别找了,最全数据可视化配色指南在这
今天的这篇聚焦的是可视化中颜色如何传递数据信息。可别小瞧了这一技能,可视化是一图看懂,还是一团浆糊,可能就是颜色有没有用对。
Lisa 为了讲清楚这个主题,整整写了4篇文章,课代表在这里给大家带来一份精华版,一起来看看吧~
✦✧✧✧
什么是色阶?
在数据可视化的过程中,我们离不开和颜色打交道。例如为不同类别的信息赋予不同的颜色,或是在地图中制作有梯度的色彩渐变。
如果你用颜色进行数据可视化,那么你用到的色相调色板和颜色渐变就会形成标注数据的色阶。这是因为二者都与数据有着对应关系:例如每一个色相对应着一个特定的类别,而每一种颜色对应着一个特定的数值区间。
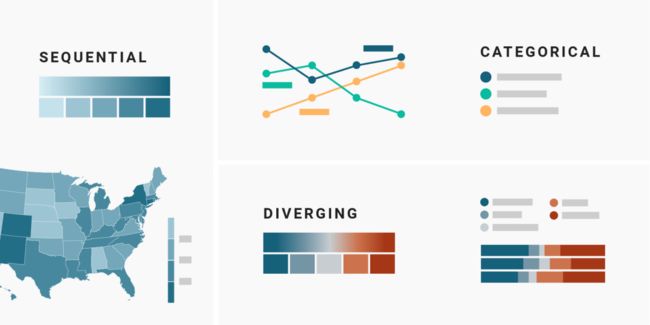
而色阶又可以分为类别色阶、连续色阶和发散色阶,它们分别对应不同数据类型:
1)类别色阶 ●●●●●
所谓色相,就是我们五岁时就知道的“不同的颜色”:红,黄,蓝......这些颜色可以很好地用来为那些没有天然优劣之分的东西进行分门别类,比如国家、种族、性别、行业——这也是为什么用于分类它们的类别色阶也被称为“无序色阶”。

⌂ FiveThirtyEight 图表图例中的色相

⌂ The Economist 图表图例中的色相
小贴士:记得要给你的色相赋予不同的明度,这对于色盲读者来说尤为重要。
2)单一方向的连续色阶 ●●●●●
连续色阶就是由亮到暗或由暗到亮的渐变。它们能很好地把从低到高的数字数字化,比如收入、温度或年龄。

⌂ New York Times 图表图例中的连续色阶

⌂ Datawrapper 图表图例中的连续色阶
小贴士:你可以在你的连续渐变中使用一种色调(例如从浅蓝到深蓝色),但在这里展示的几乎所有的例子都使用了多种色调(例如从浅黄到深蓝色)。使用两种甚至更多的色调可以增加渐变部分之间的颜色对比,使读者更容易区分它们。
3)双方向的发散色阶 ●●●●●
发散色阶(也称为双极色阶或双端色阶)的颜色刻度和连续的颜色刻度是一样的-但不是单一从低到高变化,而是有一个明亮的中间值,然后向刻度不同色调的两端逐渐变暗。发散色阶经常被用来刻画消极/积极的价值取向、选举结果或李克特量表(强烈同意、同意、中立、不同意、强烈不同意)。
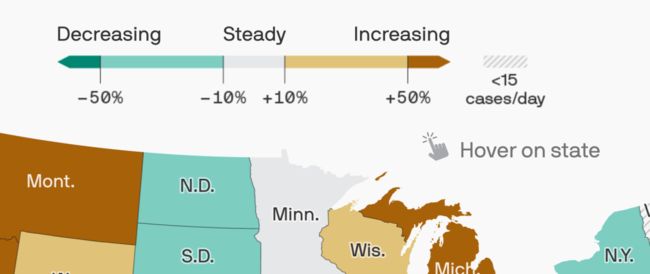
⌂ Axios 图表图例中的发散色阶

⌂ Opportunity Atlas 图表图例中的发散色阶
连续色阶和发散色阶都是定量色阶。
4)突出/弱化 ●●●●●
对于任何色阶,无论是类别色阶、连续色阶,还是发散色阶,你都可以重点强调那些你认为对你的读者或故事特别重要的数据类别:
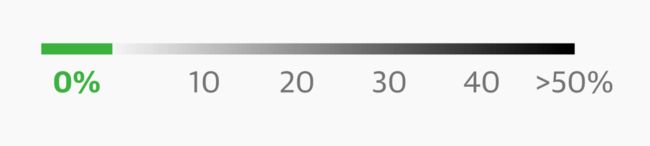
⌂ 来自《卫报》这张图强调了”0%“部分的未分类梯度。

