Golang高级数据结构
文章目录
- Golang高级数据结构
-
- 一、channel
-
- 1、channel操作
- 2、channel应用
-
- a、停止信号
- b、任务定时
- c、解耦生产方和消费方
- d、控制并发数
- 3、channel 数据结构
- 4、创建channel
- 5、向 channel 发送数据流程
-
- 源码分析
- 6、从 channel 接收数据流程
-
- 源码分析
- 7、代码应用举例
- 8、channel关闭流程
- 二、GMP数据结构
-
- 1、G—goroutine
- 2、M—machine
- 3、P—processor
- 4、Goroutine的调度时机
- 三、Scheduler
-
- 1、什么是scheduler?
- 2、为什么要scheduler?
- 3、scheduler底层原理
- 三、function
-
- 1、函数定义
- 2、多值返回
- 3、值传递和引用传递
- 4、defer
- 5、闭包
- 四、interface
-
- 1、接口作用
-
- 代码举例【开闭原则】
- 代码举例【依赖倒转原则】
- 具体类型向接口类型赋值
- 2、接口数据结构
-
- eface
- iface
Golang高级数据结构
https://www.topgoer.cn/docs/goquestions/goquestions-1cjh2ib23tsec
https://www.topgoer.cn/docs/go-internals/go-internals-1d2ah79e6dc33
https://www.topgoer.cn/docs/golangxiuyang/golangxiuyang-1cmeep843db4u
https://blog.csdn.net/qq_41822345/article/details/123015441
一、channel
不要通过共享内存来通信,而要通过通信来实现内存共享。这就是 Go 的并发哲学,它依赖 CSP ( Communicating Sequential Processes )模型,基于 channel 实现。
大多数的编程语言的并发编程模型是基于线程和内存同步访问控制,Go 的并发编程的模型则用 goroutine 和 channel 来替代。Goroutine 和线程类似,channel 和 mutex (用于内存同步访问控制)类似。
Go 的并发原则非常优秀,目标就是简单:尽量使用 channel;随便使用goroutine。
channel 可以理解为队列,遵循先进先出的规则。
首先,我们清楚 Go 语言的线程是并发机制,不是并行机制。
并发是不同的代码块交替执行,也就是交替可以做不同的事情。
并行是不同的代码块同时执行,也就是同时可以做不同的事情。
1、channel操作
跟channel相关的操作有:初始化/读/写/关闭。channel未初始化值就是nil,未初始化的channel是不能使用的。 channel操作规则【从源码中可以体现】:
| 操作 | nil channel | closed channel | not nil, not closed channel |
|---|---|---|---|
| close【关闭channel】 | panic | panic | 正常关闭【只读的 chan 不能 close】 |
| 读: <- ch【从channel接收数据】 | 阻塞 | 读到对应类型的零值 | 阻塞或正常读取数据。非缓冲型 channel 没有等待发送者或缓冲型 channel 为空时会阻塞 |
| 写: ch <-【向channel发送数据】 | 阻塞 | panic | 阻塞或正常写入数据。非缓冲型 channel 没有等待接收者或缓冲型 channel buf 满时会被阻塞 |
- channel代码举例
// 声明不带缓冲的通道【不带缓冲的通道,进和出都会阻塞。】
ch1 := make(chan string)
// 声明带10个缓冲的通道【带缓冲的通道,进一次长度 +1,出一次长度 -1,如果长度等于缓冲长度时,再进就会阻塞。】
ch2 := make(chan string, 10)
// 声明只读通道
ch3 := make(<-chan string)
// 声明只写通道
ch4 := make(chan<- string)
//----------------------------------------------------//
func producer(ch chan string) {
fmt.Println("producer start")
ch <- "a"
ch <- "b"
ch <- "c"
ch <- "d"
fmt.Println("producer end")
}
func customer(ch chan string) {
for {
msg := <-ch
fmt.Println("customer custom:", msg)
}
}
func main() {
fmt.Println("main start")
ch := make(chan string, 3) // 声明chan
defer close(ch) // 关闭 chan
go producer(ch) // 写入 chan
go customer(ch) // 读取 chan
time.Sleep(1 * time.Second) // 主线程等待子线程执行【并发】
fmt.Println("main end")
}
/*
main start
producer start
producer end
customer custom: a
customer custom: b
customer custom: c
customer custom: d
main end
*/
2、channel应用
a、停止信号
关闭 channel 的原则:
don’t close a channel from the receiver side and don’t close a channel if the channel has multiple concurrent senders.
关闭 channel 最本质的原则:
don’t close (or send values to) closed channels.
