跨数据中心高可用架构设计
前言
随着常年的码代码,做设计,笔者做过基础编码,云计算平台,架构师,见过不少应用设计,系统设计,中间件,了解现有的技术体系发展模式,集中式->分布式;cap与base理论,基本上绝大部分时候可用性都是设计的必要目标,那么可用性在分布式的情况下是如何实现的呢,答案就是副本,即多部署几个资源,理论上部署越多,可用性越高,但是状态这个并不是所有情况都是无状态的,所以取舍在所难免。
常见的设计
常用的各种技术都会有副本的概念,无状态的副本,比如多核CPU,每个核心都是独立运行,都可以执行时间片线程,但是缓存一致性问题依然存在(MESI协议)。同理在分布式环境中,如果无状态服务,那么部署资源越多,可用性越高,因为不用考虑一致性,根据CAP理论,AP可以做到。但是实际情况经常需要一致性,比如数据库事务、会话等。
在现实情况,云计算就有区域、可用区的概念,实际上就是多数据中心,那么高可用架构就是有状态的。常见设计有主备、副本集、分片集群、连接集群。
主备+仲裁
主备设计在很多场景使用,典型的是MySQL MHA,Redis哨兵。以MySQL为例,如果需要自动failover,那么需要MHA等仲裁节点支持

实际上Redis的哨兵模式也是如此,把主和备分别放在不同的数据中心,当然延迟越小越好,这就涉及跨数据中心的延迟设计,比如AWS,直接用专线(钞能力),也可以让数据中心足够近或者传输数据足够少等方式优化。
此处MHA的server就是仲裁节点,负责failover,主备自动切换,根据心跳探测,实际上mongodb的副本也可以使用1+2模式,原理相同。
同理,因为主备复制的原因,备节点不能提供写入,且需要从主节点复制(全同步、半同步、异步),所以备节点不能过多,存在主节点写入过大无法扩容的问题。
副本集(延展集群)
副本集一般不使用仲裁方式,实际上也是这个思路,但是需要奇数个节点相互仲裁即可,实际上偶数也可以,但是会出现脑裂或者很难仲裁的现象。这种思路都是基于paxos算法,但是Paxos算法太复杂,所以精简一些出现了zab与raft算法。zookeeper基于zab自主选举算法,MongoDB副本集基于raft算法,腾讯仿造mongodb使用MySQL实现tdsql等。

节点之间两两相连,相互发起投票,投票方式按照一定会出现主的节点设计(奇数个、id等),因为投票的设计,节点越多,选举越困难,所以并不是越多越好,有个平衡点,比如5或者7.
这个图是不是很熟悉,实际上Redis集群、rocketmq集群就是使用这种方式进行failover的,只不过他们跟传统的副本集不一样,使用了分片+raft算法。
那么在设计跨数据中心的HA的时候,就需要2地3中心,把一个节点部署在一个数据中心,可以保证一个数据中心宕机,服务依然可用。

分片集群
分片集群设计有两种方式,分片的片是副本集,分片的片是主备。
分片集群
如果分片的片是副本集,那么副本集就提供failover能力,常见的有mongodb分片集群,mongos路由+configserver(副本集)+ 分片,每一个分片又是一个raft副本集(replicaSet)。实际上K8S创建部署计划也是创建RS(replicaSet)。

比如2个分片的分片集群,因为每个分片都是副本集,那么每个分片的副本集节点可以跨数据中心,实现2地3中心。理论上分片可以无限扩增,但是随着扩增越多,路由的查询写入的压力越大,这种架构设计也就是mongodb或者ES(也是分片)能存储很大数据量的原因,比如60亿一张“表”。
分片+主备
常见的有Redis集群,rocketmq集群,ES集群等,以Redis为例:

