分库分表-理论、方案、问题总结
一、如何进行分库分表
1.1.为什么要进行分库分表
分库分表是两回事,有可能需要只分库不分表,也有可能只分表不分库.
为什么要分表?
随着业务数据的不断增加单表数据量越来越大,可能到几千万.这时就会出现sql执行性能问题,这时你就需要分表了.
分表是为了解决SQL执行效率问题,效率问题可能来自以下方面:
- 数据表记录太多,sql执行效率下降.尽管进行了索引优化、sql优化,还是无法提高sql性能问题.
- 还有一个可能原因,由于数据量变大,insert插入效率变低,大多数场景下insert操作都会关联事务,如果在并发量比较的情况下,事务的提交时间就会相对变长,导致事务堆积,在数据库层面就是锁等待.
本质:数据表记录太多,导致索引过大,mysql无法缓存全量的索引信息,就需要从磁盘读取,在读取、更新、写入、删除时性能降低
为什么要分库?
一般而言,一个Mysql实例最多支撑到并发2000左右,而一个健康的单库并发值最好保持在每秒1000左右.
所以为了应对并发量的增加,我们需要分库,提高并发度.
单库出现的瓶颈问题:
- CPU压力过大,导致读写性能较慢
- 内存不足(缓存池命中率较低、磁盘读写IOPS过高),导致读写性能较慢
- 磁盘空间不足,导致无法正常读写数据
- 网络宽带不足,导致读写性能较慢
分库分表方案
主要有以下3种:
- 分库不分表: 数据库读/写QPS过高,数据库连接不足
- 只分表不分库: 单表数据量过大,存储性能遇到瓶颈
- 既分库又分表: 连接不足+数据量过大引起的存储性能瓶颈
1.2.如何进行分库分表
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分.
这两种方式,拆分方式是关键,理解拆分原理是核心.
垂直拆分
垂直拆分,就是对数据进行内容进行拆分,将一条记录拆分到多个表或是将多个业务信息拆分到多个库中.
垂直拆分的原则一般按照业务类型来拆分,核心思想是专库专用,将业务耦合度比较高的表拆分到单独的库中.
以社交app为例,常见的有用户信息、用户发帖信息,可以将这两部分内容拆分到单独的数据库中.
水平拆分
还以社交APP来说,随着业务的增长,用户的发帖信息表越来越大,单库也不能满足存储和查询需求,这时就需要将用户发帖信息拆分到多个数据库和数据表中,这就是数据库和数据表的水平拆分,然后根据一定的路由规则,查询、更新、插入时,找到对应的数据库、数据表.
以下说下拆分的路由规则.
1.2.2.分库分表的路由算法
常用的分库分表路由算法有:哈希取模和Range、
哈希
按照某一个字段的哈希值进行拆分,这种拆分规则比较适用于实体表,比如用户表,内容表,一般按照这些实体表的ID字段来拆分.
加入将内容表拆分成16个库,64张表,那么可以先对用户ID进行哈希运算,哈希的目的是将ID尽量打散,然后再对16取余,这样就得到了分库的值;对64取余就得到了分表的值
Range区间
Range区间路由,是按照某一个字段的区间范围来进行路由,比较常用的字段如ID,时间字段(如订单的创建时间).
1.3.分库分表的中间件技术选型
分库分表的中间件主要分为两种: Proxy模式、client模式
1.3.1.中间件模式
Client模式
Client方式是指分库分表的逻辑都在应用本地进行控制,应用本地会直连多个数据库进行操作,然后本地进行数据的聚合汇总等操作逻辑。
Proxy模式
Proxy方式是指挥有一个独立的应用,这个应用实现了Mysql的协议,可以对外提供服务。业务方的应用不需要直接连接数据库,而是连接这个Proxy的应用,把这个Proxy就当做一个数据库使用。Proxy会将Sql分发到具体的数据库进行执行,并返回结果。
Client模式和Proxy模式对比
性能方面
在性能方面,Client模式会比较好,因为Client模式是通过sql重写后直连数据库的,基本上和没分库分表没有区别.而代理模式,中间多了一次路由,即sql先发送到Proxy服务,然后在Proxy服务进行sql解析、重写然后发送到mysql.另外Proxy服务还要维护一份路由关系表,这个关系表一般不会写死,而是会有一个管理服务维护,而Proxy服务需要定时拉取或监听管理服务的数据变更.
