具有宽度网络架构的联邦持续学习
Federated Continuous Learning With Broad Network Architecture
目前,大多数提出的 FL 模型都专注于一次性学习,而不考虑持续学习。持续学习(或终身学习)描述了一个学习过程,其中模型在训练数据流上不断训练。基于过去的知识,持续学习可以学习新知识并将其总结在新学习模型中。
在动态场景中,客户端可以随机加入和离开网络,新接收的权重可以与之前的权重显着不同。因此,新的聚合学习模型可能会“忘记”之前学到的知识。
现有的全局权重更新方法主要有两种类型:
-
异步
-
同步
在同步方法中,时间消耗由聚合过程中所有客户端之间上传最慢的客户端决定,因此可能会造成严重的缓慢训练问题。
异步训练方法存在的问题
1)不准确的训练问题:异步方法中有陈旧更新的可能性。一个客户端的陈旧更新可以覆盖聚合过程中其他客户端的更新,从而导致训练不准确的问题。
2)沟通效率低下的问题。如果采用异步方法,那么随着客户端数量的增加,所需的客户端-服务器交互轮数量正在迅速增长。如何在FCL中考虑如何减少客户端-服务器交互轮数量。
在本文中,我们提出了一种基于宽度学习(FCL-BL)方案的FCL方案,以支持高效、准确的FCL。
- 为了解决灾难性遗忘问题,我们开发了一种加权处理策略。在接收到云服务器的全局权值时,加权处理策略让每个客户端计算全局权值(即从服务器接收权值)和客户端本地权值的加权平均值。加权平均用作客户端的下一次更新。基于更新,新训练的全局模型可以保留先前学到的知识,并适应新的知识。因此,解决了灾难性遗忘问题。
- 为了解决不准确的训练问题,我们设计了一个与本地无关的训练解决方案。在 FCL-BL 中,本地训练过程可以独立执行(本地训练模型不依赖于全局学习模型的知识)。一旦获得了新的本地权重,客户端总是可以使用最新的全局权重来计算上传到云服务器的新更新。因此,消除了陈旧更新的可能性,解决了不准确的训练问题。
- 为了解决通信效率低下的问题,我们定制了现有的异步全局权重更新方法(称为批处理异步方法)。在批处理异步方法中,云服务器仅在接收到批处理后计算全局权重客户的更新。通过适当调整子集的基数,批处理异步方法可以在保证高效聚合的同时大大减少客户端-服务器交互轮数(即全局模型的高预测精度和短聚合时间)
FCL-BL 设计的主要技术挑战是如何为每个客户端有效地实现持续学习
本文贡献:
- 我们提出了FCL-BL方案来支持FL设置中的持续学习。为了解决灾难性遗忘问题,我们提出了一种加权处理策略。FCL-BL 可以保留现有的学习知识并适应新的知识,在实践中提供更好的实时性能。
- 我们开发了一种用于定制异步全局权重更新方法的局部独立训练解决方案。所提出的解决方案使我们能够避免使用耗时的同步方法,同时解决植根于现有异步方法的不准确训练问题。因此,FCL-BL 实现了快速准确的训练。
- 我**们引入了一种批处理异步方法和BL技术来保证FCL-BL的高效率。**一方面,批处理异步方法可以大大减少客户端-服务器交互轮数,同时在很大程度上保持全局模型的预测精度,避免聚合延迟长。另一方面,BL 技术支持增量学习,而无需每个客户端在学习新生成的数据时重新训练。
- 实验结果表明,即使每个客户端拥有不平衡且非独立同分布(Non-IID)数据集,FCL-BL 也可以确保全局训练模型的高预测精度。
FCL-BL的系统模型
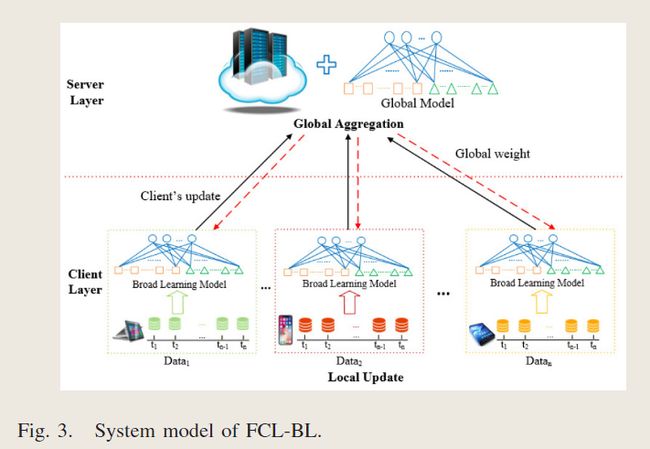
FCL-BL全局更新权重设计
Local-Independent Training Solution(本地独立培训解决方案):
在同步方法中,服务器在接收到所有客户机的本地权重时更新全局权重。具体来说,所有客户端并行训练,当所有客户端完成本地训练时,他们同时上传自己的本地权重。但是,在等待最慢的客户机时,快速客户机可能会产生大量空闲时间,这意味着在最慢的客户机完成训练之前,快速客户机无法执行任何操作。更糟糕的是,如果任何客户机退出或拒绝上传,全局权重更新过程可能会停止。因此,同步方法导致训练严重缓慢。
