Kafka消费者群组和负载均衡

前言
在大数据时代,消息处理成为众多企业关注的焦点。而Kafka作为一种高性能、分布式的消息系统,通过其消费者群组和负载均衡的特性,实现了高效的消息处理和可靠的数据传递。
消费者群组
Kafka的消费者群组是一种灵活而强大的机制,允许多个消费者协同工作以实现高吞吐量的消息处理。消费者群组通过订阅同一个主题的不同分区,实现消息的并行处理。当有新消息到达时,Kafka根据一定的策略将消息均匀地分配给不同的群组成员消费。
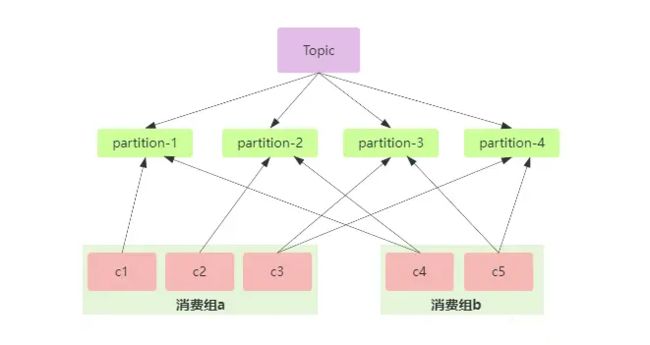
消费者群组的好处不仅体现在提高消息处理的吞吐量,还在于实现了负载均衡。消费者群组中的每个消费者将被分配到不同的分区上,这样每个消费者只需处理部分消息,大大减轻了单个消费者的负担,提高了整体的处理效率。
消费模式
发布订阅模式
顾名思义就是生产者发布消息以后,消费者订阅对应的主题分区,然后进行消费,它是一对多的,就像本号,一个订阅号会有很多人关注,当我们发布一篇文章,各位关注的帅哥美女都能收到。
那么kafka的发布订阅模式怎么实现的呢?
很简单,就是不同的消费组就能实现发布订阅模式,在上面我们说了一个分区只能被同一个消费组内的消费者消费,那么我们使用不同的消费组的消费者消费同一个分区就行了,这就实现了发布订阅模式,假如有三个消费组a,b,c的消费者c1,c2,c3消费同一个分区,在kafka中使用groupId来表示消费组,如果所有的消费者的groupId都设置一样,那么他们就属于同一个消费组,具体如下图:
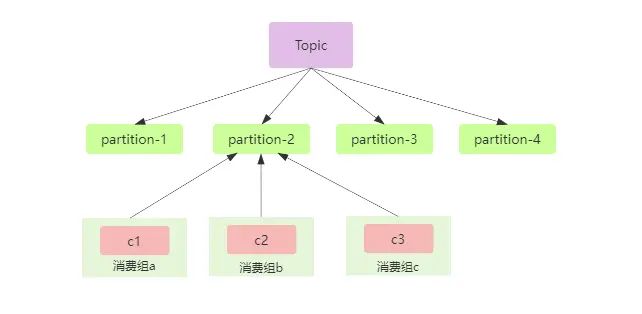
发布订阅模式的应用场景有很多,比如下游有很多服务都需要使用同一份数据,如果通过编码的方式来实现的话,可以通过RPC方式来调用,但是就会造成系统的耦合,使用消息中间件的话,上游只管投递消息,下游服务订阅后,就可以消费到消息,大大降低了耦合。
点对点模式
点对点模式就是一对一模式,如微信、QQ的两个人聊天,在kafka中要使用点对点模式,那么我们还是要回到一个分区只能被同一个消费组内的消费者消费这个问题上,我们创建了一个消费组,每个分区的数据只能被这个消费组内的消费者消息,就实现了点对点模式。 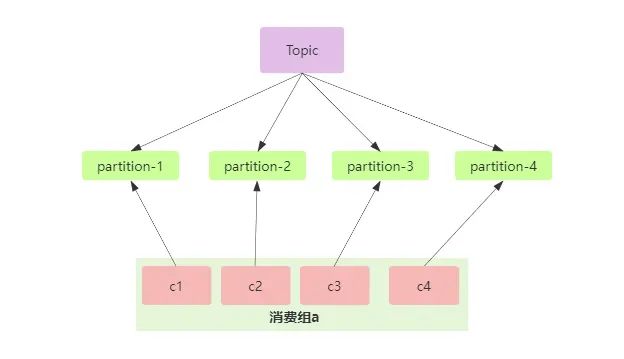
点对点的应用场景也很多,因为它的数据只能被一个消费者使用,比如可以削峰,比如上游服务发送了很多数据过来,如果下游服务的就只有一个消费者实例,那么就可能造成消息的积压,这时候就可以多开几个消费者实例一起消费,就加快了消息的消费速度,不过也得考虑一些因素,比如消息的顺序。
负载均衡
在Kafka中,负载均衡是指将消费者群组的负载均匀地分配给不同的消费者,以实现最大化的利用。Kafka通过内置的负载均衡算法,自动监测和管理消费者的状态,确保消息能够被高效地分发和处理。
下面是几种常见的负载均衡策略的详细解释:
- Round-robin(轮询): 这是最简单也是最常见的负载均衡策略。当有新的消费者加入消费者群组或者有分区需要重新分配时,Kafka按照轮询的方式将分区依次分配给消费者实例。这意味着每个消费者实例依次接收到一个分区,然后循环往复。轮询策略适用于消费者实例处理能力相当的情况。
import org.apache.kafka.clients.consumer.RangeAssignor;
import org.apache.kafka.common.Cluster;
public class RoundRobinAssignor implements RangeAssignor {
@Override
public Map> assign(Cluster metadata, Map assignments) {
// 对metadata中的所有分区按照字典序排序
List sortedPartitions = metadata.partitions()
.stream()
.sorted(Comparator.comparing(PartitionInfo::toString))
.collect(Collectors.toList());
// 将所有消费者节点按照字典序排序
List sortedConsumers = assignments.entrySet()
.stream()
.sorted(Comparator.comparing(Map.Entry::getKey))
.map(Map.Entry::getKey)
.collect(Collectors.toList());
// 平均分配所有分区给所有消费者
Map> result = new HashMap<>();
for (int i = 0; i < sortedConsumers.size(); i++) {
String consumerId = sortedConsumers.get(i);
List consumerPartitions = new ArrayList<>();
for (int j = i; j < sortedPartitions.size(); j += sortedConsumers.size()) {
