计算机毕设 大数据电商用户行为分析 -python 大数据
文章目录
- 0 前言
- 一.背景描述
- 二.项目背景
- 三.数据来源
- 四.提出问题
- 五.理解数据
- 六.数据清洗
-
- 6.1缺失值处理
- 6.2查看数据
- 6.3一致化处理
- 6.4查看data_user数据集数据类型:
- 6.5数据类型转换
- 6.6异常值处理
- 七.用户行为分析
-
- 7.1日访问量分析
- 7.2小时访问量分析
- 7.3不同行为类型用户PV分析
- 八.用户消费行为分析
-
- 8.1用户购买次数情况
- 8.1日ARPPU
- 8.2日ARPU
- 8.3付费率
- 8.4同一时间段用户消费数分布
- 九.复购情况分析
- 九、漏斗流失分析
- 十用户行为与商品种类关系分析
- 最后
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
基于大数据的淘宝用户行为分析
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
一.背景描述
针对项目:淘宝用户分析使用。2014年是阿里巴巴集团移动电商业务快速发展的一年,例如2014双11大促中移动端成交占比达到42.6%,超过240亿元。相比PC时代,移动端网络的访问是随时随地的,具有更丰富的场景数据,比如用户的位置信息、用户访问的时间规律等。
本次大赛以阿里巴巴移动电商平台的真实用户-
商品行为数据为基础,同时提供移动时代特有的位置信息,而参赛队伍则需要通过大数据和算法构面向建移动电子商务的商品推荐模型。希望参赛队伍能够挖掘数据背后丰富的内涵,为移动用户在合适的时间、合适的地点精准推荐合适的内容。
二.项目背景
本数据报告以淘宝app平台为数据集,通过行业的指标对淘宝用户行为进行分析,从而探索淘宝用户的行为模式,具体指标包括:日PV和日UV分析,付费率分析,复购行为分析,漏斗流失分析和用户价值RFM分析。
三.数据来源
丹成学长数据集
四.提出问题
- 日PV有多少
- 日UV有多少
- 付费率情况如何
- 复购率是多少
- 漏斗流失情况如何
- 用户价值情况
五.理解数据
本数据集共有104万条左右数据,数据为淘宝APP2014年11月18日至2014年12月18日的用户行为数据,共计6列字段,列字段分别是:
user_id:用户身份,脱敏
item_id:商品ID,脱敏
behavior_type:用户行为类型(包含点击、收藏、加购物车、支付四种行为,分别用数字1、2、3、4表示)
user_geohash:地理位置
item_category:品类ID(商品所属的品类)
time:用户行为发生的时间
六.数据清洗
import pandas as pd
import numpy as py
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
data_user = pd.read_csv('/home/kesci/input/taobao1920/tianchi_mobile_recommend_train_user.csv')
6.1缺失值处理
#缺失值处理
missingTotal = data_user.isnull().sum()
missingExist = missingTotal[missingTotal>0]
missingExist = missingExist.sort_values(ascending=False)
print(missingTotal)
user_id 0
item_id 0
behavior_type 0
user_geohash 8334824
item_category 0
time 0
dtype: int64
存在缺失值的是User_geohash,有717785条,不能删除缺失值,因为地理信息在数据集收集过程中做过加密转换,因此对数据集不做处理。
6.2查看数据
print(data_user.head())

6.3一致化处理
#一致化处理
import re
#拆分数据集
data_user['date'] = data_user['time'].map(lambda s: re.compile(' ').split(s)[0])
data_user['hour']=data_user['time'].map(lambda s:re.compile(' ').split(s)[1])
data_user.head()
6.4查看data_user数据集数据类型:
data_user.dtypes
user_id int64
item_id int64
behavior_type int64
user_geohash object
item_category int64
time object
date object
hour object
dtype: object
6.5数据类型转换
#发现time列和date列应该转化为日期类数据类型,hour列应该是整数数据类型。
#数据类型转化
data_user['date']=pd.to_datetime(data_user['date'])
data_user['time']=pd.to_datetime(data_user['time'])
data_user['hour']=data_user['hour'].astype('int64')
data_user.dtypes
user_id int64
item_id int64
behavior_type int64
user_geohash object
item_category int64
time datetime64[ns]
date datetime64[ns]
hour int64
dtype: object
6.6异常值处理
#异常值处理
data_user = data_user.sort_values(by='time',ascending=True)
data_user = data_user.reset_index(drop=True)
data_user.describe()

