Elasticsearch:语义搜索快速入门
这个交互式 jupyter notebook 将使用官方 Elasticsearch Python 客户端向你介绍 Elasticsearch 的一些基本操作。 你将使用 Sentence Transformers 进行文本嵌入的语义搜索。 了解如何将传统的基于文本的搜索与语义搜索集成,形成混合搜索系统。在本示例中,我们将使用模型自带的功能对文本进行向量化,而不借助 Elasticsearch 所提供的 ingest pipeline 来进行矢量化。这样的好处是完全免费,不需要购买版权。如果你想使用 ingest pipeline 来进行向量化,请参阅文章 ”Elasticsearch:使用 huggingface 模型的 NLP 文本搜索“。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们可以选择 Elastic Stack 8.x 的安装指南来进行安装。在本博文中,我将使用最新的 Elastic Stack 8.10 来进行展示。
在安装 Elasticsearch 的过程中,我们需要记下如下的信息:

Python 安装包
在本演示中,我们将使用 Python 来进行展示。我们需要安装访问 Elasticsearch 相应的安装包 elasticsearch:
python3 -m pip install -qU sentence-transformers elasticsearch transformers我们将使用 Jupyter Notebook 来进行展示。
$ pwd
/Users/liuxg/python/elser
$ jupyter notebook创建应用并展示
设置嵌入模型
在此示例中,我们使用 all-MiniLM-L6-v2,它是 sentence_transformers 库的一部分。 你可以在 Huggingface 上阅读有关此模型的更多信息。
from sentence_transformers import SentenceTransformer
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = SentenceTransformer('all-MiniLM-L6-v2', device=device)
model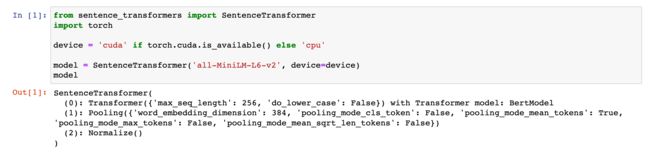
初始化 Elasticsearch 客户端
现在我们可以实例化 Elasticsearch python 客户端。我们必须提高响应的账号及证书信息:
from elasticsearch import Elasticsearch
ELASTCSEARCH_CERT_PATH = "/Users/liuxg/elastic/elasticsearch-8.10.0/config/certs/http_ca.crt"
client = Elasticsearch( ['https://localhost:9200'],
basic_auth = ('elastic', 'vXDWYtL*my3vnKY9zCfL'),
ca_certs = ELASTCSEARCH_CERT_PATH,
verify_certs = True)
print(client.info())
摄入一些数据
我们的客户端已设置并连接到我们的 Elasticsearch 部署。 现在我们需要一些数据来测试 Elasticsearch 查询的基础知识。 我们将使用包含以下字段的小型书籍索引:
titleauthorspublish_datenum_reviewspublisher
我们在当前项目的根目录下创建 books.json 文件:
books.json
[
{
"title": "The Pragmatic Programmer: Your Journey to Mastery",
"authors": ["andrew hunt", "david thomas"],
"summary": "A guide to pragmatic programming for software engineers and developers",
"publish_date": "2019-10-29",
"num_reviews": 30,
"publisher": "addison-wesley"
},
{
"title": "Python Crash Course",
"authors": ["eric matthes"],
"summary": "A fast-paced, no-nonsense guide to programming in Python",
"publish_date": "2019-05-03",
"num_reviews": 42,
"publisher": "no starch press"
},
{
"title": "Artificial Intelligence: A Modern Approach",
"authors": ["stuart russell", "peter norvig"],
"summary": "Comprehensive introduction to the theory and practice of artificial intelligence",
"publish_date": "2020-04-06",
"num_reviews": 39,
"publisher": "pearson"
},
{
"title": "Clean Code: A Handbook of Agile Software Craftsmanship",
"authors": ["robert c. martin"],
"summary": "A guide to writing code that is easy to read, understand and maintain",
"publish_date": "2008-08-11",
"num_reviews": 55,
"publisher": "prentice hall"
},
{
"title": "You Don't Know JS: Up & Going",
"authors": ["kyle simpson"],
"summary": "Introduction to JavaScript and programming as a whole",
"publish_date": "2015-03-27",
"num_reviews": 36,
"publisher": "oreilly"
},
{
"title": "Eloquent JavaScript",
"authors": ["marijn haverbeke"],
"summary": "A modern introduction to programming",
"publish_date": "2018-12-04",
"num_reviews": 38,
"publisher": "no starch press"
},
{
"title": "Design Patterns: Elements of Reusable Object-Oriented Software",
"authors": [
"erich gamma",
"richard helm",
