【文章导读】目前人脸识别技术已经遍地开花,火车站、机场、会议签到等等领域都有应用,人脸识别的过程中有个重要的环节叫做人脸检测,顾名思义就是在一张图片中找出所有的人脸的位置,早期的人脸检测是用人工提取特征的方式,训练分类器,比如opencv中自带的人脸检测器使用了haar特征,早期的这种算法自然是鲁棒性、抗干扰性太差,本文主要来介绍近几年的几种用卷积神经网络做的经典算法。
1、Compact Cascade CNN

效果图
论文链接:https://arxiv.org/abs/1508.01292
github链接:https://github.com/Bkmz21/FD-Evaluation
论文特点:识别人脸速度快!!!网络参数少,所以贼快。
这是一篇2015年的来自俄罗斯托木斯克理工大学的论文,针对快速人脸检测任务。

论文原名
该算法核心网络结构:
为了快,该网络结构参数少,分为三个stage, 依次有797, 1,819 和 2,923 个参数,使用的是TanH激活,因为网络太小ReLU不好使。而且为了速度,作者使用了近似函数来逼近TanH。
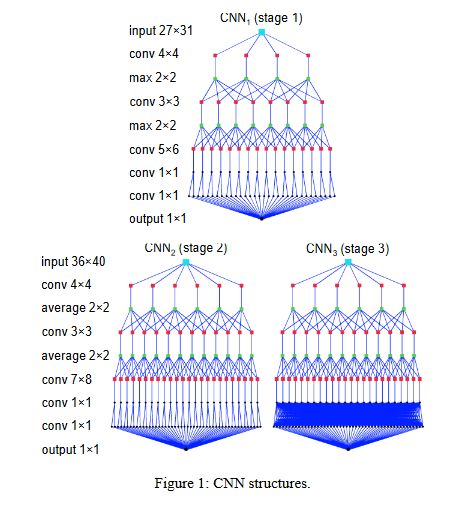
简单粗暴的网络结构
使用近似函数来逼近TanH:
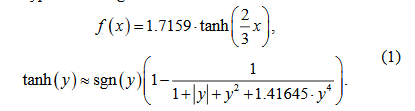
论文所用TanH激活函数公式
该算法流程图:
首先是输入一张灰度图片,构成图像金字塔。然后通过stage1(CNN1)后会产生候选单元。
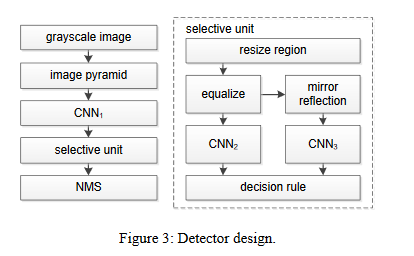
流程图
NMS(非极大值抑制)算法是从多个定位框中合并一些框,如图:

NMS
然后候选单元进入stage2和stage3(CNN2和CNN3),通过以下公式判断是否是人脸(CNN2和CNN3的输出结果进入decision rule)。

decision rule
实验结果(详细数据请参考原文):
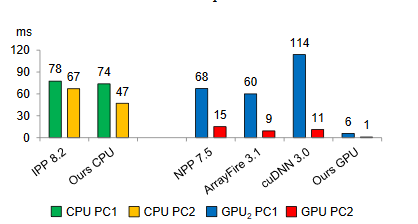
result one
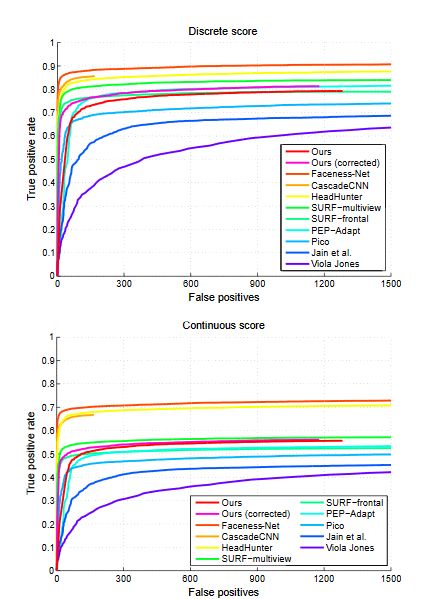
result two
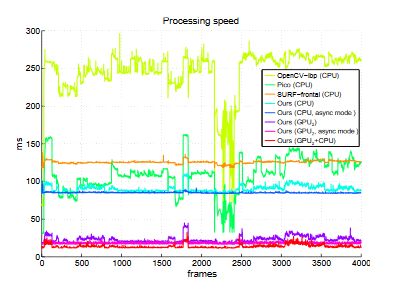
result three
总结:
这是一种轻量级的快速人脸检测算法,也就是说在计算资源较小的情况下也能实现,并且快。缺点当然就是没有特别准。
2、MTCNN(多任务级联卷积神经网络用于人脸检测与对准 )
代码链接:
https://github.com/kpzhang93/MTCNN_face_detection_alignment
这是2016年中国科学院深圳先进技术研究院的文章,同样用于人脸检测任务,跟上文所述Compact Cascade CNN类似,该算法网络也采用了三个级联的网络,接下来看看具体的流程。
MTCNN算法流程:
首先,给定图像,我们首先将其调整到不同的比例,以构建图像金字塔,这是三级网络框架的输入。
Stage 1:使用的P-Net是一个全卷积网络,通过浅层的CNN用来生成候选窗极其边框回归向量。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。

