Nebula Graph图数据库教程介绍
Nebula Graph图数据库教程介绍
Nebula Graph(星云图)是一个开源的分布式图数据库系统,最初由中国的石墨烯数据库团队开发。它专门设计用于处理大规模图数据,并提供了高度可扩展性和性能。Nebula Graph支持多种图数据库的核心特性,如顶点和边的存储、查询、索引、图算法等。它通常用于构建复杂的数据关系图,如社交网络、知识图谱、推荐系统等应用。
Nebula Graph采用分布式架构,可以横向扩展以处理大量数据和查询负载。它还提供了多语言的客户端和查询接口,包括支持Cypher语言的接口,这使得开发人员可以方便地与图数据库进行交互。
Nebula Graph的特点包括数据持久性、数据一致性、多版本控制、数据安全性等,使其适用于各种企业级应用场景。
官方主页:https://nebula-graph.com.cn/
官方文档手册:https://docs.nebula-graph.com.cn/3.4.0/
GitHub项目地址:https://github.com/vesoft-inc/nebula
1. 基本概念
1.1 图数据库
图数据库是一种特殊的数据库类型,用于存储和查询图数据结构。图数据由节点(节点表示实体)和边(边表示节点之间的关系)组成。图数据库的主要目标是高效地处理复杂的图数据查询,例如社交网络分析、推荐系统、路径查询等。
图数据库是一种特殊类型的数据库,专门用于存储和管理图形数据结构。在图数据库中,数据以图的形式表示,其中包括节点(nodes)和边(edges)。节点用于表示实体或对象,而边用于表示节点之间的关系或连接。图数据库的核心目标是有效地处理和查询这些节点和边的关系,使之能够适用于各种复杂的数据关系和模式。
图数据库和传统数据库之间的主要区别在于数据模型、查询语言、数据查询能力和性能特点。图数据库更适合处理复杂的图形数据结构,而传统数据库更适合处理结构化表格数据。选择数据库类型应根据特定应用需求和数据模型来决定。
以下是图数据库与传统数据库(通常指关系型数据库)之间的主要区别:
| 特点 | 图数据库 | 关系型数据库 |
|---|---|---|
| 数据模型 | 基于图的数据模型,节点和边用于表示实体和关系。 | 基于表格的数据模型,使用表格表示数据。 |
| 查询方式 | 使用图查询语言(如Cypher、nGQL等)进行查询。 | 使用SQL(结构化查询语言)进行查询。 |
| 数据查询 | 专注于图查询,支持路径查询和图算法。 | 适用于传统的SQL查询和连接操作。 |
| 性能 | 在某些情况下,对于特定类型的查询,性能更高。 | 在某些情况下,性能更高,特别是在复杂的连接操作中。 |
| 应用领域 | 适用于复杂关系数据的领域,如社交网络分析、知识图谱、推荐系统。 | 适用于传统企业应用、数据仓库等领域。 |
| 数据建模 | 以节点和边的形式建模数据,强调实体之间的关系。 | 使用表格和关系键来建模数据,强调结构化数据。 |
| 事务支持 | 支持事务,但在某些情况下事务支持可能较弱。 | 支持强大的事务管理,保证数据的一致性。 |
| 可视化工具 | 通常提供专门的可视化工具,用于可视化图数据的结构和关系。 | 通常需要第三方工具来实现可视化。 |
| 部署 | 可以在云上部署,支持容器化部署。 | 可以在云上部署,也支持容器化部署。 |
| 数据一致性 | 侧重于某些情况下的最终一致性。 | 强调ACID事务和一致性。 |
| 数据建模灵活性 | 具有较高的灵活性,可适应不同类型的数据和关系。 | 在固定表结构下,相对较少的灵活性。 |
| 开源项目和社区支持 | 许多图数据库是开源项目,拥有活跃的社区支持。 | 有一些开源关系型数据库,但社区活跃度不一定如此高。 |
设计思想的区别:
- 数据建模的方式:
- 关系型数据库的设计思想是建立在表格(表)的基础上,数据被组织成表格形式,其中每个表格具有预定义的列和数据类型。这种模型适用于结构化数据,但在表示复杂的关系时可能显得笨拙。关系型数据库强调了数据的结构性和一致性。
- 图数据库的设计思想是建立在图的基础上,数据被组织成节点(实体)和边(关系)的集合,这样可以更自然地表示实体之间的复杂关系。图数据库的数据模型更加灵活,适用于表示非常复杂的关系数据,例如社交网络、知识图谱和推荐系统。
- 应对复杂关系的能力:
- 关系型数据库的查询主要基于表格的连接操作,虽然可以表示一定程度的关系,但对于多层次、多对多或复杂的关系模式,查询可能变得复杂且性能下降。
- 图数据库则专注于处理图结构,这使得它更适合表示和查询复杂的关系。图数据库提供了丰富的图查询语言和图算法,能够高效地执行路径查询、图遍历和社交网络分析等操作,因此在处理具有深层次、多对多关系的数据时具有明显的优势。
图数据库和关系型数据库在诞生的思想上最大的区别在于数据建模的方式和应对复杂关系的能力。图数据库的设计思想更加灵活,能够更自然地表示和查询具有复杂关系的数据,而关系型数据库更适用于结构化数据和严格的数据一致性要求。
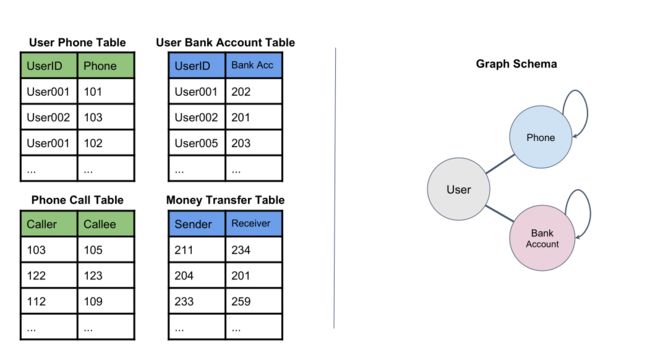
1.2 Nebula Graph
Nebula Graph是一款开源的分布式图数据库,专为处理大规模图数据而设计。它采用了图形数据模型,以节点和边的形式存储数据,适用于表示实体之间的复杂关系和连接。Nebula Graph具有出色的图查询能力,支持复杂的图查询操作,如路径查询、社交网络分析等。其分布式架构使其能够水平扩展以处理大规模数据集,并具备高可用性和负载均衡能力。Nebula Graph提供了可视化工具,帮助用户直观地探索和分析图数据。此外,它支持多种数据模型,包括点-边模型和属性图模型,以满足不同应用场景的需求。作为一个开源项目,Nebula Graph拥有活跃的社区支持,为用户和开发者提供了文档、示例和论坛等资源,使其成为处理复杂图数据的有力工具。
2. Nebula特点和优势
2.1 分布式架构
Nebula Graph采用了分布式存储和计算的架构,可以水平扩展以处理大规模数据集。它支持数据分片、负载均衡和高可用性。
分布式架构包括以下核心组件:
- Graph Storage Service:负责存储图数据,支持数据分片和分布式存储。
- Graph Query Service:处理图数据的查询请求,支持复杂的图查询操作。
- Graph Control Service:用于集群管理和负载均衡。
- Meta Service:管理集群的元数据信息,包括节点和分片信息。
这些组件协同工作,构成了Nebula Graph的分布式架构。这种架构使Nebula Graph能够有效地处理大规模图数据,实现高性能和高可用性。它还支持水平扩展,允许根据数据增长的需求添加更多的节点来增加处理能力。Nebula Graph的分布式架构是其在处理复杂图数据场景下的关键优势之一。
2.2 Nebula强大的查询能力
Nebula Graph具有强大的图数据查询能力,支持复杂的图查询操作,包括深度遍历、最短路径、社交网络分析等。它的查询语言灵活且易于使用。
以下是Nebula Graph强大查询能力的一些关键特点:
-
Cypher查询语言:
- Nebula Graph采用Cypher查询语言,这是一种用于图数据库的声明性查询语言。Cypher具有直观的语法,使用户能够轻松地编写复杂的图查询操作。
- Cypher支持模式匹配、路径查询、过滤和聚合等操作,使用户可以轻松地检索和分析图数据。
-
深度遍历:
- Nebula Graph支持深度遍历操作,允许用户沿着图中的路径进行遍历。这对于查找特定节点之间的复杂关系非常有用,如社交网络中的好友关系、路径分析等。
-
最短路径查询:
- Nebula Graph支持最短路径查询,用户可以找到两个节点之间的最短路径。这在网络路由、物流规划和推荐系统中具有广泛的应用。
-
聚合和过滤:
- Nebula Graph允许用户对查询结果进行聚合和过滤操作。这意味着您可以对图数据执行各种聚合函数,如计数、求和、平均值等,以便从数据中提取有用的信息。
-
社交网络分析:
- Nebula Graph具有专门的图算法支持,可用于执行复杂的社交网络分析操作,如查找节点的邻居、度中心性、介数中心性等。
-
可视化工具:
- Nebula Graph提供了可视化工具,帮助用户直观地探索和分析图数据。这些工具可以可视化节点和边的关系,执行查询,并生成图形报告。
-
多模型支持:
- Nebula Graph支持多种数据模型,包括点-边模型和属性图模型。这意味着它不仅适用于复杂的关系数据,还可以结合属性数据进行更广泛的应用。
总的来说,Nebula Graph的强大查询能力使其成为处理复杂图数据的理想选择。无论是在社交网络分析、推荐系统、知识图谱还是其他图数据应用中,Nebula Graph都能够支持复杂的查询需求,帮助用户深入挖掘图数据的价值。
2.3 Nebula可视化工具
Nebula Graph提供了一些可视化工具,用于帮助用户直观地探索和分析图数据,这些工具可以可视化图结构,执行查询,并生成图形报告。
-
Nebula Console:
- Nebula Console是Nebula Graph的官方命令行工具,其中包含了一些可视化功能。用户可以使用Nebula Console来执行Cypher查询,并以表格形式查看结果。这种简单的可视化工具适用于快速查询和初步探索图数据。
-
Nebula Graph Studio:
- Nebula Graph Studio是一个Web可视化工具,提供了更丰富的图数据可视化功能。用户可以通过Web界面执行Cypher查询,并以图形方式查看结果。它支持节点和边的可视化展示,包括节点的颜色和形状定制,以及边的样式设置。这使用户能够更直观地理解和分析图结构。
-
第三方可视化工具:
- 除了官方提供的工具外,Nebula Graph还可以与第三方可视化工具集成。一些流行的数据可视化工具,如Gephi、Cytoscape等,支持与Nebula Graph集成,使用户能够使用这些工具来创建更高级的图形可视化。
这些可视化工具使用户能够以不同的方式探索和呈现图数据。从简单的命令行查询到交互式的Web界面和高级的第三方工具,用户可以根据其需求和技术水平选择最适合的工具来可视化和分析Nebula Graph中的数据。这些工具有助于用户更好地理解图数据的结构、关系和模式。
2.4 Nebula支持多种数据模型
Nebula Graph支持多种数据模型,包括点-边模型和属性图模型。这使得它适用于不同类型的应用场景。
-
点-边数据模型:
- 这是Nebula Graph的核心数据模型,适用于表示实体之间的关系。数据以节点(points)和边(edges)的形式组织,其中节点代表实体或对象,而边代表节点之间的关系。这种模型非常适合处理复杂的图数据,如社交网络、推荐系统、知识图谱等。
-
属性图数据模型:
- 在点-边数据模型的基础上,Nebula Graph还支持属性图(property graph)数据模型。属性图模型允许为节点和边添加属性(properties),这些属性可以包括关于节点和边的附加信息,如名称、年龄、权重等。属性图模型使得Nebula Graph更灵活,能够应对更广泛的应用场景,包括需要丰富属性信息的数据分析任务。
这两种数据模型可以根据特定应用的需求进行选择和组合。点-边模型适用于表示实体之间的复杂关系,而属性图模型则允许将附加信息与节点和边关联起来,以丰富数据的描述和分析。Nebula Graph的多模型支持使其具备了更广泛的适用性,可以满足不同领域和应用场景的需求。
3. Nebula 用途领域