⌂ 来自 The Pudding 的这张图弱化了”text“部分的颜色分类。

⌂ 来自彭博社的这张图,突出了中国。
除了强调,你也可以弱化一些类别,比如杂项、其他或者无数据。它们通常是灰色的:

⌂ FiveThirtyEight 的这张图就补充了”无数据“的已分类梯度。
我们接下来关注的问题是:什么时候应该使用哪种色阶?
✧✦✧✧
何时定性?何时定量?
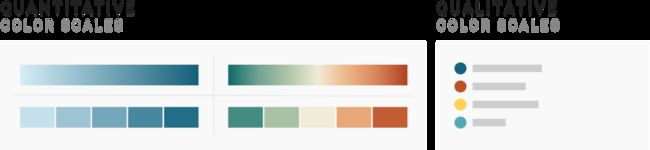
我们先来看看适用于90%情况的答案:
1)当你的数据没有内在排序时,使用类别色阶
如果你无法对颜色编码后的变量进行大小排序,使用类别色阶,反之如果可以排序,使用连续色阶或发散色阶。
例如变量是行业或国别,如伊朗、摩洛哥、巴基斯坦,应该使用不同的色相,因为摩洛哥本身并不比巴基斯坦好,反之亦然。
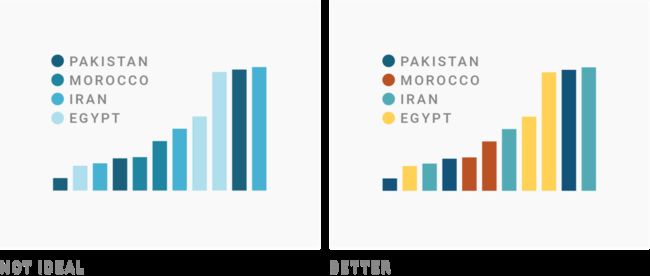
如果你想对失业率,如3.4%,1.4%,2%,这样的数据进行颜色编码,就要使用一个定量的色阶,连续色阶或者发散色阶。
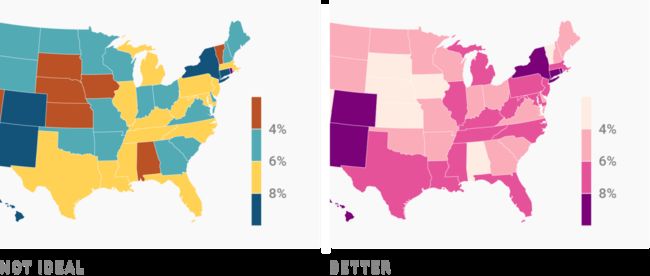
这并不仅仅是用不同方法区分文本与数字的问题,如在李克特量表和衣服尺码表中都有内在的排序,这些也是定量尺度。所以当你把它们可视化的时候也一定要考虑使用定量的色阶。

让我们再深入一点。
2)使用明暗强调内在的排序
在你的分类之下总会有一些数字,如各州的失业率或是子类的计数,你可以使用定性的色阶来展示这些潜在的值。
下面的树状图就是一个很好的示例:

