(基础)Redis 第一章 Redis基础
Redis 第一章 Redis基础
- Redis 介绍
- 1.1 Redis特性
- 1.2 Redis数据类型
- 1.3 Redis常用命令
- 2. Redis启动加载过程及RDB的实现
- 2.1 启动加载过程
- 2.2 RDB实现
- 2.3 AOF实现
- 2.4 Redis数据库的实现
Redis 介绍
1.1 Redis特性
(1)存储结构
Redis是Remote Dictonary Server(远程字段服务)的缩写,它使用字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容。同大多数脚本语言的字典一样,Redis字典中的键值除了可以是字符串,还可以是其他数据类型。Redis支持的数据类型有字符串、散列、列表、集合、有序集合。
(2)内存存储与持久化
Redis数据库的所有数据都存储在内存中,在一台普通的笔记本电脑上,Redis可以在1秒内读写超过十万个键值。Redis也提供了持久化的支持,即将内存中的数据异步写入硬盘中,同时不影响继续提供服务。
(3)功能丰富
Redis在很多场合是名副其他的多面手,越来越多的人讲其用作缓存、队列系统中。例如,Redis可作为缓存系统,并且可以为每个键设置生存时间,生存时间到期后键会自动删除;Redis还支持“发布/订阅”的消息模式,等等。
(4)简单稳定
在Redis中使用命令来读写数据,就相当于SQL语言之关系型数据库。并且Redis提供了几十种不同编程语言的客户端库,这些库很好地封装了Redis命令,使得在程序中与Redis进行交互更加容易。 Redis是开源的,良好的开发氛围和严谨的版本发布机制使得Redis的稳定版本更加可靠。
先直观了解下redis命名的简洁性
SQL语句:
SELECT title FROM posts WHERE id=1 LIMIT 1
Redis中命令:
HGET post:1 title
1.2 Redis数据类型
(1)字符串类型
字符串类型是Redis中最基本的数据类型,它能存储任何形式的字符串,例如存储用户的邮箱、JSON化的对象甚至是一张图片。一个字符串类型键允许存储的数据的最大容量是512MB,但是不建议存储超大文件。
(2)散列类型
Redis是采用字典结构以键值对的形式存储数据,而散列类型的键值也是一种字典结构,其存储了字段和字段的映射,但是字段值只能是字符串,不支持其他数据类型。散列类型适合存储对象。
(3)列表类型
列表类型可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个字段。
(4)集合类型
集合中的每个元素都是不同的,并且没有顺序。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
(5)有序集合类型
在集合类型的基础上,使得我们可以获得最高(最低)的前N个元素、指定分数范围内的元素等与分数有关的操作。
1.3 Redis常用命令
-
(0)启动
安装很简单,自己百度。
启动 Redis
redis-server
检查Redis是否在工作
redis-cli -
(1)字符串
SET name "Tom"
GET name
SET counter 1000
INCR counter
DECR counter
APPEND name "Jack"
GET name
- (2)散列类型
HMSET car name "volvo" color "black" price 20
HMGET car name
HEXISTS car name
HDEL car price
- (3)列表类型
LPUSH lists redis
LPUSH lists mogodb
RPUSH lists mysql
LPOP lists
RPOP lists
LRANGE lists 0 10
(4)集合类型
SADD letters a
SADD letters a b c
SREM letters c d
SMEMBERS letters
SADD setA 1 2 3
SADD setB 2 3 4
SDIFF setA setB
- (5)有序集合
ZADD tutorials 1 redis 2 mongodb 3 mysql 3 mysql
ZRANGE tutorials 0 10 WITHSCORES
- (6)事务
MULTI