Nebula Graph是一个通用的图数据库,适用于多种应用领域,尤其是在需要处理复杂图数据和复杂关系的场景中具有广泛的应用。以下是一些Nebula Graph的常见用途领域:
-
社交网络分析:
- Nebula Graph可用于分析社交网络数据,包括用户之间的关系、社交网络图的结构和演化趋势。它支持查询用户之间的连接、社交网络中的子图、社群检测等任务。
-
推荐系统:
- 在推荐系统中,Nebula Graph可以用于存储和查询用户行为数据以及物品之间的关系。这有助于构建个性化推荐算法,提供用户定制的推荐内容。
-
知识图谱:
- Nebula Graph可以用于构建和查询知识图谱,其中包括实体之间的复杂关系和属性信息。它支持语义搜索、智能问答系统和知识图谱推理。
-
路径分析:
- Nebula Graph适用于路径分析任务,如物流路线规划、网络路由、交通管理等。它可以找到两个节点之间的最短路径、路径模式和路径优化。
-
风险分析:
- 在金融领域,Nebula Graph可以用于风险分析和欺诈检测。它可以帮助识别异常节点和关系,以提高风险管理效率。
-
推理引擎:
- Nebula Graph支持复杂的图推理任务,如图神经网络(GNN)等。这对于构建智能系统、社交网络分析和推荐算法非常有用。
-
生物信息学:
- 在生物信息学研究中,Nebula Graph可以用于存储和查询生物分子之间的相互作用网络,帮助科学家研究生物体系的复杂性。
-
物联网:
- Nebula Graph可用于存储和分析物联网设备之间的连接和关系,支持物联网应用中的数据聚合和分析。
Nebula工商企业数据用途
Nebula Graph在工商企业信息数据领域有广泛的用途,可以帮助企业和组织更好地管理、分析和利用工商企业信息数据。以下是Nebula Graph在这一领域的一些应用场景:
-
企业关系分析:
- Nebula Graph可以用于存储和分析企业之间的关系,包括合并、收购、合作等。它能够帮助企业识别潜在的合作伙伴或竞争对手,支持战略规划和市场分析。
-
公司股权结构分析:
- Nebula Graph可以用于建模和分析公司的股权结构,包括股东关系、持股比例和权益变动。这有助于投资者、分析师和监管机构监控和评估企业的股权情况。
-
商业信用评估:
- Nebula Graph可以用于构建企业的信用评估模型,通过分析历史交易、财务数据和合作关系来评估企业的信用风险。这对于金融机构和供应链管理非常重要。
-
市场调研和竞争分析:
- 通过分析企业的业务活动、市场份额和客户关系,Nebula Graph可以帮助企业进行市场调研和竞争分析。这有助于制定营销策略和决策。
-
政府监管和合规性:
- 政府部门可以利用Nebula Graph来监管工商企业信息数据,确保企业合规性和遵守法规。它可以帮助监管机构识别潜在的违规行为和不正当竞争。
-
投资决策:
- 投资者可以使用Nebula Graph来分析潜在投资目标的企业信息数据,包括财务状况、经营历史和股东结构,以做出更明智的投资决策。
-
供应链管理:
- Nebula Graph可以用于分析供应链中的企业关系和交易,帮助企业优化供应链管理,降低成本并提高效率。
Nebula Graph在工商企业信息数据领域的用途非常广泛,它可以帮助企业、金融机构、政府和研究机构更好地理解和管理企业信息,支持数据驱动的决策和业务运营。其强大的图数据库功能使其成为处理复杂企业关系和大规模企业信息数据的理想选择。
4. Nebula 架构
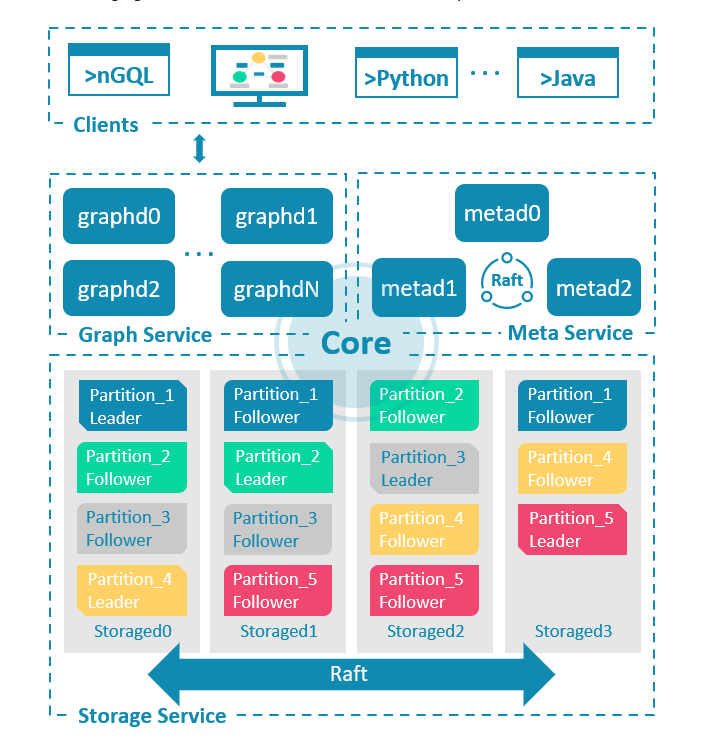
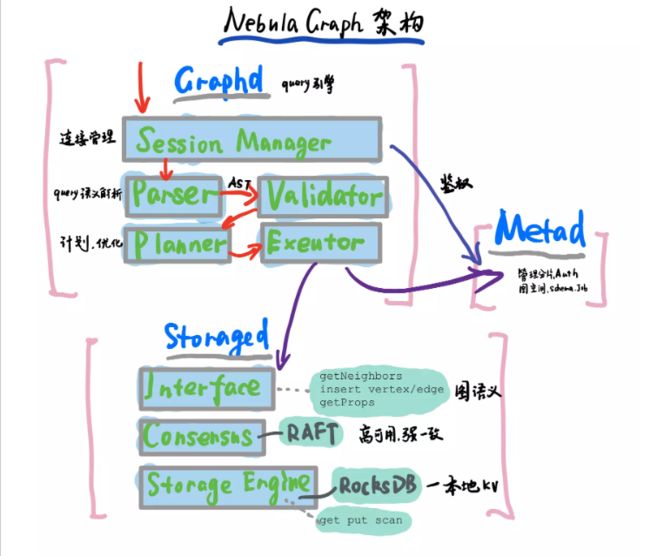
Nebula Graph的架构包括以下关键组件:
4-1. Storage Service
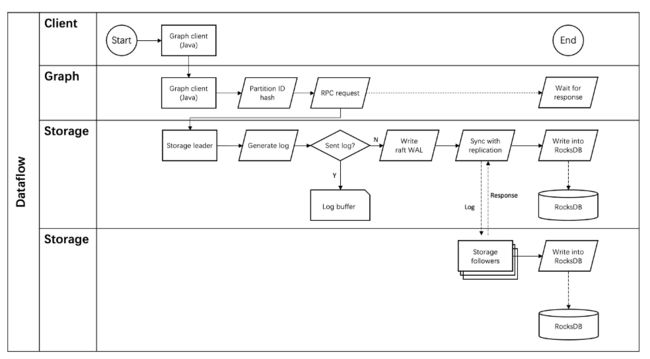
- 这是Nebula Graph的存储层,负责存储图数据。它采用了分片存储的方式,将图数据分割成多个分片,每个分片存储在不同的节点上。这使得数据可以水平分布在多个节点上,以提高性能和可扩展性。
- Storage Service支持数据的持久化和复制,以确保数据的持久性和高可用性。
Storage 服务架构:

Storage 写入流程:
4-2. Graph Service
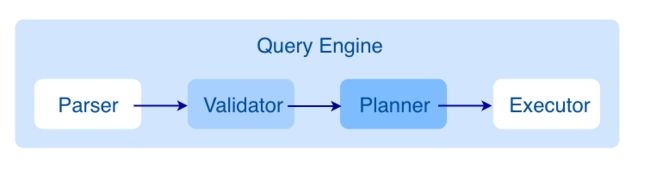
查询请求发送到 Graph 服务后,会由如下模块依次处理:
- Parser:词法语法解析模块。
- Validator:语义校验模块。
- Planner:执行计划与优化器模块。
- Executor:执行引擎模块。
4-2-1. Parser
Parser 模块收到请求后,通过 Flex(词法分析工具)和 Bison(语法分析工具)生成的词法语法解析器,将语句转换为抽象语法树(AST),在语法解析阶段会拦截不符合语法规则的语句。
例如GO FROM "Tim" OVER like WHERE properties(edge).likeness > 8.0 YIELD dst(edge)语句转换的 AST 如下。

4-2-2. Validator
Validator 模块对生成的 AST 进行语义校验,主要包括:
-
校验元数据信息
校验语句中的元数据信息是否正确。
例如解析
OVER、WHERE和YIELD语句时,会查找 Schema 校验 Edge type、Tag 的信息是否存在,或者插入数据时校验插入的数据类型和 Schema 中的是否一致。 -
校验上下文引用信息
校验引用的变量是否存在或者引用的属性是否属于变量。
例如语句
$var = GO FROM "Tim" OVER like YIELD dst(edge) AS ID; GO FROM $var.ID OVER serve YIELD dst(edge),Validator 模块首先会检查变量var是否定义,其次再检查属性ID是否属于变量var。 -
校验类型推断
推断表达式的结果类型,并根据子句校验类型是否正确。
例如
WHERE子句要求结果是bool、null或者empty。 -
校验
*代表的信息查询语句中包含
*时,校验子句时需要将*涉及的 Schema 都进行校验。例如语句
GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge),校验OVER子句时需要校验所有的 Edge type,如果 Edge type 包含like和serve,该语句会展开为GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(edge).likeness, dst(edge)。 -
校验输入输出
校验管道符(|)前后的一致性。
例如语句
GO FROM "Tim" OVER like YIELD dst(edge) AS ID | GO FROM $-.ID OVER serve YIELD dst(edge),Validator 模块会校验$-.ID在管道符左侧是否已经定义。
校验完成后,Validator 模块还会生成一个默认可执行,但是未进行优化的执行计划,存储在目录 src/planner 内。
4-2-3. Planner
如果配置文件 nebula-graphd.conf 中 enable_optimizer 设置为 false,Planner 模块不会优化 Validator 模块生成的执行计划,而是直接交给 Executor 模块执行。
如果配置文件 nebula-graphd.conf中enable_optimizer 设置为 true,Planner 模块会对 Validator 模块生成的执行计划进行优化。如下图所示。

4-2-4. Executor
Executor 模块包含调度器(Scheduler)和执行器(Executor),通过调度器调度执行计划,让执行器根据执行计划生成对应的执行算子,从叶子节点开始执行,直到根节点结束。如下图所示。
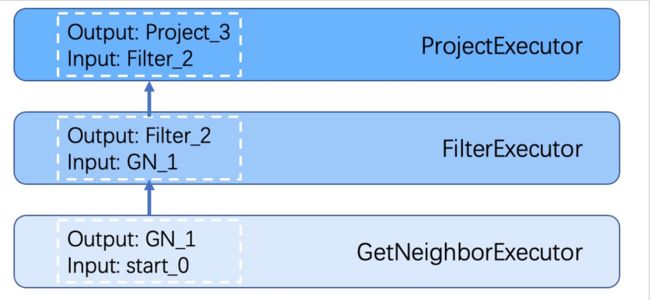
每一个执行计划节点都一一对应一个执行算子,节点的输入输出在优化执行计划时已经确定,每个算子只需要拿到输入变量中的值进行计算,最后将计算结果放入对应的输出变量中即可,所以只需要从节点 Start 一步步执行,最后一个算子的输出变量会作为最终结果返回给客户端。
4-3. Meta Service
- Meta Service管理Nebula Graph的元数据信息,包括节点和分片的信息。它跟踪数据的拓扑结构和集群配置,以确保查询请求能够正确地路由到相应的节点和分片。
- Meta Service还支持元数据的持久化和备份,以保障元数据的稳定性。
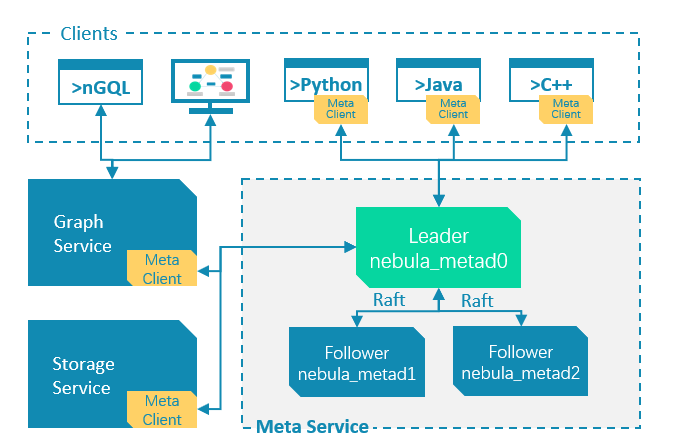
Nebula Graph 中的 Meta Service 组件是负责存储和管理图数据库元数据的重要组件。为了确保 Meta Service 的高可用性和数据一致性,它使用了 Raft 一致性协议
Raft 是一种分布式一致性算法,用于确保分布式系统中的多个节点之间的数据一致性和高可用性。Raft 将多个节点组织成一个集群,其中包括一个领导者(Leader)和多个追随者(Followers)。领导者负责处理客户端请求,追随者则复制领导者的日志以保持数据一致性。
在 Nebula Graph 中,Meta Service 通过 Raft 机制来维护数据库的元数据(例如图空间、标签、边类型等信息),确保这些数据的一致性和高可用性
5. 社区和生态系统
尽管Nebula Graph是一个相对小众的项目,但它的社区正在不断壮大。社区提供了论坛、邮件列表、GitHub仓库和在线文档,以支持用户和开发者。此外,Nebula Graph还有一些扩展和插件,可以满足不同应用场景的需求。
Nebula-graph社区地址:https://discuss.nebula-graph.com.cn/
6. Nebula安装部署和管理(3.4.0)
本次部署版本为 3.4.0
6-1. 环境建议-(官方参考建议)
Nebula Graph的部署和管理通常涉及以下步骤:
- 安装Nebula Graph集群。
- 配置集群的Graph Storage、Graph Query和Meta服务。
- 启动服务并监控性能。
-
关于存储硬件
-
不建议使用 HDD;因为其 IOPS 性能差,随机寻道延迟高;会遇到大量问题。
-
不要使用远端存储设备(如 NAS 或 SAN),不要外接基于 HDFS 或者 Ceph 的虚拟硬盘。
-
不要使用磁盘阵列(RAID)。
-
使用本地 SSD 设备;或 AWS Provisioned IOPS SSD 或等价云产品。
-
-
操作系统要求
- 当前仅支持在 Linux 系统中编译NebulaGraph,建议使用内核版本为
4.15及以上版本的 Linux 系统
- 当前仅支持在 Linux 系统中编译NebulaGraph,建议使用内核版本为
-
生产环境运行建议
| 类型 | 要求 |
|---|---|
| CPU 架构 | x86_64 |
| CPU 核数 | 48 |
| 内存 | 256 GB |
| 硬盘 | 2 * 1.6 TB,NVMe SSD |
以上为生产环境的参考建议配置,非必须。
如以实验学习或是测试,常规配置即可
- 服务架构建议
| 进程 | 数量 |
|---|---|
| metad(meta 数据服务进程) | 3 |
| storaged(存储服务进程) | ≥3 |