你可以像左图那样,在树状图中通过不同的色相给你的类别上色(如定义国家或行业)。但如果像右图一样通过色块的尺寸大小对应明暗变化来上色,你的树状图的可读性会更好,不会看起来花里胡哨。
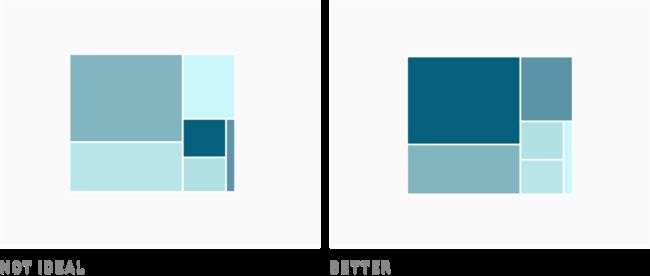
左边的树状图试图同时做太多的事情,即使有一个很好的颜色图标,阅读这样的图表也是一个挑战。
在大多数图表类型中,避免使用未被编码的值(例如位置或顺序)着色。如果你想给图表中潜在的值上色,请确保这些值在无颜色的情况下也是清晰可见的,这样这个图表才会易于理解。
我不想给你们留下用一个尚未编码的潜在变量着色总是一个糟糕的决定的印象。下面是《经济学人》的一个反例:
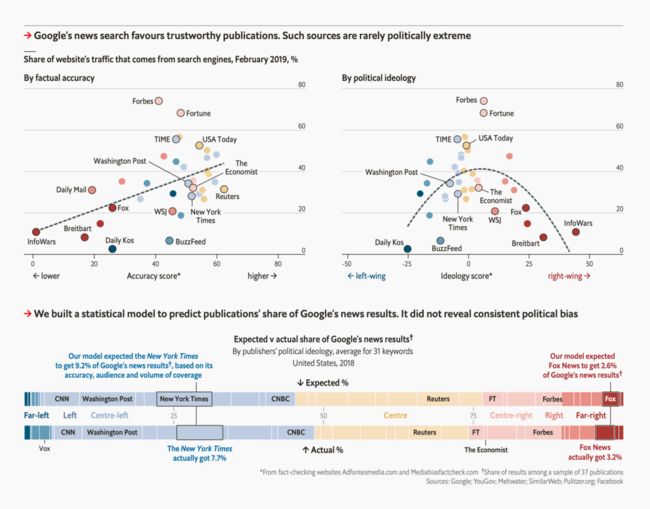
⌂ 图表来自2019年6月8日,《经济学人》的“谷歌算法”详细页面。
让我们看看左上角的散点图:这张散点图是用它的数值来着色,而不需要用位置、长度等来可视化。散点图是为数不多的用根据数值上色效果就能很好的图表。我认为这是因为散点图类似于符号图,读者习惯于看到根据数据上色的点。
尽管如此,我们还是花了几秒钟才能理解《经济学人》的这张图表。但右上角的散点图就容易理解多了,因为它是双重编码的:政治意识形态通过位置(左右)和明暗双重显示。
如果没有右上角和下方柱状图,要迅速理解左上角的散点图是很困难的。
到目前为止,我们已经学习了树形图、柱状图和散点图,下面还有折线图的例子:
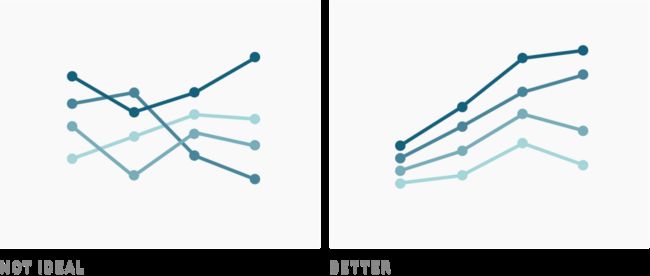
在这两个折线图中,明暗变化都用于在第一个日期对折线顺序进行双重编码。但是右边的图表中,更容易看到这一点,因为在整个图表中线条的顺序是相同的,左侧的图表会使我们感到困惑。
3)使用明暗变化区分子类别
还有更多的理由建议我们使用定量色阶而不是定性色阶来给定性数值上色。比如,区分子类别。以下是经济学家的图表展示:
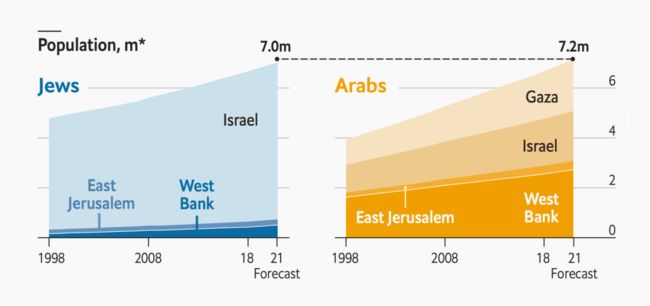
⌂ 图表来自《经济学人》,按宗教信仰分组的被占领土人口。
这张图里,一级分类有犹太人(蓝色)和阿拉伯人(黄色),子分类是地区,以不同明度的蓝色和黄色表示。
4)使用色调来区分强调和弱化的区域
颜色分类不必具有相同的重要性,如果你想突出显示一个类别,可以用一种色调(通常是灰色)的阴影为所有其他类别着色:

