leetcode:399. 除法求值
题目来源
- leetcode:399. 除法求值
题目描述


class Solution {
public:
vector<double> calcEquation(vector<vector<string>>& equations, vector<double>& values, vector<vector<string>>& queries) {
}
};
题目解析
题意
给出方程式A/B=K,其中A和B均为代表字符串的变量,K是一个浮点数。要求根据已知方程式求解问题,并返回计算结果。如果结果不存在,则返回-1.0。
- equations和values:
- equations中每个一维序列表示一对数进行相除(前 / 后),得到的结果就是values中相应位置的值,以上作为已知条件。
- equations.size() == values.size(),即⽅程式的⻓度与⽅程式结果⻓度相等(程式与结果⼀⼀对应)
- queries:包含两个元素,目的是要我们求:第一个元素 / 第二个元素 = ?
即这道题给出了一些字母变量的倍数关系,问给出任意两个字母的倍数关系是多少。
示例一:
- 给定 a / b = 2.0, b / c = 3.0
- 问题: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ?
- 返回 [6.0, 0.5, -1.0, 1.0, -1.0 ]
我们来一个个的分析。现在告诉了你a和b、b和c的关系,现在要让你求出a和c的关系,你应该怎么求呢?
- 我们知道,计算关系是具有传递性的,对应到数据结构中是一张图
- 因此求两者之间关系不就是两个节点之间的连接嘛
- 如果是简单的对等关系,那么就是无权图
- 如果有指向性要求,那就是有向无权图。
- 对应到本题,我们用图来表示字符串之间的关系,比如
{a, b}对应的值为2.0,那么可以将a,b视作同一集合的元素,a指向b,权值为2.0,同时能推导出b到a也有一条路径,权值为0.5。即是一张有向加权图
- 因此求两者之间关系不就是两个节点之间的连接嘛
并查集
分析示例 1:
- a / b = 2.0,说明a = 2b,a和b在同一个集合中
- b / c = 3.0,说明b = 3c,b和c在同一个集合中
求 a c a \over c ca,可以 a = 2 b , b = 3 c a = 2b,b = 3c a=2b,b=3c依次代入,得到 a c a \over c ca = 2 b c 2b \over c c2b = 2 ∗ 3 c c 2 * 3c \over c c2∗3c = 6.0 6.0 6.0
![]()
我们计算了两个结果,不难知道:可以将题目给出的 equation中的两个变量所在的集合进行[合并],同在一个集合中的两个变量就可以通过某种方式计算出它们的比值。具体来说,可以把不同的变量的比值转换成为相同变量的比值,这样在做除法的时候就可以消去相同的变量,然后再计算转换成相同变量以后的系数的比值,就是题目要求的结果。统一了比较的标准,可以以O(1)的时间复杂度完成计算。
如果两个变量不在同一个集合中,返回-1.0。并且根据题目的意思,如果两个变量中至少有一个变量没有出现在所有 equations 出现的字符集合中,也返回 -1.0。
构造有向图
通过示例1的分析,我们知道了,题目给出的equations 和 values可以表示成一个图,equations 中出现的变量就是图的顶点,[分子]于「分母」的比值可以表示成一个有向关系(因为「分子」和「分母」是有序的,不可以对换),并且这个图是一个带权图,values 就是对应的有向边的权值。
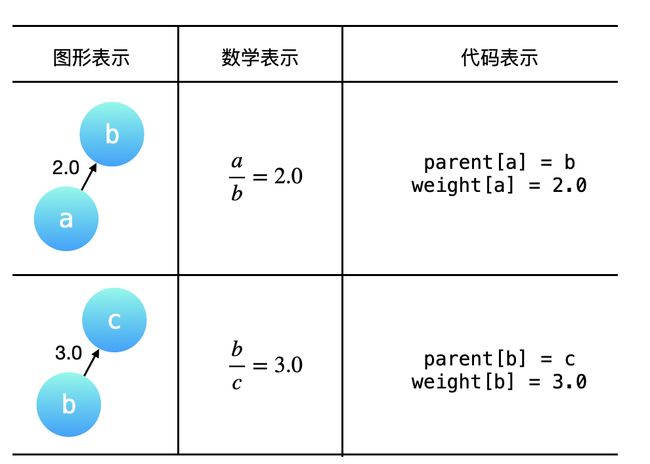
例 1 中给出的 equations 和 values 表示的「图形表示」、「数学表示」和「代码表示」如下表所示。其中 parent[a] = b 表示:结点 a 的(直接)父亲结点是 b,与之对应的有向边的权重,记为 weight[a] = 2.0,即 weight[a] 表示结点 a 到它的 直接父亲结点 的有向边的权重。
「统一变量」与「路径压缩」的关系
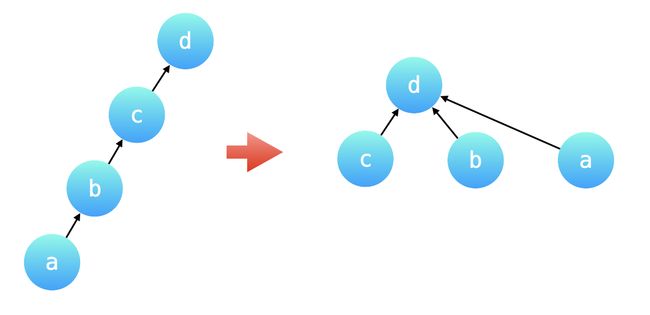
刚刚在分析例 1 的过程中,提到了:可以把一个一个 query 中的不同变量转换成 同一个变量,这样在计算 query 的时候就可以以 O(1)O(1) 的时间复杂度计算出结果,在「并查集」的一个优化技巧中,「路径压缩」就恰好符合了这样的应用场景。
为了避免并查集所表示的树形结构高度过高,影响查询性能。「路径压缩」就是针对树的高度的优化。「路径压缩」的效果是:在查询一个结点 a 的根结点同时,把结点 a 到根结点的沿途所有结点的父亲结点都指向根结点。如下图所示,除了根结点以外,所有的结点的父亲结点都指向了根结点。特别地,也可以认为根结点的父亲结点就是根结点自己。如下国所示:路径压缩前后,并查集所表示的两棵树形结构等价,路径压缩以后的树的高度为 2,查询性能最好。
如何在「查询」操作的「路径压缩」优化中维护权值变化
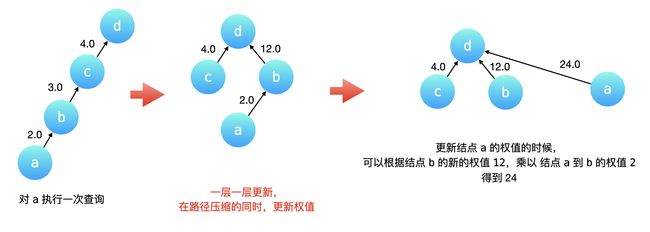
如下图所示,我们在结点 a 执行一次「查询」操作。路径压缩会先一层一层向上先找到根结点 d,然后依次把 c、b 、a 的父亲结点指向根结点 d。