| graphd(查询引擎服务进程) | ≥3 |
有且仅有 3 个 metad 进程,每个 metad 进程会自动创建并维护 meta 数据的一个副本。
storaged 进程的数量不会影响图空间副本的数量。
用户可以在一台机器上部署多个不同进程,例如机器A上部署metad 进程、storaged进程 、graphd进程
6-2. 机器环境准备
- 机器准备 * 5台
| 操作系统 | 机器名称 | graphd进程 | storaged进程 | metad进程 |
|---|---|---|---|---|
| CentOS 7.4 | hdt-dmcp-ops01 - (172.20.8.117) | √ | √ | √ |
| CentOS 7.4 | hdt-dmcp-ops02 - (172.20.14.164) | √ | √ | √ |
| CentOS 7.4 | hdt-dmcp-ops03 - (172.20.14.243) | √ | √ | √ |
| CentOS 7.4 | hdt-dmcp-ops04 - (172.20.9.6) | √ | √ | |
| CentOS 7.4 | hdt-dmcp-ops05 - (172.20.12.179) | √ | √ |
准备 5 台用于部署集群的机器,保证5台机器的系统时间同步
hdt-dmcp-ops01 - (172.20.8.117) 对应修改配置文件:
nebula-graphd.conf、nebula-storaged.conf、nebula-metad.confhdt-dmcp-ops02 - (172.20.14.164) 对应修改配置文件:
nebula-graphd.conf、nebula-storaged.conf、nebula-metad.confhdt-dmcp-ops03 - (172.20.14.243) 对应修改配置文件:
nebula-graphd.conf、nebula-storaged.conf、nebula-metad.confhdt-dmcp-ops04 - (172.20.9.6) 对应修改配置文件:
nebula-graphd.conf、nebula-storaged.confhdt-dmcp-ops05 - (172.20.12.179) 对应修改配置文件:
nebula-graphd.conf、nebula-storaged.conf
6-3. 安装依赖软件 - [所有机器操作]
- 安装依赖
# 更新yum包
yum update
# 安装依赖
yum install -y make \
m4 \
git \
wget \
unzip \
xz \
readline-devel \
ncurses-devel \
zlib-devel \
gcc \
gcc-c++ \
cmake \
curl \
redhat-lsb-core \
bzip2
注意:当操作系统为:CentOS 8+、RedHat 8+、Fedora时,需要安装libstdc+±static 和 libasan。
yum install -y libstdc++-static libasan
- 验证版本
[root@hdt-dmcp-ops01 ~]# g++ --version
g++ (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
[root@hdt-dmcp-ops01 ~]# cmake --version
cmake version 2.8.12.2
6-4. 下载安装包 - [ hdt-dmcp-ops01操作 ]
官方下载链接:https://www.nebula-graph.com.cn/download
3.4.0官方下载链接:https://oss-cdn.nebula-graph.com.cn/package/3.4.0/nebula-graph-3.4.0.el7.x86_64.tar.gz
命令行下载:
wget https://oss-cdn.nebula-graph.com.cn/package/3.4.0/nebula-graph-3.4.0.el7.x86_64.tar.gz
6-5. 解压安装与配置 - [ hdt-dmcp-ops01操作 ]
- 安装
# 解压至安装目录
[root@hdt-dmcp-ops01 ~]# tar -xvzf nebula-graph-3.4.0.el7.x86_64.tar.gz -C /opt/module/
[root@hdt-dmcp-ops01 ~]# cd /opt/module/
# 更改应用目录名
[root@hdt-dmcp-ops01 module]# mv nebula-graph-3.4.0.el7.x86_64 nebula
[root@hdt-dmcp-ops01 ~]# cd /opt/module/nebula/
[root@hdt-dmcp-ops01 nebula]# cd etc/
# 更改默认配置文件名
[root@hdt-dmcp-ops01 etc]# mv nebula-graphd.conf.default nebula-graphd.conf
[root@hdt-dmcp-ops01 etc]# mv nebula-storaged.conf.default nebula-storaged.conf
[root@hdt-dmcp-ops01 etc]# mv nebula-metad.conf.default nebula-metad.conf
- 修改第一台机器配置文件
保存需要
wq!强制保存
- hdt-dmcp-ops01 - (172.20.8.117)配置
[root@hdt-dmcp-ops01 etc]# vim nebula-graphd.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.8.117
--listen_netdev=any
--port=9669
[root@hdt-dmcp-ops01 etc]# vim nebula-storaged.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.8.117
--port=9779
[root@hdt-dmcp-ops01 etc]# vim nebula-metad.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.8.117
--port=9559
- 将hdt-dmcp-ops01上相关配置文件修改后,后续对nebula目录进行分发,可以减少大量的修改操作
- 数据存储目录默认在项目路径下,data/storage, 如指定路径可以修改
--data_path- 更多配置项可以参见下方第八章节
6-6. 安装nebula-console工具
nebula-console 是 Nebula Graph 的官方命令行工具,用于与 Nebula Graph 集群进行交互、执行查询和管理数据库。这个工具提供了一种简单的方式来连接到 Nebula Graph,发送 Cypher 查询语句,并查看查询结果。
nebula-console 会显示查询结果并以表格的形式呈现,以便用户阅读。如果查询结果包含多个列,结果将以表格的形式显示。
连接到 Nebula Graph,要连接到 Nebula Graph 集群,请使用以下命令:
nebula-console -u <用户名> -p <密码> --address=<Nebula_Graph_IP>:<Nebula_Graph_Port>
<用户名>:您的 Nebula Graph 用户名。<密码>:您的 Nebula Graph 用户密码。
下载地址:
github地址:https://github.com/vesoft-inc/nebula-console/releases
https://github.com/vesoft-inc/nebula-console/releases/download/v3.4.0/nebula-console-linux-amd64-v3.4.0
# 安装工具,将console工具安装在nebula/bin目录下,使用方便
[root@hdt-dmcp-ops01 bin]# cd /opt/module/nebula/bin/
[root@hdt-dmcp-ops01 bin]# mv nebula-console-linux-amd64-v3.4.0 nebula-console
[root@hdt-dmcp-ops01 bin]# chmod +x nebula-console
6-7. 分发nebula目录至其它服务器
[root@hdt-dmcp-ops01 module]# scp -r nebula hdt-dmcp-ops02:/opt/module/
[root@hdt-dmcp-ops01 module]# scp -r nebula hdt-dmcp-ops03:/opt/module/
[root@hdt-dmcp-ops01 module]# scp -r nebula hdt-dmcp-ops04:/opt/module/
[root@hdt-dmcp-ops01 module]# scp -r nebula hdt-dmcp-ops05:/opt/module/
6-8. 修改配置文件 - [ 剩余机器操作 ]
- hdt-dmcp-ops02 - (172.20.14.164)配置
[root@hdt-dmcp-ops02 ~]# cd /opt/module/nebula/etc/
[root@hdt-dmcp-ops02 etc]# vim nebula-graphd.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.164
--listen_netdev=any
--port=9669
[root@hdt-dmcp-ops02 etc]# vim nebula-storaged.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.164
--port=9779
[root@hdt-dmcp-ops02 etc]# vim nebula-metad.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.164
--port=9559
- hdt-dmcp-ops03 - (172.20.14.243)配置
[root@hdt-dmcp-ops03 ~]# cd /opt/module/nebula/etc/
[root@hdt-dmcp-ops03 etc]# vim nebula-graphd.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.243
--listen_netdev=any
--port=9669
[root@hdt-dmcp-ops03 etc]# vim nebula-storaged.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.243
--port=9779
[root@hdt-dmcp-ops03 etc]# vim nebula-metad.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.14.243
