Midjourney学习指南【模型篇】
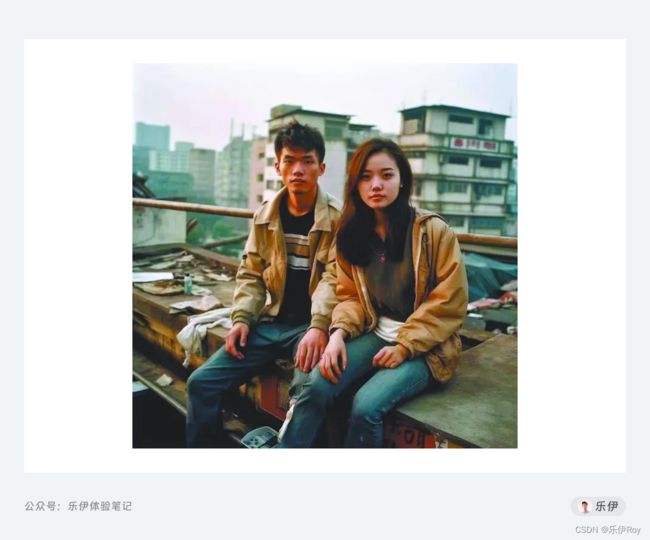
自各类AI工具出现后,各种算法模型迭代的速度都非常快,Midjourney也不例外。下面这张中国情侣图相信很多人在网上都看过,这就是由今年3月16日发布的V5模型生成的。
上一代的默认V4发布还不到半年,在今年5月初V5.1 又已经发布。短短几个月Midjourney的模型在图像细节和准确度上有了巨大提升,即使和真实照片相比也难辨真假。
虽然新的V5模型在各项性能上都有了很大提升,但是有时候也会出现不稳定的情况,在实际绘图时很多时候还是要根据自身的实际需求来选择模型。加上V5和Niji模型还陆续更新了几种不同的绘图模式,今天本篇文章是针对上一篇【基础篇】内容的补充,方便大家更好的理解和选择合适的绘图模型。
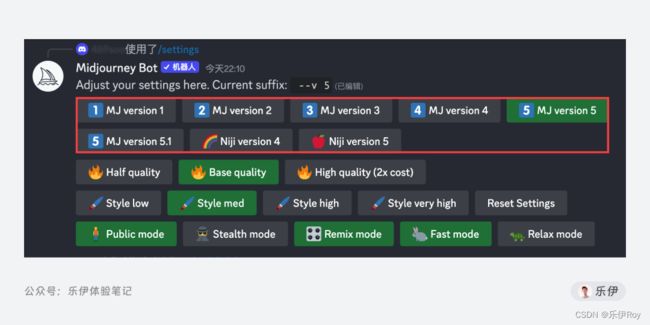
关于切换绘图模型的方法在之前的文章里也有介绍过,那就是在文本提示词的后面加上对应的模型参数即可。
如果觉得每次选择模型比较麻烦,也可以直接在设置项中选择默认模型,这样在绘图时就会自动加上相应的模型参数后缀。
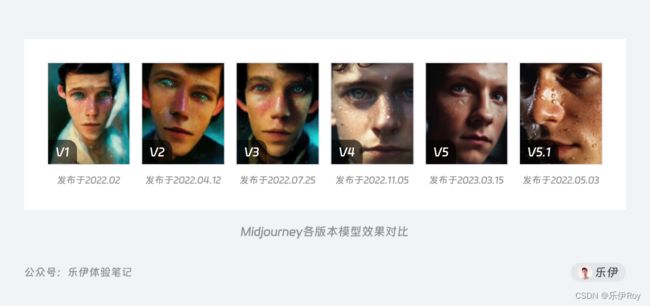
下面开始正式介绍目前最常用的几种绘图模型,关于V4之前的模型都是旧版本,此处就不再一一赘述了。
关于V4
使用方法:--v 4
在正式介绍V5模型前,我们先来回顾下让Midjourney火遍全球的V4模型。
在V4出现之前,Midjourney一直是整合其他开源模型作为图像生成算法,图像的生成效果也始终差强人意。直到V4开始,Midjourney开始正式自行训练模型,闭源的算法结合Discord上积累的庞大用户反馈数据,Midjourney不断针对用户需求做针对性的训练,如今无论是创意行业设计者,还是普通爱好者,都能通过Midjourney轻松完成自身的绘画需求。