内存方面
Client模式,取回数据后,是在本地进行数据合并,所以会占用本地的cpu和内存资源.
Proxy模式是单独部署的,所以是隔离状态,不会占用调用者的cpu和内容资源.
架构复杂度
Client模式只需引入一个jar包,比较简单不会有单点故障问题.
Proxy需要单独部署服务,要考虑高可用,提高整体架构的复杂度.
版本升级和管控方面
Client只需引用jar包,而这个jar包一般有其他团队负责维护、升级,所以升级时可能需要改代码配置,推动比较耗时.
Proxy模式对调用者透明,升级维护对调用者无感知.
1.3.2.常用的中间件
Proxy模式中间件有:
- MyCat :java
- KingShard: Go
- Atlas : C
- cobar: Java
Client模式:
- zebra: java
- Sharing-jdbc : java
- TSharding : java
1.3.2.1.Sharding-jdbc基础知识
分片配置
spring:
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.56.101:3306/test_db?useUnicode=true&useSSL=false&characterEncoding=utf8&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
sharding:
tables:
t_user:
key-generator-column-name: uid
key-generator:
column: uid
type: SNOWFLAKE
actual-data-nodes: m1.t_user_$->{0..1}
table-strategy:
inline:
sharding-column: uid
algorithm-expression: t_user_$->{uid%2}
binding-tables: t_user
props:
sql.show: true
如上面所示:
spring.shardingsphere.sharding.tables:配置需要路由的表
spring.shardingsphere.sharding.tables.xxx.key-generator-column-name: uid 路由字段
spring.shardingsphere.sharding.tables.xxx.key-generator: uid 路由字段生成策略
spring.shardingsphere.sharding.tables.xxx.key-generator.column :uid 路由字段
spring.shardingsphere.sharding.tables.xxx.key-generator.type: 路由字段生成策略算法
spring.shardingsphere.sharding.tables.xxx.actual-data-nodes: 当前路由表的表名。t_user_{0…1}代表t_user_0,t_user_1
spring.shardingsphere.sharding.tables.xxx.table-strategy:路由算法配置
spring.shardingsphere.sharding.tables.xxx.table-strategy.inline:行表达式,配置路由算法
spring.shardingsphere.sharding.binding-tables: 绑定需要分片的表名
字典表配置
如果在分库的情况下,每个库中需要一份相同的字典表,例如业务的配置信息.那么sharding-jdbc支持,在操作该字典表时,同时操作所有库中的字典表.
配置如下:
spring.shardingsphere.sharding.broadcast-tables=dict 配置表名
spring.shardingsphere.sharding.tables.dict.key-generator.column=id 配置全局id
spring.shardingsphere.sharding.tables.dict.key-generator.type=SNOWFLAKE 配置生成id的算法
主从配置
Sharing-jdbc支持主从数据库配置,配置如下:
配置数据源名称:
spring.shardingsphere.datasource.names=ds-0,ds-1m,ds-2m,ds-1s1,ds-2s1,ds->1s2,ds-2s2
//下面配置每个数据源信息
配置主从关系:
spring.shardingsphere.sharding.master-slave-rules.ds-1(数据库名).master-data-source->name=ds-1m
spring.shardingsphere.sharding.master-slave-rules.ds-1.slave-data-source->names[0]=ds-1s1
spring.shardingsphere.sharding.master-slave-rules.ds-1.slave-data-source->names[1]=ds-1s2
spring.shardingsphere.sharding.master-slave-rules.ds-2.master-data-source->name=ds-2m
spring.shardingsphere.sharding.master-slave-rules.ds-2.slave-data-source->names=ds-2s1,ds-2s2
然后配置分片信息:
spring.shardingsphere.sharding.tables.xxx.actual-data-nodes: 当前路由表的表名。t_user_{0..1}代表t_user_0,t_user_1
xxx应该修改为上面的ds-1
然后sharding-jdbc会自动将insert/update类型的sql路由到主库
二、分库分表带来的问题
2.1、分布式事务
分布式事务问题,查看该文章.
