分配训练数据,可配合 Failover 记录消费位点,数据不丢失。
单点容错:提供单点容错的能力,不需要完整重启作业。
资源弹性:支持运行时 Pod 级和 CPU/Memory 级的资源弹性扩缩容,动态全局优化决策。
04
DLRover 能带来什么
1.作业零资源参数配置
用户提交分布式作业时无需提供任何资源信息,DLRover 会自动对作业进行画像,推导出最优的资源配置,同时运行时可以根据实际情况(集群资源、样本流量、当前利用率、...)自动对资源进行调整。下面展示了两种提交脚本的配置对比:

2. 单点容错提升作业稳定性与恢复效率
DLRover 支持单点恢复 Parameter Server 和 Worker 角色的失败退出而不需要整体作业重启,对于非用户代码和数据类型的错误可以实现用户无感的重启。例如集群中,很常见的一类错误是由于用户配置了不足的内存,导致训练 OOM。在 DLRover 的帮助下,我们可以自动拉起一个优化配置的节点来恢复失败的 Node。在真实环境下,DLRover 管理的训练作业,相比基线的 Kubeflow TF-Operator 作业,训练成功率从 84% 提升到了 95% 以上。
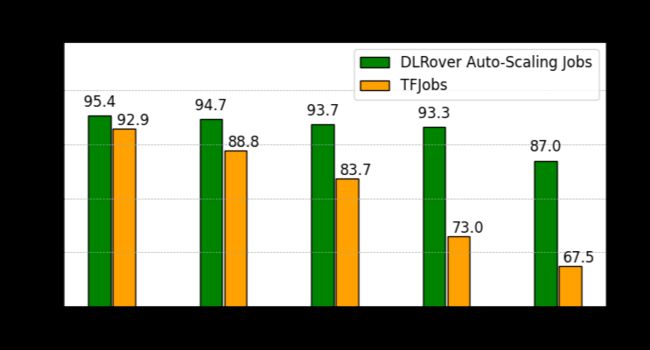
3. 自动扩缩容提升作业训练性能
DLRover 针对 Parameter Server 和 Worker 级别都支持在训练运行时进行自动的调节训练资源以提升训练性能。通过监控作业节点的 Workload,DLRover 可以分析资源配置的瓶颈。常见的资源瓶颈有:节点抢占、Workload 不平衡、CPU 不足导致算力低下、节点数目不足。DLRover 可以通过动态的资源热更新来持续优化训练性能。

4. 自动扩缩容提升作业资源利用率
通常不同的模型训练作业,需要不同的资源配置。然而用户倾向于超额配置作业的资源以保障作业的成功率。这通常会导致大量的资源浪费。DLRover 的自动扩缩容能力,可以自动根据作业的真实需求配置资源,以最少的资源达到最优的训练性能,从而减少资源浪费。下图显示了自动资源对比手动资源的资源利用率曲线对比:

5. 动态数据分发解决慢节点问题
混部集群存在资源超卖和抢占的情况,部分节点消费数据慢,快节点需要等待慢节点,降低训练速度。DLRover 可以通过数据动态分发给慢节点少分发一些数据,减少等待。此外 DLRover 应该保证训练任务尽可能按照用户配置参数消费数据,避免重复消费/丢失数据,这会给训练带来不确定性,影响模型性能。
当扩容或者缩容时,需要有个全局协调者知道记录节点当前消费数据详情。当节点失败重启后,全局协调者需要知道节点已经消费和尚未消费的数据。如果这些逻辑让训练节点来做,训练节点和训练节点之间需要交互,增加训练节点逻辑的复杂性。DLRover Master 充当了这个全局协调者的角色。
总而言之,在我们看来,通过动态数据可以简化训练节点逻辑的复杂性,训练节点只管从 DLRover Master 获取 Shard,然后读取数据,不需要处理其他的逻辑。
6. 统一离线与在线学习范式
上述动态数据分片特性,实际上帮助我们将 Data Source 和训练作业进行了解耦,在此基础上 DLRover 可以同时支持离线训练,也可以支持消费实时样本流的在线学习作业。(可以通过 Dlrover.trainer 直接对接样本流,也可以作为流计算引擎的训练 Sink 节点)
在蚂蚁的实践中,DLRover 可以作为一个理想的组件,来帮助我们构建出一个端到端的在线学习系统。DLRover 可以提供数据源消费位点记录与恢复,在线学习长跑作业稳定性与性能保障,资源利用率保障等一系列实际问题。我们的开源仓库中也提供了简单的范例,后续我们也会开放更多周边组件。
7. 支持异步和同步训练模式
训练集群中每天都运行着不同业务域性质各异的训练作业:推荐系统的大规模稀疏模型通常运行在 PS/Worker 架构的训练模式下进行异步参数更新,资源也多以 CPU 计算为主。CV/NLP 领域的稠密模型则多以数据并行的方式在 GPU 服务器上进行同步训练,这时只有 Worker 一种角色。
DLRover 在设计上,可以同时支持同步和异步更新模式,做到针对各种训练范式的统一。
8. 同训 DL 练框架解耦
DLRover 支持用户使用任何自己的训练框架,底层训练代码通过提供约定的 API 接口以实现自动弹性扩缩等需要同底层分布式代码深度交互。集群中部署完成后,终端算法同学基本可以无感接入。
05
总结 & 未来计划
DLRover 目前已经在蚂蚁大规模落地,集群资源利用率相对于基线稳定获得了 15% 以上的提升。同时也有效解决了由于资源配置不合理造成的训练吞吐不及预期的问题。我们希望通过 DLRover 的开源可以帮助更多同行一起推行低碳、绿色、AI 的理念。同时也切实降低模型开发中的运维成本,释放更多的生产力去解决业务的问题。
当前 DLRover 的调优算法,以及资源,作业画像策略主要针对蚂蚁内部技术栈优化。考虑到不同机构实际技术栈的多样性,在设计上,DLRover 在 API 层做了统一接口抽象,具体调优算法与作业画像策略则可灵活自定义。我们欢迎不同机构的开发者也能根据自身特点,同我们一起共建 DLRover 项目,将其发展壮大。
了解更多...
DLRover Star 一下✨:
https://github.com/intelligent-machine-learning
本周推荐阅读

Go 原生插件使用问题全解析

MOSN 构建 Subset 优化思路分享

MOSN 文档使用指南

MOSN 1.0 发布,开启新架构演进
