Puppeteer 使用教程-基础篇(超详细、超全面)
目录
前言
一、 Puppeteer 简介
二、 Puppeteer中Browser、browserContent、Page的关系
三、 Puppeteer APIS
3.1、 Browser
3.2 Page
3.2.1 page.on(request/response)
3.2.2 page.$()
3.2.3 page.$$()
3.2.4 page.$eval()
3.2.5 page.addScriptTag()
3.2.6 page.addStyleTag(options)
3.2.7 page.click
3.2.9 page.evaluate(pageFunction[, ...args])
3.2.10 page.exposeFunction(name, puppeteerFunction)
3.2.11 page.focus()、page.hover(selector) 、page.mouse()
3.2.12 page.pdf()
3.2.14 page.setRequestInterception(value[Boolean])
3.2.15 重点讲述一下请求: Request、Response
3.2.16 page.type(selector, text[, options])
3.2.17 page.waitFor(selectorOrFunctionOrTimeout[, options[, ...args]])
3.2.18 page.waitForRequest
四、总结
前言
Puppeteer是目前比较友好的实现爬虫、自动化测试、页面捕获等的Node库,但是网上相关的博客有些少,没有一篇文章能将 puppeteer 的相关内容、API、示例讲的很清晰,故而借机写一篇文章,将自己所知分享一下,有误海涵。
Puppeteer 中文官网
Puppeteer 英文官网
Gitee地址
一、 Puppeteer 简介
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。在创建 browser时,可通过传入配置项实现无头模式的控制,如下:
const puppeteer = require('puppeteer');
const browser = puppeteer.launch({ headless: false })
// 为false表示不开启无头模式,则运行程序时,会有puppeteer的内核浏览器开启运行,模拟页面操作
// 当关闭无头模式后,可能会导致电脑闪屏,也是偶发的,反正我的电脑是会这样二、 Puppeteer中Browser、browserContent、Page的关系
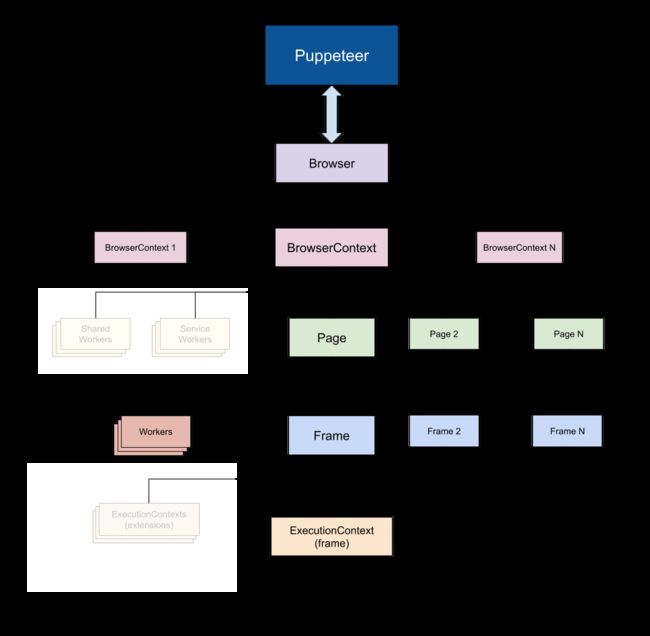
上图是官网展示的Puppeteer的浏览器结构,Puppeteer创建出来的浏览器,可以通过 DevTools 协议控制。
// 创建 browser
const browser =puppeteer.launch()
// 创建 browserContent
browser.newPage()
// 创建 Page
page.goto("URL")- Puppeteer 使用 Devtools协议与浏览器进行通信;