在异步方法中,每当服务器从任何客户机接收到本地权重时,都会更新全局权重。但是,由于客户的培训速度不同,会造成培训不准确的问题。
为了解决训练缓慢和训练不准确的问题,我们提出了一个独立于本地的训练解决方案(Local-Independent Training Solution)。在该解决方案中,本地训练处理是独立执行的。此外,为了避免在过小的数据集或过大的数据集上进行本地训练,将客户端的样本阈值设置为thr1,只要样本数量大于thr1,就进行本地训练???。因此,客户端可以连续地在新的本地数据集上进行训练,而不必再等待速度较慢的客户端,从而解决了同步方法的慢训练问题。
此外,在本地独立训练中,每个客户端仅根据自己的本地数据集更新本地权重。也就是说,本地训练模式不依赖于全局学习模式的知识。在不受全局权值约束的情况下,客户端始终可以选择最新的全局权值来计算新客户端的更新。因此,本地独立的训练方案可以保证每次全局权值更新都是基于最新的全局权值,从而消除了陈旧的更新,解决了训练不准确的问题。
Batch-Asynchronous Approach(批处理异步方法):
尽管本地独立训练解决方案可以解决训练速度慢和训练不准确的问题,但全局权重更新还存在其他限制。如果在同步方法中使用本地独立训练解决方案,则服务器仅在接收到所有客户端的更新时执行聚合以更新全局权重,因此聚合时间由最慢的客户端确定。如果采用异步方法,则服务器在接收到任何客户端的更新后立即执行全局权重更新,从而实现短的聚合延迟。然而,这样做的成本是增加交互回合的数量,以获得具有高预测精度的全局模型,尤其是对于大量客户端,这将导致通信效率低下的问题。为此,我们提出了一种批处理异步方法,如图所示。
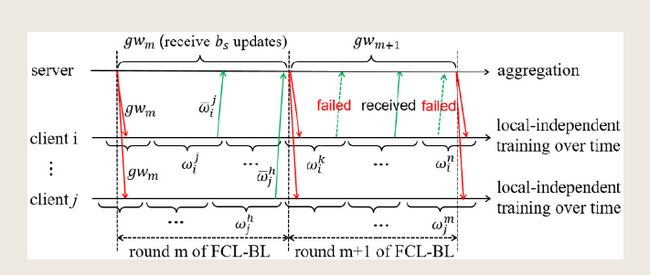
在批处理异步方法中,服务器只有在接收到一批客户端的更新后才执行聚合。通过适当调整批处理的基数(定义为bs),批处理异步方法可以大大减少客户端-服务器交互轮次的数量同时确保高效聚合。此外,为了确保有效的全局权重更新,同时避免过时的更新,可以随时上传客户端的更新。为了确保学习的公平性,在一轮FCL-BL中,服务器最多只能接收每个客户端的一次更新。如果客户端的更新上传失败,则允许客户端再次上传;如果服务器接收到上传,则在同一轮中将拒绝将此更新上传到另一客户端。
持续学习的FCL-BL
基于上述全局权重更新设计,构建了FCL-BL来实现持续学习。在FCL-BL中,提出了本地BL模型、本地再聚合策略和加权处理策略
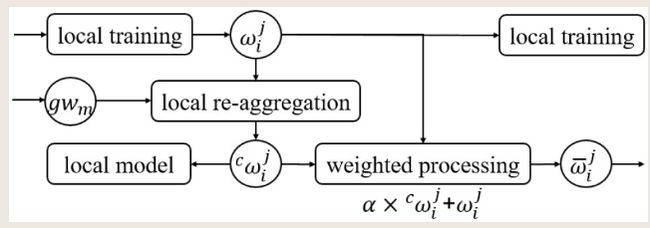
在客户端,执行本地更新,如图所示,在本地更新中,它包括本地训练、本地重新聚合策略和加权处理策略。
A.基于宽度学习的本地训练:
在 BL 中,它可以不断地学习新的传入数据集,而无需从头开始就进行重新训练,因此训练明显加快。
B.本地再聚合策略:
本地再聚合策略保证了本地模型具有较高的预测精度。
在客户端中,本地模型可用于预测、分类等。然而,由于新数据集是随着时间的推移而产生的,如果直接使用全局权重来更新本地模型,则不使用新生成的数据集。如果使用新的本地权重来更新本地模型,则不使用来自其他客户端的学习知识。它们都会影响本地模型的预测精度。
该策略的关键思想是重新聚合客户端中的全局权重 和新的本地权重。
1,如果客户端参与第m轮全局权重的聚合,则会造成偏差,需要删除了全局权重中客户端的相对陈旧的权重。
2,如果客户端不参与第m轮全局权重的聚合,则客户端的本地权重可以直接聚合。
C.加权处理策略(解决灾难性遗忘问题,使FCL-BL能够实现连续学习):
在接收到云服务器的全局权值时,加权处理策略允许每个客户端计算全局权值和客户端本地权值的加权平均值。分配适当的权重将有助于记住以前的知识,同时避免欠拟合或过度拟合新数据集。
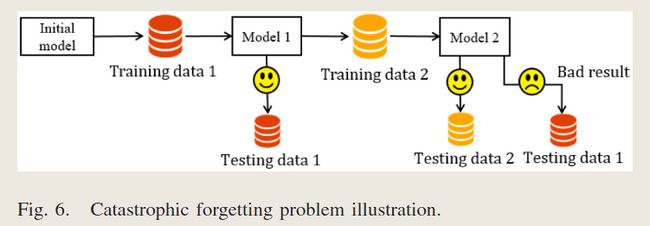
灾难性遗忘问题图解