PartitionInfo partitionInfo = sortedPartitions.get(j);
TopicPartition partition = new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
consumerPartitions.add(partition);
}
result.put(consumerId, consumerPartitions);
}
return result;
}
}
- Range(范围): 这种策略会将主题分区根据分区ID的范围进行分配。每个消费者实例被分配一定范围的分区。例如,如果一个主题有10个分区,而消费者群组有4个消费者实例,则第一个消费者实例被分配分区0-2,第二个消费者实例被分配分区3-5,依此类推。范围策略适用于消费者实例的处理能力不同的情况,可以更合理地分配负载。
import org.apache.kafka.clients.consumer.RangeAssignor;
import org.apache.kafka.common.Cluster;
public class RangeAssignor implements RangeAssignor {
@Override
public Map> assign(Cluster metadata, Map assignments) {
// 对metadata中的所有分区按照分区ID范围排序
List sortedPartitions = metadata.partitions()
.stream()
.sorted(Comparator.comparing(PartitionInfo::partition))
.collect(Collectors.toList());
// 计算每个消费者节点应该分配哪些分区
Map> result = new HashMap<>();
int consumerCount = assignments.size();
int maxPartitionId = sortedPartitions.get(sortedPartitions.size() - 1).partition();
for (Map.Entry entry : assignments.entrySet()) {
String consumerId = entry.getKey();
int consumerIndex = entry.getValue();
List consumerPartitions = new ArrayList<>();
int startPartition = maxPartitionId;
for (int i = 0; i < sortedPartitions.size(); i++) {
PartitionInfo partitionInfo = sortedPartitions.get(i);
TopicPartition partition = new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
if (i % consumerCount == consumerIndex) {
consumerPartitions.add(partition);
startPartition = partitionInfo.partition();
} else if (partitionInfo.partition() <= startPartition) {
consumerPartitions.add(partition);
}
}
result.put(consumerId, consumerPartitions);
}
return result;
}
}
-
Capacity-based(基于处理能力): 这种负载均衡策略根据消费者实例的处理能力来进行分配。在消费者实例加入消费者群组或者分区需要重新分配时,Kafka会根据每个消费者实例的处理能力(例如,每秒处理消息的数量)来动态调整分配。较强的消费者实例会被分配更多的分区,以确保整体上的负载均衡。基于处理能力的策略适用于消费者实例的处理能力差异较大的情况。
Kafka 并没有内置的 Capacity-based 策略,但你可以根据自己的需求来实现这个策略。Capacity-based 策略是根据每个消费者的处理能力和负载情况来分配分区,以实现负载均衡和最大化处理能力。
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.*;
public class CapacityBasedConsumerExample {
public static void main(String[] args) {
// 假设有3个消费者,每个消费者的处理能力为3
int numConsumers = 3;
int maxCapacity = 3;
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singleton("my-topic"));
try {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
// 模拟消费者的处理时间
