第五课 树与图
文章目录
- 第五课 树与图
-
- lc94.二叉树的中序遍历--简单
-
- 题目描述
- 代码展示
- lc589.N叉树的层序遍历--中等
-
- 题目描述
- 代码展示
- lc297.二叉树的序列化和反序列化--困难
-
- 题目描述
- 代码展示
- lc105.从前序与中序遍历序列构造二叉树--中等
-
- 题目描述
- 代码展示
- lc106.从中序与后序遍历序列构造二叉树--中等
-
- 题目描述
- 代码展示
- lc236.二叉树的最近公共祖先(LCA)--中等
-
- 题目描述
- 代码展示
- lc207.课程表--中等
-
- 题目描述
- 代码展示
- lc210.课程表II--中等
-
- 题目描述
- 代码展示
- lc684.冗余连接--中等
-
- 题目描述
- 代码展示
第五课 树与图
lc94.二叉树的中序遍历–简单
题目描述
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
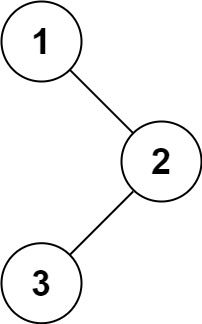
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
代码展示
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void inorder(TreeNode* root, vector<int>& res) {
if (!root) {
return;
}
inorder(root->left, res);
res.push_back(root->val);
inorder(root->right, res);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
inorder(root, res);
return res;
}
};
lc589.N叉树的层序遍历–中等
题目描述
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
代码展示
/*
// Definition for a Node.
class Node {
public:
int val;
vector children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public: //广度优先搜索
vector<vector<int>> levelOrder(Node* root) {
if (!root) {
return {};
}
vector<vector<int>> ans;
queue<Node*> q;
q.push(root);
while (!q.empty()) {
int cnt = q.size();
vector<int> level;
for (int i = 0; i < cnt; ++i) {
Node* cur = q.front();
q.pop();
level.push_back(cur->val);
for (Node* child: cur->children) {
q.push(child);
}
}
ans.push_back(move(level));
}
return ans;
}
};
lc297.二叉树的序列化和反序列化–困难
题目描述
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
示例 1:
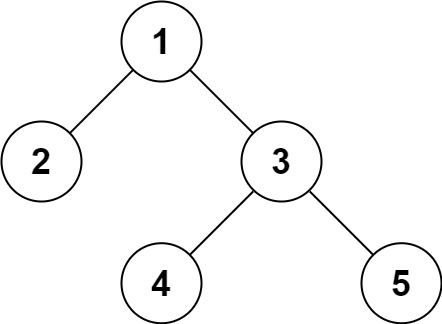
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
提示:
- 树中结点数在范围
[0, 104]内 -1000 <= Node.val <= 1000
代码展示
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
void rserialize(TreeNode* root, string& str) {
if (root == nullptr) {
str += "None,";
} else {
str += to_string(root->val) + ",";
rserialize(root->left, str);
rserialize(root->right, str);
}
}
string serialize(TreeNode* root) {
string ret;
rserialize(root, ret);
return ret;
}
TreeNode* rdeserialize(list<string>& dataArray) {
if (dataArray.front() == "None") {
dataArray.erase(dataArray.begin());
return nullptr;
}
TreeNode* root = new TreeNode(stoi(dataArray.front()));
dataArray.erase(dataArray.begin());
root->left = rdeserialize(dataArray);
root->right = rdeserialize(dataArray);
return root;
}
TreeNode* deserialize(string data) {
list<string> dataArray;
string str;
for (auto& ch : data) {
if (ch == ',') {
dataArray.push_back(str);
str.clear();
} else {
str.push_back(ch);
}
}
if (!str.empty()) {
dataArray.push_back(str);
str.clear();
}
return rdeserialize(dataArray);
}
};
// Your Codec object will be instantiated and called as such:
// Codec ser, deser;
// TreeNode* ans = deser.deserialize(ser.serialize(root));
lc105.从前序与中序遍历序列构造二叉树–中等
题目描述
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
代码展示
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
unordered_map<int, int> index;
public: //递归
TreeNode* myBuildTree(const vector<int>& preorder, const vector<int>& inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) {
if (preorder_left > preorder_right) {
return nullptr;
}
// 前序遍历中的第一个节点就是根节点
int preorder_root = preorder_left;
// 在中序遍历中定位根节点
int inorder_root = index[preorder[preorder_root]];
// 先把根节点建立出来
TreeNode* root = new TreeNode(preorder[preorder_root]);
// 得到左子树中的节点数目
int size_left_subtree = inorder_root - inorder_left;
// 递归地构造左子树,并连接到根节点
// 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素
root->left = myBuildTree(preorder, inorder, preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1);
// 递归地构造右子树,并连接到根节点
// 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素
root->right = myBuildTree(preorder, inorder, preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n = preorder.size();
// 构造哈希映射,帮助我们快速定位根节点
for (int i = 0; i < n; ++i) {
index[inorder[i]] = i;
}
return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public: //迭代