b、任务定时
与 timer 结合,一般有两种玩法:实现超时控制,实现定期执行某个任务。
有时候,需要执行某项操作,但又不想它耗费太长时间,上一个定时器就可以搞定:
select {
case <-time.After(100 * time.Millisecond):
case <-s.stopc:
return false
}
等待 100 ms 后,如果 s.stopc 还没有读出数据或者被关闭,就直接结束。这是来自 etcd 源码里的一个例子,这样的写法随处可见。
定时执行某个任务,也比较简单:
func worker() {
ticker := time.Tick(1 * time.Second)
for {
select {
case <- ticker:
// 执行定时任务
fmt.Println("执行 1s 定时任务")
}
}
}
每隔 1 秒种,执行一次定时任务。
c、解耦生产方和消费方
服务启动时,启动 n 个 worker,作为工作协程池,这些协程工作在一个 for {} 无限循环里,从某个 channel 消费工作任务并执行:
func main() {
taskCh := make(chan int, 100)
go worker(taskCh)
// 塞任务
for i := 0; i < 10; i++ {
taskCh <- i
}
// 等待 1 小时
select {
case <-time.After(time.Hour):
}
}
func worker(taskCh <-chan int) {
const N = 5
// 启动 5 个工作协程
for i := 0; i < N; i++ {
go func(id int) {
for {
task := <- taskCh
fmt.Printf("finish task: %d by worker %d\n", task, id)
time.Sleep(time.Second)
}
}(i)
}
}
d、控制并发数
有时需要定时执行几百个任务,例如每天定时按城市来执行一些离线计算的任务。但是并发数又不能太高,因为任务执行过程依赖第三方的一些资源,对请求的速率有限制。这时就可以通过 channel 来控制并发数。
下面的例子来自《Go 语言高级编程》:
var limit = make(chan int, 3)
func main() {
// …………
for _, w := range work {
go func() {
limit <- 1
w()
<-limit
}()
}
// …………
}
构建一个缓冲型的 channel,容量为 3。接着遍历任务列表,每个任务启动一个 goroutine 去完成。真正执行任务,访问第三方的动作在 w() 中完成,在执行 w() 之前,先要从 limit 中拿“许可证”,拿到许可证之后,才能执行 w(),并且在执行完任务,要将“许可证”归还。这样就可以控制同时运行的 goroutine 数。
这里,limit <- 1 放在 func 内部而不是外部,原因是:
- 如果在外层,就是控制系统 goroutine 的数量,可能会阻塞 for 循环,影响业务逻辑。
- limit 其实和逻辑无关,只是性能调优,放在内层和外层的语义不太一样。
还有一点要注意的是,如果 w() 发生 panic,那“许可证”可能就还不回去了,因此需要使用 defer 来保证。
3、channel 数据结构
代码位于$GOROOT/src/runtime/chan.go
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
// 指向底层循环数组的指针【只针对有缓冲的 channel】
buf unsafe.Pointer // points to an array of dataqsiz elements
// chan 中元素大小
elemsize uint16
// chan 是否被关闭的标志
closed uint32
// chan 中元素类型
elemtype *_type // element type
// 已发送元素在循环数组中的索引
sendx uint // send index
// 已接收元素在循环数组中的索引
recvx uint // receive index
// 等待接收的 goroutine 队列【被阻塞的 goroutine,这些 goroutine 由于尝试读取 channel 或向 channel 发送数据而被阻塞。】
recvq waitq // list of recv waiters waitq是双向链表
// 等待发送的 goroutine 队列
sendq waitq // list of send waiters waitq是双向链表
// 用来保证每个读 channel 或写 channel 的操作都是原子的。
lock mutex // lock protects all fields in hchan
}
// 等待队列,waitq是双向链表
type waitq struct {
first *sudog // sudog represents a g in a wait list,
last *sudog // sudog就是goroutine
}
recvq 存储那些尝试读取 channel 但被阻塞的 goroutine,sendq 则存储那些尝试写入 channel,但被阻塞的 goroutine。
例如,创建一个容量为 6 的,元素为 int 型的 channel 数据结构如下:
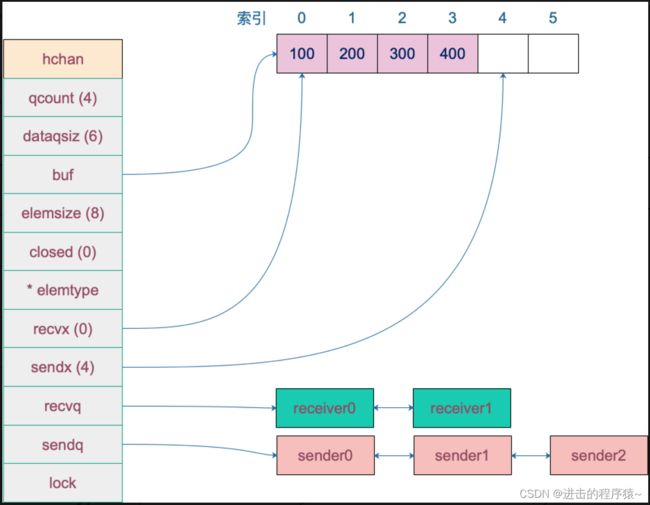
4、创建channel
从源码来看,创建的 chan 是一个指针。所以我们能在函数间直接传递 channel,而不用传递 channel 的指针。
代码位于$GOROOT/src/runtime/chan.go
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// 非缓冲channel ,只进行一次内存分配
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
// 如果 hchan 结构体中不含指针,GC 就不会扫描 chan 中的元素
case elem.ptrdata == 0:
// 分配 "hchan 结构体大小 + 缓冲大小为mem" 的内存
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 进行两次内存分配操作
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
// 循环数组长度
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
// 返回 hchan 指针
return c
}
5、向 channel 发送数据流程
channel 的发送和接收操作本质上都是 “值的拷贝”,无论是从 sender goroutine 的栈到 chan buf,还是从 chan buf 到 receiver goroutine【带缓冲的channel】,或者是直接从 sender goroutine 到 receiver goroutine【不带缓冲的channel】。
源码分析
代码位于$GOROOT/src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 如果 channel 是 nil
if c == nil {
// 非阻塞,直接返回 false,表示未发送成功
if !block {
return false
}
// 当前 goroutine 被挂起。【如果 channel 是 nil 则阻塞】
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(chansend))
}
// 对于非阻塞的 send,快速检测失败场景
// 如果 channel 未关闭且 channel 没有多余的缓冲空间。这可能是:
// 1. channel 是非缓冲型的,且等待接收队列里没有 goroutine
// 2. channel 是缓冲型的,但循环数组已经装满了元素
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 锁住 channel,并发安全
lock(&c.lock)
// 【向已关闭的 channel 发送【写】数据,panic】
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 如果接收队列里有 goroutine,直接将要发送的数据拷贝到接收 goroutine
if sg := c.recvq.dequeue(); sg != nil
// 【正常写入数据】,调用send()
// send()里调用sendDirect()【直接拷贝内存(从发送者到接收者)】
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 对于缓冲型的 channel,如果还有缓冲空间
if c.qcount < c.dataqsiz {
// qp 指向 buf 的 sendx 位置
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
// 将数据从 ep 处拷贝到 qp
typedmemmove(c.elemtype, qp, ep)
// 发送游标值加 1
c.sendx++
// 如果发送游标值等于容量值,游标值归 0
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 缓冲区的元素数量加一
c.qcount++
// 解锁
unlock(&c.lock)
return true
}
// 如果非阻塞,则直接返回错误
if !block {
unlock(&c.lock)
return false
}
// 【channel 满,发送方会被阻塞】。接下来会唤醒一个receiver接收者
// Block on the channel. Some receiver will complete our operation for us.
gp := getg()
// 会构造一个 sudog ,用于存放当前 goroutine的信息
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 将当前 goroutine 进入发送等待队列
c.sendq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
// 当前 goroutine 被挂起
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// Ensure the value being sent is kept alive until the receiver copies it out.