- Browser 实例可以拥有浏览器上下文;
- BrowserContent 实例定义了一个浏览器会话并可拥有多个页面;
- Page 就是我们所理解的标签页。
三、 Puppeteer APIS
其他的一些东西官网都讲述的很明白了,我们直接开始学习Puppeteer提供的API吧。
3.1、 Browser
当 Puppeteer 连接到一个 Chromium 实例的时候会通过 puppeteer.launch 或 puppeteer.connect 创建一个 Browser 对象,可通过传入option实现对创建的浏览器进行控制,例如 headless 、defaultViewport 、timeout 等。
浏览器的断开与重连:
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
// 存储节点以便能重新连接到 Chromium
const browserWSEndpoint = browser.wsEndpoint();
// 从 Chromium 断开和 puppeteer 的连接
browser.disconnect();
// 使用节点来重新建立连接
const browser2 = await puppeteer.connect({browserWSEndpoint});
// 关闭 Chromium
await browser2.close();
});3.2 Page
Page 提供操作一个 tab 页或者 extension background page 的方法。一个 Browser 实例可以有多个 Page 实例。可通过创建的Browser 调用 newPage()来创建,如下:
const browser = await puppeteer.launch();
const page = await browser.newPage()page是puppeteer中重要的角色,为我们提供了可操作对象,包括获取dom内容、页面截图、保存PDF等多操作。Page可以触发Node 原生事件,通过 on once removeListener实现对事件的监听移除,可监听事件列表如下:
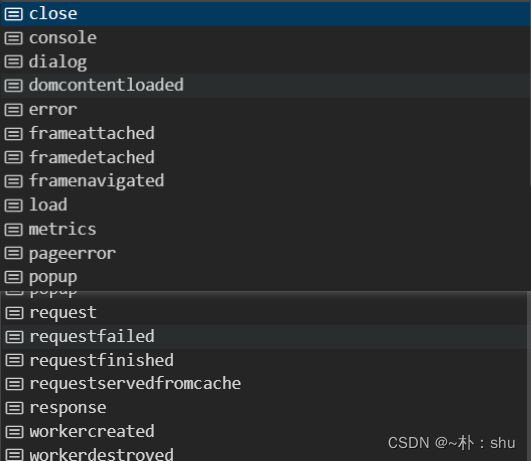
我们可以通过 page的事件,监听页面的行为,包括 request、response 监听页面请求,实现数据拦截等,还是比较有用的。
3.2.1 page.on(request/response)
var xhr = new XMLHttpRequest();
xhr.open("get", "https://dog.ceo/api/breeds/image/random");
xhr.send();
xhr.onload = () => {
console.log(xhr.response);
}上诉代码模拟了一次请求,我们如何在 Puppeteer中监听这次请求,并获取响应数据呢?
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// 说明,以下代码我是开启了项目 demo.html
await page.goto("http://127.0.0.1:5500/demo.html");