"ralph johnson",
"john vlissides"
],
"summary": "Guide to design patterns that can be used in any object-oriented language",
"publish_date": "1994-10-31",
"num_reviews": 45,
"publisher": "addison-wesley"
},
{
"title": "The Clean Coder: A Code of Conduct for Professional Programmers",
"authors": ["robert c. martin"],
"summary": "A guide to professional conduct in the field of software engineering",
"publish_date": "2011-05-13",
"num_reviews": 20,
"publisher": "prentice hall"
},
{
"title": "JavaScript: The Good Parts",
"authors": ["douglas crockford"],
"summary": "A deep dive into the parts of JavaScript that are essential to writing maintainable code",
"publish_date": "2008-05-15",
"num_reviews": 51,
"publisher": "oreilly"
},
{
"title": "Introduction to the Theory of Computation",
"authors": ["michael sipser"],
"summary": "Introduction to the theory of computation and complexity theory",
"publish_date": "2012-06-27",
"num_reviews": 33,
"publisher": "cengage learning"
}
]$ pwd
/Users/liuxg/python/elser
$ ls
Multilingual semantic search.ipynb
NLP text search using hugging face transformer model.ipynb
Semantic search - ELSER.ipynb
Semantic search quick start.ipynb
books.json
data.json创建索引
让我们使用测试数据的正确映射创建一个 Elasticsearch 索引。
INDEX_NAME = "book_index"
if es.indices.exists(index=INDEX_NAME):
print("Deleting existing %s" % INDEX_NAME)
client.options(ignore_status=[400, 404]).indices.delete(index=INDEX_NAME)
# Define the mapping
mappings = {
"properties": {
"title_vector": {
"type": "dense_vector",
"dims": 384,
"index": "true",
"similarity": "cosine"
}
}
}
# Create the index
client.indices.create(index = INDEX_NAME, mappings = mappings)
索引测试数据
运行以下命令上传一些测试数据,其中包含该数据集中的 10 本流行编程书籍的信息。 model.encode 将使用我们之前初始化的模型将文本动态编码为向量。
import json
# Load data into a JSON object
with open('books.json') as f:
data_json = json.load(f)
print(data_json)
actions = []
for book in data_json:
actions.append({"index": {"_index": INDEX_NAME}})
# Transforming the title into an embedding using the model
book["title_vector"] = model.encode(book["title"]).tolist()
actions.append(book)
client.bulk(index=INDEX_NAME, operations=actions)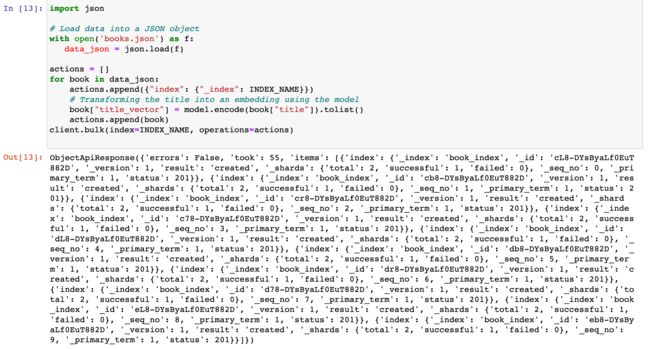
我们可以在 Kibana 中进行查看:
GET book_index/_search
漂亮地打印 Elasticsearch 响应
你的 API 调用将返回难以阅读的嵌套 JSON。 我们将创建一个名为 Pretty_response 的小函数,以从示例中返回漂亮的、人类可读的输出。
def pretty_response(response):
for hit in response['hits']['hits']:
id = hit['_id']
publication_date = hit['_source']['publish_date']
score = hit['_score']
title = hit['_source']['title']
summary = hit['_source']['summary']
publisher = hit["_source"]["publisher"]
num_reviews = hit["_source"]["num_reviews"]
authors = hit["_source"]["authors"]
pretty_output = (f"\nID: {id}\nPublication date: {publication_date}\nTitle: {title}\nSummary: {summary}\nPublisher: {publisher}\nReviews: {num_reviews}\nAuthors: {authors}\nScore: {score}")
print(pretty_output)查询
现在我们已经对书籍进行了索引,我们想要对与给定查询相似的书籍执行语义搜索。 我们嵌入查询并执行搜索。
response = client.search(index="book_index", body={
"knn": {
"field": "title_vector",
"query_vector": model.encode("Best javascript books?"),
"k": 10,
"num_candidates": 100
}
})
pretty_response(response)
过滤
过滤器上下文主要用于过滤结构化数据。 例如,使用过滤器上下文来回答以下问题:
- 该时间戳是否在 2015 年至 2016 年范围内?
- 状态字段是否设置为 “published”?