--port=9559
- hdt-dmcp-ops04 - (172.20.9.6)配置
[root@hdt-dmcp-ops04 ~]# cd /opt/module/nebula/etc/
[root@hdt-dmcp-ops04 etc]# mv nebula-metad.conf nebula-metad.conf.default
[root@hdt-dmcp-ops04 etc]# vim nebula-graphd.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.9.6
--listen_netdev=any
--port=9669
[root@hdt-dmcp-ops04 etc]# vim nebula-storaged.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.9.6
--port=9779
- hdt-dmcp-ops05 - (172.20.12.179)配置
[root@hdt-dmcp-ops05 ~]# cd /opt/module/nebula/etc/
[root@hdt-dmcp-ops05 etc]# mv nebula-metad.conf nebula-metad.conf.default
[root@hdt-dmcp-ops05 etc]# vim nebula-graphd.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.12.179
--listen_netdev=any
--port=9669
[root@hdt-dmcp-ops05 etc]# vim nebula-storaged.conf
########## networking ##########
--meta_server_addrs=172.20.8.117:9559,172.20.14.164:9559,172.20.14.243:9559
--local_ip=172.20.12.179
--port=9779
6-9. 启动nebula服务集群
依次启动各个服务器上的对应进程
| 机器名称 | 待启动的进程 |
|---|---|
| hdt-dmcp-ops01 172.20.8.117 | graphd、storaged、metad (三个都操作可以用all) |
| hdt-dmcp-ops02 172.20.14.164 | graphd、storaged、metad (三个都操作可以用all) |
| hdt-dmcp-ops03 172.20.14.243 | graphd、storaged、metad (三个都操作可以用all) |
| hdt-dmcp-ops04 172.20.9.6 | graphd、storaged |
| hdt-dmcp-ops05 172.20.12.179 | graphd、storaged |
启动NebulaGraph进程的命令如下:
sudo /opt/module/nebula/scripts/nebula.service start
- 确保每个服务器中的对应服务进程都要启动,否则服务将启动失败。
- 当需都启动 graphd、storaged 和 metad 时,可以用 all 代替。
- /opt/module/nebula是我的安装路径,如果修改过安装路径,请使用实际路径。
# hdt-dmcp-ops01
[root@hdt-dmcp-ops01 module]# /opt/module/nebula/scripts/nebula.service start all
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done
# hdt-dmcp-ops02
[root@hdt-dmcp-ops02 etc]# /opt/module/nebula/scripts/nebula.service start all
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done
# hdt-dmcp-ops03
[root@hdt-dmcp-ops03 ~]# /opt/module/nebula/scripts/nebula.service start all
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done
# hdt-dmcp-ops04
[root@hdt-dmcp-ops04 ~]# /opt/module/nebula/scripts/nebula.service start graphd
[INFO] Starting nebula-graphd...
[INFO] Done
[root@hdt-dmcp-ops04 ~]# /opt/module/nebula/scripts/nebula.service start storaged
[INFO] Starting nebula-storaged...
[INFO] Done
#hdt-dmcp-ops05
[root@hdt-dmcp-ops05 ~]# /opt/module/nebula/scripts/nebula.service start graphd
[INFO] Starting nebula-graphd...
[INFO] Done
[root@hdt-dmcp-ops05 ~]# /opt/module/nebula/scripts/nebula.service start storaged
[INFO] Starting nebula-storaged...
[INFO] Done
注意:如果启动服务时,发生报错,可以到服务日志nebula/logs/路径下查看报错信息进行排障
6-10. 添加 Storage 主机
[root@hdt-dmcp-ops01 bin]# cd /opt/module/nebula/bin/
[root@hdt-dmcp-ops01 bin]# ./nebula-console -addr 172.20.8.117 --port 9669 -u root -p nebula
Welcome to Nebula Graph!
# 将 5 台storaged服务加入到集群
(root@nebula) [(none)]> ADD HOSTS 172.20.8.117:9779, 172.20.14.164:9779, 172.20.14.243:9779, 172.20.9.6:9779, 172.20.12.179:9779;
Execution succeeded (time spent 1.925ms/2.257408ms)
Tue, 12 Sep 2023 14:26:36 CST
# 查看集群HOST清单
(root@nebula) [(none)]> SHOW HOSTS;
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| "172.20.9.6" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.8.117" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.12.179" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.164" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.243" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
Got 5 rows (time spent 1.081ms/1.538768ms)
Tue, 12 Sep 2023 14:26:49 CST
(root@nebula) [(none)]>
(root@nebula) [(none)]> exit
Bye root!
Tue, 12 Sep 2023 14:29:43 CST
截止到此,nebula服务已经部署完毕
6-11. 使用nebula.service管理服务
使用脚本nebula.service管理服务,包括启动、停止、重启、中止和查看
nebula.service在项目nebula/scripts目录下
使用语法:
$ sudo /usr/local/nebula/scripts/nebula.service
[-v] [-c <config_file_path>]
<start | stop | restart | kill | status>
<metad | graphd | storaged | all>
参数介绍:
| 参数 | 说明 |
|---|---|
| -v | 显示详细调试信息 |
| -c | 指定配置文件路径,默认路径为nebula/etc/ |
| start | 启动服务 |
| stop | 停止服务 |
| restart | 重启服务 |
| kill | 中止服务 |
| status | 查看服务状态 |
| metad | 管理 Meta 服务 |
| graphd | 管理 Graph 服务 |
| storaged | 管理 Storage 服务 |
| all | 管理所有服务 |
当前各服务端口可以通过命令查看,服务正常时,可以查看到如下信息
[root@hdt-dmcp-ops01 bin]# netstat -tnlpu|grep -E "9559|9669|9779"
tcp 0 0 0.0.0.0:9669 0.0.0.0:* LISTEN 6467/nebula-graphd
tcp 0 0 0.0.0.0:19559 0.0.0.0:* LISTEN 6398/nebula-metad
tcp 0 0 0.0.0.0:9779 0.0.0.0:* LISTEN 6520/nebula-storage
tcp 0 0 0.0.0.0:19669 0.0.0.0:* LISTEN 6467/nebula-graphd
tcp 0 0 0.0.0.0:9559 0.0.0.0:* LISTEN 6398/nebula-metad
tcp 0 0 0.0.0.0:19779 0.0.0.0:* LISTEN 6520/nebula-storage
- status查看状态
[root@hdt-dmcp-ops01 bin]# cd /opt/module/nebula/scripts/
[root@hdt-dmcp-ops01 scripts]# ./nebula.service status all
[INFO] nebula-metad(db3c1b3): Running as 6398, Listening on 9559
[INFO] nebula-graphd(db3c1b3): Running as 6467, Listening on 9669
[INFO] nebula-storaged(db3c1b3): Running as 6520, Listening on 9779
- stop关闭服务
[root@hdt-dmcp-ops01 scripts]# ./nebula.service stop all
[INFO] Stopping nebula-metad...