V4作为一款去年12月发布的版本,在本月7号的V5.1发布前还一直是作为Midjourney默认的版本模型,可见其稳定性和图像效果已经十分强大。在大部分绘图场景下V4生成的图像效果依旧十分出色,甚至效果更佳,所以大家不必一味的追求最新版本,而是根据自己的实际做图需求来选择模型。
结合我自己的使用体验来看,V5适合生成摄影照片等需要高度清晰和细节还原的图片,而V4适合生成带有强烈艺术风格的插画或传统图像。
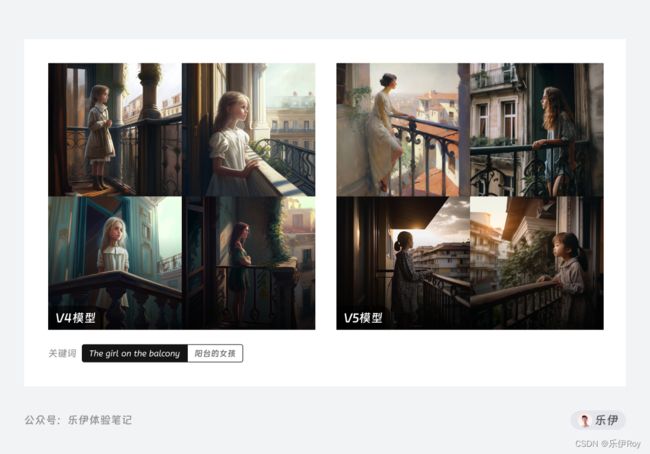
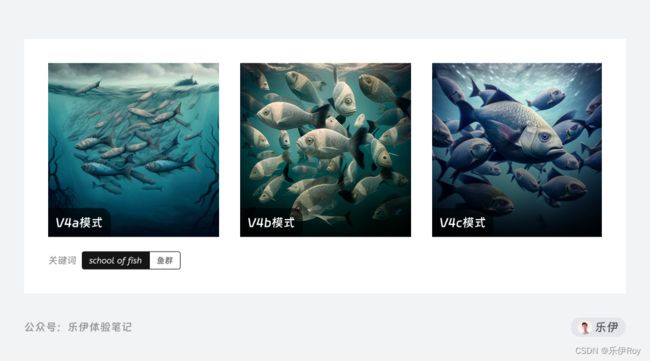
关于Midjourney模型大家还需要了解的是,大版本的模型迭代期间,也会间歇性的更新小版本模型。比如V4其中变化比较明显的被分为3个子版本,分别是V4a、V4b、V4c,默认情况下的V4使用的就是最近的V4c,可以在V4版本后加入style参数来切换查看子版本的图片生成效果。
关于V5.0
使用方法:--v 5
2023年3月15日,所有人期待已久的V5模型正式上线,一经发布立马在AI绘画圈引起巨大反响。根据更新文档来看,V5重点更新了以下内容
-
增加了图片风格化的范围,对提示词响应更加准确
-
提升图片质量,优化了动态范围(图片细节的丰富区间)
-
增加了更多图片细节,展示内容更加准确,移除了不必要的文本
-
提升了图片提示词的信息权重
-
支持【--tile】的无缝平铺效果
-
支持【--ar】的长宽比大于2:1
-
支持【--iw】来调整提示图片和提示文本的信息权重
下面针对更新内容给大家说明下使用过程中的细节注意点:
多使用口语化描述提示词
在V5版本下,提示词和图片内容关联性更强,需要我们更加关注对图片内容的描述。此外,算法优化了自然语言处理(NLP)的功能,这就提醒我们尽量采用一段完整的话进行描述,而不是单个词汇来描述关键词。
下图可以看出,同样是使用V5模型,当使用完整句子描述时图片内容明显更加准确

图片默认分辨率更高
此前V4版本下四格图为512*512,在点击【U按钮】后的图像尺寸会放大到1024*1024,且图像中的部分细节元素也会被二次优化。