Redis的分片也是数据的分片,但是Redis主备failover由Redis的主节点投票决定,在多数据中心设计中,如果是2个数据中心,那么这个就没办法处理了 ,所以Redis一般是3主3从,5主5从等。奇数的节点就会在2个数据中心出现,其中节点多的一方挂掉,整个集群不可用,需要2地3中心支持。
连接集群
连接集群顾名思义:把2个或者多个集群数据相互复制,达到数据一致性的问题。
多次连接
以rocketmq为例,使用中间复制平台,将2个数据中心的rocketmq集群相互复制

此处仅画了一半,右边也会复制到左边

通过sdk路由分发,实现双活集群,数据完全同步,如果其中一个数据中心挂了,那么业务没有任何影响,缺点也很明显,带宽占用极高,如果数据中心延迟高或者带宽不够,那么这个方法就行不通。
设计应用,也需要考虑,例如MQ消费的幂等去重等,避免出现多次消费;发送可以根据数据区的标记发送一边即可,当然消费亦可以,根据实际情况处理,是真正意义的双活设计。如果出现某个数据中心故障,切换发送和消费的标记,那么实现无缝迁移业务,甚至根据监控数据实现自动切换。
因为是连接集群,那么存储的时候需要考虑写入数据的id(唯一性)冲突的问题,建议数据打标写入。
数据存储文件复制
上面的设计可以进一步优化,比如使用中间件的特性,比如MySQL binlog,kafka的commit log index log等。通过中间件自身属性实现文件或者数据流的复制。

本质一样,实现区别而已。
分片大集群-数据允许丢失
如果对数据要求不高,允许丢失,比如缓存数据,可以使用分片大集群模式
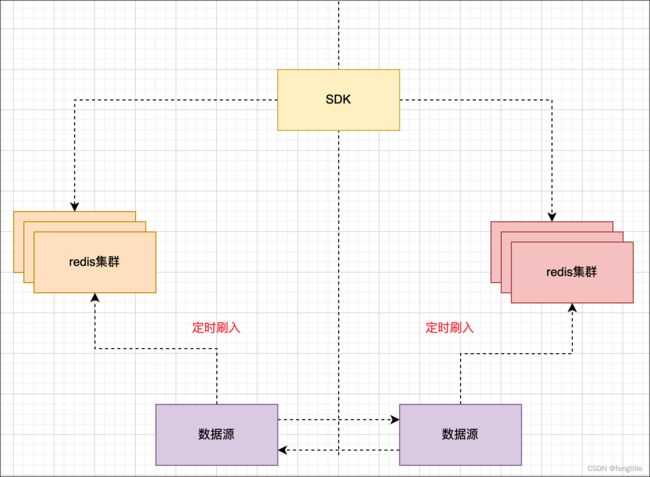
数据完全分片,数据源可以同步,并定时写入redis,如果redis集群因为一边数据中心挂了,那么会丢失数据,等待写入,但是对业务无影响,至于sdk路由怎么设计,这个就要根据具体情况了,路由规则罢了。如果是注册中心这样的有本地缓存,且定时检查心跳,那么自动注册,即可无需复制

数据没有复制,但是是分片集群,其中一个数据中心宕机,那么sdk会自动向另一个数据中心注册,且每个sdk有本地缓存,实现了无需切换的代价,且整个数据中心宕机,应用也挂了,亦不存在任何问题。
当然也可以不实现跨数据中心自动注册,丢掉一部分APP提供能力,等恢复后应用又可以自动恢复能力。
总结
笔者仅仅简单的介绍了跨数据中心的做法,方案等;实际上设计更加复杂,各种实际问题非常棘手,尤其是还有各种状态考虑,复制的稳定性,带宽等综合考虑就更复杂了。简单的sdk就会有多种设计,路由去重幂等等实现。具体还是需要根据实际场景设计。
开发逻辑向平台迁移
随着这些年docker等容器的兴起,开发逻辑向平台倾斜,以前开发是FATJar模式,变为agent,变为sidecar,变为serverless,实际上就是平台承担所有与业务无关的能力,专注业务,核心是定框子,在框子干活保证质量与效率。对于开发人员,很难接触系统实现逻辑了。