分布式事务
2.2、分库分表的主键问题
在分库分表后,主键将无法使用自增长来实现了,在不同的表中我们需要统一全局主键 ID。因此,我们需要单独设计全局主键,避免不同表和库中的主键重复问题。
全局唯一ID的实现方案有如下几个:
- uuid
- 雪花算法
- 号段模式
- redis/zookeeper
2.2.1.uuid
使用 UUID 实现全局 ID 是最方便快捷的方式,即随机生成一个 32 位 16 进制数字,这种方式可以保证一个 UUID 的唯一性,水平扩展能力以及性能都比较高。但使用 UUID 最大的缺陷就是,它是一个比较长的字符串,连续性差,如果作为主键使用,性能相对来说会比较差。
2.2.2.雪花算法(推荐)
雪花算法: Twitter 开源的分布式 ID 生产算法——snowflake 解决全局主键 ID 问题,snowflake 是通过分别截取时间、机器标识、顺序计数的位数组成一个 long 类型的主键 ID。这种算法可以满足每秒上万个全局 ID 生成,不仅性能好,而且低延时。
参考博客
雪花算法有以下几个优点:
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
不依赖第三方库或者中间件。
算法简单,在内存中进行,效率高。
雪花算法有如下缺点:
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
2.2.3.号段模式(推荐)
设计架构:

设计思路:
全局唯一id服务:
- 提供申请服务:可以申请一个Key,用于标记当前业务获取ID的标识
- 提供调用服务: 根据标识key,调用获取id的接口get(tag),返回id起始值,步长值
客户端:
- 提供调用API
- 提供自动获取、或延长功能,防止调用ID服务延迟,导致业务并发量高时阻塞
- 自动获取是指根据ID服务返回的起始值、步长值,来决定当id增加到步长值一定比例时,自动调取ID服务接口,并缓存结果,当客户端端ID适用完时,调用接口,直接返回缓存数据
数据库:
- 表设计: 为每一个tag建立一条记录,维护当前使用Id的数值和步长值,当下次调用时根据id+步长值=新的id,并更新数据库记录
表结构:
| 业务线信息 | tag(调用ID接口参数tag) | id(当前id) | step(步长) | status(状态) |
|---|---|---|---|---|
| 订单业务线 | biz_order | 10000 | 2000 | 1 |
| 用户信息业务线 | biz_user | 1000 | 1000 | 1 |
2.2.4.redis和zookeeper
redis
基于Redis INCR 命令生成 分布式全局唯一id
INCR 命令主要有以下2个特征:
- Redis的INCR命令具备了“INCR AND GET”的原子操作,即增加并返回结果的原子操作。这个原子性很方便我们实现获取ID.
- Redis是单进程单线程架构,INCR命令不会出现id重复.
zookeeper
实现方式有两种,一种通过节点,一种通过节点的版本号
- 节点的特性
持久顺序节点(PERSISTENT_SEQUENTIAL)
他的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在ZooKeeper中,每个父节点都会为他的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候,可以设置这个标记,那么在创建节点过程中,ZooKeeper会自动为给定节点加上一个数字后缀,作为一个新的、完整的节点名。另外需要注意的是,这个数字后缀的上限是整型的最大值。 - 版本-保证分布式数据原子性操作
ZooKeeper中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。
2.3、分库分表查询
由于分库分表后,业务关联数据被分散到多个库,多个表中.
当程序中出现统计查询、业务列表查询排序、分页时就可能出现跨库join查询、多表分页查询等问题.
可以按照以下两种方案解决:
统计查询
统计查询一般实时性比较低,后台使用,所以可以不直接查询业务库,可以单独抽取后台统计库,监听业务库数据变更binlog,将数据同步到后台统计库中,进行统计查询.