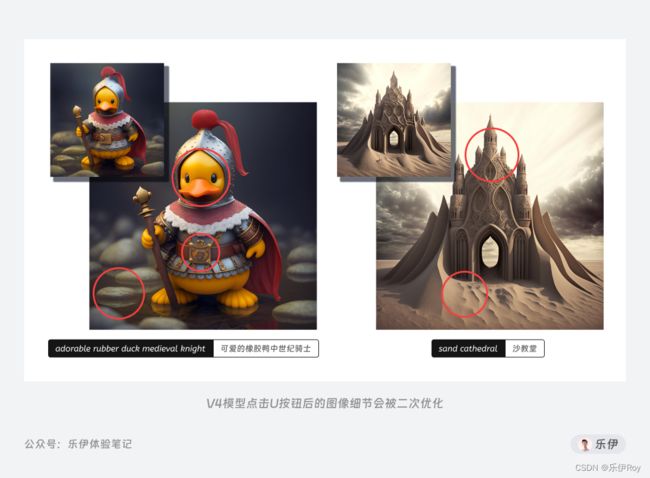
V5版本的默认四格图升级为分辨率1024*1024,由于已是最大分辨率,所以U按钮只是进行裁切图像的工作,并不会放大图像和优化图片细节。
下表是目前不同版本默认四格图和放大后的图像尺寸(只针对默认1:1的正方形)
| 版本模型 |
起始四格图中的单图尺寸 |
点击U按钮后图像尺寸 |
|---|---|---|
| V5 |
1024*1024 |
只进行裁切,原图尺寸不变 |
| V4 |
512*512 |
1024*1024 |
| Niji5 |
1024*1024 |
只进行裁切,原图尺寸不变 |
| Niji4 |
512*512 |
1024*1024 |
图像更加写实
V5的模型在写实图像内容处理上进行了很大提升,效果上会更像实景拍摄的照片。如果想要控制图像的写实程度,可以使用风格化参数stylize进行调节,具体的参数使用方法在【基础篇】中有详细介绍。

支持随意设置长宽比
V5图像支持更多的长宽比例选择,不再限制为2:1的范围内,但依旧不能有小数点
支持iw参数,垫图更加好用
图像权重参数在此前的V4版本中并不支持,而到了V5模型又可以使用了。在iw参数控制下,图像提示可以控制的更加精确了。
Remix混合模式更加稳定
在此前V4版本下,混合模式即使提示词不做调整,再次生成的图像也会和原图有一定差异。而到了V5则更加稳定,可以精确调整提示词中变化的内容。

修复手脚错乱问题
V4版本中一直被诟病的手脚错乱问题在V5被优化,出现的概率大大降低,不过为了避免出现错落情况,可以直接使用no hands来避免出现手部。

关于V5.1和raw模式
V5.1发布于今年5月4日,它在识别简短提示词的准确性上进一步提升,更加擅长理解自然语言,生成图像的清晰度也进一步提升。此外,在此前版本生成图像时,经常会出现一些多余边框和文字内容,这些小bug在更新后也被修复了。
此外,V5.1还上线了raw模式,单词raw翻译过来的意思是原生的、未经处理的。