pipline
网络结构介绍:

整体网络结构
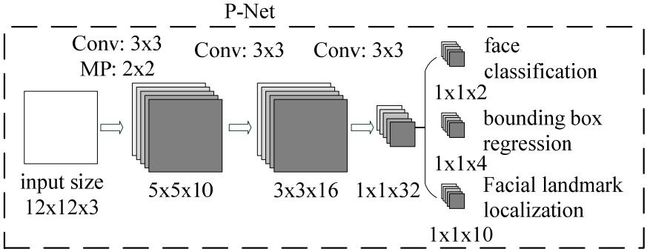
P-Net

R-Net
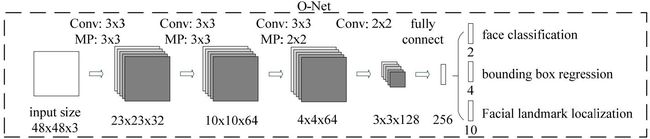
O-Net
pytorch实现网络结构代码(需要注意,略有不同的是,代码中的P-Net和R-Net没有输出网络结构中的Facial landmark localization):
importtorchimporttorch.nnasnnimporttorch.nn.functionalasFfromcollectionsimportOrderedDictimportnumpyasnpclassFlatten(nn.Module):def__init__(self):super(Flatten, self).__init__()defforward(self, x):"""
Arguments:
x: a float tensor with shape [batch_size, c, h, w].
Returns:
a float tensor with shape [batch_size, c*h*w].
"""# without this pretrained model isn't workingx = x.transpose(3,2).contiguous()returnx.view(x.size(0),-1)classPNet(nn.Module):def__init__(self):super(PNet, self).__init__()# suppose we have input with size HxW, then# after first layer: H - 2,# after pool: ceil((H - 2)/2),# after second conv: ceil((H - 2)/2) - 2,# after last conv: ceil((H - 2)/2) - 4,# and the same for Wself.features = nn.Sequential(OrderedDict([ ('conv1', nn.Conv2d(3,10,3,1)), ('prelu1', nn.PReLU(10)), ('pool1', nn.MaxPool2d(2,2, ceil_mode=True)), ('conv2', nn.Conv2d(10,16,3,1)), ('prelu2', nn.PReLU(16)), ('conv3', nn.Conv2d(16,32,3,1)), ('prelu3', nn.PReLU(32)) ])) self.conv4_1 = nn.Conv2d(32,2,1,1) self.conv4_2 = nn.Conv2d(32,4,1,1)#net = self()weights = np.load('src/weights/pnet.npy')[()]forn, pinself.named_parameters():#passp.data = torch.FloatTensor(weights[n])defforward(self, x):"""
Arguments:
x: a float tensor with shape [batch_size, 3, h, w].
Returns:
b: a float tensor with shape [batch_size, 4, h', w'].
a: a float tensor with shape [batch_size, 2, h', w'].
"""x = self.features(x) a = self.conv4_1(x) b = self.conv4_2(x) a = F.softmax(a)returnb, aclassRNet(nn.Module):def__init__(self):super(RNet, self).__init__() self.features = nn.Sequential(OrderedDict([ ('conv1', nn.Conv2d(3,28,3,1)), ('prelu1', nn.PReLU(28)), ('pool1', nn.MaxPool2d(3,2, ceil_mode=True)), ('conv2', nn.Conv2d(28,48,3,1)), ('prelu2', nn.PReLU(48)), ('pool2', nn.MaxPool2d(3,2, ceil_mode=True)), ('conv3', nn.Conv2d(48,64,2,1)), ('prelu3', nn.PReLU(64)), ('flatten', Flatten()), ('conv4', nn.Linear(576,128)), ('prelu4', nn.PReLU(128)) ])) self.conv5_1 = nn.Linear(128,2) self.conv5_2 = nn.Linear(128,4) weights = np.load('src/weights/rnet.npy')[()]forn, pinself.named_parameters(): p.data = torch.FloatTensor(weights[n])defforward(self, x):"""
Arguments:
x: a float tensor with shape [batch_size, 3, h, w].
Returns:
b: a float tensor with shape [batch_size, 4].
a: a float tensor with shape [batch_size, 2].
"""x = self.features(x) a = self.conv5_1(x) b = self.conv5_2(x) a = F.softmax(a)returnb, aclassONet(nn.Module):def__init__(self):super(ONet, self).__init__() self.features = nn.Sequential(OrderedDict([ ('conv1', nn.Conv2d(3,32,3,1)), ('prelu1', nn.PReLU(32)), ('pool1', nn.MaxPool2d(3,2, ceil_mode=True)), ('conv2', nn.Conv2d(32,64,3,1)), ('prelu2', nn.PReLU(64)), ('pool2', nn.MaxPool2d(3,2, ceil_mode=True)), ('conv3', nn.Conv2d(64,64,3,1)), ('prelu3', nn.PReLU(64)), ('pool3', nn.MaxPool2d(2,2, ceil_mode=True)), ('conv4', nn.Conv2d(64,128,2,1)), ('prelu4', nn.PReLU(128)), ('flatten', Flatten()), ('conv5', nn.Linear(1152,256)), ('drop5', nn.Dropout(0.25)), ('prelu5', nn.PReLU(256)), ])) self.conv6_1 = nn.Linear(256,2) self.conv6_2 = nn.Linear(256,4) self.conv6_3 = nn.Linear(256,10) weights = np.load('src/weights/onet.npy')[()]forn, pinself.named_parameters(): p.data = torch.FloatTensor(weights[n])defforward(self, x):"""
Arguments:
x: a float tensor with shape [batch_size, 3, h, w].
Returns:
c: a float tensor with shape [batch_size, 10].
b: a float tensor with shape [batch_size, 4].
a: a float tensor with shape [batch_size, 2].
"""x = self.features(x) a = self.conv6_1(x) b = self.conv6_2(x) c = self.conv6_3(x) a = F.softmax(a)returnc, b, a
模型训练阶段:
人脸检测
这就是一个分类任务,使用交叉熵损失函数:
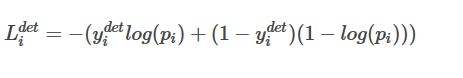
交叉熵损失函数
边框回归使用平方和损失函数:
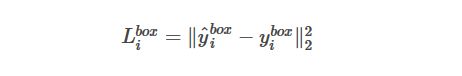
边框回归使用平方和损失函数
人脸特征点定位也使用平方和损失函数:

人脸特征点定位也使用平方和损失函数
我们在整个CNN框架上有多种不同的任务,不是每一种任务都需要执行以上三种损失函数的,比如判断背景图片是不是人脸的时候,只需要计算det的损失函数(第一个损失函数),α表示任务的重要性,所以定义如下函数:
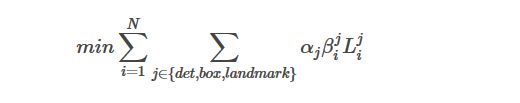
多任务训练
实验结果(详细分析请参考论文原文):

实验结果
用上边pytorch的代码跑了一下(测试了一张只有一个人脸的图片):
输出了一些O-Net的face classification、bounding box regression和Facial landmark localization,输出依旧是5 * 2、5 * 4、5 * 10的Variable(至于为什么都是5,待我搞清楚再更新...),如下图:
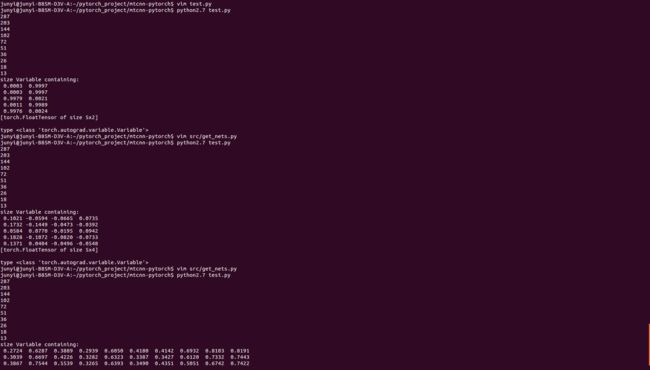
关注图片中的三个输出的Variable就好
pytorch版本开源代码:https://github.com/TropComplique/mtcnn-pytorch
结论:
同时提高了人脸检测的速度和精度。
参考文献:
1、https://blog.csdn.net/tinyzhao/article/details/53236191
2、https://blog.csdn.net/tinyzhao/article/details/53236191
3、https://www.zhihu.com/question/28748001
作者:东北大学 张俊怡
作者:Moonsmile
链接:https://www.jianshu.com/p/db66f6bfba86
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。