每当查询子句传递给过滤器参数(例如布尔查询中的 filter 或 must_not 参数)时,过滤器上下文就会生效。
在 Elasticsearch 文档中了解有关过滤器上下文的更多信息。
示例:关键字过滤
这是向查询添加关键字过滤器的示例。
它通过仅包含 “publisher” 字段等于 “addison-wesley” 的文档来缩小结果范围。
该代码检索类似于 “Best javascript books?” 的热门书籍。 基于他们的 title 向量,并以 “addison-wesley” 作为出版商。
response = client.search(index=INDEX_NAME, body={
"knn": {
"field": "title_vector",
"query_vector": model.encode("Best javascript books?"),
"k": 10,
"num_candidates": 100,
"filter": {
"term": {
"publisher.keyword": "addison-wesley"
}
}
}
})
pretty_response(response)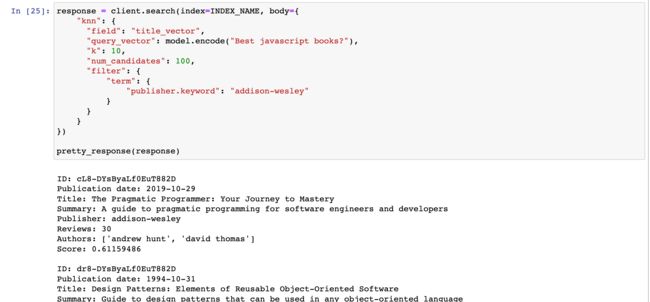
示例:高级过滤
Elasticsearch 中的高级过滤允许通过应用条件来精确细化搜索结果。 它支持多种运算符,可用于根据特定字段、范围或条件过滤结果,从而提高搜索结果的精度和相关性。 在此查询和过滤上下文示例中了解更多信息。
response = client.search(index="book_index", body={
"knn": {
"field": "title_vector",
"query_vector": model.encode("Best javascript books?"),
"k": 10,
"num_candidates": 100,
"filter": {
"bool": {
"should": [
{
"term": {
"publisher.keyword": "addison-wesley"
}
},
{
"term": {
"authors.keyword": "robert c. martin"
}
}
],
}
}
}
})
pretty_response(response)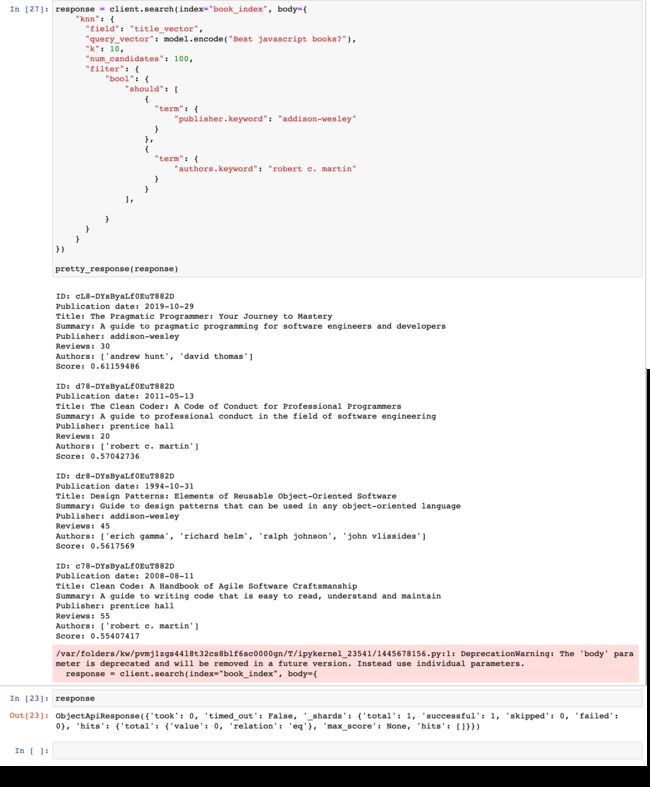
Hybrid search
在此示例中,我们正在研究两种搜索算法的组合:用于文本搜索的 BM25 和用于最近邻搜索的 HNSW。 通过结合多种排名方法,例如 BM25 和生成密集向量嵌入的 ML 模型,我们可以获得最佳排名结果。 这种方法使我们能够利用每种算法的优势并提高整体搜索性能。
倒数排名融合 (RRF) 是一种最先进的排名算法,用于组合来自不同信息检索策略的结果。 RRF 在未经校准的情况下优于所有其他排名算法。 简而言之,它支持开箱即用的一流混合搜索。
response = client.search(index="book_index", body={
"query": {
"match": {
"summary": "python"
}
},
"knn": {
"field": "title_vector",
# generate embedding for query so it can be compared to `title_vector`
"query_vector" : model.encode("python programming").tolist(),
"k": 5,
"num_candidates": 10
},
"rank": {
"rrf": {
"window_size": 100,
"rank_constant": 20
}
}
})
pretty_response(response)
最终的 jupyter 文件可以在地址下载。