KeepAlive(ep)
// 从这里开始被唤醒了(channel 有机会可以发送了)
// someone woke us up.
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
// 去掉 mysg 上绑定的 channel
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
// 被唤醒后,如果 channel 关闭了,panic
panic(plainError("send on closed channel"))
}
return true
}
如果能从等待接收队列 recvq 里出队一个 sudog(代表一个 goroutine),说明此时 channel 是空的,没有元素,所以才会有等待接收者。这时会调用 send() 函数将元素直接从发送者的栈拷贝到接收者的栈,关键操作由 sendDirect 函数完成。
sendDirect() 这里涉及到一个 goroutine 直接写另一个 goroutine 栈的操作,一般而言,不同 goroutine 的栈是各自独有的。而这也违反了 GC 的一些假设。为了不出问题,写的过程中增加了写屏障,保证正确地完成写操作。这样做的好处是减少了一次内存 copy:不用先拷贝到 channel 的 buf,直接由发送者到接收者,没有中间商赚差价,效率得以提高,完美。
6、从 channel 接收数据流程
接收操作有两种写法,一种带 “ok”,表示 channel 是否关闭;一种不带 “ok”,它无法得知channel是否关闭。
// entry points for <- c from compiled code
// 返回不带 “ok”
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
// 返回带 “ok”
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
源码分析
代码位于$GOROOT/src/runtime/chan.go
// chanrecv receives on channel c and writes the received data to ep.
// ep may be nil, in which case received data is ignored.
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
// A non-nil ep must point to the heap or the caller's stack.
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// debug调试
if debugChan {
print("chanrecv: chan=", c, "\n")
}
// 如果是一个 nil 的 channel
if c == nil {
// 如果非阻塞,直接返回 (false, false)
if !block {
return
}
// 否则,接收一个 nil 的 channel,goroutine 挂起
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
// 不会执行到这一步
throw("unreachable")
}
// Fast path: check for failed non-blocking operation without acquiring the lock.
// 非阻塞并且channel是空的。 快速检测到失败,不用获取锁,快速返回
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
if empty(c) {
// The channel is irreversibly closed and empty.
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
// typedmemclr 根据类型清理相应地址的内存
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 加锁
lock(&c.lock)
//channel 已关闭,并且循环数组 buf 里没有元素
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
// typedmemclr 根据类型清理相应地址的内存
typedmemclr(c.elemtype, ep)
}
// 从一个已关闭的 channel 接收,selected 会返回true,received返回 false
return true, false
}
// 如果有等待发送的队列,说明 channel 已经满了,要么是非缓冲型的 channel,要么是缓冲型的 channel,但 buf 满了。这两种情况下都可以正常接收数据。
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 缓冲型,buf 里有元素,可以正常接收
if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 清理掉循环数组里相应位置的值
typedmemclr(c.elemtype, qp)
// 接收游标向前移动
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// buf 数组里的元素个数减 1
c.qcount--
// 解锁
unlock(&c.lock)
return true, true
}
if !block {
// 非阻塞接收,解锁。selected 返回 false,因为没有接收到值
unlock(&c.lock)
return false, false
}
// 阻塞的接收
// no sender available: block on this channel.
gp := getg()
// 构造一个 sudog ,用于存放当前 goroutine的信息
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
// 将当前 goroutine 进入channel 的接收等待队列
c.recvq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
// 当前 goroutine 被挂起
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// 从这里开始被唤醒了(channel 有机会可以接收了)
// someone woke us up
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
// 去掉 mysg 上绑定的 channel
mysg.c = nil
releaseSudog(mysg)
return true, success
}
如果有等待发送的队列,说明 channel 已经满了,要么是非缓冲型的 channel,要么是缓冲型的 channel,但 buf 满了。这两种情况下都可以正常接收数据。这时调用recv()。
在recv() 中,如果是非缓冲型的,就直接从发送者的栈拷贝到接收者的栈,调用recvDirect()。 否则,就是缓冲型 channel,而 buf 又满了的情形。说明发送游标和接收游标重合了,因此需要先找到接收游标 chanbuf(), 将该处的元素拷贝到接收地址。然后将发送者待发送的数据拷贝到接收游标处。这样就完成了接收数据和发送数据的操作。
7、代码应用举例
向 channel 发送数据 和 从 channel 接收数据的过程均会使用下面这个例子来进行说明。
func goroutineA(a <-chan int) {
val := <- a
fmt.Println("G1 received data: ", val)
return
}
func goroutineB(b <-chan int) {
val := <- b
fmt.Println("G2 received data: ", val)
return
}
func main() {
ch := make(chan int)
go goroutineA(ch)
go goroutineB(ch)
ch <- 3
time.Sleep(time.Second)
}
上面代码的执行过程中, 首先创建了一个无缓冲的 channel,接着启动两个 goroutine,并将前面创建的 channel 传递进去。然后,向这个 channel 中发送数据 3,最后 sleep 1 秒后程序退出。
G1 和 G2 会被挂起【运行到val := <- a 之后调用了 gopark 之后,处于waiting状态】,等待 sender 的解救。直到当主协程向 ch 发送了一个元素 3 之后:
sender 发现 ch 的 recvq 里有 receiver 在等待着接收,就会出队一个 sudog【 sudog 可以看成一个 goroutine 】,把 recvq 里 first 指针的 sudog “推举”出来了,并将其加入到 P 的可运行 goroutine 队列中。
然后,sender 把发送元素拷贝到 sudog 的 elem 地址处,最后会调用 goready 将 G1 唤醒,状态变为 runnable。
当调度器光顾 G1 时,将 G1 变成 running 状态,执行 goroutineA 接下来的代码。这里其实涉及到一个协程写另一个协程栈的操作。有两个 receiver 在 channel 的一边虎视眈眈地等着,这时 channel 另一边来了一个 sender 准备向 channel 发送数据,为了高效,用不着通过 channel 的 buf “中转”一次,直接从源地址把数据 copy 到目的地址。
3 会被拷贝到 G1 栈上的某个位置,也就是 val 的地址处,保存在 elem 字段。