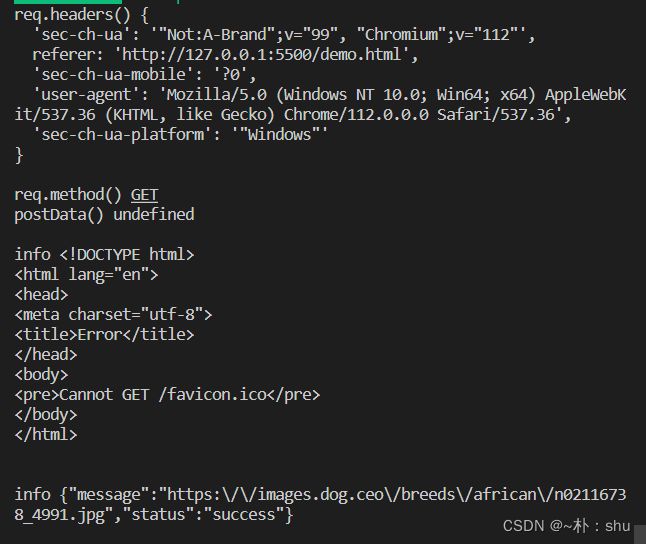
page.on("request", (req) => {
console.log("req.headers()", req.headers());
console.log("req.method()", req.method());
console.log("postData()", req.postData());
});
page.on("response", async (res) => {
console.log(await res.text());
});得到的结果如下:
我们页面请求的参数与响应: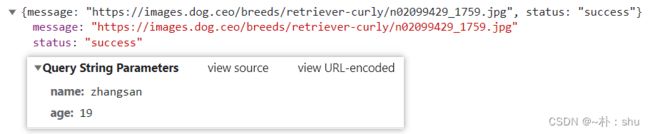
我们还可以再请求发送之前,修改请求的参数、对响应做拦截等,更详细的大家可以看Puppeteer官网样例说明:Puppeteer API | Puppeteer 中文文档 | Puppeteer 中文网
3.2.2 page.$()
此方法在页面内执行 document.querySelector。如果没有元素匹配指定选择器,返回值是 null,方法返回的是页内的 DOM 元素,可以得到元素进行页面操作。
const btn = await page.$("button");
await btn.click();3.2.3 page.$$()
方法执行的是 document.querySelectorAll,用法同上。
3.2.4 page.$eval()
page.$eval(selector, pageFunction[, ...args]),方法会把匹配到的元素作为第一个参数传给 pageFunction。第一个参数是选择器,第二个参数是回调函数,page.$('selector',callback).还可以通过第三个参数实现上下文参数传到 puppeteer中实现动态参数。这也是我们常用的方法,重点讲一下:
// page $eval 方法 page.$eval('selector',callback,[...args])
const data = await page.$eval("h1", (h1) => {
// 这里的环境是在 puppeteer 浏览器中,不是在 外部环境,因此 log 在打开的浏览器中看
// 返回的结果作为方法的结果
console.log("puppeteer 内核浏览器", h1);
return "主动返回的结果作为 方法返回值";
});
console.log("page.$eval 结果:", data);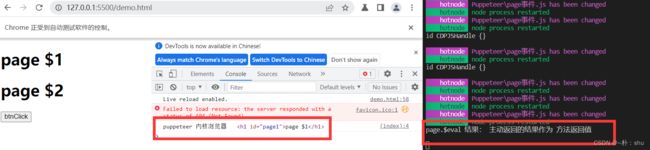
在page.$eval()方法中,就跟你在实际浏览器控制台中操作页面一模一样,因此也比较贴合我们实际的操作习惯,我更接受这种方式取操作页面、获取数据。
通过该方法,能实现参数的内外环境传递,比如你的代码里生成了一个变量,在页面中执行方法时需要用到,可以通过这个 args 传进去,如下:
const params = {
p1: "p1",
p2: 30,
p3: {
data: [1, 2, 3, 4],
},
};
// 一定注意, ...args 需要传,pageFunction 形参中也要写!!!