在统计库中,可以按照查询维度或业务场景,周期性生成统计表.
业务列表、关联查询
列表查询
对于互联网C端业务而言,列表查询,一般借助单独的搜索引擎架构,如下:

索引服务:
- 提供根据数据表构建全量数据对应的ES索引功能
- 监听数据库变更(mysql binlog),实时增量更新索引
缓存服务:
- 提供全量构建缓存功能,或构建可配置热点数据功能
- 监听数据库变更(mysql binlog、业务系统的mq消息),更新缓存
业务系统查询列表数据流程:
- 根据搜索条件,调用ES接口进行查询,获取内容的主键id列表
- 根据主键id列表查询缓存,如果部分没有查询到,批量查询查询数据库
- 拼装列表信息.
业务关联查询
在高并发业务系统中应尽量避免join查询,如果业务进行了分库分表,join查询将变得更加复杂.
可以将join查询拆成多个主键、索引的单表查询,热点数据进行缓存,尽量查询缓存,降低join查询的使用呢.
2.4、数据迁移、扩容问题
随着数据的增加,进行分库分表,那么根据路由规则,原先在一个库,某张表的数据将被分散到多个库,多个表中,如何进行迁移?
如果进行扩容,那么根据路由规则,怎么更好的扩容,减少数据的迁移?
解决方案,看下面两个文章:
扩容方案
迁移方案
三、分库分表操纵SOP
内容摘抄
如果要进行分库分表,我们要做哪些工作,以下我们来梳理一下一些注意事项和最佳实践:
- 业务重构
- 技术架构设计
- 改造和上线
- 稳定性保障
业务背景:
- 已经接入搜索引擎
- 后台统计和C端逻辑没有公用一个库
3.1.业务重构
3.1.1.查询分析
我们在业务重构阶段需要重点排查一下涉及分库分表的表,用到了哪些字段进行查询.
1)哪些查询是无法拆分的?例如分页(尽可能地改造,实在改不了只能以冗余列的形式)
2)哪些查询是可以业务上join拆分的?
3)哪些表/字段是可以融合的?
4)哪些字段需要冗余?
5)哪些字段可以直接废弃了?
6)根据业务具体场景和sql整体统计,识别关键的分表键。其余查询走搜索平台。
3.1.2.新表设计
这一步基于查询的拆分分析,得出旧表融合、冗余、废弃字段的结果,设计新表的字段。
产出新表设计结构后,必须发给各个相关业务方进行review,并保证所有业务方都通过该表的设计。有必要的话可以进行一次线下review。
如果新表的过程中,对部分字段进行了废弃,必须通知所有业务方进行确认。
对于新表的设计,除了字段的梳理,也需要根据具体查询,重新设计、优化索引。
3.1.2.1 尽量不改变原表的字段名称
在做新表融合的时候,一开始只是简单归并表A 和 表B的表,因此很多字段名相同的字段做了重命名。
后来字段精简过程中,删除了很多重复字段,但是没有将重命名的字段改回来。
导致后期上线的过程中,不可避免地需要业务方进行重构字段名。
因此,新表设计的时候,除非必不得已,不要修改原表的字段名称!
3.1.2.2 新表的索引需要仔细斟酌
新表的索引不能简单照搬旧表,而是需要根据查询拆分分析后,重新设计。
尤其是一些字段的融合后,可能可以归并一些索引,或者设计一些更高性能的索引。
3.2.架构设计
3.2.1.整体架构
根据第一阶段整理的查询梳理结果,我们总结了这样的查询规律。
- 80%以上的查询都是通过或者带有字段pk1、字段pk2、字段pk3这三个维度进行查询的,其中pk1和pk2由于历史原因存在一一对应的关系
- 20%的查询千奇百怪,包括模糊查询、其他字段查询等等
因此,我们设计了如下的整体架构,引入了数据库中间件、数据同步工具、搜索引擎(阿里云opensearch/ES)等。
下文的论述都是围绕这个架构来展开的.