[INFO] Done
[INFO] Stopping nebula-graphd...
[INFO] Done
[INFO] Stopping nebula-storaged...
[INFO] Done
# 关闭服务后再查询服务端口情况,已经没有了相关信息
[root@hdt-dmcp-ops01 scripts]# netstat -tnlpu|grep -E "9559|9669|9779"
[root@hdt-dmcp-ops01 scripts]#
- start开启服务
[root@hdt-dmcp-ops01 scripts]# ./nebula.service start all
[INFO] Starting nebula-metad...
[INFO] Done
[INFO] Starting nebula-graphd...
[INFO] Done
[INFO] Starting nebula-storaged...
[INFO] Done
6-12. 连接NebulaGraph服务 - nebula-console
注意:版本相同的 NebulaGraph Console 和NebulaGraph兼容程度最高,版本不同的 NebulaGraph Console 连接NebulaGraph时,可能会有兼容问题,或者无法连接并报错
incompatible version between client and server
使用语法:
$ ./nebula-console -addr <ip> -port <port> -u <username> -p <password>
[-t 120] [-e "nGQL_statement" | -f filename.nGQL]
参数说明如下:
| 参数 | 说明 |
|---|---|
| -h / -help | 显示帮助菜单。 |
| -addr / -address | 设置要连接的 Graph 服务的 IP 地址。默认地址为 127.0.0.1。 |
| -P / -port | 设置要连接的 Graph 服务的端口。默认端口为 9669。 |
| -u / -user | 设置 Nebula Graph 账号的用户名。未启用身份认证时,可以使用任意已存在的用户名(默认为 root)。 |
| -p / -password | 设置用户名对应的密码。未启用身份认证时,密码可以填写任意字符。 |
| -t / -timeout | 设置整数类型的连接超时时间。单位为毫秒,默认值为 120。 |
| -e / -eval | 设置字符串类型的 nGQL 语句。连接成功后会执行一次该语句并返回结果,然后自动断开连接。 |
| -f / -file | 设置存储 nGQL 语句的文件的路径。连接成功后会执行该文件内的 nGQL 语句并返回结果,执行完毕后自动断开连接。 |
| -enable_ssl | 连接 Nebula Graph 时使用 SSL 加密。 |
| -ssl_root_ca_path | 指定 CA 证书的存储路径。 |
| -ssl_cert_path | 指定 CRT 证书的存储路径。 |
| -ssl_private_key_path | 指定私钥文件的存储路径。 |
使用示例:
# 使用 -e 参数 进行非交互式的查询
[root@hdt-dmcp-ops01 bin]# ./nebula-console -addr hdt-dmcp-ops01 --port 9669 -u root -p nebula -e "SHOW HOSTS;"
(root@nebula) [(none)]> SHOW HOSTS;
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| "172.20.9.6" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.8.117" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.12.179" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.164" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.243" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
Got 5 rows (time spent 942µs/1.253175ms)
Tue, 12 Sep 2023 17:05:23 CST
Bye root!
Tue, 12 Sep 2023 17:05:23 CST
[root@hdt-dmcp-ops01 bin]#
# 使用 -f 将文件中的 nGQL 命令内容执行
[root@hdt-dmcp-ops01 bin]# vim ~/test.nGQL
SHOW HOSTS;
[root@hdt-dmcp-ops01 bin]# ./nebula-console -addr hdt-dmcp-ops01 --port 9669 -u root -p nebula -f ~/test.nGQL
(root@nebula) [(none)]> SHOW HOSTS;
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
| "172.20.9.6" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.8.117" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.12.179" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.164" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
| "172.20.14.243" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.4.0" |
+-----------------+------+----------+--------------+----------------------+------------------------+---------+
Got 5 rows (time spent 759µs/1.061992ms)
Tue, 12 Sep 2023 17:06:41 CST
Bye root!
Tue, 12 Sep 2023 17:06:41 CST
6-13. Storage相关操作
添加Storage主机在6-10章节中有介绍,这里省略
- 删除Storage主机
# 从集群中删除 Storage 主机
nebula> DROP HOSTS <ip>:<port> [,<ip>:<port> ...];
nebula> DROP HOSTS "" :<port> [,"" :<port> ...];
- 查看集群中的 Storage 主机
[root@hdt-dmcp-ops01 ~]# /opt/module/nebula/bin/nebula-console -addr hdt-dmcp-ops01 --port 9669 -u root -p nebula
Welcome to Nebula Graph!
(root@nebula) [(none)]> SHOW HOSTS STORAGE;
+-----------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+-----------------+------+----------+-----------+--------------+---------+
| "172.20.9.6" | 9779 | "ONLINE" | "STORAGE" | "db3c1b3" | "3.4.0" |
| "172.20.8.117" | 9779 | "ONLINE" | "STORAGE" | "db3c1b3" | "3.4.0" |
| "172.20.12.179" | 9779 | "ONLINE" | "STORAGE" | "db3c1b3" | "3.4.0" |
| "172.20.14.164" | 9779 | "ONLINE" | "STORAGE" | "db3c1b3" | "3.4.0" |
| "172.20.14.243" | 9779 | "ONLINE" | "STORAGE" | "db3c1b3" | "3.4.0" |
+-----------------+------+----------+-----------+--------------+---------+
Got 5 rows (time spent 982µs/1.468439ms)
Tue, 12 Sep 2023 17:17:06 CST
7. nGQL操作指南
准备工作1:
nGQL官方示例数据:https://docs.nebula-graph.io/2.0/basketballplayer-2.X.ngql 下载
wget https://docs.nebula-graph.io/2.0/basketballplayer-2.X.ngql
导入测试实验数据:
./nebula-console -addr hdt-dmcp-ops01 --port 9669 -u root -p nebula -f ~/basketballplayer-2.X.ngql
文件中有删除语句
drop space basketballplayer;,因为新部署环境没有这个空间,提示不存在忽视即可。
准备工作2:
当谈论图数据库中的基本术语概念时,初学者容易不好理解,可以使用以下比喻来帮助大家简单理解各属于的概念,便于更好的去操作nGQL:
-
图数据库:
- 想象整个图数据库就像一个庞大的社交网络,其中有成千上万个人和他们之间的各种关系。
-
图:
- 图就像这个社交网络的整个网络,包括所有人和所有可能的社交关系。整个社交网络是一个大图。
-
空间(Graph Space):
- 空间就像是社交网络中的不同社交圈子。每个社交圈子都有一组人和他们之间的关系。例如,家庭、朋友、同事,每个都是一个独立的社交圈子,就像图数据库中的空间。
-
节点:
- 节点就像是社交网络中的个人资料,每个节点代表一个人。节点上有个人的信息,比如姓名、年龄、兴趣爱好等。
-
边:
- 边就像社交网络中的连接,表示人与人之间的各种关系。例如,友谊、家庭关系、工作关系,每种关系都是一种边。
-
子图:
- 子图就像是社交网络中的一个小圈子,包括一组人和他们之间的社交关系。这个小圈子可以是一个独立的社交圈子,也可以是整个社交网络中的一部分。
-
路径:
- 路径就像是社交网络中的一系列社交关系,连接一个人到另一个人。如果你要找出两个人之间的朋友关系,你需要沿着他们之间的路径查找。
如果以上看完还是不清楚这些概念之间的关系,那结合关系型数据库的概念来一起理解Nebula Graph,有助于建立起对 Nebula Graph 数据模型和操作的直观理解。
-
Space(空间):在 Nebula Graph 中,Space 可以类比为数据库。就像关系型数据库中可以有多个数据库,Nebula Graph 中可以有多个 Space。每个 Space 可以看作是一个独立的数据存储区域,用于存储不同类型的数据。
- 比喻:Space 就像是一个大仓库,您可以在仓库中存放不同类型的货物,每个货物都有自己的存储区域。
-
Tag(标签)和 Vertex(顶点):在 Nebula Graph 中,Tag 类似于表,而 Vertex 类似于表中的行。Tag 定义了一组属性,而 Vertex 是具有这些属性值的实体。
- 比喻:Tag 就像是表的结构定义,而 Vertex 就像是表中的每一行数据。比如,一个 “Person” Tag 可以包含属性如姓名、年龄等,而每个 Vertex 则代表一个具体的人,拥有这些属性值。
-
Edge(边):Edge 用于表示 Vertex 之间的关系。Edge 通常连接两个 Vertex,并且可以包含额外的属性信息。
- 比喻:Edge 就像是两个人之间的关系,比如 “朋友关系”。它连接两个人(Vertex)并且可能包含一些关于这个关系的额外信息,比如结交的时间。
-
Schema(模式):Schema 定义了每个 Tag 和 Edge 的结构,包括属性名称、数据类型等。
- 比喻:Schema 就像是建筑工程图纸,它规定了建筑物的结构,包括墙壁、窗户、门等的位置和规格。
-
Space ID、Tag ID 和 Vertex ID:每个 Space、Tag 和 Vertex 都有一个唯一的标识符,用于在数据库中进行访问和管理。
- 比喻:这些 ID 就像是每个仓库、每个货物、每个人都有的唯一身份证号码,帮助系统准确定位和识别它们。
-
查询语言(nGQL):Nebula Graph 使用 nGQL(Nebula Graph Query Language)来执行查询操作,类似于 SQL 用于关系型数据库。
- 比喻:nGQL 就像是您与仓库管理员交流的语言,您可以用它来查询货物、添加货物、检查关系等。
-