在摄影领域也有raw的概念,全称是Raw Image Format,即未经加工的图像格式,可以简单理解为相机由光信号转化为数字信号时的最原始图像数据,未经曝光、白平衡等处理。

V5.1下的raw模式可以理解为V5算法模型的原生图像模式,该模式下模型不会根据自主观点改变图像内容和风格,内容更加接近提示词所描述的内容。
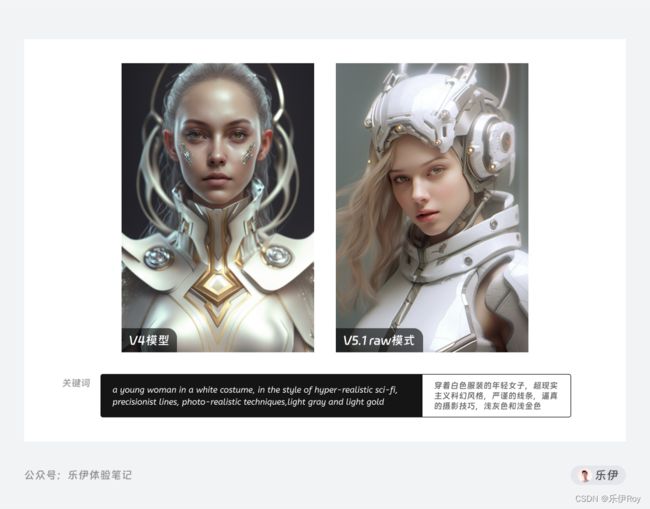
对比V4来看,V5.1的raw模式下元素主题和环境的融合更加自然,不会像V4下那么生硬,在图片生成方面更加贴近现实和用户的意图。
总结来说,我们可以将V5和V5.1的raw模式理解为专业版模型,擅长理解完整的提示词,适合有相关AI绘图经验的用户。而V5.1则是在此基础上适配的入门版,更适合没有经验的小白新手。
关于 Niji 5的四大模式
下面就到了最近刚更新的二次元绘画Niji5模型。
先简单介绍下 Niji-journey 是什么?它是 Midjourney 和 Spellbrush 合作的一款专门针对二次元的 AI 绘画工具。
Spellbrush的团队成员来自麻省理工,他们曾在2019年的动漫博览会上推出过Waifu Labs(二次元头像生成网站),作为专注于二次元AI领域的团队,他们和Midjourney合作开发的Niji算法模型拥有丰富的动漫知识,特别擅长创建动态和动感十足的镜头,并且非常注重角色和构图,可以说是目前在二次元领域最强的绘图模型。

为什么要专门针对二次元领域单独训练一款模型来使用?相较于真实世界的图像,二次元动漫是一个抽象且充满艺术美感的领域,虽然我们人类可以一眼分辨出现实照片和动漫的区别,但是在机器学习角度来看很难理解,毕竟现实图像有物理世界的规则限制,而二次元动漫的风格多种多样,难以直接通过图像训练得到。因此需要针对动漫图像做单独的数据标识和训练,并从中提取出独立的一套二次元图像绘画模型。
调用Niji模型的方法有2种,一种是直接使用Midjourney的机器人,选择Niji模式
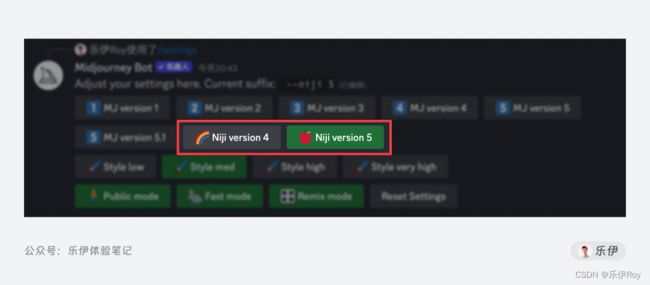