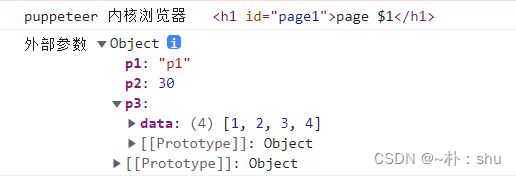
const data = await page.$eval(
"h1",
(h1, params) => {
// 这里的环境是在 puppeteer 浏览器中,不是在 外部环境,因此 log 在打开的浏览器中看
// 返回的结果作为方法的结果
console.log("puppeteer 内核浏览器", h1);
console.log("外部参数", params);
return "主动返回的结果作为 方法返回值";
},
params
);
方法函数是不可以直接通过参数传递的形式供内部浏览器使用,后面我们会介绍另一种形式实现。
const saveImg = (path) => {
console.log("有人调用 saveImg 方法了", path);
};
const data = await page.$eval(
"h1",
(h1, saveImg) => {
// 这里的环境是在 puppeteer 浏览器中,不是在 外部环境,因此 log 在打开的浏览器中看
// 返回的结果作为方法的结果
console.log("puppeteer 内核浏览器", h1);
console.log("外部参数", saveImg);
},
saveImg
); ![]()
但是可以通过将数据返回,通过外部 node 环境实现外部函数调用,但是下面介绍了另一种API后,还是推荐使用API实现,这种数据回传的形式,还是跟我们编程习惯不一致。
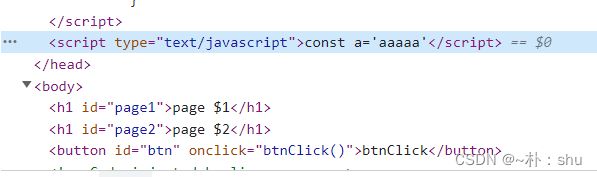
3.2.5 page.addScriptTag()
puppeteer 允许我们向页面插入script标签,或者 script 代码片段
// 注入 script
await page.addScriptTag({
content: "const a='aaaaa'",
});
插入js文件,则通过 url实现:
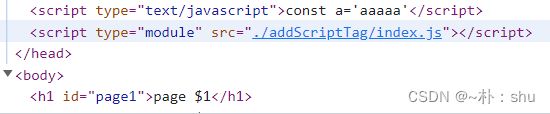
但是路径是相对于页面路径,实际上可能不可用。

因此,建议直接将代码放到代码块中插入。
await page.addScriptTag({
content:
"const saveImg = (path) => console.log('调用了 saveImg方法,path=', path); ",
});
但是这样会导致原页面script 混乱,如果仅是想要在内部调用方法,还是推荐使用后面讲述的方法实现。
3.2.6 page.addStyleTag(options)
该方法与上类似。
3.2.7 page.click
模拟一个元素点击。上面示例中,我们用了 page.$(),然后调用 click(),我们可以直接用page.clcik()完成。
3.2.8 page.cookies()
返回页面 cookies:
await page.goto("https://www.baidu.com");
const cookies = await page.cookies("https://www.baidu.com");
console.log(cookies);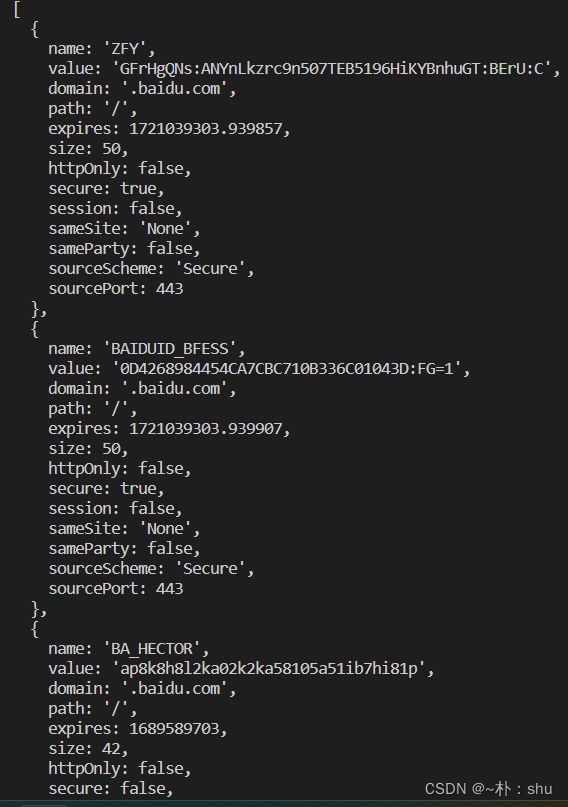
下面还讲述如何设置cookies,在需要登录的页面中,需要提前设置 cookies 后,才能发请求,获取数据,因此 cookies 的内容是非常重要的。
3.2.9 page.evaluate(pageFunction[, ...args])
要在页面实例上下文中执行的方法,用法跟 page.$eval()类似,只是没有了选择器,参数传递都一样的。这个方法让我们更加随意的在上下文中处理数据。