分区(Partition):Nebula Graph 中的数据通常被分成多个分区,以提高查询性能和可扩展性。每个分区包含一部分数据。
- 比喻:分区就像是仓库的不同货架,每个货架上存放着一部分货物。这有助于提高取货效率和避免货物拥堵。
-
索引(Index):索引是用于加速查询的数据结构,它们可以帮助您更快地找到需要的信息。
- 比喻:索引就像是仓库的目录或标签,您可以根据目录快速找到需要的货物。
7-1. nGQL概述
7-1-1. 什么是nGQL
nGQL(NebulaGraph Query Language)是 NebulaGraph 使用的的声明式图查询语言,支持灵活高效的图模式,而且 nGQL 是为开发和运维人员设计的类 SQL 查询语言,易于学习。
7-1-2. nGQL 可以做什么
- 支持图遍历
- 支持模式匹配
- 支持聚合
- 支持修改图
- 支持访问控制
- 支持聚合查询
- 支持索引
- 支持大部分 openCypher 9 图查询语法(不支持修改和控制语法)
7-1-3. 占位标识符和占位符值
| 符号 | 含义 |
|---|---|
< > |
语法元素的名称。 |
: |
定义元素的公式。 |
[ ] |
可选元素。 |
{ } |
显式的指定元素。 |
| ` | ` |
... |
可以重复多次。 |
7-1-4. 原生 nGQL 和 openCypher
-
nGQL 语言` = `原生 nGQL 语句` + `openCypher 兼容语句 -
原生 nGQL 是由 NebulaGraph 自行创造和实现的图查询语言。openCypher 是由 openCypher Implementers Group 组织所开源和维护的图查询语言,最新版本为 openCypher 9
7-1-5. Schema-模式
对于图库的知识无储备的情况下,模式相关知识可以延后再查看,否则理解难度较大。
Schema(模式) 在 Nebula Graph 中类似于数据库表的结构定义。它规定了每个 Tag(类似于表)和 Edge(边)的结构,包括属性的名称、数据类型以及其他属性级别的配置。Schema 主要用于定义数据的组织结构,使系统能够有效存储和检索数据。
-
单点模式(Single Point):单点模式是最简单的查询模式,用于查找一个特定的顶点(Vertex)或边(Edge)
- 点用一对括号来描述,通常包含一个名称。例如:
(a)- 示例为一个简单的模式,描述了单个点,并使用变量
a命名该点
-
多点关联模式(Multi-Point Relations):多点关联模式允许您查找与一个或多个顶点相关联的其他顶点或边。这种模式通常用于查找某个节点的邻居节点或关联边。
- 多个点通过边相连是常见的结构,模式用箭头来描述两个点之间的边。例如:
(a)-[]->(b)- 示例为一个简单的数据结构:两个点和一条连接两个点的边,两个点分别为
a和b,边是有方向的,从a到b。
- 这种描述点和边的方式可以扩展到任意数量的点和边,例如:
(a)-[]->(b)<-[]-(c)- 这样的一系列点和边称为
路径(path)。
- 只有在涉及某个点时,才需要命名这个点。如果不涉及这个点,则可以省略名称,例如:
(a)-[]->()<-[]-(c)
- 多个点通过边相连是常见的结构,模式用箭头来描述两个点之间的边。例如:
-
Tag 模式:Tag 模式指的是按照 Tag 类型(类似于关系型数据库中的表)进行查询。它用于查找特定类型的顶点和相关信息。
-
nGQL 中的
Tag概念与 openCypher 中的Label有一些不同。例如,必须创建一个Tag之后才能使用它,而且Tag还定义了属性的类型。 -
模式除了简单地描述图中的点之外,还可以描述点的 Tag。例如:
-
(a:User)-[]->(b)- 模式也可以描述有多个 Tag 的点,例如:
(a:User:Admin)-[]->(b)
-
-
属性模式(Property Pattern):属性模式允许您按照顶点或边的属性值来查询数据。这种模式通常用于根据属性条件筛选数据。
-
点和边是图的基本结构。nGQL 在这两种结构上都可以增加属性,方便实现更丰富的模型
-
在模式中,属性的表示方式为:用花括号括起一些键值对,用英文逗号分隔,并且需要指定属性所属的 Tag 或者 Edge type,例如一个点有两个属性:
(a:player{name: "Tim Duncan", age: 42})
-
在这个点上可以有一条边是:
(a)-[e:follow{degree: 95}]->(b)
-
-
边模式(Edge Pattern):边模式用于查询与边相关的信息。您可以根据边的类型和属性来查找相关的边。
- 描述一条边最简单的方法是使用箭头连接两个点
- 可以用以下方式描述边以及它的方向性。如果不关心边的方向,可以省略箭头,例如:
(a)-[]-(b)
- 和点一样,边也可以命名。一对方括号用于分隔箭头,变量放在两者之间。例如:
(a)-[r]->(b)
- 和点上的 Tag 一样,边也可以有类型。描述边的类型,例如:
(a)-[r:REL_TYPE]->(b)
- 和点上的 Tag 不同,一条边只能有一种 Edge type。但是如果我们想描述多个可选 Edge type,可以用管道符号(|)将可选值分开,例如:
(a)-[r:TYPE1|TYPE2]->(b)
- 和点一样,边的名称可以省略,例如:
(a)-[:REL_TYPE]->(b)
-
变长模式(Variable-Length Pattern):变长模式允许您查找特定顶点之间的路径,路径的长度可以是任意值。这种模式通常用于查找特定关系网络。
-
在图中指定边的长度来描述多条边(以及中间的点)组成的一条长路径,不需要使用多个点和边来描述。例如:
(a)-[*2]->(b)
-
该模式描述了 3 点 2 边组成的图,它们都在一条路径上(长度为 2),等价于:
(a)-[]->()-[]->(b)
-
也可以指定长度范围,这样的边模式称为
variable-length edges,例如:(a)-[*3..5]->(b)*3..5表示最小长度为 3,最大长度为 5。- 该模式描述了 4 点 3 边、5 点 4 边或 6 点 5 边组成的图。
-
也可以忽略最小长度,只指定最大长度,例如:
(a)-[*..5]->(b)
-
必须指定最大长度,不支持仅指定最小长度(
(a)-[*3..]->(b))或都不指定((a)-[*]->(b))。
-
-
路径变量
- 一系列连接的点和边称为
路径。nGQL 允许使用变量来命名路径,例如:p = (a)-[*3..5]->(b)- 可以在 MATCH 语句中使用路径变量
- 一系列连接的点和边称为
7-1-6. 注释
NebulaGraph 支持三种注释方式:#、//、/* */。
示例:
nebula> # 这行什么都不做。
nebula> RETURN 1+1; # 这条注释延续到行尾。
nebula> RETURN 1+1; // 这条注释延续到行尾。
nebula> RETURN 1 /* 这是一条行内注释 */ + 1 == 2;
nebula> RETURN 11 + \
/* 多行注释 \
用反斜线来换行。 \
*/ 12;
nGQL 语句中的反斜线(\)代表换行
OpenCypher 兼容性
- 在 nGQL 中,用户必须在行末使用反斜线(\)来换行,即使是在使用
/* */符号的多行注释内。 - 在 openCypher 中不需要使用反斜线换行。
/* openCypher 风格:
这条注释
延续了不止
一行 */
MATCH (n:label)
RETURN n;
/* 原生 nGQL 风格: \
这条注释 \
延续了不止 \
一行 */ \
MATCH (n:tag) \
RETURN n;
7-1-7. 大小写区分
- 标识符区分大小写
以下语句会出现错误,因为
my_space和MY_SPACE是两个不同的图空间。
nebula> CREATE SPACE IF NOT EXISTS my_space (vid_type=FIXED_STRING(30));
nebula> use MY_SPACE;
[ERROR (-1005)]: SpaceNotFound:
- 关键字不区分大小写
以下语句是等价的,因为
show和spaces是关键字。
nebula> show spaces;
nebula> SHOW SPACES;
nebula> SHOW spaces;
nebula> show SPACES;
- 函数不区分大小写
函数名称不区分大小写,例如
count()、COUNT()、couNT()是等价的。
nebula> WITH [NULL, 1, 1, 2, 2] As a \
UNWIND a AS b \
RETURN count(b), COUNT(*), couNT(DISTINCT b);
+----------+----------+-------------------+
| count(b) | COUNT(*) | couNT(distinct b) |
+----------+----------+-------------------+
| 4 | 5 | 2 |
+----------+----------+-------------------+
7-1-8. 数据类型
- 数值
- 布尔
- 字符串
- 日期时间
- NULL
- 列表
- 集合
- 映射
- 类型转换
- 地理位置
根据业务需求可以自行在官网地址查看详情:https://docs.nebula-graph.com.cn/3.4.0/3.ngql-guide/3.data-types/1.numeric/
7-2. 图空间SPACE操作
- 图空间是 NebulaGraph 中彼此隔离的图数据集合,与 MySQL 中的 database 概念类似。
CREATE SPACE语句可以创建一个新的图空间,或者克隆现有图空间的 Schema- 只有 God 角色的用户可以执行
CREATE SPACE语句
- 创建图空间
CREATE SPACE [IF NOT EXISTS] (
[partition_num = ,]
[replica_factor = ,]
vid_type = {FIXED_STRING() | INT[64]}
)
[COMMENT = ''];
示例:
# 仅指定 VID 类型,其他选项使用默认值。
nebula> CREATE SPACE IF NOT EXISTS my_space_1 (vid_type=FIXED_STRING(30));
# 指定分片数量、副本数量和 VID 类型。
nebula> CREATE SPACE IF NOT EXISTS my_space_2 (partition_num=15, replica_factor=1, vid_type=FIXED_STRING(30));
# 指定分片数量、副本数量和 VID 类型,并添加描述。
nebula> CREATE SPACE IF NOT EXISTS my_space_3 (partition_num=15, replica_factor=1, vid_type=FIXED_STRING(30)) comment="测试图空间";
- 克隆图空间
CREATE SPACE [IF NOT EXISTS] AS ;
示例:
# 克隆图空间。
nebula> CREATE SPACE IF NOT EXISTS my_space_4 as my_space_3;
- 检查分片分布情况
nebula> SHOW HOSTS;
- 空间分片均衡负载实施
nebula> BALANCE LEADER;
- 切换空间SPACE
USE ;
示例:
# 创建示例空间。
nebula> CREATE SPACE IF NOT EXISTS space1 (vid_type=FIXED_STRING(30));
nebula> CREATE SPACE IF NOT EXISTS space2 (vid_type=FIXED_STRING(30));
# 指定图空间 space1 作为工作空间。
nebula> USE space1;
# 切换到图空间 space2。检索 space2 时,无法从 space1 读取任何数据,检索的点和边与 space1 无关。
nebula> USE space2;
- 查看空间SPACE清单
SHOW SPACES;nebula> SHOW SPACES;
+--------------------+
| Name |
+--------------------+
| "cba" |
| "basketballplayer" |
+--------------------+
- 查看空间SPACE结构
DESC[RIBE] SPACE
nebula> DESCRIBE SPACE basketballplayer;
- 清空空间SPACE数据
CLEAR SPACE [IF EXISTS] ;
CLEAR SPACE语句用于清空图空间中的点和边,但不会删除图空间本身以及其中的 Schema 信息- 建议在执行
CLEAR SPACE操作之后,立即执行SUBMIT JOB COMPACT操作以提升查询性能。需要注意的是,COMPACT 操作可能会影响查询性能,建议在业务低峰期(例如凌晨)执行该操作。
注意事项:
- 数据清除后,如无备份,无法恢复。使用该功能务必谨慎