另一种是使用niji·journey Bot的独立机器人,和使用Midjourney机器人类似,需要先在Niji·Journey的社区中邀请niji·journey Bot机器人到自己的房间中使用。

Niji·Journey主要是面向亚洲地区的用户,它的社区包含中英日韩四个语言的区域。是的没错,Niji模型支持直接输入中文提示词来绘制图像。虽然这样很方便,但其实Niji模型并没有专门针对中文进行训练,只是在后台加了中译英的入口,为了避免翻译时产生歧义,英文水平还不错的朋友建议还是采用英文提示词进行输入。
Niji模型在使用上和Midjourney模型差不多,同样支持垫图,连指令都十分类似,但目前只支持 1:1、2:3 或者 3:2 的图片比例。
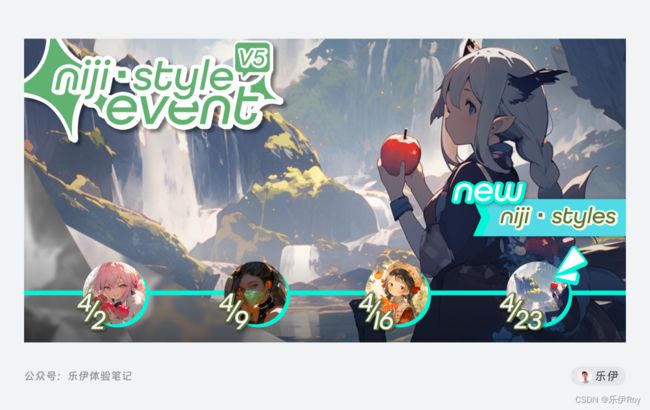
紧跟着Midjourney V5版本的升级,自4月2日开始,Niji·Journey连着四周挨个发布了Niji 5、Expressive、Cute、Scenic四款模型。
-
如果使用Midjourney Bot机器人,可以使用
--style参数进行微调,分别是--style cute、--style scenic或--style expressive -
如果是直接使用niji·journey Bot机器人,除了使用
--style参数,还可以在设置项中进行选择
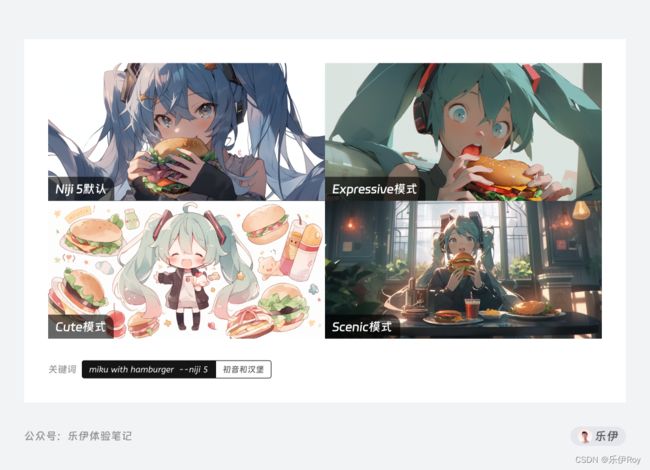
默认的Niji 5
相较于Niji4版本,Niji5 模型在情绪表达、戏剧层次和美术效果上都进行了优化,画面渲染和手部连贯性方面进行了提升,图像的轮廓边缘和角色造型上更加惊艳。
和Midjourney模型类似,Niji5同样受 stylize参数控制图像风格化程度,数值越大,二次元的动漫痕迹也就越明显。
Expressive 动漫艺术模式
Expressive 模式下的算法融入了3D渲染的绘画原理,与默认Niji 5相比,绘制的人物外观更加成熟,更偏向于西方美术风格,画面层次感更饱满。
该模式下的绘图可以呈现多样的风格,很适合进行绘图风格探索