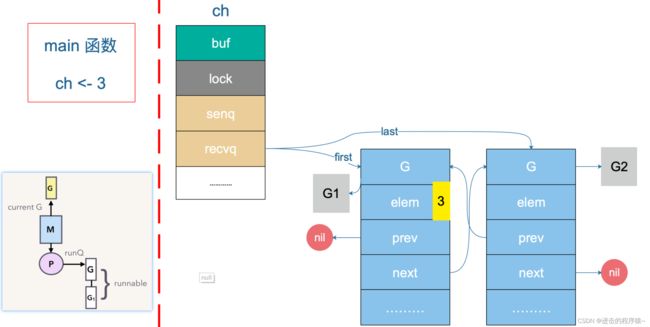
8、channel关闭流程
close 逻辑比较简单,对于一个 channel,recvq 和 sendq 中分别保存了阻塞的发送者和接收者。关闭 channel 后,对于等待接收者而言,会收到一个相应类型的零值。对于等待发送者,会直接 panic。所以,在不了解 channel 还有没有接收者的情况下,不能贸然关闭 channel。
close 函数先上一把大锁,接着把所有挂在这个 channel 上的 sender 和 receiver 全都连成一个 sudog 链表,再解锁。最后,再将所有的 sudog 全都唤醒。唤醒之后,sender 会继续执行 chansend 函数里 goparkunlock 函数之后的代码,很不幸,检测到 channel 已经关闭了,panic。receiver 则比较幸运,进行一些扫尾工作后,返回。这里,selected 返回 true,而返回值 received 则要根据 channel 是否关闭,返回不同的值。如果 channel 关闭,received 为 false,否则为 true。
二、GMP数据结构
GMP模型相关链接:https://blog.csdn.net/qq_41822345/article/details/123015441
如何起一个goroutine:通过go关键字。go关键字的实现仅仅是一个语法糖衣而已。go f(args) 可以看做 runtime.newproc(size, f, args)。
如何调度goroutine: G、P、M 是 Go 调度器的三个核心组件,各司其职。在它们精密地配合下,Go 调度器得以高效运转,这也是 Go 天然支持高并发的内在动力。
Go调度器很轻量也很简单,足以撑起goroutine的调度工作,并且让Go具有了原生(强大)并发的能力。Go调度本质是把大量的goroutine分配到少量线程上去执行,并利用多核并行,实现更强大的并发。
1、G—goroutine
G表示goroutine ,主要保存 goroutine 的一些状态信息以及 CPU 的一些寄存器的值,例如 IP 寄存器,以便在轮到本 goroutine 执行时,CPU 知道要从哪一条指令处开始执行。
- 当 goroutine 被调度起来运行时,调度器负责把 g 对象的成员变量所保存的寄存器值恢复到 CPU 的寄存器。
- 当 goroutine 被调离 CPU 时,调度器负责把 CPU 寄存器的值保存在 g 对象的成员变量之中。
代码位于代码位于$GOROOT/src/runtime/runtime2.go 。
type g struct {
// goroutine 使用的栈
stack stack // offset known to runtime/cgo
// 用于栈的扩张和收缩检查,抢占标志
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
// 当前与 g 绑定的 m
m *m // current m; offset known to arm liblink
// goroutine 的运行现场[包括 PC,SP 等寄存器]
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// wakeup 时传入的参数
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
// g 被阻塞之后的近似时间
waitsince int64 // approx time when the g become blocked
// g 被阻塞的原因
waitreason string // if status==Gwaiting
// 指向全局队列里下一个 g
schedlink guintptr
// 抢占调度标志。这个为 true 时,stackguard0 等于 stackpreempt
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
paniconfault bool // panic (instead of crash) on unexpected fault address
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
throwsplit bool // must not split stack
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
// syscall 返回之后的 cputicks,用来做 tracing
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
// 如果调用了 LockOsThread,那么这个 g 会绑定到某个 m 上
lockedm *m
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
// 创建该 goroutine 的语句的指令地址
gopc uintptr // pc of go statement that created this goroutine
// goroutine 函数的指令地址
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
// time.Sleep 缓存的定时器
timer *timer // cached timer for time.Sleep
gcAssistBytes int64
}
// 描述栈的数据结构,栈的范围:[lo, hi)
type stack struct {
// 栈顶,低地址
lo uintptr
// 栈低,高地址
hi uintptr
}
type gobuf struct {
// 存储 rsp 寄存器的值
sp uintptr
// 存储 rip 寄存器的值
pc uintptr
// 指向 goroutine
g guintptr
ctxt unsafe.Pointer // this has to be a pointer so that gc scans it
// 保存系统调用的返回值
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}
G的状态流转:
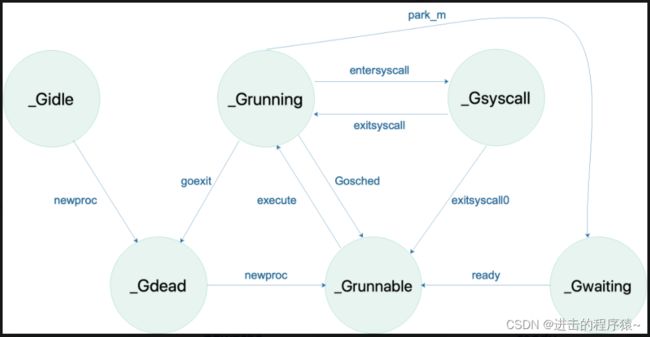
2、M—machine
M表示Machine,它代表一个工作线程,或者说系统线程。它保存了 M 自身使用的栈信息、当前正在 M 上执行的 G 信息、与之绑定的 P 信息等等。
-
G 需要调度到 M 上才能运行,M 是真正工作的人。
-
当 M 没有工作可做的时候,在它休眠前,会“自旋”地来找工作:检查全局队列,查看 network poller,试图执行 gc 任务,或者“偷”工作。
代码位于代码位于$GOROOT/src/runtime/runtime2.go 。
// m 代表工作线程,保存了自身使用的栈信息
type m struct {
// 记录工作线程(也就是内核线程)使用的栈信息。在执行调度代码时需要使用
// 执行用户 goroutine 代码时,使用用户 goroutine 自己的栈,因此调度时会发生栈的切换
g0 *g // goroutine with scheduling stack/
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
sigmask sigset // storage for saved signal mask
// 通过 tls 结构体实现 m 与工作线程的绑定
// 这里是线程本地存储
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
// 指向正在运行的 gorutine 对象
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
// 当前工作线程绑定的 p
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
id int32
mallocing int32
throwing int32
// 该字段不等于空字符串的话,要保持 curg 始终在这个 m 上运行
preemptoff string // if != "", keep curg running on this m
locks int32
softfloat int32
dying int32
profilehz int32
helpgc int32
// 为 true 时表示当前 m 处于自旋状态,正在从其他线程偷工作
spinning bool // m is out of work and is actively looking for work
// m 正阻塞在 note 上
blocked bool // m is blocked on a note
// m 正在执行 write barrier
inwb bool // m is executing a write barrier
newSigstack bool // minit on C thread called sigaltstack
printlock int8
// 正在执行 cgo 调用
incgo bool // m is executing a cgo call
fastrand uint32
// cgo 调用总计数
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 成员上,
// 其它线程通过这个 park 唤醒该工作线程
park note
// 记录所有工作线程的链表
alllink *m // on allm
schedlink muintptr
mcache *mcache
lockedg *g
createstack [32]uintptr // stack that created this thread.