3.2.1.1 mysql分表存储
Mysql分表的维度是根据查询拆分分析的结果确定的。
我们发现pk1\pk2\pk3可以覆盖80%以上的主要查询。让这些查询根据分表键直接走mysql数据库即可。
原则上一般最多维护一个分表的全量数据,因为过多的全量数据会造成存储的浪费、数据同步的额外开销、更多的不稳定性、不易扩展等问题。
但是由于本项目pk1和pk3的查询语句都对实时性有比较高的要求,因此,维护了pk1和pk3作为分表键的两份全量数据。
而pk2和pk1由于历史原因,存在一一对应关系,可以仅保留一份映射表即可,只存储pk1和pk2两个字段。
3.2.1.2. 搜索平台索引存储
搜索平台索引,可以覆盖剩余20%的零散查询。
这些查询往往不是根据分表键进行的,或者是带有模糊查询的要求。
对于搜索平台来说,一般不存储全量数据(尤其是一些大varchar字段),只存储主键和查询需要的索引字段,搜索得到结果后,根据主键去mysql存储中拿到需要的记录。
当然,从后期实践结果来看,这里还是需要做一些权衡的:
1)有些非索引字段,如果不是很大,也可以冗余进来,类似覆盖索引,避免多一次sql查询;
2)如果表结构比较简单,字段不大,甚至可以考虑全量存储,提高查询性能,降低mysql数据库的压力。
这里特别提示,搜索引擎和数据库之间同步是必然存在延迟的。所以对于根据分表id查询的语句,尽量保证直接查询数据库,这样不会带来一致性问题的隐患。
3.2.1.3. 数据同步
一般新表和旧表直接可以采用 数据同步 或者 双写的方式进行处理,两种方式有各自的优缺点。
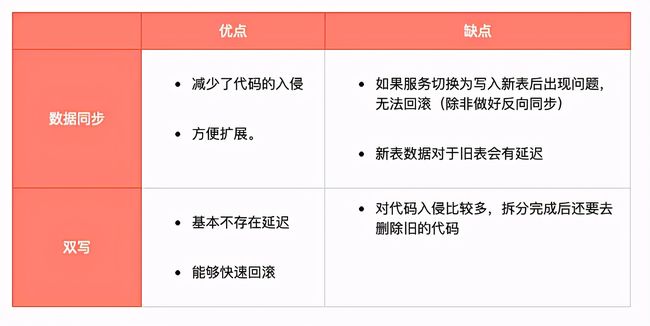
一般根据具体情况选择一种方式就行。
本次项目的具体同步关系见整体存储架构,包括了四个部分:
1)旧表到新表全量主表的同步
一开始为了减少代码入侵、方便扩展,采用了数据同步的方式。而且由于业务过多,担心有未统计到的服务没有及时改造,所以数据同步能避免这些情况导致数据丢失。
但是在上线过程中发现,当延迟存在时,很多新写入的记录无法读到,对具体业务场景造成了比较严重的影响。(具体原因参考4.5.1的说明)
因此,为了满足应用对于实时性的要求,我们在数据同步的基础上,重新在3.0.0-SNAPSHOT版本中改造成了双写的形式。
2)新表全量主表到全量副表的同步
3)新表全量主表到映射表到同步
4)新表全量主表到搜索引擎数据源的同步
2)、3)、4)都是从新表全量主表到其他数据源的数据同步,因为没有强实时性的要求,因此,为了方便扩展,全部采用了数据同步的方式,没有进行更多的多写操作。
3.2.2 容量评估
在申请mysql存储和搜索平台索引资源前,需要进行容量评估,包括存储容量和性能指标。
具体线上流量评估可以通过监控系统查看qps,存储容量可以简单认为是线上各个表存储容量的和。
但是在全量同步过程中,我们发现需要的实际容量的需求会大于预估,具体可以看3.4.6的说明。
具体性能压测过程就不再赘述。
3.2.3 数据校验
从上文可以看到,在本次项目中,存在大量的业务改造,属于异构迁移。
从过去的一些分库分表项目来说,大多是同构/对等拆分,因此不会存在很多复杂逻辑,所以对于数据迁移的校验往往比较忽视。
在完全对等迁移的情况下,一般确实比较少出现问题。
但是,类似这样有比较多改造的异构迁移,校验绝对是重中之重!!
