Diff算法
什么是虚拟DOM
虚拟DOM是一个对象,一个什么样的对象呢?一个用来表示真实DOM的对象,要记住这句话。我举个例子,请看以下真实DOM:
<ul id="list">
<li class="item">哈哈li>
<li class="item">呵呵li>
<li class="item">嘿嘿li>
ul>
上面的模版在转换成虚拟DOM后就是下面的内容
let oldVDOM = { // 旧虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: ['哈哈']
},
{
tagName: 'li', props: { class: 'item' }, children: ['呵呵']
},
{
tagName: 'li', props: { class: 'item' }, children: ['嘿嘿']
},
]
}
这样的 DOM 结构就称之为 虚拟 DOM (Virtual Node),简称 vnode。
它的表达方式就是把每一个标签都转为一个对象,这个对象可以有三个属性:tag、props、children
- tag:必选。就是标签。也可以是组件,或者函数
- props:非必选。就是这个标签上的属性和方法
- children:非必选。就是这个标签的内容或者子节点,如果是文本节点就是字符串,如果有子节点就是数组。换句话说 如果判断 children 是字符串的话,就表示一定是文本节点,这个节点肯定没有子元素
这时候,我修改一个li标签的文本:
<ul id="list">
<li class="item">哈哈li>
<li class="item">呵呵li>
<li class="item">测试哈哈哈哈哈li> // 修改
ul>
这时候生成的新虚拟DOM为:
let newVDOM = { // 新虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: ['哈哈']
},
{
tagName: 'li', props: { class: 'item' }, children: ['呵呵']
},
{
tagName: 'li', props: { class: 'item' }, children: ['测试哈哈哈哈哈']
},
]
}
为什么要使用虚拟 DOM 呢? 看个图
如图可以看出原生 DOM 有非常多的属性和事件,就算是创建一个空div也要付出不小的代价。而使用虚拟 DOM 来提升性能的点在于 DOM 发生变化的时候,通过 diff 算法和数据改变前的 DOM 对比,计算出需要更改的 DOM,然后只对变化的 DOM 进行操作,而不是更新整个视图
在 Vue 里虚拟 DOM 的数据更新机制采用的是异步更新队列,就是把变更后的数据变装入一个数据更新的异步队列(patch),用它来做新老 vnode 对比
Diff算法
上述操作中,其实只有一个li标签修改了文本,其他都是不变的,所以没必要所有的节点都要更新,只更新这个li标签就行,Diff算法就是查出这个li标签的算法。
总结:Diff算法在 Vue 里面就是叫做 patch,是一种对比算法。对比两者是旧虚拟DOM和新虚拟DOM,对比出是哪个虚拟节点更改了,找出这个虚拟节点,并只更新这个虚拟节点所对应的真实节点,而不用更新其他数据没发生改变的节点,实现精准地更新真实DOM,进而提高效率。
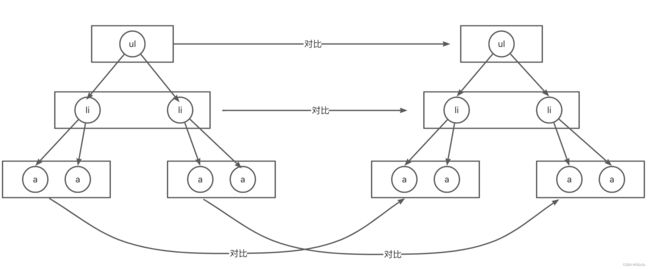
Diff同层对比
新旧虚拟DOM对比的时候,Diff算法比较只会在同层级进行, 不会跨层级比较。 所以Diff算法是:深度优先算法。 时间复杂度:O(n)
Diff对比流程
当数据改变时,会触发setter,并且通过Dep.notify去通知所有订阅者Watcher,订阅者们就会调用patch方法,给真实DOM打补丁,更新相应的视图。
newVnode和oldVnode:同层的新旧虚拟节点
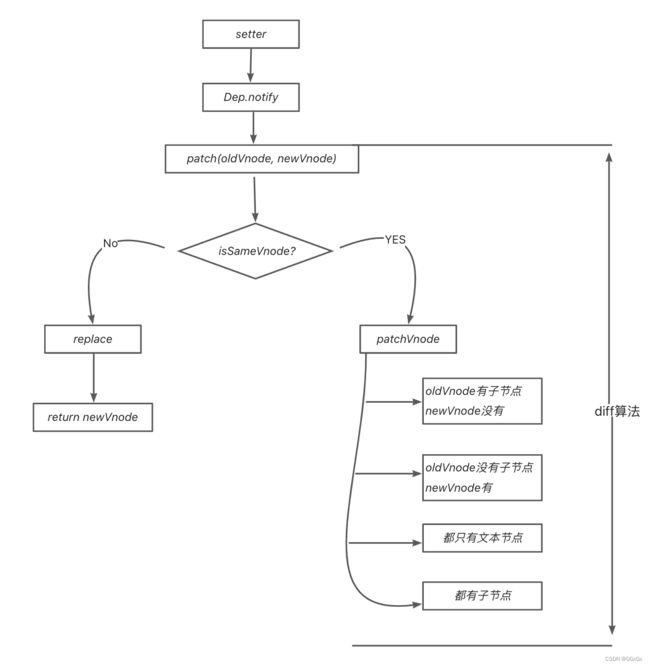
patch方法
这个方法作用就是,对比当前同层的虚拟节点是否为同一种类型的标签(同一类型的标准,下面会讲):
是:继续执行patchVnode方法进行深层比对
否:没必要比对了,直接整个节点替换成新虚拟节点
sameVnode方法
patch关键的一步就是sameVnode方法判断是否为同一类型节点,那问题来了,怎么才算是同一类型节点呢?这个类型的标准是什么呢?