INCR likes
INCR visitors
EXEC
- (7)生存时间
SET session uuid11
EXPIRE session 20
TTL session
- (8)排序
LPUSH mylist 4 2 6 1 7 3
SORT mylist
LPUSH mylistalpha a c e d c a
SORT mylistalpha ALPHA
(9)消息通知
PUBLISH redisChat "Redis is a great caching technique"
SUBSCRIBE redisChat
PUBLISH redisChat "Learn redis by tutorials point"
注:管道
-P的意思就是把多个请求放到一个管道中,Redis的底层通信协议对管道(pipelining)提供了支持,通过管道可以一次性发送多条指令并在执行完成后一次性将结果返回,当一组命令中每条命令不依赖于之前命令的执行结果时就可以将这组命令一起通过管道发出,管道可以减少客户端与Redis的通信次数来实现降低往返时延累计值的目的。因为redis内存存储速度在100ns之内,而网络请求速度在20ms-30ms。所以通过管道处理能显著提供redis的吞吐量。

2. Redis启动加载过程及RDB的实现
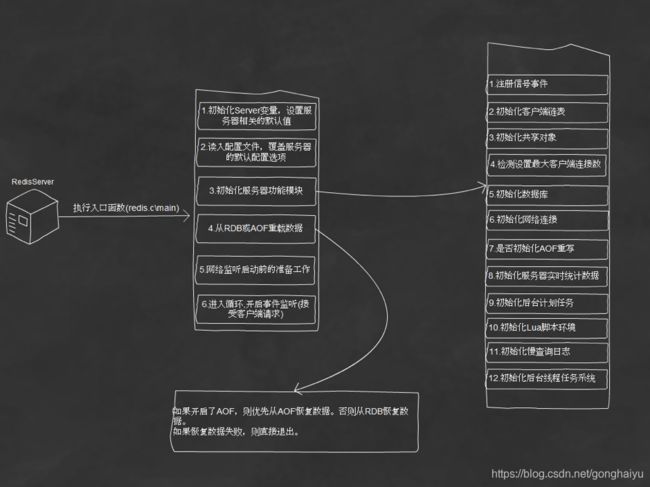
2.1 启动加载过程
1.初始化server变量,设置redis相关的默认值
2.读入配置文件,同时接收命令行中传入的参数,替换服务器设置的默认值
3.初始化服务器功能模块。在这一步初始化了包括进程信号处理、客户端链表、共享对象、初始化数据、初始化网络连接等
4.从RDB或AOF重载数据
5.网络监听服务启动前的准备工作
6.开启事件监听,开始接受客户端的请求
2.2 RDB实现
从上述描述可以看出,RDB主要包括两个功能:
关于rdb的实现可以见src/rdb.c
a)保存(rdbSave)
rdbSave负责将内存中的数据库数据以RDB格式保存到磁盘中,如果RDB文件已经存在将会替换已有的RDB文件。保存RDB文件期间会阻塞主进程,这段时间期间将不能处理新的客户端请求,直到保存完成为止,类似于JVM中的STOP THE WORLD。
为避免主进程阻塞,Redis提供了rdbSaveBackground函数。在新建的子进程中调用rdbSave,保存完成后会向主进程发送信号,同时主进程可以继续处理新的客户端请求。因为后台线程在存储数据时,主线程会存储一部分客户端的数据,当主线程挂掉时,数据将丢失,故此种方案在数据恢复时肯定是不行的。
b)读取(rdbLoad)
当Redis启动时,会根据配置的持久化模式,决定是否读取RDB文件,如果为RDB持久化模式,则需要读取RDB文件的对象保存到内存中。
载入RDB过程中,每载入1000个键就处理一次已经等待处理的客户端请求,但是目前仅处理订阅功能的命令(PUBLISH 、 SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE),其他一律返回错误信息。因为发布订阅功能是不写入数据库的,也就是不保存在Redis数据库的,这就说明为什么使用Redis作为消息队列很容易出现问题。
实例:
save 900 1 #刷新快照到硬盘中,必须满足两者要求才会触发,即900秒之后至少1个关键字发生变化。
save 300 10 #必须是300秒之后至少10个关键字发生变化。
save 60 10000 #必须是60秒之后至少10000个关键字发生变化。
stop-writes-on-bgsave-error yes #后台存储错误停止写。
rdbcompression yes #使用LZF压缩rdb文件。
rdbchecksum yes #存储和加载rdb文件时校验。
dbfilename dump.rdb #设置rdb文件名。
dir ./ #设置工作目录,rdb文件会写入该目录。
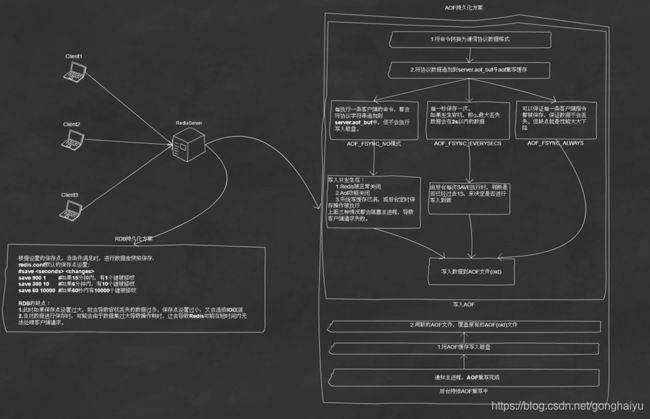
2.3 AOF实现
以协议文本的方式,将所有对数据库进行的写入命令记录到AOF文件,达到记录数据库状态的目的。
- a)保存
1.将客户端请求的命令转换为网络协议格式
2.将协议内容字符串追加到变量server.aof_buf中
3.当AOF系统达到设定的条件时,会调用aof_fsync(文件描述符号)将数据写入磁盘