该模式下只要关键词相同,图像的明暗对比、颜色和场景都能保持高度一致性,风格参数的数值只会影响到风格化本身,而不会对图像内容产生影响
Cute 治愈艺术模式
Cute模式绘制的图像充满天马行空的味道,图像表现上更具魅力和治愈性。相较于前2种精彩的视觉吸引力,Cute模式更像是让你在忙碌生活中放松的绘画方式,该风格的灵感来自于灵动的平面设计和装饰图形设计。
虽然看起来图像上3D渲染的部分少了很多,画面表现上看起来更简单,但技术上反而是最难训练的模型,除了提供画面表现力还要维持图像内容的一致性。
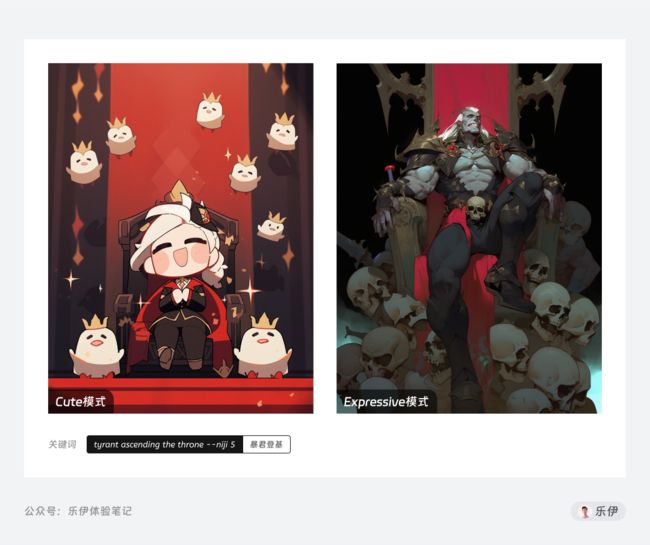
Cute模式的特点在于不会第一眼给用户造成很强的视觉冲击,但是治愈的画风会逐渐引导你去欣赏内部的图像细节。此外Cute模式除了默认的绘图风格,还可以作为其他绘画方式的限定词。在后面加入其他风格关键词来生成新的风格图像。
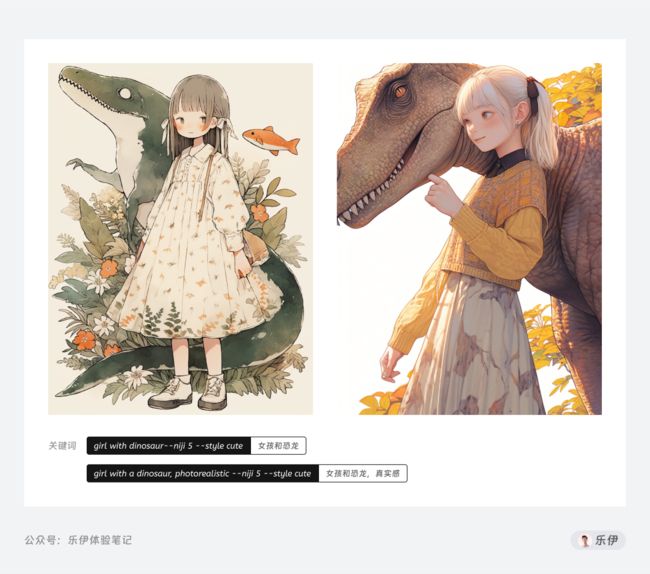
风格参数对于 Cute 模式影响效果图示
Scenic 场景模式
Scenic模式没有特定的美学艺术风格,而是将前三种模型最受欢迎的特色集于一身。
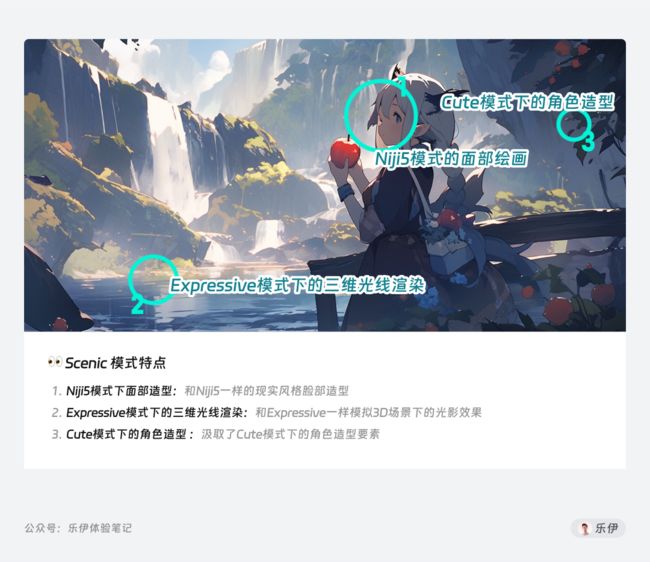
和其他模型相比,Scenic模式下擅长通过场景氛围来烘托主主体角色。

该模型下的难点在于不能单纯的提供背景氛围,而是将角色融入到环境当中,达到一种平衡状态。研发团队在研究各种表现形式后,采用了脸部侧视图的方式来提升角色的轮廓感,通过脸部朝向来指引观众的视线焦点。

该模式非常适合叙事风格的图像生成,比如在美轮美奂的电影镜头中增加宽长比,从而提升观感。
使用Niji模型绘制原创人物
关于Niji模型绘图的提示词和Midjourney使用方法会有点不太一样,下面再给大家简单介绍下过程。其实汇总成一句话就是:提示词文本内容描述精简,多使用图像提示来确定画面元素。
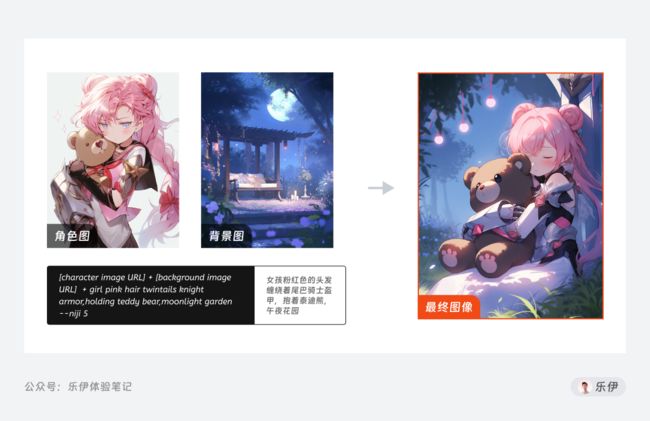