// 这里假设消费者处理一条消息需要1秒
Thread.sleep(1000);
System.out.println("Partition: " + record.partition() +
", Offset: " + record.offset() +
", Key: " + record.key() +
", Value: " + record.value());
}
// 手动提交消费位移
consumer.commitSync();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
在示例代码中,我们假设有3个消费者,并且每个消费者的处理能力为3个消息/秒(通过模拟消费者处理时间来实现)。然后,我们使用 poll() 方法从 Kafka 服务器获取消息,并在消费每条消息时进行处理操作。在这里,通过 Thread.sleep(1000) 来模拟每条消息的处理时间。
请注意,这里的例子只是一个模拟,实际的 Capacity-based 策略可能更加复杂,涉及更多因素,如消费者的网络状况、处理能力的评估和动态调整等。
- Sticky(粘性): 粘性负载均衡策略会尽量将同一分区分配给同一个消费者实例,以避免消息的重新分配。当消费者实例离线或者新的消费者加入时,分区再平衡会尽量将原来分配给该消费者的分区分配给它。这可以确保消费者实例在处理分区时保持状态的连续性,适用于一些需要有序处理消息的场景。 Kafka 没有内置的 Sticky 策略,但你可以根据自己的需求来实现这个策略。
下面是一个简单的示例代码,展示了如何实现 Sticky 策略:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.*;
public class StickyConsumerExample {
public static void main(String[] args) {
// 假设有3个消费者和6个分区
int numConsumers = 3;
int numPartitions = 6;
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singleton("my-topic"));
try {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
// 根据分区和消费者数量计算消费者的索引
int consumerIndex = Integer.parseInt(record.partition()) % numConsumers;
// 获取消费者的分配信息
Set partitions = consumer.assignment();
TopicPartition currentPartition = new TopicPartition(record.topic(), record.partition());
// 如果分区没有被分配给消费者,将其分配给对应的消费者
if (!partitions.contains(currentPartition)) {
// 暂停消费者的分区分配
consumer.pause(partitions);
// 分配特定的分区给消费者
consumer.assign(Collections.singletonList(currentPartition));
// 恢复消费者的分区分配
consumer.resume(partitions);
}
System.out.println("Consumer: " + consumerIndex +
", Partition: " + record.partition() +
", Offset: " + record.offset() +
", Key: " + record.key() +
", Value: " + record.value());
}
// 手动提交消费位移
consumer.commitSync();
}
} finally {
consumer.close();
}
}
}
实现高效消息处理
利用Kafka的消费者群组和负载均衡特性,可以实现高效的消息处理。通过创建适当数量的消费者,将其组织成群组,并订阅合适的主题,可以将消息处理的负载分散到多个消费者上。
同时,消费者群组还具备一定的容错能力。当某个消费者发生故障或不可用时,其他消费者仍然可以继续处理消息,确保了系统的可靠性和连续性。
通过合理设置消费者群组和利用负载均衡算法,可以优化消息处理的性能和效率。消费者群组和负载均衡机制使得企业能够更好地应对庞大且高并发的消息流,并提供及时、可靠的数据传递服务。
总结
Kafka的消费者群组和负载均衡机制为企业提供了强大的消息处理能力。通过合理组织消费者群组,利用负载均衡算法,可以提高消息处理的吞吐量,实现高效的数据传递。这种高可扩展性和容错能力使得Kafka成为当今大数据领域中不可或缺的消息系统之一。
好货分享
顶尖架构师栈
关注回复关键字
【C01】超10G后端学习面试资源
【IDEA】最新IDEA激活工具和码及教程
【JetBrains软件名】 最新软件激活工具和码及教程
工具&码&教程
本文由 mdnice 多平台发布