freglo [16]uint32 // d[i] lsb and f[i]
freghi [16]uint32 // d[i] msb and f[i+16]
fflag uint32 // floating point compare flags
locked uint32 // tracking for lockosthread
// 正在等待锁的下一个 m
nextwaitm uintptr // next m waiting for lock
needextram bool
traceback uint8
waitunlockf unsafe.Pointer // todo go func(*g, unsafe.pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
// 工作线程 id
thread uintptr // thread handle
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
mOS
}
M 的状态变化:

3、P—processor
P表示processor,为 M 的执行提供“上下文”,保存 M 执行 G 时的一些资源,例如本地可运行 G 队列,memeory cache 等。
- 一个 M 只有绑定 P 才能执行 goroutine。
- 当 M 被阻塞时,整个 P 会被传递给其他 M ,或者说整个 P 被接管。
代码位于代码位于$GOROOT/src/runtime/runtime2.go 。
// p 保存 go 运行时所必须的资源
type p struct {
lock mutex
// 在 allp 中的索引
id int32
status uint32 // one of pidle/prunning/...
link puintptr
// 每次调用 schedule 时会加一
schedtick uint32
// 每次系统调用时加一
syscalltick uint32
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
sysmontick sysmontick // last tick observed by sysmon
// 指向绑定的 m,如果 p 是 idle 的话,那这个指针是 nil
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
racectx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
// 本地可运行的队列,不用通过锁即可访问
runqhead uint32 // 队列头
runqtail uint32 // 队列尾
// 使用数组实现的循环队列
runq [256]guintptr
// runnext 非空时,代表的是一个 runnable 状态的 G,
// 这个 G 被 当前 G 修改为 ready 状态,相比 runq 中的 G 有更高的优先级。
// 如果当前 G 还有剩余的可用时间,那么就应该运行这个 G
// 运行之后,该 G 会继承当前 G 的剩余时间
runnext guintptr
// Available G's (status == Gdead)
// 空闲的 g
gfree *g
gfreecnt int32
sudogcache []*sudog
sudogbuf [128]*sudog
tracebuf traceBufPtr
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcBgMarkWorker guintptr
gcMarkWorkerMode gcMarkWorkerMode
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad [sys.CacheLineSize]byte
}
P 的状态流转:
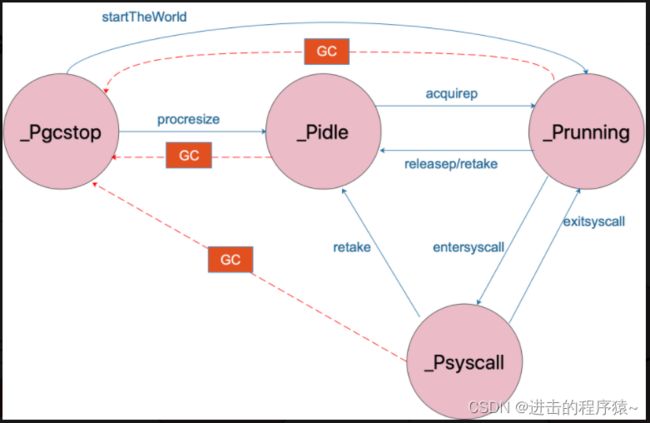
4、Goroutine的调度时机
在四种情形下,goroutine 可能会发生调度,但也并不一定会发生,只是说 Go scheduler 有机会进行调度。
| 情形 | 说明 |
|---|---|
使用关键字 go |
go 创建一个新的 goroutine,Go scheduler 会考虑调度。 |
| GC | 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度。当然,Go scheduler 还会做很多其他的调度,例如调度不涉及堆访问的 goroutine 来运行。GC 不管栈上的内存,只会回收堆上的内存。 |
| 系统调用 | 当 goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度上来。 |
| 内存同步访问 | atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走。等条件满足后(例如其他 goroutine 解锁了)还会被调度上来继续运行。 |
三、Scheduler
1、什么是scheduler?
Go 程序的执行由两层组成:Go Program,Runtime,即用户程序和运行时。它们之间通过函数调用来实现内存管理、channel 通信、goroutines 创建等功能。用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
Go scheduler 的目标: 调度 goroutines 到内核线程上。
// 保存调度器的信息
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
// 需以原子访问访问。
// 保持在 struct 顶部,以使其在 32 位系统上可以对齐
goidgen uint64
lastpoll uint64
lock mutex
// 由空闲的工作线程组成的链表
midle muintptr // idle m's waiting for work
// 空闲的工作线程数量
nmidle int32 // number of idle m's waiting for work
// 空闲的且被 lock 的 m 计数
nmidlelocked int32 // number of locked m's waiting for work
// 已经创建的工作线程数量
mcount int32 // number of m's that have been created
// 表示最多所能创建的工作线程数量
maxmcount int32 // maximum number of m's allowed (or die)
// goroutine 的数量,自动更新
ngsys uint32 // number of system goroutines; updated atomically
// 由空闲的 p 结构体对象组成的链表
pidle puintptr // idle p's
// 空闲的 p 结构体对象的数量
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
// 全局可运行的 G队列
runqhead guintptr // 队列头
runqtail guintptr // 队列尾
runqsize int32 // 元素数量
// Global cache of dead G's.