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (!preorder.size()) {
return nullptr;
}
TreeNode* root = new TreeNode(preorder[0]);
stack<TreeNode*> stk;
stk.push(root);
int inorderIndex = 0;
for (int i = 1; i < preorder.size(); ++i) {
int preorderVal = preorder[i];
TreeNode* node = stk.top();
if (node->val != inorder[inorderIndex]) {
node->left = new TreeNode(preorderVal);
stk.push(node->left);
}
else {
while (!stk.empty() && stk.top()->val == inorder[inorderIndex]) {
node = stk.top();
stk.pop();
++inorderIndex;
}
node->right = new TreeNode(preorderVal);
stk.push(node->right);
}
}
return root;
}
};
lc106.从中序与后序遍历序列构造二叉树–中等
题目描述
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
代码展示
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
int post_idx;
unordered_map<int, int> idx_map;
public: //递归
TreeNode* helper(int in_left, int in_right, vector<int>& inorder, vector<int>& postorder){
// 如果这里没有节点构造二叉树了,就结束
if (in_left > in_right) {
return nullptr;
}
// 选择 post_idx 位置的元素作为当前子树根节点
int root_val = postorder[post_idx];
TreeNode* root = new TreeNode(root_val);
// 根据 root 所在位置分成左右两棵子树
int index = idx_map[root_val];
// 下标减一
post_idx--;
// 构造右子树
root->right = helper(index + 1, in_right, inorder, postorder);
// 构造左子树
root->left = helper(in_left, index - 1, inorder, postorder);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
// 从后序遍历的最后一个元素开始
post_idx = (int)postorder.size() - 1;
// 建立(元素,下标)键值对的哈希表
int idx = 0;
for (auto& val : inorder) {
idx_map[val] = idx++;
}
return helper(0, (int)inorder.size() - 1, inorder, postorder);
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public: //迭代
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (postorder.size() == 0) {
return nullptr;
}
auto root = new TreeNode(postorder[postorder.size() - 1]);
auto s = stack<TreeNode*>();
s.push(root);
int inorderIndex = inorder.size() - 1;
for (int i = int(postorder.size()) - 2; i >= 0; i--) {
int postorderVal = postorder[i];
auto node = s.top();
if (node->val != inorder[inorderIndex]) {
node->right = new TreeNode(postorderVal);
s.push(node->right);
} else {
while (!s.empty() && s.top()->val == inorder[inorderIndex]) {
node = s.top();
s.pop();
inorderIndex--;
}
node->left = new TreeNode(postorderVal);
s.push(node->left);
}
}
return root;
}
};
lc236.二叉树的最近公共祖先(LCA)–中等
题目描述
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
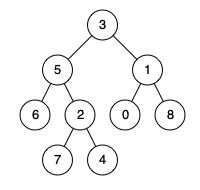
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
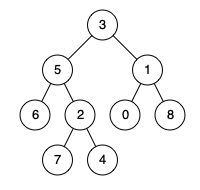
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
提示:
- 树中节点数目在范围
[2, 105]内。 -109 <= Node.val <= 109- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
代码展示
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public: //递归
TreeNode* ans;
bool dfs(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == nullptr) return false;
bool lson = dfs(root->left, p, q);
bool rson = dfs(root->right, p, q);
if ((lson && rson) || ((root->val == p->val || root->val == q->val) && (lson || rson))) {
ans = root;
}
return lson || rson || (root->val == p->val || root->val == q->val);
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
dfs(root, p, q);
return ans;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public: //存储父节点
unordered_map<int, TreeNode*> fa;
unordered_map<int, bool> vis;
void dfs(TreeNode* root){
if (root->left != nullptr) {
fa[root->left->val] = root;
dfs(root->left);
}
if (root->right != nullptr) {
fa[root->right->val] = root;
dfs(root->right);
}
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
fa[root->val] = nullptr;
dfs(root);
while (p != nullptr) {
vis[p->val] = true;
p = fa[p->val];
}
while (q != nullptr) {
if (vis[q->val]) return q;
q = fa[q->val];
}
return nullptr;
}
};

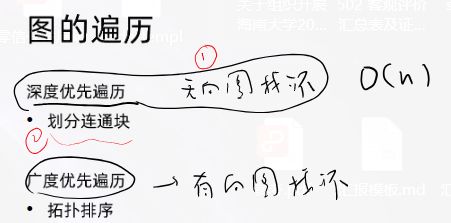
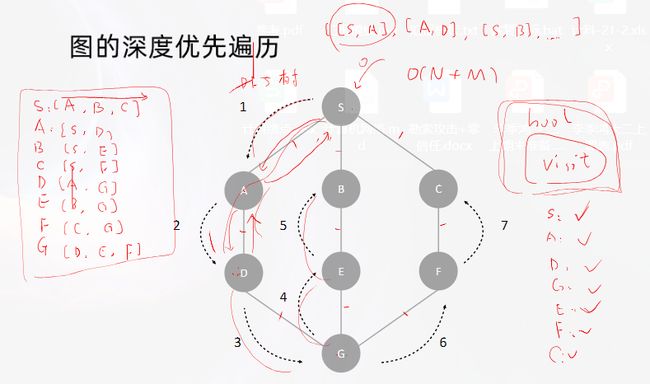

lc207.课程表–中等
题目描述
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
代码展示