咱们来看看sameVnode方法的核心原理代码,就一目了然了
function sameVnode(oldVnode, newVnode) {
return (
oldVnode.key === newVnode.key && // key值是否一样
oldVnode.tagName === newVnode.tagName && // 标签名是否一样
oldVnode.isComment === newVnode.isComment && // 是否都为注释节点
isDef(oldVnode.data) === isDef(newVnode.data) && // 是否都定义了data
sameInputType(oldVnode, newVnode) // 当标签为input时,type必须是否相同
)
}
patchVnode方法
这个函数做了以下事情:
- 找到对应的真实DOM,称为el
- 判断newVnode和oldVnode是否指向同一个对象,如果是,那么直接return
- 如果他们都有文本节点并且不相等,那么将el的文本节点设置为newVnode的文本节点。
- 如果oldVnode有子节点而newVnode没有,则删除el的子节点
- 如果oldVnode没有子节点而newVnode有,则将newVnode的子节点真实化之后添加到el
- 如果两者都有子节点,则执行updateChildren函数比较子节点,这一步很重要
updateChildren方法
这是patchVnode里最重要的一个方法,新旧虚拟节点的子节点对比,就是发生在updateChildren方法中,就是首尾指针法,新的子节点集合和旧的子节点集合,各有首尾两个指针,举个例子:
<ul>
<li>ali>
<li>bli>
<li>cli>
ul>
// 修改数据后
<ul>
<li>bli>
<li>cli>
<li>eli>
<li>ali>
ul>
那么新旧两个子节点集合以及其首尾指针为:
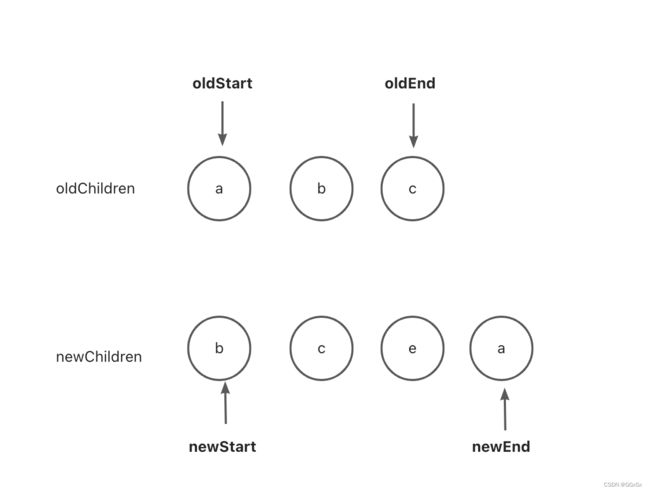
然后会进行互相进行比较,总共有五种比较情况:
1、oldStart 和 newStart 使用sameVnode方法进行比较,sameVnode(oldStart, newStart)
2、oldStart 和 newEnd 使用sameVnode方法进行比较,sameVnode(oldStart, newEnd)
3、oldEnd 和 newStart 使用sameVnode方法进行比较,sameVnode(oldEnd, newStart)
4、oldEnd 和 newEnd 使用sameVnode方法进行比较,sameVnode(oldEnd, newEnd)
5、如果以上逻辑都匹配不到,再把所有旧子节点的 key 做一个映射到旧节点下标的 key -> index 表,然后用新 vnode 的 key 去找出在旧节点中可以复用的位置。

接下来就以上面代码为例,分析一下比较的过程
分析之前,请大家记住一点,最终的渲染结果都要以newVDOM为准,这也解释了为什么之后的节点移动需要移动到newVDOM所对应的位置
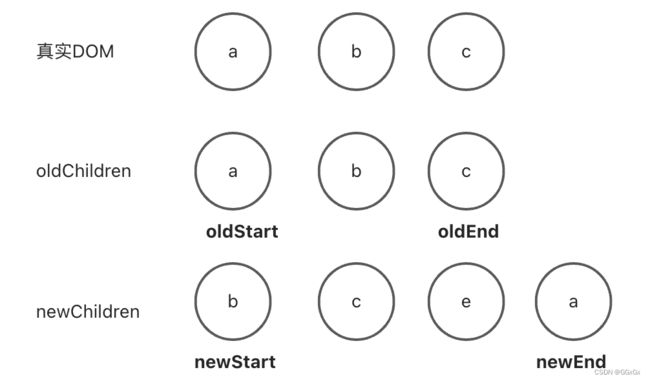
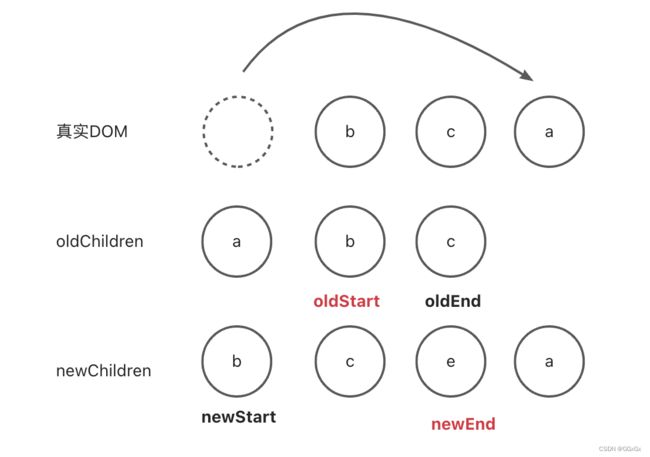
第一步
oldStart = a, oldEnd = c