- c 的父亲结点已经是根结点了,它的权值不用更改;
- b 的父亲结点要修改成根结点,它的权值就是从当前结点到根结点经过的所有有向边的权值的乘积,因此是 3.0乘以 4.0 也就是 12.0;
- a 的父亲结点要修改成根结点,它的权值就是依然是从当前结点到根结点经过的所有有向边的权值的乘积,但是我们 没有必要把这三条有向边的权值乘起来,这是因为 b 到 c,c 到 d 这两条有向边的权值的乘积,我们在把 b 指向 d 的时候已经计算出来了。因此,a 到根结点的权值就等于 b 到根结点 d 的新的权值乘以 a 到 b 的原来的有向边的权值。
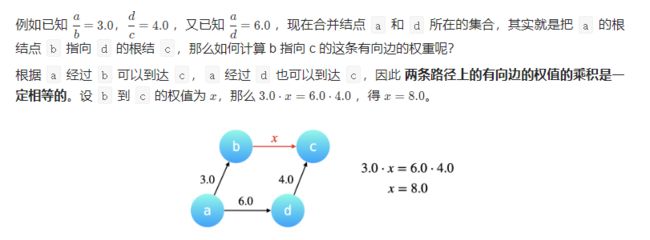
如何在「合并」操作中维护权值的变化
「合并」操作基于这样一个 很重要的前提:我们将要合并的两棵树的高度最多为 2,换句话说两棵树都必需是「路径压缩」以后的效果,两棵树的叶子结点到根结点最多只需要经过一条有向边。
class Solution {
class UnionFind{
private:
std::vector<int> parent; //存放父节点
std::vector<double > weight; //指向父节点的值
public:
UnionFind(int n){
for (int i = 0; i < n; ++i) {
parent.push_back(i);
weight.push_back(1.0); // 权重初始化为1
}
}
//路径压缩。返回根节点id
int find(int x){
// 递归寻找根节点,更新该点到根的权重为该点父节点到根的权重
while (x != parent[x]){
int origin = parent[x];
parent[x] = find(parent[x]);
weight[x] *= weight[origin];
}
return parent[x];
}
// 返回除法结果。如果两个值不存在则-1
double isConnected(int x, int y){
int rootX = find(x);
int rootY = find(y);
// 如果两个值有共同的根也就是可以计算,则算结果。否则不在同一个并查集,-1
if(rootX == rootY){
return weight[x] / weight[y];
}else{
return -1.0;
}
}
void merge(int x, int y, double value){
// 分别找到二者的根节点
int rootX = find(x), rootY = find(y);
if (rootX == rootY) {
return; // 二者已经指向同一个根节点
}
// 令分子指向分母的根节点,权重为分母到根的权重*分母除分子的值/分子到根的权重。一开始都是1
parent[rootX] = rootY;
weight[rootX] = weight[y] * value / weight[x];
}
};
public:
vector<double> calcEquation(vector<vector<string>>& equations, vector<double>& values, vector<vector<string>>& queries) {
// 初始化并查集
int eSize = equations.size();
UnionFind unionFind(2 * eSize);
// 第 1 步:预处理,将变量的值与 id 进行映射
std::map<std::string, int> hashMap;
int id = 0;
for (int i = 0; i < eSize; ++i) {
auto equat = equations[i];
string var1 = equat[0];
string var2 = equat[1];
if (!hashMap.count(var1)) {
hashMap[var1] = id;
++id;
}
if (!hashMap.count(var2)) {
hashMap[var2] = id;
++id;
}
// 把分子分母用有向边连起来
unionFind.merge(hashMap[var1], hashMap[var2], values[i]);
}
// 第 2 步:做查询
int qSize = queries.size();
std::vector<double > res(qSize, -1.0);
for (int i = 0; i < qSize; ++i) {
string var1 = queries[i][0];
string var2 = queries[i][1];
int id1, id2;
// 如果两个值有至少一个不在equations中,结果为-1,否则做除法
if(hashMap.count(var1) && hashMap.count(var2)){
id1 = hashMap[var1];
id2 = hashMap[var2];
res[i] = unionFind.isConnected(id1, id2);
}
}
return res;
}
};
DFS
参考
- C++ 图+DFS 击败100% 思路详细!
除法求值