CLEAR SPACE不是原子性操作。如果执行出错,请重新执行,避免残留数据。- 图空间中的数据量越大,
CLEAR SPACE消耗的时间越长。如果CLEAR SPACE的执行因客户端连接超时而失败,可以增大 Graph 服务配置中storage_client_timeout_ms参数的值。- 在
CLEAR SPACE的执行过程中,向该图空间写入数据的行为不会被自动禁止。这样的写入行为可能导致CLEAR SPACE清除数据不完全,残留的数据也可能受到损坏。
- 删除空间SPACE
DROP SPACE语句用于删除指定图空间以及其中的所有信息
DROP SPACE是否删除图空间对应的硬盘数据由 Storage 配置参数auto_remove_invalid_space决定。auto_remove_invalid_space的默认值为true,表示会删除数据。如需在删除逻辑图空间时保留硬盘数据,将auto_remove_invalid_space的值修改为false。
7-3. 图库标签 Tag
标签(Tag):
-
标签类似于关系数据库中的表,但它们用于存储节点(Vertex)数据。每个标签定义了一组具有相似属性的节点。例如,如果您在 Nebula 图数据库中存储个人资料,可以有一个标签 “Person” 来表示个人节点,其中包含了姓名、年龄、兴趣爱好等属性。每个标签就像是一个表,其中包含了具有相同结构的节点。
-
创建tag
nebula> CREATE TAG IF NOT EXISTS player(name string, age int);
# 创建没有属性的 Tag。
nebula> CREATE TAG IF NOT EXISTS no_property();
# 创建包含默认值的 Tag。
nebula> CREATE TAG IF NOT EXISTS player_with_default(name string, age int DEFAULT 20);
# 对字段 create_time 设置 TTL 为 100 秒。
nebula> CREATE TAG IF NOT EXISTS woman(name string, age int, \
married bool, salary double, create_time timestamp) \
TTL_DURATION = 100, TTL_COL = "create_time";
- 删除Tag
DROP TAG [IF EXISTS] ;
- 修改Tag
ALTER TAG语句可以修改 Tag 的结构。例如增删属性、修改数据类型,也可以为属性设置、修改TTL
nebula> CREATE TAG IF NOT EXISTS t1 (p1 string, p2 int);
nebula> ALTER TAG t1 ADD (p3 int32, p4 fixed_string(10));
nebula> ALTER TAG t1 TTL_DURATION = 2, TTL_COL = "p2";
nebula> ALTER TAG t1 COMMENT = 'test1';
nebula> ALTER TAG t1 ADD (p5 double NOT NULL DEFAULT 0.4 COMMENT 'p5') COMMENT='test2';
// 将 TAG t1 的 p3 属性类型从 INT32 改为 INT64,p4 属性类型从 FIXED_STRING(10) 改为 STRING。
nebula> ALTER TAG t1 CHANGE (p3 int64, p4 string);
- Tag清单
SHOW TAGS语句显示当前图空间内的所有 Tag 名称
nebula> SHOW TAGS;
+----------+
| Name |
+----------+
| "player" |
| "team" |
+----------+
- 查看Tag结构
DESCRIBE TAG显示指定 Tag 的详细信息,例如字段名称、数据类型等
nebula> DESCRIBE TAG player;
+--------+----------+-------+---------+---------+
| Field | Type | Null | Default | Comment |
+--------+----------+-------+---------+---------+
| "name" | "string" | "YES" | | |
| "age" | "int64" | "YES" | | |
+--------+----------+-------+---------+---------+
- 删除Tag
DELETE TAG FROM ;
-
tag_name_list:指定 Tag 名称。多个 Tag 用英文逗号(,)分隔,也可以用*表示所有 Tag。 -
VID:指定要删除 Tag 的点 ID。
示例:
nebula> CREATE TAG IF NOT EXISTS test1(p1 string, p2 int);
nebula> CREATE TAG IF NOT EXISTS test2(p3 string, p4 int);
nebula> INSERT VERTEX test1(p1, p2),test2(p3, p4) VALUES "test":("123", 1, "456", 2);
nebula> FETCH PROP ON * "test" YIELD vertex AS v;
+------------------------------------------------------------+
| v |
+------------------------------------------------------------+
| ("test" :test1{p1: "123", p2: 1} :test2{p3: "456", p4: 2}) |
+------------------------------------------------------------+
nebula> DELETE TAG test1 FROM "test";
nebula> FETCH PROP ON * "test" YIELD vertex AS v;
+-----------------------------------+
| v |
+-----------------------------------+
| ("test" :test2{p3: "456", p4: 2}) |
+-----------------------------------+
nebula> DELETE TAG * FROM "test";
nebula> FETCH PROP ON * "test" YIELD vertex AS v;
+---+
| v |
+---+
+---+
在 openCypher 中,有增加标签(
SET label)和移除标签(REMOVE label)的功能,可以用于加速查询或者标记过程。在 NebulaGraph 中,可以通过 Tag 变相实现相同操作,创建 Tag 并将 Tag 插入到已有的点上,就可以根据 Tag 名称快速查找点,也可以通过
DELETE TAG删除某些点上不再需要的 Tag。
7-4. 图库边类型 Edge Type
边类型(Edge Type):
- 边类型也类似于关系数据库中的表,但它们用于存储节点之间的关系或连接。边类型定义了一种关系的结构,例如友谊、家庭关系、工作关系等。边类型中包含了连接两个节点的边,这些边上可能还有属性,用来描述关系的特征。每个边类型就像是一个表,用于存储不同类型的节点之间的连接。
nGQL 中的 Edge type 和 openCypher 中的关系类型相似,但又有所不同,例如它们的创建方式。
-
openCypher 中的关系类型需要在
CREATE语句中与点一起创建。 -
nGQL 中的 Edge type 需要使用
CREATE EDGE语句独立创建。Edge type 更像是 MySQL 中的表。 -
创建EDGE
nebula> CREATE EDGE IF NOT EXISTS follow(degree int);
# 创建没有属性的 Edge type。
nebula> CREATE EDGE IF NOT EXISTS no_property();
# 创建包含默认值的 Edge type。
nebula> CREATE EDGE IF NOT EXISTS follow_with_default(degree int DEFAULT 20);
# 对字段 p2 设置 TTL 为 100 秒。
nebula> CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int, p3 timestamp) \
TTL_DURATION = 100, TTL_COL = "p2";
- 删除EDGE
DROP EDGE [IF EXISTS]
-
IF EXISTS:检测待删除的 Edge type 是否存在,只有存在时,才会删除 Edge type。 -
edge_type_name:指定要删除的 Edge type 名称。一次只能删除一个 Edge type。
示例:
nebula> CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int);
nebula> DROP EDGE e1;
- 修改EDGE
ALTER EDGE语句可以修改 Edge type 的结构。例如增删属性、修改数据类型,也可以为属性设置、修改TTL
注意事项:
- 登录的用户必须拥有对应权限才能执行
ALTER EDGE语句 - 确保要修改的属性不包含索引,否则
ALTER EDGE时会报冲突错误[ERROR (-1005)]: Conflict!。 - 确保新增的属性名不与已存在或被删除的属性名同名,否则新增属性会失败。
- 允许增加
FIXED_STRING和INT类型的长度。 - 允许
FIXED_STRING类型转换为STRING类型、FLOAT类型转换为DOUBLE类型。
语法:
ALTER EDGE
[, alter_definition] ...]
[ttl_definition [, ttl_definition] ... ]
[COMMENT = ''];
alter_definition:
| ADD (prop_name data_type)
| DROP (prop_name)
| CHANGE (prop_name data_type)
ttl_definition:
TTL_DURATION = ttl_duration, TTL_COL = prop_name
-
edge_type_name:指定要修改的 Edge type 名称。一次只能修改一个 Edge type。请确保要修改的 Edge type 在当前工作空间中存在,否则会报错。 -
可以在一个
ALTER EDGE语句中使用多个ADD、DROP和CHANGE子句,子句之间用英文逗号(,)分隔。 -
当使用
ADD或CHANGE指定属性值为NOT NULL时,必需为该属性指定默认值,即定义DEFAULT的值。
示例:
nebula> CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int);
nebula> ALTER EDGE e1 ADD (p3 int, p4 string);
nebula> ALTER EDGE e1 TTL_DURATION = 2, TTL_COL = "p2";
nebula> ALTER EDGE e1 COMMENT = 'edge1';
- EDGE清单
nebula> SHOW EDGES;
+----------+
| Name |
+----------+
| "follow" |
| "serve" |
+----------+
- EDGE结构查看
nebula> DESCRIBE EDGE follow;
+----------+---------+-------+---------+---------+
| Field | Type | Null | Default | Comment |
+----------+---------+-------+---------+---------+
| "degree" | "int64" | "YES" | | |
+----------+---------+-------+---------+---------+
7-5. 点语句 vertex
- insert
INSERT VERTEX语句可以在 NebulaGraph 实例的指定图空间中插入一个或多个点
语法:
INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...]
VALUES VID: ([prop_value_list])
tag_props:
tag_name ([prop_name_list])
prop_name_list:
[prop_name [, prop_name] ...]
prop_value_list:
[prop_value [, prop_value] ...]