3.2.10 page.exposeFunction(name, puppeteerFunction)
到现在,我们终于可以实现在上下文中调用 node 中的方法了,name是挂在到 window上的方法明,puppeteerFunction 是调用方法名实际执行的函数,我们还是通过该方法,实现 saveImg 方法的调用。
const saveImg = (path) => {
console.log("有人调用 saveImg 方法了", path);
};
// 添加方法
await page.exposeFunction("saveImg", (path) => saveImg(path));
// 直接在上下文执行,不需要通过选择器,简单理解,上下文就是 puppeteer 内核浏览器的控制台
page.evaluate(() => {
console.log("puppeteer 内核浏览器");
saveImg("/img/test");
});
这样是最方便的,想象一下哎,我们爬取得到的图片视频资源,可能需要通过别的模块方法实现存储、数据处理,应该在内核浏览器直接调用方法就行了,这样也更符合我们的编程思路。
3.2.11 page.focus()、page.hover(selector) 、page.mouse()
这些事件都比较简单。
3.2.12 page.pdf()
直达官网 PDF
3.2.13 page.setCookie(...cookies)
该方法非常重要!!!常用于爬取有cookies的网址,需要提前将cookies获取并设置到页面上,方法如下:
await page.setCookie({
name: "BD_UPN",
value: "12314753",
});如何将实际页面的cookies设置到页面上呢?
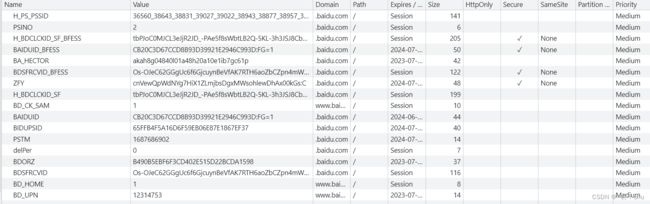
这是页面真实的 cookies,通过 document.cookies 获取string类型:
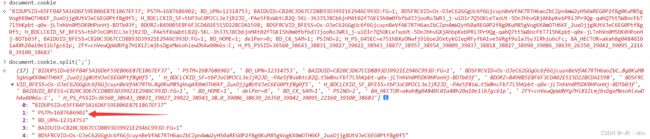
通过 split(';')拆分数组,而每一项又是 name=value的形式,对每一项都 split('='),通过await page.setCookie(cookieObject1, cookieObject2); 实现处理
const cookies ="BIDUPSID=;BDSFRCVID=Os-....省略....B64_BOT=1;channel=bai47c2-a2fb-4aae994ac343";
const arr = cookies.split(";");
arr.forEach(async (i) => {
const [name, value] = i.split("=");
let obj = { name, value };
await page.setCookie(obj);
});注意:name、value中一定不要有空格,不然会报 Invalid cookie fields,可以先执行 replaceAll(' ','')清空所有空格,在执行 split 操作。
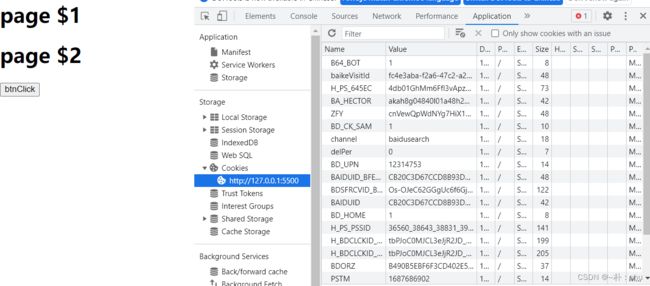
这样,百度的cookies就放到我们的网址里面了。有些网页的请求是需要携带cookies的,可以这样实现。
3.2.14 page.setRequestInterception(value[Boolean])
启用请求拦截器,会激活 request.abort, request.continue 和 request.respond 方法。这提供了修改页面发出的网络请求的功能。一旦启用请求拦截,每个请求都将停止,除非它继续,响应或中止.