因此,必须对数据同步的结果做校验,保证业务逻辑改造正确、数据同步一致性正确。这一点非常非常重要。
在本次项目中,存在大量业务逻辑优化以及字段变动,所以我们单独做了一个校验服务,对数据的全量、增量进行校验。
过程中提前发现了许多数据同步、业务逻辑的不一致问题,给我们本次项目平稳上线提供了最重要的前提保障!!
3.2.4.最佳实践
3.2.4.1 分库分表引起的流量放大问题
在做容量评估的时候,需要关注一个重要问题。就是分表带来的查询流量放大。
这个流量放大有两方面的原因:
- 索引表的二次查询。比如根据pk2查询的,需要先通过pk2查询pk1,然后根据pk1查询返回结果。
- in的分批查询。如果一个select…in…的查询,数据库中间件会根据分表键,将查询拆分落到对应的物理分表上,相当于原本的一次查询,放大为多次查询。(当然,数据库会将落在同一个分表的id作为一次批量查询,而这是不稳定的合并)
因此,我们需要注意:
- 业务层面尽量限制in查询数量,避免流量过于放大;
- 容量评估时,需要考虑这部分放大因素,做适当冗余,另外,后续会提到业务改造上线分批进行,保证可以及时扩容;
- 分64、128还是256张表有个合理预估,拆得越多,理论上会放大越多,因此不要无谓地分过多的表,根据业务规模做适当估计;
- 对于映射表的查询,由于存在明显的冷热数据,所以我们又在中间加了一层缓存,减少数据库的压力
3.2.4.2 分表键的变更方案
本项目中,存在一种业务情况会变更字段pk3,但是pk3作为分表键,在数据库中间件中是不能修改的,因此,只能在中台中修改对pk3的更新逻辑,采用先删除、后添加的方式。
这里需要注意,删除和添加操作的事务原子性。当然,简单处理也可以通过日志的方式,进行告警和校准。
3.4.3 数据同步一致性问题
我们都知道,数据同步中一个关键点就是(消息)数据的顺序性,如果不能保证接受的数据和产生的数据的顺序严格一致,就有可能因为(消息)数据乱序带来数据覆盖,最终带来不一致问题。
我们自研的数据同步工具底层使用的消息队列是kakfa,,kafka对于消息的存储,只能做到局部有序性(具体来说是每一个partition的有序)。我们可以把同一主键的消息路由至同一分区,这样一致性一般可以保证。但是,如果存在一对多的关系,就无法保证每一行变更有序,见如下例子。

那么需要通过反查数据源获取最新数据保证一致性。
但是,反查也不是“银弹“,需要考虑两个问题。
1)如果消息变更来源于读写实例,而反查 数据库是查只读实例,那就会存在读写实例延迟导致的数据不一致问题。因此,需要保证 消息变更来源 和 反查数据库 的实例是同一个。
2)反查对数据库会带来额外性能开销,需要仔细评估全量时候的影响。
3.2.4.3 数据实时性问题
延迟主要需要注意几方面的问题,并根据业务实际情况做评估和衡量。
1)数据同步平台的秒级延迟
2)如果消息订阅和反查数据库都是落在只读实例上,那么除了上述数据同步平台的秒级延迟,还会有数据库主从同步的延迟
3)宽表到搜索平台的秒级延迟
只有能够满足业务场景的方案,才是合适的方案。
3.2.4.4 分表后存储容量优化
由于数据同步过程中,对于单表而言,不是严格按照递增插入的,因此会产生很多”存储空洞“,使得同步完后的存储总量远大于预估的容量。
因此,在新库申请的时候,存储容量多申请50%。
具体原因可以参考我的这篇文章 为什么MySQL分库分表后总存储大小变大了?