因为磁盘写入速度慢,所以其中第三步提到的设定条件,就是AOF性能的关键点。目前Redis支持三种保存条件机制:
1.AOF_FSYNC_NO:不保存
此模式下,每执行一条客户端的命令,都会将协议字符串追加到server.aof_buf中,但不会执行写入磁盘。
写入只发生在:
1.Redis被正常关闭
2.aof功能关闭
3.系统写缓存已满,或后台定时保存操作被执行
上面三种情况都会阻塞主进程,导致客户端请求失败。
2.AOF_FSYNC_EVERYSECS:每一秒保存一次
由后台子进程调用写入保存,不会阻塞主进程。如果发生宕机,那么最大丢失数据会在2s以内的数据。这也是默认的设置选项
3.AOF_FSYNC_ALWAYS:每执行一个命令都保存一次
这种模式下,可以保证每一条客户端指令都被保存,保证数据不会丢失。但缺点就是性能大大下降,因为每一次操作都是独占性的,需要阻塞主进程。
- b)读取
AOF保存的是数据协议格式的数据,所以只要将AOF中的数据转换为命令,模拟客户端重新执行一遍,就可以还原所有数据库状态。
读取的过程是:
1.创建模拟的客户端
2.读取AOF保存的文本,还原数据为原命令和原参数。然后使用模拟的客户端发出这个命令请求。
3.继续执行第二步,直到读取完AOF文件
AOF需要将所有的命令都保存到磁盘,那么这个文件会随着时间变得越来越大。读取也会变得很慢。
Redis提供了AOF的重写机制,帮助减少文件的大小。实现的思路是:
LPUSH list 1 2 3 4 5
LPOP list
LPOP list
LPUSH list 1
最初保存到AOF文件的将会是四条指令。但经过AOF重写后,会变成一条指令:
LPUSH list 1 3 4 5
同时,考虑到为了在AOF重写时,不影响AOF的写入增加了AOF重写缓存的概念。
也就是说Redis在开启AOF时,除了将命令格式数据写入到AOF文件,同时也会写入到AOF重写缓存。这样AOF的写入、重写就做到了隔离,保证了重写时不会阻塞写入。
- c)AOF重写流程
1.AOF重写完成会向主进程发送一个完成的信号
2.会将AOF重写缓存中的数据全部写入到文件中
3.用新的AOF文件,覆盖原有的AOF文件。
下面给出客户端请求RedisServer时,server端持久化的部分操作图解。
实例:
save 900 1 #刷新快照到硬盘中,必须满足两者要求才会触发,即900秒之后至少1个关键字发生变化。
save 300 10 #必须是300秒之后至少10个关键字发生变化。
save 60 10000 #必须是60秒之后至少10000个关键字发生变化。
stop-writes-on-bgsave-error yes #后台存储错误停止写。
rdbcompression yes #使用LZF压缩rdb文件。
rdbchecksum yes #存储和加载rdb文件时校验。
dbfilename dump.rdb #设置rdb文件名。
dir ./ #设置工作目录,rdb文件会写入该目录。
2.4 Redis数据库的实现
Redis是一个键值对数据库,称为键空间。实现这种KV形式的存储,Redis使用了两种数据结构类型:
1、字典
Redis字典使用的是哈希表实现,原本不准备详细介绍Redis哈希表的实现。但发现Redis在实现哈希表时,
提供了一个很好的rehash方案,这个方案思路很好,甚至可以衍生到其他各个应用中使用,方案的名称叫“渐进式Rehash”。
实现哈希表的方法大同小异,但为何各个开源软件总是去开发自己独有的哈希数据结构呢?
从研究PHP内核的哈希实现与Redis哈希实现,发现应用场景决定了必须定制才能更好的发挥性能。(关于PHP哈希实现可以参看:PHP内核中的神器之HashTable)
a)PHP主要应用于WEB场景,在WEB场景针对单次请求数据之间是隔离的,并且哈希的数量是有限的,那么进行一次rehash也是很快的。
所以PHP内核使用阻塞形式rehash,即rehash进行中将不能对当前哈希表进行任何操作。
b)在来看Redis,常驻进程,接收客户端请求处理各项事务,并且操作的数据是相关且数据量较大的,如果使用PHP内核的那种方式就会出现:
对哈希表进行rehash时,此时将阻塞所有客户端请求,并发性能会大大下降。
初始化字典图解:

新增字典元素图解:

Rehash执行流程:
这里的rehash与Java中的hash不一样,主要不一样后面单独一篇比较redis,php,java中的hash算法。