这张图表基本上把类别(已婚、单身、离婚、丧偶)分成了子类别,又通过不同色调明暗把它们分成更大的类别。正如我们刚才看到的,子类别内的阴影不会迷惑读者——所以这个图表也不会。
5)用阴影使分类颜色减少,便于色盲人群阅读
在数据可视化行业中有一条准则——从业者要让他们的可视化数据对于视力受损的读者也可以理解。这条准则的意思是颜色应该具有不同的亮度级别,以便在将它们转换为灰度时可以轻松区分。
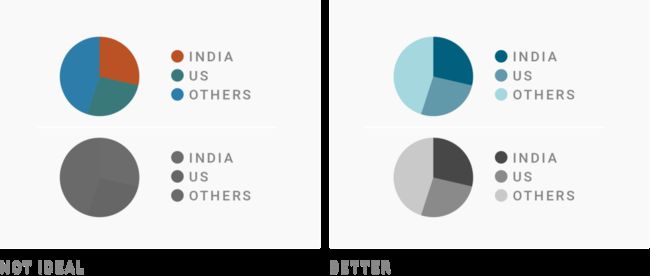
此外,仅使用一种色调,你的老板(或读者)就不会抱怨它看起来“太五颜六色”了。如果你正在做一个严肃的话题的可视化,那么这种单色调方式可能会排在你优先级列表的首位。
更容易理解和专业的表达,会说服你在分类时相比于选择不同色相更有可能选择同一色相,只是通过明暗色调来区别。英国的《金融时报》就是这样做:

但当尝试这么做的时候还有一些要点要牢记。
首先,要做好一些读者会为你的着色进行“合理化”解释的准备。即使这并不是你的本意,他们还是可能搜寻一些使用渐变的缘由。如“美国用一种更暗的色调展示是因为它有更高的值”或是“因为这对故事来说更重要。”因此,不要随意地着色。
其次,根据经验,编码条目时使用的渐变越多,阅读就越困难。辨认2-3个相同颜色的明暗渐变还是较为可行的。但如果是4、5、6个不同的渐变读者就会放弃,尤其是如果它们是无序的、没有被直接标记、或只使用一个色相(浅蓝到深蓝)而不是多个色相(浅黄到深蓝)的情况下,(读者会更容易放弃)。
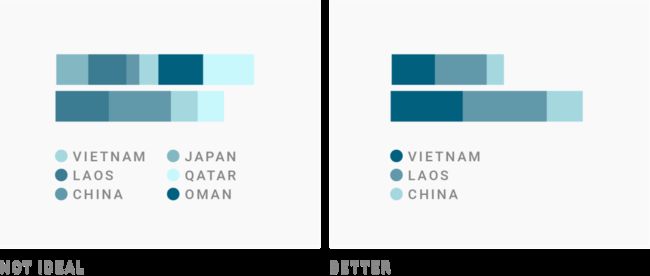
第三,如果你确实想使用渐变,如果在引入第二种颜色没有意义的情况下,请保持一种颜色的渐变。
有一个示例。为了避免使用一个颜色的太多渐变,《金融时报》有时会展示多个颜色的渐变。

这样的效果并不好。“非洲/中东”和“其他”是不是属于蓝色区域(欧洲、亚太、美国)之外的另一个类别?这份图表的作者或许并没有想让读者这样理解这份图表,但读者的确会有这样的猜测。
✧✧✦✧
何时一个色系?何时两个色系?
如果你决定应使用定量色阶而不是分类色阶的话,还有两个问题要讨论。第一个问题,你应该使用顺序色阶还是发散色阶?
1)如果有一个有意义的中间节点,就使用两端发散的明暗色阶

如果中间值有意义,请使用多种颜色。那可能是:
零,例如正负经济增长
50%,例如两个选择之间的投票
平均年龄或中位数,例如,年龄中位数以下
商定的阈值,例如低于或高于贫困线的收入水平
目标,例如收入高于和低于季度目标
这听起来很容易,但是,很多时候中间值是什么并不清楚,或者根本没有中间值。举个例子:

⌂ 日常活动中歌曲的动机品质,图表来自 PepMusic。
这个项目的开发者决定不用配色对这些活动进行编码,而是用耗尽的程度来分类,并采用定量色阶:

然后,他们决定其他们的色阶是发散的,这意味着色阶有一个中间点:“正常/平均”程度的疲惫类型(办公室、早餐、晚餐)。他们也可以不设中间值——睡眠是零疲劳,跑步是非常疲劳,这样的话他们的变化应该是从亮到暗。

注意,使用发散色阶主要有两个优点:第一,强调极端情况;第二,使读者看到更多的数据差异。
2)使用发散色阶可以强调极端值
如果你的故事强调一个最大值,就选择连续色阶;如果你的故事同时关注最低和最高值,就选择发散色阶。
设想你写了一篇关于互联网的主要构成是欧洲、美国、日本、澳大利亚和其他西方国家,并且这些国家和地区从中受益颇多的故事。为了说明你的观点,下面这幅用连续色阶制作的地图很适合作为插图。它强调了数值最高的国家:

但如果你的故事是关于在非洲和亚洲只有少数人使用互联网,你或许就想用一个发散色阶来展示你的数据:

3)使用发散的明暗,让读者看到数据中的更多差异
和连续色阶相比,使用发散的明暗变化会让你看到数据中更多的差异。这是因为你表现出一个梯度的数量范围是连续渐变的数量范围的一半。
你可以在上面的地图上看到, 浅蓝色渐变在顺序色阶地图中占0至100%,但在发散色阶地图图中仅占50%至100%。10%或20%点的差异在发散色阶地图中变得更加明显。
将俄罗斯和土耳其比较一下,按照连续色阶,尽管它们之间相差16%,但土耳其在地图上看起来只比俄罗斯略浅一点点。
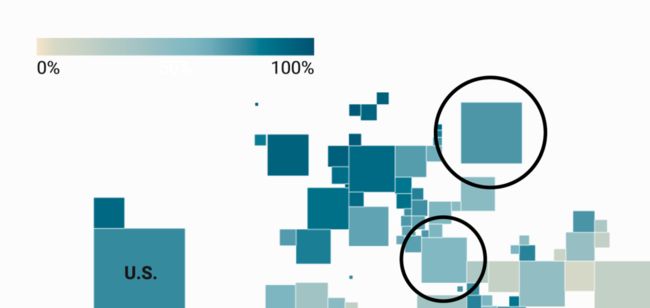
在发散色阶的地图中,差异会更加明显——俄罗斯仍然是类似的蓝色,但土耳其看上去颜色更浅,更接近米色,这表明它更接近中间点。

✧✧✦✧
何时分类?何时不分类?
要使用定量色阶,除了要注意是用顺序色阶还是发散色阶,你需要考虑是否要把数据分级(即归类,也称分类、阶梯化、量化、分等级、统计或使其离散),还是不分级(即让其保持未归类的,也称连续的)。
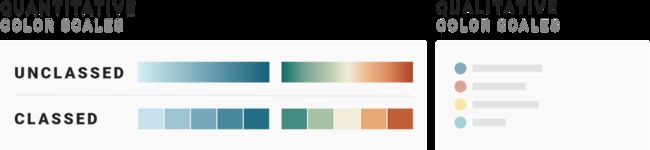
1)如果数据已分类,请使用分类的色阶
首先,如果你的数据是非连续的,请不要使用连续的色阶。这意味着,当可视化有天然排序的数据时,例如李克特量表、服装尺寸、官衔等,请使用分类的色阶。未分类的色阶会让人误认为两个相邻选项之间还有别的选项,但其实并没有。

2)如果想要表达统计范围,就使用分级色阶
使用分类的色阶会比未分类的色阶更容易表明观点。你可以将具有相同颜色的数值和区域进行分组,以便读者可以快速了解你想表达的观点。
制图师迈克尔·多布森(Michael Dobson)在1980年代大力倡导分类地图。他称它是“更简单、更高效的通信设备”。分类地图肯定会更简单,因为简化是分类地图的核心。但这是否也会更有效?这取决于你要传达的内容。

如果您想传达非常有限的信息,分类地图是一个不错的选择。制图师麦凯瑟琳(Mr. 库尔森(Coulson)在1991年指出,只要地图具有统计目标,例如显示:
“中等家庭收入排最后百分之十的县域”
“癌症死亡率高于平均水平两个标准差以上的区域”
如果某个县的失业率高于全国平均水平(如上图所示)
分类是实现这一目标的方法。“分类系统定义了自己,相比地图的整体模式,重点是哪些数据单元属于特定的预定义类别。” 如果你希望读者查看某些区域是否在统计范围内,请使用分类色阶。
但是一旦你想展示一种普遍现象 ,如“温度在南部比北部高”或“我们的收入是今年高于去年”,未分类地图可能是更好的选择。
这是同一张失业地图,其色阶有所不同:

相比上一张,这张地图让人们更难看清各个县属于哪个统计范围——即它们的失业率低于或高于全国失业率。
3)用未分类色阶呈现细微差别的视图
正如上面的两张地图所清楚显示的,与未分类的地图相比,分类的地图显示的细微差别要小。
未分类的地图会提供更真实、更细致的失业率视图。朱迪思·泰纳(Judith A. Tyner)在她的《地图设计原理》中写道:“未分类的等值线图可以最精确地表示数据模型。”
展示数据的复杂性本身就是一个崇高的目标。如果展示复杂性在你的优先级中名列前茅,请使用未分类的地图。
但是分类地图也可以或多或少地产生细微差别。你显示的类别越多,地图就变得越细致入微。仅显示两个类别的失业率地图是个极端的例子。这里我们提供了一份有六个档次的地图,3个高于全国平均水平的档次和3个低于全国平均水平的档次。
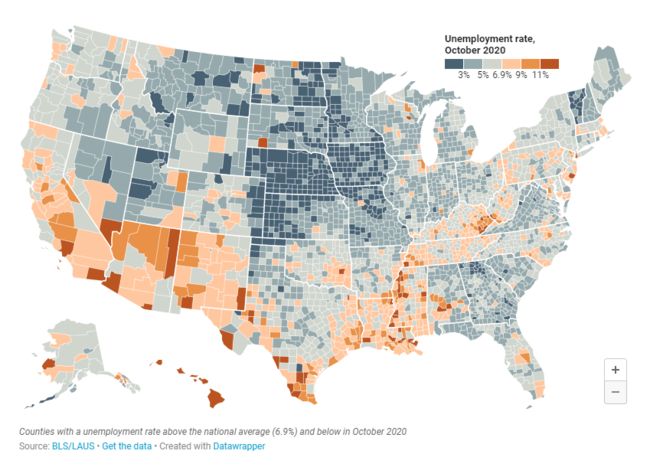
与只有两个分类的地图相比,此地图显示的差别更加细微–但与未分类地图相比还是略逊一筹。
4)如果你懒得向读者解释,请使用未分类色阶
未分类的图中能体现出的那些你观察到的细微差别可以让读者看到一些对仅仅对他们很重要的信息。
比如,未分类图能让读者更容易看到:
…边界区域。在分类地图中,通常将它们与数值稍高或稍低的区域放在一起。
…不同类别之间的过渡是平稳的还是突兀的。
…作为读者我感兴趣的地区的数值与相邻地区相比到底是更高还是更低。
举个例子,让我们放大南达科他州-下图正中央的地区。南达科他州的失业率比周围大多数州都更接近全国平均水平(所以它的蓝色更浅)。在未分档的地图上,我们可以看到,那些与其他州接壤的南达科他州县的失业率都要高于接壤的外州的区县。
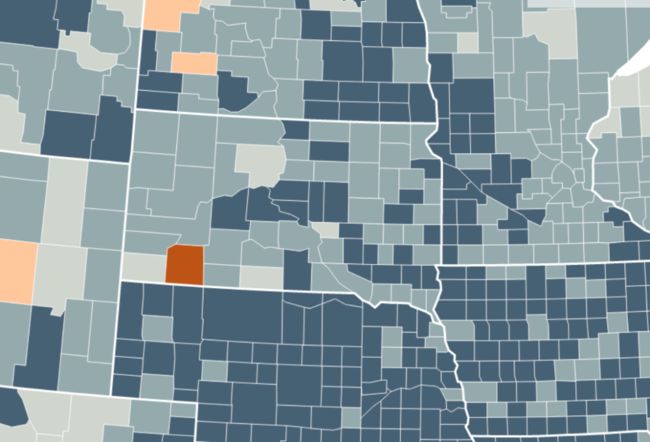