class Solution {
private:
vector<vector<int>> edges;
vector<int> visited;
bool valid = true;
public: //深度优先搜索
void dfs(int u) {
visited[u] = 1;
for (int v: edges[u]) {
if (visited[v] == 0) {
dfs(v);
if (!valid) {
return;
}
}
else if (visited[v] == 1) {
valid = false;
return;
}
}
visited[u] = 2;
}
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
edges.resize(numCourses);
visited.resize(numCourses);
for (const auto& info: prerequisites) {
edges[info[1]].push_back(info[0]);
}
for (int i = 0; i < numCourses && valid; ++i) {
if (!visited[i]) {
dfs(i);
}
}
return valid;
}
};
class Solution {
private:
vector<vector<int>> edges;
vector<int> indeg;
public: //广度优先搜索
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
edges.resize(numCourses);
indeg.resize(numCourses);
for (const auto& info: prerequisites) {
edges[info[1]].push_back(info[0]);
++indeg[info[0]];
}
queue<int> q;
for (int i = 0; i < numCourses; ++i) {
if (indeg[i] == 0) {
q.push(i);
}
}
int visited = 0;
while (!q.empty()) {
++visited;
int u = q.front();
q.pop();
for (int v: edges[u]) {
--indeg[v];
if (indeg[v] == 0) {
q.push(v);
}
}
}
return visited == numCourses;
}
};
lc210.课程表II–中等
题目描述
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
输出:[0,2,1,3]
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
示例 3:
输入:numCourses = 1, prerequisites = []
输出:[0]
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- 所有
[ai, bi]互不相同
代码展示
class Solution {
private:
// 存储有向图
vector<vector<int>> edges;
// 标记每个节点的状态:0=未搜索,1=搜索中,2=已完成
vector<int> visited;
// 用数组来模拟栈,下标 0 为栈底,n-1 为栈顶
vector<int> result;
// 判断有向图中是否有环
bool valid = true;
public: //深度优先搜索
void dfs(int u) {
// 将节点标记为「搜索中」
visited[u] = 1;
// 搜索其相邻节点
// 只要发现有环,立刻停止搜索
for (int v: edges[u]) {
// 如果「未搜索」那么搜索相邻节点
if (visited[v] == 0) {
dfs(v);
if (!valid) {
return;
}
}
// 如果「搜索中」说明找到了环
else if (visited[v] == 1) {
valid = false;
return;
}
}
// 将节点标记为「已完成」
visited[u] = 2;
// 将节点入栈
result.push_back(u);
}
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
edges.resize(numCourses);
visited.resize(numCourses);
for (const auto& info: prerequisites) {
edges[info[1]].push_back(info[0]);
}
// 每次挑选一个「未搜索」的节点,开始进行深度优先搜索
for (int i = 0; i < numCourses && valid; ++i) {
if (!visited[i]) {
dfs(i);
}
}
if (!valid) {
return {};
}
// 如果没有环,那么就有拓扑排序
// 注意下标 0 为栈底,因此需要将数组反序输出
reverse(result.begin(), result.end());
return result;
}
};
class Solution {
private:
// 存储有向图
vector<vector<int>> edges;
// 存储每个节点的入度
vector<int> indeg;
// 存储答案
vector<int> result;
public: //广度优先搜索
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
edges.resize(numCourses);
indeg.resize(numCourses);
for (const auto& info: prerequisites) {
edges[info[1]].push_back(info[0]);
++indeg[info[0]];
}
queue<int> q;
// 将所有入度为 0 的节点放入队列中
for (int i = 0; i < numCourses; ++i) {
if (indeg[i] == 0) {
q.push(i);
}
}
while (!q.empty()) {
// 从队首取出一个节点
int u = q.front();
q.pop();
// 放入答案中
result.push_back(u);
for (int v: edges[u]) {
--indeg[v];
// 如果相邻节点 v 的入度为 0,就可以选 v 对应的课程了
if (indeg[v] == 0) {
q.push(v);
}
}
}
if (result.size() != numCourses) {
return {};
}
return result;
}
};
lc684.冗余连接–中等
题目描述
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:

输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
示例 2:

输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的
代码展示
class Solution {
public: //并查集
int Find(vector<int>& parent, int index) {
if (parent[index] != index) {
parent[index] = Find(parent, parent[index]);
}
return parent[index];
}
void Union(vector<int>& parent, int index1, int index2) {
parent[Find(parent, index1)] = Find(parent, index2);
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
int n = edges.size();
vector<int> parent(n + 1);
for (int i = 1; i <= n; ++i) {
parent[i] = i;
}
for (auto& edge: edges) {
int node1 = edge[0], node2 = edge[1];
if (Find(parent, node1) != Find(parent, node2)) {
Union(parent, node1, node2);
} else {
return edge;
}
}
return vector<int>{};
}
};