3.3.改造上线
前两个阶段完成后,开始业务切换流程,主要步骤如下:
1)中台服务采用单读 双写 的模式
2)旧表往新表开着数据同步
3) 所有服务升级依赖的projectDB版本,上线RPC,如果出现问题,降版本即可回滚(上线成功后,单读新库,双写新旧库)
4)检查监控确保没有 中台服务 以外的其他服务访问旧库旧表
5)停止数据同步
6)删除旧表
3.3.1 查询改造
如何验证我们前两个阶段设计是否合理?能否完全覆盖查询的修改 是一个前提条件。
当新表设计完毕后,就可以以新表为标准,修改老的查询。
以本项目为例,需要将旧的sql在 新的中台服务中 进行改造。
1)读查询的改造
可能查询会涉及以下几个方面:
a)根据查询条件,需要将pk1和pk2的inner join改为对应分表键的新表表名
b)部分sql的废弃字段处理
c)非分表键查询改为走搜索平台的查询,注意保证语义一致
d)注意写单测避免低级错误,主要是DAO层面。
只有新表结构和存储架构能完全适应查询改造,才能认为前面的设计暂时没有问题。
当然,这里还有个前提条件,就是相关查询已经全部收拢,没有遗漏。
- 写查询的改造
除了相关字段的更改以外,更重要的是,需要改造为旧表、新表的双写模式。
这里可能涉及到具体业务写入逻辑,本项目尤为复杂,需要改造过程中与业务方充分沟通,保证写入逻辑正确。
可以在双写上各加一个配置开关,方便切换。如果双写中发现新库写入有问题,可以快速关闭。
同时,双写过程中不关闭 旧库到新库 的数据同步。
为什么呢?主要还是由于我们项目的特殊性。由于我们涉及到几十个服务,为了降低风险,必须分批上线。因此,存在比较麻烦的中间态,一部分服务是老逻辑,一部分服务是新逻辑,必须保证中间态的数据正确性,具体见4.5.1的分析。
3.3.2 服务化改造
为什么需要新建一个 服务来 承载改造后的查询呢?
一方面是为了改造能够方便的升级与回滚切换,另一方面是为了将查询收拢,作为一个中台化的服务来提供相应的查询能力。
将改造后的新的查询放在服务中,然后jar包中的原本查询,全部替换成这个服务的client调用。
同时,升级jar包版本到3.0.0-SNAPSHOT。
3.3.3 服务分批上线
为了降低风险,需要安排从非核心服务到核心服务的分批上线。
注意,分批上线过程中,由于写服务往往是核心服务,所以安排在后面。可能出现非核心的读服务上线了,这时候会有读新表、写旧表的中间状态。
1) 所有相关服务使用 重构分支 升级projectdb版本到3.0.0-SNAPSHOT并部署内网环境;
2) 业务服务依赖于 中台服务,需要订阅服务
3) 开重构分支(不要与正常迭代分支合并),部署内网,内网预计测试两周以上
使用一个新的 重构分支 是为了在内网测试两周的时候,不影响业务正常迭代。每周更新的业务分支可以merge到重构分支上部署内网,然后外网使用业务分支merge到master上部署。
当然,如果从线上线下代码分支一致的角度,也可以重构分支和业务分支一起测试上线,对开发和测试的压力会较大。
4)分批上线过程中,如果碰到依赖冲突的问题,需要及时解决并及时更新到该文档中
5)服务上线前,必须要求业务开发或者测试,明确评估具体api和风险点,做好回归。
这里再次提醒,上线完成后,请不要漏掉离线的数据分析业务!请不要漏掉离线的数据分析业务!请不要漏掉离线的数据分析业务!