⌂ 上图:数据分六个等级的地图,下图:未分级的地图。
在分档地图中,这些细微的差异是不可见的。读者无法知道南达科他州的标为深蓝色的县的失业率是否比周围其他州标为深蓝色的县更高还是更低。
5)如果如果想让读者读取数值,请使用分类色阶
分档地图使读者虽然只能让读者读取一个范围(例如6%和7%之间),但是却可以帮助他们更好的领会这份数据。我们在几小节前已经提到过的麦格和库尔森(Mak and Coulson)在1991年的一项研究中得出结论:“分级地图在估计数值的测试中比未分级地图在统计结果上有着非常显著的优势。”
让我们再次看看南达科他州:
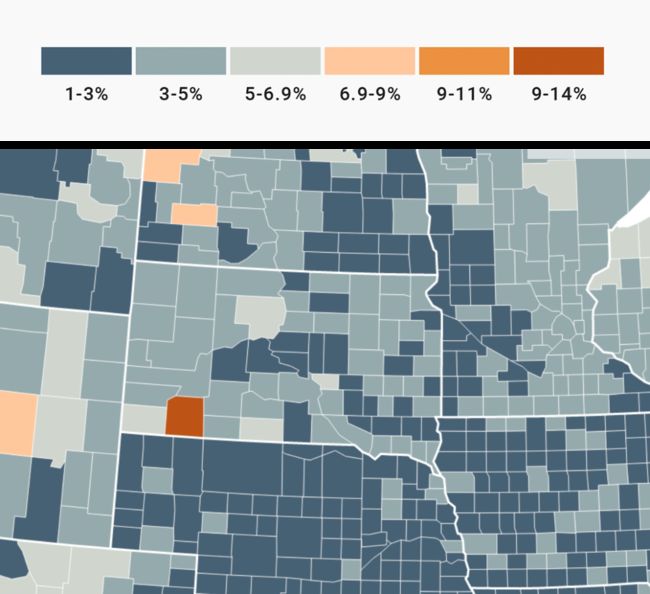
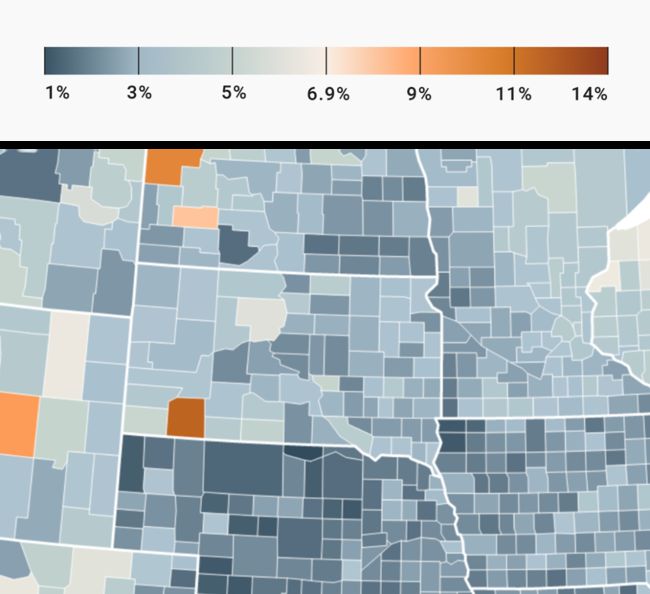
⌂ 上图:数据分六个等级的地图,下图:未分级的地图。
在上面的分档地图中,你可以确保正确阅读某一区域的值处在哪个范围-而在未分档的地图上,你只能对值域有“合理的猜测”。你的猜测可能在很小的区间里(“接近6%”,而不是“介于5%和6.9%之间”),但他们仍只是猜测。
当然,数值的可读性也取决于到底有多少类:你定义的类别越多,读者读出正确数值的可能性就越小。
因此,如果你希望读者读出特定的数值范围,请选择仅包含几个类的分类地图。这在你展示静态地图(例如在打印或 PDF报表中)这种人们没有办法通过工具或者鼠标悬停获得补充信息的时候尤为重要。
编译略有删改,原文链接:
https://blog.datawrapper.de/which-color-scale-to-use-in-data-vis/
https://blog.datawrapper.de/quantitative-vs-qualitative-color-scales/
https://blog.datawrapper.de/diverging-vs-sequential-color-scales/
https://blog.datawrapper.de/classed-vs-unclassed-color-scales/
作者 Lisa Charlotte Rost
编译 李凯睿
觉得还不错就给我一个小小的鼓励吧!