通过观察数据集的四分位数,总数,平均值,方差等,发现数据集并无异常值存在。
七.用户行为分析
(1)pv和uv分析
PV(访问量):即Page View, 具体是指网站的是页面浏览量或者点击量,页面被刷新一次就计算一次。
UV(独立访客):即Unique Visitor,访问您网站的一台电脑客户端为一个访客。
7.1日访问量分析
#pv_daily记录每天用户操作次数,uv_daily记录每天不同的上线用户数量
pv_daily=data_user.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_daily=data_user.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_daily.plot(x='date',y='pv',ax=axes[0])
uv_daily.plot(x='date',y='uv',ax=axes[1])
axes[0].set_title('pv_daily')
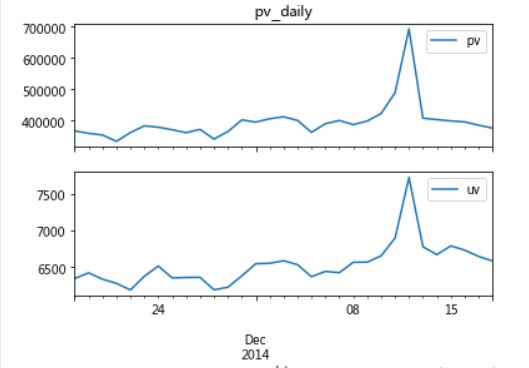
结果显示如上图所示,在双十二期间,pv和uv访问量达到峰值,并且可以发现,uv和pv两个访问量数值差距比较大,同时,因为数据集总人数大约是10000人左右,因此,通过nv值可以分析出双十二期间淘宝用户的日活跃大概是45%浮动。
7.2小时访问量分析
#小时访问量分析
#pv_hour记录每小时用户操作次数,uv_hour记录每小时不同的上线用户数量
pv_hour=data_user.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pv'})
uv_hour=data_user.groupby('hour')['user_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_hour.plot(x='hour',y='pv',ax=axes[0])
uv_hour.plot(x='hour',y='uv',ax=axes[1])
axes[0].set_title('pv_hour')
axes[0].set_title('uv_hour')

图表显示:pv和uv在凌晨0-5点期间波动情况相同,都呈下降趋势,访问量都比较小,同时在晚上18:00左右,pv波动情况比较剧烈,相比来看uv不太明显,因此晚上18:00以后是淘宝用户访问app的活跃时间段。
7.3不同行为类型用户PV分析
#不同行为类型用户pv分析
pv_detail=data_user.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'total_pv'})
fig,axes=plt.subplots(2,1,sharex=True)
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail,ax=axes[0])
sns.pointplot(x='hour',y='total_pv',hue='behavior_type',data=pv_detail[pv_detail.behavior_type!=1],ax=axes[1])
axes[0].set_title('pv_different_behavior_type')
axes[1].set_title('pv_different_behavior_type_except1')

有图表显示:点击这一用户行为相比较于其他三类用户行为,pv访问量较高,同时四种用户行为的波动情况基本一致,因此晚上这一时间段不管哪一种用户行为,pv访问量都是最高的。从图2可以看出,加入购物车这一用户行为的pv总量高于收藏的总量,因此在后续漏斗流失分析中,用户类型3应该在2之前分析。
八.用户消费行为分析
8.1用户购买次数情况
#(1)用户购买次数情况分析
data_user_buy=data_user[data_user.behavior_type==4].groupby('user_id')['behavior_type'].count()
sns.distplot(data_user_buy,kde=False)
plt.title('daily_user_buy')