关键词结构:【角色参考图+背景参考图】+【角色描述】+【背景描述】
[character id image] [background id image] girl pink hair twintails ballgown moonlight garden glimmering extremely detailed
Niji模型绘图主要分为三步:确定人物角色信息、设定角色动作、添加背景图
第1步:确定人物角色信息
首先我们通过关键词描述生成一张角色图片,在其中选择一张最合适的角色图片。
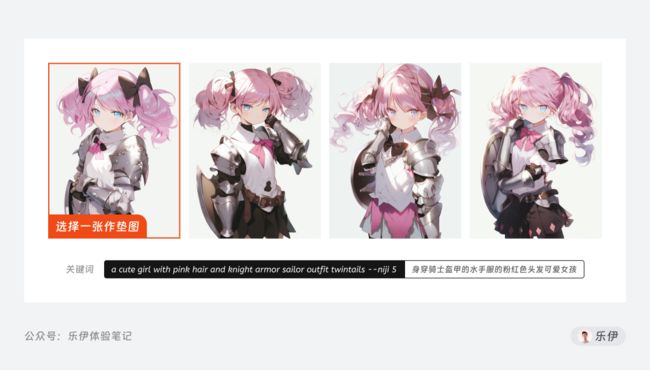
这里单纯靠提示词生成的图片内容可能不够精确,因此为了达到最佳效果,可以继续使用该角色图片作为喂图,加上之前的提示词再次生成图片。不过提示词内容要更加精简,以保证图片信息的精准度。

需要注意的是,在二次绘图时不需要过于详细的描述角色信息,比如指定卷发、粉缎带、蓝眼睛等,Niji会自动从参考图中读取信息并在生成图像时保持角色一致性
第2步:设定角色动作
使用上一步确定的角色图,为其添加动作和其他人物细节。

这里我们也可以对比下没有使用第一步角色垫图时的生成效果,可以发现在有垫图情况下的绘图结果会更加稳定。

第3步:添加背景图
最后就是通过添加背景图来将角色融入到背景中。背景图可以使用其他素材,当然也可以直接用提示词来生成。
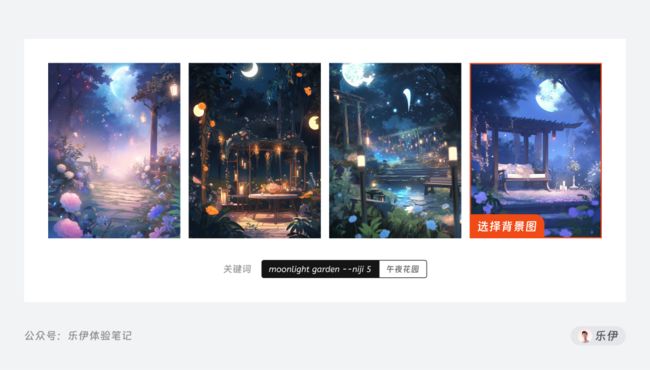
将角色图和背景图作为垫图,再加上提示词描述,生成最终的效果图。
总结
关于Midjourney模型部分的内容到这里就结束啦~ 不得不说,自从Midjourney在全球火爆以来,短短几个月算法模型已经陆续更迭了多次,作为重度使用者的最大感受就是:往往学的还没官方更新的快,刚熟悉的绘图模型可能在几周后就又被更新了。
总体来看,目前AI技术始终是在往提高用户工作效率的方向发展,相较于早期的模型,如今的Midjourney已经有了巨大提升,不管是图像效果还是内容精准度都在逐步提升,也很期待未来几个月官方会发布更多惊喜的内容。