newStart = b, newEnd = a
比较结果:oldStart 和 newEnd 相等,需要把节点a移动到newE所对应的位置,也就是末尾,同时oldStart++,newEnd- -
第二步
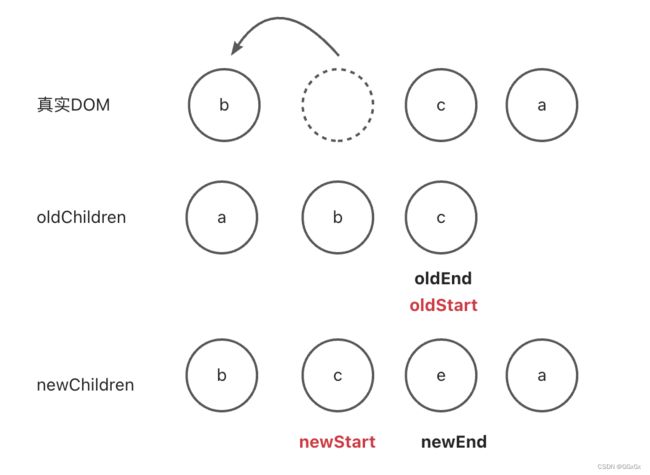
oldStart = b, oldEnd = c
newStart = b, newEnd = e
比较结果:oldStart 和 newStart相等,需要把节点b移动到newStart所对应的位置,同时oldStart++,newStart++
第三步
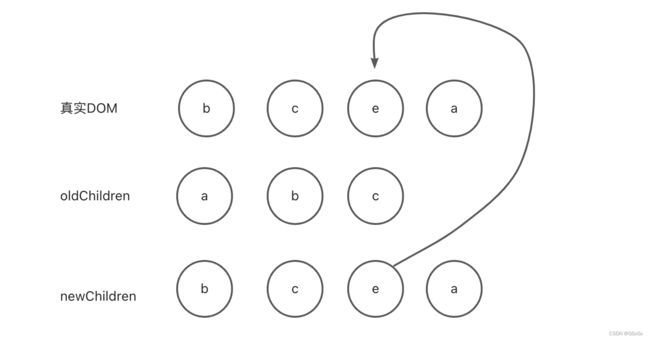
oldStart = c, oldEnd = c
newStart = c, newEnd = e
比较结果:oldStart、oldEnd 和 newStart相等,需要把节点c移动到newStart所对应的位置,同时oldStart++,newStart++,oldEnd–

第四步 oldStart > oldEnd,则oldChildren先遍历完成了,而newChildren还没遍历完,说明newChlidren比oldChildren多,所以需要将多出来的节点,插入到真实DOM上对应的位置上
思考题
我在这里给大家留一个思考题哈。上面的例子是newChildren比oldChildren多,假如相反,是oldChildren比newChildren多的话,那就是newChildren先走完循环,然后oldChildren会有多出的节点,结果会在真实DOM里进行删除这些旧节点。大家可以自己思考一下,模拟一下这个过程,像我一样,画图模拟,才能巩固上面的知识。
附上updateChildren的核心原理代码
function updateChildren(parentElm, oldCh, newCh) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
api.insertBefore(parentElm, oldStartVnode.el, api.nextSibling(oldEndVnode.el))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
api.insertBefore(parentElm, oldEndVnode.el, oldStartVnode.el)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 使用key时的比较
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) // 有key生成index表
}
idxInOld = oldKeyToIdx[newStartVnode.key]
if (!idxInOld) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
newStartVnode = newCh[++newStartIdx]
}
else {
elmToMove = oldCh[idxInOld]
if (elmToMove.sel !== newStartVnode.sel) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