// dead G 的全局缓存
// 已退出的 goroutine 对象,缓存下来
// 避免每次创建 goroutine 时都重新分配内存
gflock mutex
gfreeStack *g
gfreeNoStack *g
// 空闲 g 的数量
ngfree int32
// Central cache of sudog structs.
// sudog 结构的集中缓存
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs of different sizes.
// 不同大小的可用的 defer struct 的集中缓存池
deferlock mutex
deferpool [5]*_defer
gcwaiting uint32 // gc is waiting to run
stopwait int32
stopnote note
sysmonwait uint32
sysmonnote note
// safepointFn should be called on each P at the next GC
// safepoint if p.runSafePointFn is set.
safePointFn func(*p)
safePointWait int32
safePointNote note
profilehz int32 // cpu profiling rate
// 上次修改 gomaxprocs 的纳秒时间
procresizetime int64 // nanotime() of last change to gomaxprocs
totaltime int64 // ∫gomaxprocs dt up to procresizetime
}
2、为什么要scheduler?
Go scheduler 可以说是 Go 运行时的一个最重要的部分。Runtime 维护所有的 goroutines,并通过 scheduler 来进行调度。Goroutines 和 threads 是独立的,但是 goroutines 要依赖 threads 才能执行。
Go 程序执行的高效和 scheduler 的调度是分不开的。
- Go加载过程
Go 程序,系统加载可执行文件大概都会经过这几个阶段:
- 从磁盘上读取可执行文件,加载到内存
- 创建进程和主线程
- 为主线程分配栈空间
- 把由用户在命令行输入的参数拷贝到主线程的栈
- 把主线程放入操作系统的运行队列等待被调度
- Go工作流
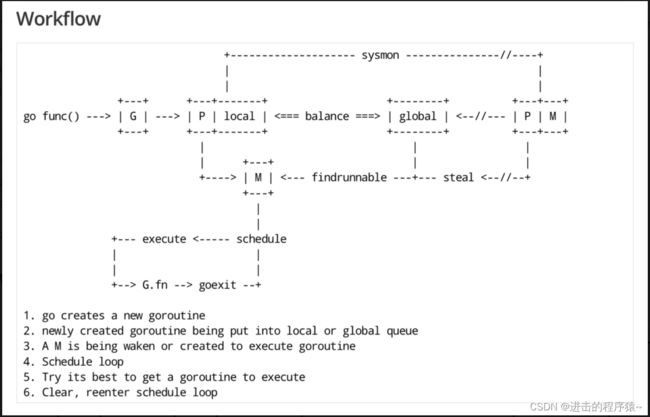
3、scheduler底层原理
实际上在操作系统看来,所有的程序都是在执行多线程。将 goroutines 调度到线程上执行,仅仅是 runtime 层面的一个概念,在操作系统之上的层面。
Runtime 起始时会启动一些 G:垃圾回收的 G,执行调度的 G,运行用户代码的 G;并且会创建一个 M 用来开始 G 的运行。随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
还有一个核心的结构体:sched,它总览全局。
Go scheduler 是 Go runtime 的一部分,它内嵌在 Go 程序里,和 Go 程序一起运行。因此它运行在用户空间,在 kernel 的上一层。和 Os scheduler 抢占式调度(preemptive)不一样,Go scheduler 采用协作式调度(cooperating)。
当然,在 Go 的早期版本,并没有 p 这个结构体,m 必须从一个全局的队列里获取要运行的 g,因此需要获取一个全局的锁,当并发量大的时候,锁就成了瓶颈。后来在大神 Dmitry Vyokov 的实现里,加上了 p 结构体。每个 p 自己维护一个处于 Runnable 状态的 g 的队列,解决了原来的全局锁问题。
Go scheduler 的核心思想是:
- reuse threads;
- 限制同时运行(不包含阻塞)的线程数为 N,N 等于 CPU 的核心数目;
- 线程私有的 runqueues,并且可以从其他线程 stealing goroutine 来运行,线程阻塞后,可以将 runqueues 传递给其他线程。
Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚。
三、function
1、函数定义
func function_name(arg1, arg2 int) (ret1, ret2 int) {
// 函数体 【函数定义的代码集合】
return value1, value2 // 返回多个值
}
- 函数用
func声明。 - 函数可以有零个、一个或多个参数,需要有参数类型,用
,分割。 - 函数可以有零个、一个或多个返回值,需要有返回值类型,用
,分割。 - 函数体是指由函数定义的代码集合。
2、多值返回
为了实现多值返回,Go是使用栈空间来返回值的。
函数 function_name 调用前其内存布局是这样的:
为ret2保留空位
为ret1保留空位
参数3
参数2
参数1 <-SP
调用之后变为:【 Go在被调函数中对参数值的修改是会返回到调用函数中的,从而返回ret1和ret2 】
为ret2保留空位
为ret1保留空位
参数2
参数1 <-FP
保存PC <-SP
f的栈
...