图表显示:淘宝用户消费次数普遍在10次以内,因此需要重点关注购买次数在10次以上的消费者用户群体。
8.1日ARPPU
ARPPU(average revenue per paying user)是指从每位付费用户身上获得的收入,它反映的是每个付费用户的平均付费额度。
ARPPU=总收入/活跃用户付费数量
因为本数据集中没有消费金额,因此在计算过程中用消费次数代替消费金额
人均消费次数=消费总次数/消费人数
data_use_buy1=data_user[data_user.behavior_type==4].groupby(['date','user_id'])['behavior_type'].count().reset_index().rename(columns={'behavior_type':'total'})
data_use_buy1.groupby('date').apply(lambda x:x.total.sum()/x.total.count()).plot()
plt.title('daily_ARPPU')

图表显示:平均每天消费次数在1-2次之间波动,双十二期间消费次数达到最高值。
8.2日ARPU
#ARPU(Average Revenue Per User) :平均每用户收入,可通过 总收入/AU 计算得出。它可以衡量产品的盈利能力和发展活力。
#活跃用户数平均消费次数=消费总次数/活跃用户人数(每天有操作行为的为活跃)
data_user['operation']=1
data_use_buy2=data_user.groupby(['date','user_id','behavior_type'])['operation'].count().reset_index().rename(columns={'operation':'total'})
data_use_buy2.groupby('date').apply(lambda x:x[x.behavior_type==4].total.sum()/len(x.user_id.unique())).plot()
plt.title('daily_ARPU')

8.3付费率
#(4)付费率
#付费率=消费人数/活跃用户人数
data_use_buy2.groupby('date').apply(lambda x:x[x.behavior_type==4].total.count()/len(x.user_id.unique())).plot()
plt.title('daily_afford_rate')

8.4同一时间段用户消费数分布
#(5)同一时间段用户消费次数分布
data_user_buy3=data_user[data_user.behavior_type==4].groupby(['user_id','date','hour'])['operation'].sum().rename('buy_count')
sns.distplot(data_user_buy3)
print('大多数用户消费:{}次'.format(data_user_buy3.mode()[0]))
大多数用户消费:1次

九.复购情况分析
#复购情况,即两天以上有购买行为,一天多次购买算一次
#复购率=有复购行为的用户数/有购买行为的用户总数
date_rebuy=data_user[data_user.behavior_type==4].groupby('user_id')['date'].apply(lambda x:len(x.unique())).rename('rebuy_count')
print('复购率:',round(date_rebuy[date_rebuy>=2].count()/date_rebuy.count(),4))
复购率: 0.8717
#所有复购时间间隔消费次数分布
data_day_buy=data_user[data_user.behavior_type==4].groupby(['user_id','date']).operation.count().reset_index()
data_user_buy4=data_day_buy.groupby('user_id').date.apply(lambda x:x.sort_values().diff(1).dropna())
data_user_buy4=data_user_buy4.map(lambda x:x.days)
data_user_buy4.value_counts().plot(kind='bar')
plt.title('time_gap')
plt.xlabel('gap_day')
plt.ylabel('gap_count')

多数用户复购率为0.4693,消费次数随着消费时间间隔的增加而不断下降,在1-10天之内复购次数比较多,10天之后复购次数淘宝用户很少在进行复购,因此需要重视10天之内的淘宝用户复购行为,增加用户复购。不同用户平均复购时间呈正态分布,但是总体来看,呈现逐渐下降趋势。多数淘宝用户平均复购时间集中在1-5天时间间隔内。
九、漏斗流失分析
漏斗分析是一套流程式数据分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。
data_user_count=data_user.groupby(['behavior_type']).count()
data_user_count.head()
pv_all=data_user['user_id'].count()
print(pv_all)
12256906
十用户行为与商品种类关系分析
#不同用户行为类别的转化率 data_category=data_user[data_user.behavior_type!=2].groupby(['item_category','behavior_type']).operation.count().unstack(1).rename(columns={1:'点击量',3:'加入购物车量',4:'购买量'}).fillna(0)
data_category.head()