3.3.4 旧表下线流程
1)检查监控确保没有中台服务以外的其他服务访问旧库旧表
2)检查数据库上的sql审计,确保没有其他服务仍然读取旧表数据
3)停止数据同步
4)删除旧表
3.3.5 最佳实践
3.3.5.1 写完立即读可能读不到
在分批上线过程中,遇到了写完立即读可能读不到的情况。由于业务众多,我们采用了分批上线的方式降低风险,存在一部分应用已经升级,一部分应用尚未升级的情况。未升级的服务仍然往旧表写数据,而升级后的应用会从新表读数据,当延迟存在时,很多新写入的记录无法读到,对具体业务场景造成了比较严重的影响。
延迟的原因主要有两个:
1)写服务还没有升级,还没有开始双写,还是写旧表,这时候会有读新表、写旧表的中间状态,新旧表存在同步延迟。
2)为了避免主库压力,新表数据是从旧表获取变更、然后反查旧表只读实例的数据进行同步的,主从库本身存在一定延迟。
解决方案一般有两种:
1)数据同步改为双写逻辑。
2)在读接口做补偿,如果新表查不到,到旧表再查一次。
3.3.5.2 数据库中间件唯一ID替换自增主键(划重点,敲黑板)
由于分表后,继续使用单表的自增主键,会导致全局主键冲突。因此,需要使用分布式唯一ID来代替自增主键。各种算法网上比较多,本项目采用的是数据库自增sequence生成方式。
数据库自增sequence的分布式ID生成器,是一个依赖Mysql的存在, 它的基本原理是在Mysql中存入一个数值, 每有一台机器去获取ID的时候,都会在当前ID上累加一定的数量比如说2000, 然后把当前的值加上2000返回给服务器。这样每一台机器都可以继续重复此操作获得唯一id区间。
但是仅仅有全局唯一ID就大功告成了吗?显然不是,因为这里还会存在新旧表的id冲突问题。
因为服务比较多,为了降低风险需要分批上线。因此,存在一部分服务还是单写旧表的逻辑,一部分服务是双写的逻辑。
这样的状态中,旧表的id策略使用的是auto_increment。如果只有单向数据来往的话(旧表到新表),只需要给旧表的id预留一个区间段,sequence从一个较大的起始值开始就能避免冲突。
但该项目中,还有新表数据和旧表数据的双写,如果采用上述方案,较大的id写入到旧表,旧表的auto_increment将会被重置到该值,这样单鞋旧表的服务产生的递增id的记录必然会出现冲突。
所以这里交换了双方的区间段,旧库从较大的auto_increment起始值开始,新表选择的id(也就是sequence的范围)从大于旧表的最大记录的id开始递增,小于旧表auto_increment即将设置的起始值,很好的避免了id冲突问题。
1)切换前:
sequence的起始id设置为当前旧表的自增id大小,然后旧表的自增id需要改大,预留一段区间,给旧表的自增id继续使用,防止未升级业务写入旧表的数据同步到新库后产生id冲突;
2)切换后
无需任何改造,断开数据同步即可
3)优点
只用一份代码;
切换可以使用开关进行,不用升级改造;
如果万一中途旧表的autoincrement被异常数据变大了,也不会造成什么问题。
4)缺点
如果旧表写失败了,新表写成功了,需要日志辅助处理
3.4.稳定性保障
这一章主要再次强调稳定性的保障手段。作为本次项目的重要目标之一,稳定性其实贯穿在整个项目周期内,基本上在上文各个环节都已经都有提到,每一个环节都要引起足够的重视,仔细设计和评估方案,做到心中有数,而不是靠天吃饭:
1)新表设计必须跟业务方充分沟通、保证review。
2)对于“数据同步”,必须有数据校验保障数据正确性,可能导致数据不正确的原因上文已经提到来很多,包括实时性、一致性的问题。保证数据正确是上线的大前提。
3)每一阶段的变动,都必须做好快速回滚都预案。
4)上线过程,都以分批上线的形式,从非核心业务开始做试点,避免故障扩大。
5)监控告警要配置全面,出现问题及时收到告警,快速响应。不要忽略,很重要,有几次出现选过数据的小问题,都是通过告警及时发现和解决的
6)单测,业务功能测试等要充分
3.5.一定要留好各种文档
操作要有SOP
设计要有具体文档