3、值传递和引用传递
值传递 是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递 是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
4、defer
defer在声明时不会立刻去执行,而是在函数 return 后去执行的。它的主要应用场景有异常处理、记录日志、清理数据、释放资源 等。
defer实现原理:defer f(args) 可以看做 runtime.deferproc。
在defer出现的地方,插入了指令call runtime.deferproc,然后在函数返回之前的地方,插入指令call runtime.deferreturn。
goroutine的控制结构中,有一张表记录defer,调用runtime.deferproc时会将需要defer的表达式记录在表中,而在调用runtime.deferreturn的时候,则会依次从defer表中出栈并执行。
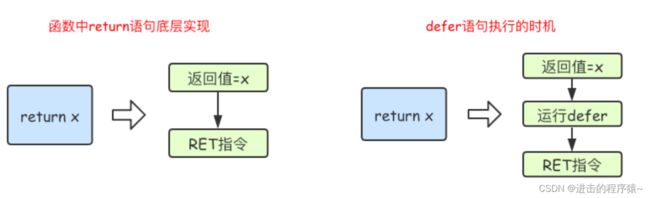
要理解:return 语句并不是一条原子指令! 它分为给返回值赋值和RET指令两步。
所以函数返回的过程是这样的:先给返回值赋值,然后调用defer表达式,最后才是返回到调用函数中。
其实使用defer时,用一个简单的转换规则改写一下,就不会迷糊了。改写规则是将return语句拆成两句写,return xxx会被改写成:
返回值 = xxx
调用defer函数
空的return
先举三个列子,下面3个函数输出是什么?【在心里跑出结果试试】
func f() (result int) {
defer func() {
result++
}()
return 0
}
func f() (r int) {
t := 5
defer func() {
t = t + 5
}()
return t
}
func f() (r int) {
defer func(r int) {
r = r + 5
}(r)
return 1
}
//------------------------------结论---------------------------------//
// 上面3个例子可以改写成如下:
func f() (result int) {
result = 0 //return语句不是一条原子调用,return xxx其实是赋值+ret指令
func() { //defer被插入到return之前执行,也就是赋返回值和ret指令之间
result++
}()
return
}
/*
1
*/
func f() (r int) {
t := 5
r = t //赋值指令
func() { //defer被插入到赋值与返回之间执行,这个例子中返回值r没被修改过
t = t + 5
}
return //空的return指令
}
/*
5
*/
func f() (r int) {
r = 1 //给返回值赋值
func(r int) { //这里改的r是传值传进去的r,不会改变要返回的那个r值
r = r + 5
}(r)
return //空的return
}
/*
1
*/
结论:return 语句并不是原子指令。
func calc(index string, a, b int) int {
ret := a + b
fmt.Println(index, a, b, ret)
return ret
}
func main() {
x := 1
y := 2
defer calc("A", x, calc("B", x, y)) // defer 调用的函数,参数的值在 defer 定义时就确定
x = 3
defer calc("C", x, calc("D", x, y))
y = 4
}
/*
B 1 2 3
D 3 2 5
C 3 5 8
A 1 3 4
*/
结论:defer 函数定义的顺序 与 实际执的行顺序是相反的,也就是最先声明的最后才执行。
defer 调用的函数,参数的值在 defer 定义时就确定。
func main() {
defer fmt.Println("1")
fmt.Println("main")
os.Exit(0)
}
/*
main
*/
结论:当os.Exit()方法退出程序时,defer不会被执行。
func main() {
GoA()
time.Sleep(1 * time.Second)
fmt.Println("main")
}
func GoA() {
defer (func(){
if err := recover(); err != nil {
fmt.Println("panic:" + fmt.Sprintf("%s", err))
}
})()
go GoB() // GoB() panic 捕获不到。
//GoB() // GoB() panic 可以捕获。
}
func GoB() {
panic("error")
}
结论:defer 只对当前协程有效。
5、闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)。 闭包=函数+引用环境
func main() {
var a = 1
var b = 2
defer func() {
fmt.Println(a + b) //defer 函数内部所使用的变量的值需要在这个函数运行时才确定
}()
a = 2
fmt.Println("main")
}
/*
main
4
*/
func main() {
var a = 1
var b = 2
defer func(a int, b int) { //defer 调用的函数,参数的值在 defer 定义时就确定
fmt.Println(a + b)
}(a, b)
a = 2
fmt.Println("main")
}
/*
main
3
*/
结论:
闭包获取变量相当于引用传递,而非值传递。【defer 函数内部所使用的变量的值需要在这个函数运行时才确定】
传参是值复制。【defer 调用的函数,参数的值在 defer 定义时就确定】
四、interface
1、接口作用
interface 是Go语言中最成功的设计之一,可以理解为 一种类型的规范或者约定 。 它使得Go这样的静态语言拥有了一定的动态性,但却又不损失静态语言在类型安全方面拥有的编译时检查的优势。
如何理解 interface 是 go 语言的一大特性,只要牢记以下四点:
- interface 是方法或行为声明的集合。
- interface接口方式实现比较隐性,任何类型的对象实现interface所包含的全部方法,则表明该类型实现了该接口。
- interface可以作为一种数据类型,实现了该接口的任何对象都可以给对应的接口类型变量赋值。
- interface可以作为一种通用的类型,其他类型变量可以给interface声明的变量赋值。
go语言并没有面向对象的相关概念, interface 的设计是为了满足一些面向对象的编程思想。 软件设计的最高目标:高内聚、低耦合。 其中有一个设计原则叫开闭原则。
Go中 interface 的设计可以使代码:对扩展开放,对修改关闭【开闭原则】,依赖于接口而不是实现【依赖倒转】,对优先使用组合而不是继承【合成复用】,这些是程序抽象的基本原则。
代码举例【开闭原则】
import "fmt"
//抽象的银行业务员
type AbstractBanker interface{
DoBusi() //抽象的处理业务接口
}
//存款的业务员
type SaveBanker struct {
//AbstractBanker
}
func (sb *SaveBanker) DoBusi() {
fmt.Println("进行了存款")
}
//转账的业务员
type TransferBanker struct {
//AbstractBanker
}
func (tb *TransferBanker) DoBusi() {
fmt.Println("进行了转账")
}
//支付的业务员
type PayBanker struct {
//AbstractBanker
}
func (pb *PayBanker) DoBusi() {
fmt.Println("进行了支付")
}
func main() {
//进行存款
sb := &SaveBanker{}
sb.DoBusi()
//进行转账
tb := &TransferBanker{}
tb.DoBusi()
//进行支付
pb := &PayBanker{}
pb.DoBusi()
}
go中没有明确的说明实现某个接口(即没有implements关键字),那是如何知道具体实现了哪个接口呢?其实这个工作是在运行时解决的,也就是说在运行时才判断。在使用 interface 时不需要显式在 struct 上声明要实现哪个 interface ,只需要实现对应 interface 中的方法即可,go 会自动进行 interface 的检查,并在运行时执行从其它类型到 interface 的自动转换,即使实现了多个 interface,go 也会在使用对应 interface 时实现自动转换。
接口的最大的意义就是实现多态的思想。就是我们可以根据interface类型来设计API接口,那么这种API接口的适应能力不仅能适应当下所实现的全部模块,也适应未来实现的模块来进行调用。
多态的几个要素:
1、有interface接口,并且有接口定义的方法。
2、有子类去重写interface的接口。
3、有父类指针指向子类的具体对象。
代码举例【依赖倒转原则】
import "fmt"
//1、有interface接口,并且有接口定义的方法。
// ===== > 抽象层 < ========
type Car interface {
Run()
}
type Driver interface {
Drive(car Car)
}
//2、有子类去重写interface的接口。
// ===== > 实现层 < ========
type BenZ struct {
//...