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', interceptedRequest => {
if (interceptedRequest.url().endsWith('.png') || interceptedRequest.url().endsWith('.jpg'))
interceptedRequest.abort();
else
interceptedRequest.continue();
});
await page.goto('https://example.com');
await browser.close();
});想要处理请求拦截器,先熟悉 请求的响应参数,request.abort 会取消请求,request.continue则继续请求,request.respond则是结束请求并返回响应状态码:
request.respond({
status: 404,
contentType: 'text/plain',
body: 'Not Found!',
});请求的参数用 req.postData(),请求 url 用 req.url(),【该方法可以获取 params 参数】,请求方法用 req.method()
3.2.15 重点讲述一下请求: Request、Response
我们在获取爬取网页数据时,除了直接从页面上获取外,更多的是从接口中获取,因此掌握页面拦截请求、请求对象、响应对象的属性也是很重要的 。
Request:
request.abort([errorCode]):
想要中断请求,应该使用 page.setRequestInterception 来开启请求拦截,如果请求拦截没有开启会立即抛出异常。(node:17688) UnhandledPromiseRejectionWarning: Error: Request Interception is not enabled!
开启后,
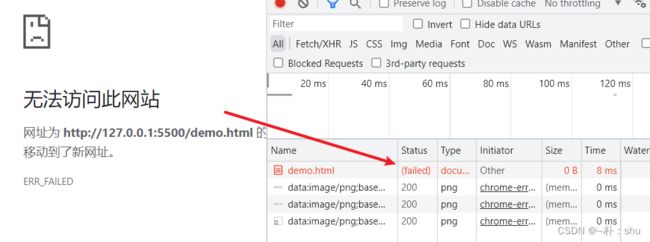
我们还可以指定某一个请求进行中断,不然首页都看不见了。
request.continue:
想要用可选的请求覆写选项继续请求,应该使用 page.setRequestInterception 来开启请求拦截,如果请求拦截没有开启会立即抛出异常。

我们可以重写该请求的URL、Headers、请求数据等。
request.headers(): 获取请求头
request.method():获取请求方法
request.postData():获取请求数据(get请求的url参数直接在 url()中截取,postData特指post参数)
request.url(): 请求的URL
Request:
response.buffer():Promise which resolves to a buffer with response body,解析响应中的buffer。
response.headers():响应头
response.json():将响应体转换为 json 格式,如果响应主体无法进行 JSON.parse 解析,则此方法将抛出错误。
response.remoteAddress():获取远程服务的ip端口
response.text():Promise which resolves to a text representation of response body,直接文本化响应体。
如上图,第一次请求是请求 页面,第二次请求是请求接口。
3.2.16 page.type(selector, text[, options])
是页面输入操作重要方法,实现字符输入操作。
page.type('#mytextarea', 'Hello'); // 立即输入
page.type('#mytextarea', 'World', {delay: 100}); // 输入变慢,像一个用户3.2.17 page.waitForRequest
上面也说了,我们的很多数据可以直接从接口请求中获取,那么必然会需要等待某一个请求,因此,page.waitForRequest(urlOrPredicate[, options]) 就是这个用途。
page.waitForResponse(urlOrPredicate[, options]) 也可以等待某一个请求的响应。
四、总结
以上只是简单讲述了一些常用API的例子,还有更多的的 worker、Frame apis 如果大家有需要,可以再出一篇文章讲述。对于页面爬取数据,请求、响应、DOM(选择器)是最常用,自动化测试,type字符输入、page.$()选取元素也是最常用的。基本上掌握上诉API,对于爬取数据没问题了,我还会出一篇爬取数据示例,将应用讲述到的API。