姿态估计动作捕捉与Unity,第一篇
这里使用开源的程序StridedTransformer-Pose3D,进行姿态检测,动作捕捉。
通过姿态估计程序把动作数据保存为txt文件,并利用Unity对数据文件进行解析,做动作捕捉。
txt动作数据文件,类似如下
0.0,0.0,0.7132570147514343,0.09690220654010773,-0.02704877406358719,0.7112197279930115,0.2909281551837921,0.10303543508052826,0.39557522535324097,0.4647705554962158,0.07060116529464722,0.0,-0.09777916967868805,0.027383409440517426,0.7151314616203308,0.05990784615278244,0.20277225971221924,0.4451775550842285,-0.01586601883172989,0.09693390130996704,0.07215827703475952,-0.043468981981277466,-0.013245195150375366,0.9565557241439819,-0.12227113544940948,0.02160206437110901,1.1949050426483154,-0.14719891548156738,0.07646191120147705,1.2867826223373413,-0.19019447267055511,0.06274139881134033,1.3792723417282104,-0.22385671734809875,0.04734146595001221,1.1589763164520264,-0.20313921570777893,0.2757633924484253,0.9522016048431396,-0.09251818060874939,0.14737790822982788,1.1633667945861816,0.02290845289826393,-0.005502611398696899,1.1955679655075073,0.22553035616874695,0.010887622833251953,0.9510767459869385,0.275457501411438,0.10281592607498169,0.7807502746582031,
程序地址
https://github.com/Vegetebird/StridedTransformer-Pose3D
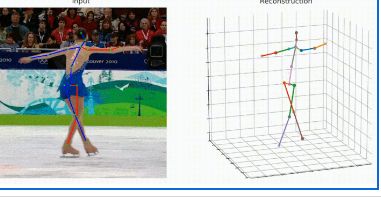
环境配置姿
环境:Ubuntu 22.04.2 LTS
1、使用conda,创建新的python环境
conda create -n shuziren2 python=3.8
2、安装pytorch
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
3、安装项目需要的依赖
pip3 install -r requirements.txt
4、下载文件放到指定目录
a、数据集文件:放到./dataset,链接
b、下载预训练模型预训练模型,下载并放入’./checkpoint/pretrained‘,链接
5、预训练模型进行测试
python main.py --test --refine --reload --refine_reload --previous_dir 'checkpoint/pretrained'

6、例子,运用训练好的模型测试
这里有一个已经训练好的模型,下载训练好的模型到文件夹./demo/lib/checkpoint,下载链接
python demo/vis.py --video sample_video.mp4
7、自训练
训练模型在Human3.6M上训练:
python main.py
训练几个epoch后,添加refine模块
python main.py --refine --lr 1e-5 --reload --previous_dir [your model saved path]
动作保存
上面我们对源码进行了配置,如何把视频中的动作保存起来,并在Unity应用呢?
应用我们创建的方法
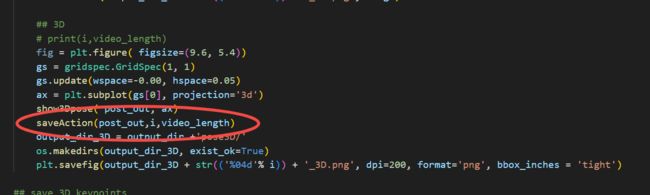
这样我们会保存一个Motion.txt文件,把这个文件导入Unity中,在Unity中读取文件,效果如下
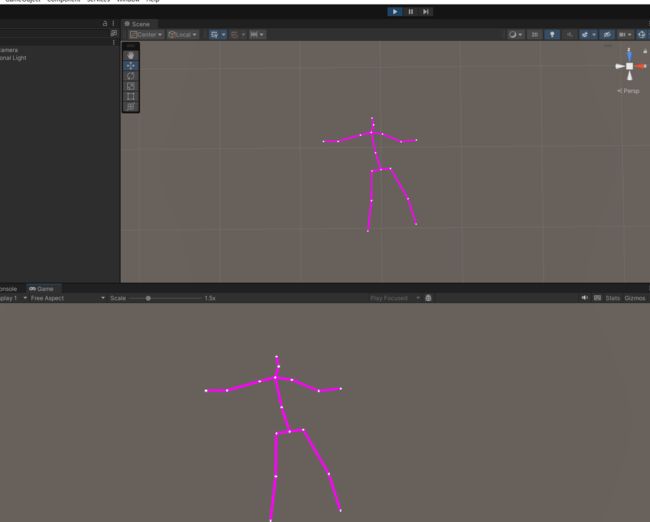
Unity篇
关于Unity的文章,公众号回复uu,获得unity篇文章