}
func (benz * BenZ) Run() {
fmt.Println("Benz is running...")
}
type Bmw struct {
//...
}
func (bmw * Bmw) Run() {
fmt.Println("Bmw is running...")
}
type Zhang_3 struct {
//...
}
func (zhang3 *Zhang_3) Drive(car Car) {
fmt.Println("Zhang3 drive car")
car.Run()
}
type Li_4 struct {
//...
}
func (li4 *Li_4) Drive(car Car) {
fmt.Println("li4 drive car")
car.Run()
}
// ===== > 业务逻辑层 < ========
func main() {
//张3 开 宝马
var bmw Car
bmw = &Bmw{} //3、有父类指针指向子类的具体对象。
var zhang3 Driver
zhang3 = &Zhang_3{}
zhang3.Drive(bmw)
//李4 开 奔驰
var benz Car
benz = &BenZ{}
var li4 Driver
li4 = &Li_4{}
li4.Drive(benz)
}
具体类型向接口类型赋值
将具体类型数据赋值给 interface{} 这样的抽象类型,中间会涉及到类型转换操作。从接口类型转换为具体类型(也就是反射),也涉及到了类型转换。
如果是转换成空接口eface,这个过程比较简单,就是返回一个Eface,将Eface中的data指针指向原型数据,type指针会指向数据的Type结构体。
如果是转换成非空接口iface,会复杂一些。中间涉及了一道检测,该类型必须要实现了接口中声明的所有方法才可以进行转换。这个检测是在编译过程中做的。【 类型转换时的检测就是比较具体类型的方法表和接口类型的方法表,看具体类型是实现了接口类型所声明的所有的方法。】
2、接口数据结构
interface实际上就是一个结构体,包含两个成员。其中一个成员是指向具体数据的指针【接口就是指针】,另一个成员中包含了类型信息。
interface在使用的过程中,共有两种表现形式 :
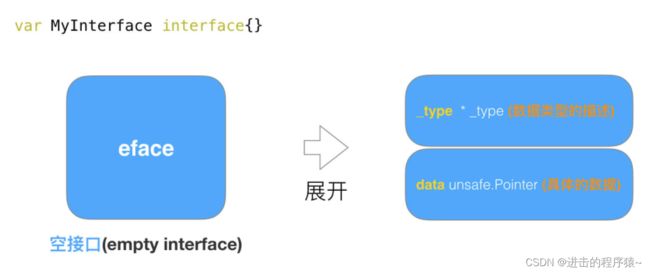
一种为空接口(empty interface),定义如下: var MyInterface interface{} 。
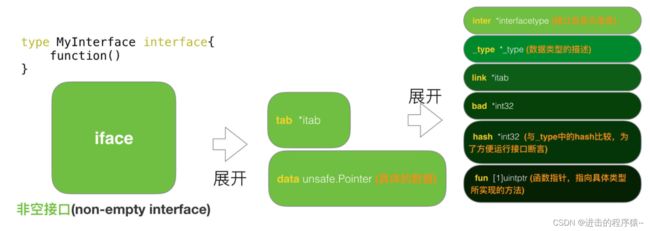
一种为非空接口(non-empty interface), 定义如下:type MyInterface interface {function()}
这两种interface类型分别用两种struct结构体表示,空接口为eface, 非空接口为iface。
在go中,想要理解接口,我们一定要想着其最终都是指针。
eface
空接口eface结构,由两个属性构成,一个是类型信息_type,一个是数据信息。
代码位于$GOROOT/src/runtime/runtime2.go
type eface struct { //空接口
_type *_type //类型信息【所有类型公共字段】
data unsafe.Pointer //指向数据的指针(go语言中特殊的指针类型unsafe.Pointer类似于c语言中的void*)
}
type _type struct {
size uintptr //类型大小
ptrdata uintptr //前缀持有所有指针的内存大小
hash uint32 //数据hash值
tflag tflag
align uint8 //对齐
fieldalign uint8 //嵌入结构体时的对齐
kind uint8 //kind 有些枚举值kind等于0是无效的
alg *typeAlg //函数指针数组,类型实现的所有方法
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte //GC相关
str nameOff
ptrToThis typeOff
}
iface
非空接口iface结构,也是由两个属性构成,一个是 itab结构,一个是数据信息。
代码位于$GOROOT/src/runtime/runtime2.go
type iface struct {
tab *itab //itab里面包含了interface的一些关键信息,比如method的具体实现。
data unsafe.Pointer //指向数据的指针
}
type itab struct {
inter *interfacetype // 接口自身的元信息,eg:package path、method等
_type *_type // 具体类型的元信息
link *itab
bad int32
hash int32 // _type里也有一个同样的hash,此处多放一个是为了方便运行接口断言
fun [1]uintptr // 函数指针,指向具体类型所实现的方法
}
代码举例,以下代码输出是?
import (
"fmt"
)
type People interface {
Show()
}
type Student struct{}
func (stu *Student) Show() {
}
func live() People {
var stu *Student
return stu
}
func main() {
if live() == nil {
fmt.Println("AAAAAAA")
} else {
fmt.Println("BBBBBBB")
}
}
/*
BBBBBBB
*/
//stu是一个指向nil的空指针,但是最后return stu 会触发匿名变量 People = stu值拷贝动作,所以最后live()放回给上层的是一个People insterface{}类型,也就是一个iface struct{}类型。 stu为nil,只是iface中的data 为nil而已。 但是iface struct{}本身并不为nil.