} else {
patchVnode(elmToMove, newStartVnode)
oldCh[idxInOld] = null
api.insertBefore(parentElm, elmToMove.el, oldStartVnode.el)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].el
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
用index做key
平常v-for循环渲染的时候,为什么不建议用index作为循环项的key呢?
我们举个例子,左边是初始数据,然后我在数据前插入一个新数据,变成右边的列表
<ul> <ul>
<li key="0">ali> <li key="0">测试li>
<li key="1">bli> <li key="1">ali>
<li key="2">cli> <li key="2">bli>
<li key="3">cli>
ul> ul>
按理说,最理想的结果是:只插入一个li标签新节点,其他都不动,确保操作DOM效率最高。但是我们这里用了index来当key的话,真的会实现我们的理想结果吗?废话不多说,实践一下:
<ul>
<li v-for="(item, index) in list" :key="index">{{ item.title }}li>
ul>
<button @click="add">增加button>
list: [
{ title: "a", id: "100" },
{ title: "b", id: "101" },
{ title: "c", id: "102" },
]
add() {
this.list.unshift({ title: "测试", id: "99" });
}
点击按钮我们可以看到,并不是我们预想的结果,而是所有li标签都更新了
为什么会这样呢?还是通过图来解释
按理说,a,b,c三个li标签都是复用之前的,因为他们三个根本没改变,改变的只是前面新增了一个测试
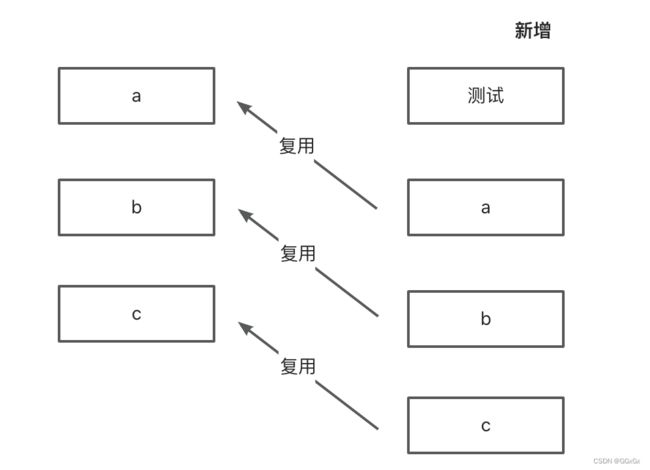
但是我们前面说了,在进行子节点的 diff算法 过程中,会进行 旧首节点和新首节点的sameNode对比,这一步命中了逻辑,因为现在新旧两次首部节点 的 key 都是 0了,同理,key为1和2的也是命中了逻辑,导致相同key的节点会去进行patchVnode更新文本,而原本就有的c节点,却因为之前没有key为4的节点,而被当做了新节点,所以很搞笑,使用index做key,最后新增的居然是本来就已有的c节点。所以前三个都进行patchVnode更新文本,最后一个进行了新增,那就解释了为什么所有li标签都更新了。

<ul>
<li v-for="item in list" :key="item.id">{{ item.title }}li>
ul>
为什么用了id来当做key就实现了我们的理想效果呢,因为这么做的话,a,b,c节点的key就会是永远不变的,更新前后key都是一样的,并且又由于a,b,c节点的内容本来就没变,所以就算是进行了patchVnode,也不会执行里面复杂的更新操作,节省了性能,而测试节点,由于更新前没有他的key所对应的节点,所以他被当做新的节点,增加到真实DOM上去了。