示例:
# 插入不包含属性的点。
nebula> CREATE TAG IF NOT EXISTS t1();
nebula> INSERT VERTEX t1() VALUES "10":();
nebula> CREATE TAG IF NOT EXISTS t2 (name string, age int);
nebula> INSERT VERTEX t2 (name, age) VALUES "11":("n1", 12);
# 创建失败,因为"a13"不是 int 类型。
nebula> INSERT VERTEX t2 (name, age) VALUES "12":("n1", "a13");
# 一次插入 2 个点。
nebula> INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8);
nebula> CREATE TAG IF NOT EXISTS t3(p1 int);
nebula> CREATE TAG IF NOT EXISTS t4(p2 string);
# 一次插入两个 Tag 的属性到同一个点。
nebula> INSERT VERTEX t3 (p1), t4(p2) VALUES "21": (321, "hello");
# 一个点可以多次插入属性值,以最后一次为准
# 多次插入属性值。
nebula> INSERT VERTEX t2 (name, age) VALUES "11":("n2", 13);
nebula> INSERT VERTEX t2 (name, age) VALUES "11":("n3", 14);
nebula> INSERT VERTEX t2 (name, age) VALUES "11":("n4", 15);
nebula> FETCH PROP ON t2 "11" YIELD properties(vertex);
+-----------------------+
| properties(VERTEX) |
+-----------------------+
| {age: 15, name: "n4"} |
+-----------------------+
nebula> CREATE TAG IF NOT EXISTS t5(p1 fixed_string(5) NOT NULL, p2 int, p3 int DEFAULT NULL);
nebula> INSERT VERTEX t5(p1, p2, p3) VALUES "001":("Abe", 2, 3);
# 插入失败,因为属性 p1 不能为 NULL。
nebula> INSERT VERTEX t5(p1, p2, p3) VALUES "002":(NULL, 4, 5);
[ERROR (-1009)]: SemanticError: No schema found for `t5'
# 属性 p3 为默认值 NULL。
nebula> INSERT VERTEX t5(p1, p2) VALUES "003":("cd", 5);
nebula> FETCH PROP ON t5 "003" YIELD properties(vertex);
+---------------------------------+
| properties(VERTEX) |
+---------------------------------+
| {p1: "cd", p2: 5, p3: __NULL__} |
+---------------------------------+
# 属性 p1 最大长度为 5,因此会被截断。
nebula> INSERT VERTEX t5(p1, p2) VALUES "004":("shalalalala", 4);
nebula> FETCH PROP on t5 "004" YIELD properties(vertex);
+------------------------------------+
| properties(VERTEX) |
+------------------------------------+
| {p1: "shala", p2: 4, p3: __NULL__} |
+------------------------------------+
- delete
DELETE VERTEX语句可以删除点,但是默认不删除该点关联的出边和入边
语法:
DELETE VERTEX [ , ... ] [WITH EDGE];
WITH EDGE: 删除该点关联的出边和入边。
示例:
# 删除 VID 为 `team1` 的点,不删除该点关联的出边和入边。
nebula> DELETE VERTEX "team1";
# 删除 VID 为 `team1` 的点,并删除该点关联的出边和入边。
nebula> DELETE VERTEX "team1" WITH EDGE;
# 结合管道符,删除符合条件的点。
nebula> GO FROM "player100" OVER serve WHERE properties(edge).start_year == "2021" YIELD dst(edge) AS id | DELETE VERTEX $-.id;
- update
UPDATE VERTEX语句可以修改点上 Tag 的属性值。
语法:
UPDATE VERTEX ON
SET
[WHEN ]
[YIELD 示例:
// 查看点”player101“的属性。
nebula> FETCH PROP ON player "player101" YIELD properties(vertex);
+--------------------------------+
| properties(VERTEX) |
+--------------------------------+
| {age: 36, name: "Tony Parker"} |
+--------------------------------+
// 修改属性 age 的值,并返回 name 和新的 age。
nebula> UPDATE VERTEX ON player "player101" \
SET age = age + 2 \
WHEN name == "Tony Parker" \
YIELD name AS Name, age AS Age;
+---------------+-----+
| Name | Age |
+---------------+-----+
| "Tony Parker" | 38 |
+---------------+-----+
- upsert
UPSERT VERTEX语句结合UPDATE和INSERT,如果点存在,会修改点的属性值;如果点不存在,会插入新的点UPSERT VERTEX性能远低于INSERT,因为UPSERT是一组分片级别的读取、修改、写入操作。
语法:
UPSERT VERTEX ON
SET
[WHEN ]
[YIELD 示例:
// 查看三个点是否存在,结果 “Empty set” 表示顶点不存在。
nebula> FETCH PROP ON * "player666", "player667", "player668" YIELD properties(vertex);
+--------------------+
| properties(VERTEX) |
+--------------------+
+--------------------+
Empty set
nebula> UPSERT VERTEX ON player "player666" \
SET age = 30 \
WHEN name == "Joe" \
YIELD name AS Name, age AS Age;
+----------+----------+
| Name | Age |
+----------+----------+
| __NULL__ | 30 |
+----------+----------+
nebula> UPSERT VERTEX ON player "player666" \
SET age = 31 \
WHEN name == "Joe" \
YIELD name AS Name, age AS Age;
+----------+-----+
| Name | Age |
+----------+-----+
| __NULL__ | 30 |
+----------+-----+
nebula> UPSERT VERTEX ON player "player667" \
SET age = 31 \
YIELD name AS Name, age AS Age;
+----------+-----+
| Name | Age |
+----------+-----+
| __NULL__ | 31 |
+----------+-----+
nebula> UPSERT VERTEX ON player "player668" \
SET name = "Amber", age = age + 1 \
YIELD name AS Name, age AS Age;
+---------+----------+
| Name | Age |
+---------+----------+
| "Amber" | __NULL__ |
+---------+----------+
7-6. 边语句 edge
- insert
INSERT EDGE语句可以在 NebulaGraph 实例的指定图空间中插入一条或多条边。边是有方向的,从起始点(src_vid)到目的点(dst_vid)。INSERT EDGE的执行方式为覆盖式插入。如果已有 Edge type、起点、终点、rank 都相同的边,则覆盖原边。
语法:
INSERT EDGE [IF NOT EXISTS] <edge_type> ( <prop_name_list> ) VALUES
<src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> )
[, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...];
<prop_name_list> ::=
[ <prop_name> [, <prop_name> ] ...]
<prop_value_list> ::=
[ <prop_value> [, <prop_value> ] ...]
-
-
-
src_vid:起始点 ID,表示边的起点。 -
dst_vid:目的点 ID,表示边的终点。 -
rank:可选项。边的 rank 值。默认值为0。 -
prop_name_list填写属性值。如果属性值和 Edge type 中的数据类型不匹配,会返回错误。如果没有填写属性值,而 Edge type 中对应的属性设置为NOT NULL,也会返回错误。
示例:
# 插入不包含属性的边。
nebula> CREATE EDGE IF NOT EXISTS e1();
nebula> INSERT EDGE e1 () VALUES "10"->"11":();
# 插入 rank 为 1 的边。
nebula> INSERT EDGE e1 () VALUES "10"->"11"@1:();
nebula> CREATE EDGE IF NOT EXISTS e2 (name string, age int);
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 1);
# 一次插入 2 条边。
nebula> INSERT EDGE e2 (name, age) VALUES \
"12"->"13":("n1", 1), "13"->"14":("n2", 2);
# 创建失败,因为"a13"不是 int 类型。
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", "a13");
# 多次插入属性值。
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 12);
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 13);
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 14);
nebula> FETCH PROP ON e2 "11"->"13" YIELD edge AS e;
+-------------------------------------------+
| e |
+-------------------------------------------+
| [:e2 "11"->"13" @0 {age: 14, name: "n1"}] |
+-------------------------------------------+
- delete
DELETE EDGE语句可以删除边。一次可以删除一条或多条边。用户可以结合管道符一起使用- 如果需要删除一个点的所有出边,请删除这个点。
语法:
DELETE EDGE -> [@] [, -> [@] ...]
示例:
nebula> DELETE EDGE serve "player100" -> "team204"@0;
# 结合管道符,删除两点之间同类型的所有rank的边。
nebula> GO FROM "player100" OVER follow \
WHERE dst(edge) == "player101" \
YIELD src(edge) AS src, dst(edge) AS dst, rank(edge) AS rank \
| DELETE EDGE follow $-.src -> $-.dst @ $-.rank;
- update
UPDATE EDGE语句可以修改边上 Edge type 的属性。
语法:
UPDATE EDGE ON
-> [@]
SET
[WHEN ]
[YIELD 示例:
// 用 GO 语句查看边的属性值。
nebula> GO FROM "player100" \
OVER serve \
YIELD properties(edge).start_year, properties(edge).end_year;
+-----------------------------+---------------------------+
| properties(EDGE).start_year | properties(EDGE).end_year |
+-----------------------------+---------------------------+
| 1997 | 2016 |
+-----------------------------+---------------------------+
// 修改属性 start_year 的值,并返回 end_year 和新的 start_year。
nebula> UPDATE EDGE ON serve "player100" -> "team204"@0 \
SET start_year = start_year + 1 \
WHEN end_year > 2010 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 1998 | 2016 |
+------------+----------+
- upsert
UPSERT EDGE语句结合UPDATE和INSERT,如果边存在,会更新边的属性;如果边不存在,会插入新的边。UPSERT EDGE性能远低于INSERT,因为UPSERT是一组分片级别的读取、修改、写入操作。
语法:
UPSERT EDGE ON
-> [@rank]
SET
[WHEN ]
[YIELD ]
示例:
// 查看如下三个点是否有 serve 类型的出边,结果 “Empty set” 表示没有 serve 类型的出边。
nebula> GO FROM "player666", "player667", "player668" \
OVER serve \
YIELD properties(edge).start_year, properties(edge).end_year;
+-----------------------------+---------------------------+
| properties(EDGE).start_year | properties(EDGE).end_year |
+-----------------------------+---------------------------+
+-----------------------------+---------------------------+
Empty set
nebula> UPSERT EDGE on serve \
"player666" -> "team200"@0 \
SET end_year = 2021 \
WHEN end_year == 2010 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| __NULL__ | 2021 |
+------------+----------+
nebula> UPSERT EDGE on serve \
"player666" -> "team200"@0 \
SET end_year = 2022 \
WHEN end_year == 2010 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| __NULL__ | 2021 |
+------------+----------+
nebula> UPSERT EDGE on serve \
"player667" -> "team200"@0 \
SET end_year = 2022 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| __NULL__ | 2022 |
+------------+----------+
nebula> UPSERT EDGE on serve \
"player668" -> "team200"@0 \
SET start_year = 2000, end_year = end_year + 1 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 2000 | __NULL__ |
+------------+----------+
上面最后一个示例中,因为end_year没有默认值,插入边时,end_year默认值为NULL,执行end_year = end_year + 1后仍为NULL。如果end_year有默认值,则end_year = end_year + 1可以正常执行,例如:
nebula> CREATE EDGE IF NOT EXISTS serve_with_default(start_year int, end_year int DEFAULT 2010);
Execution succeeded
nebula> UPSERT EDGE on serve_with_default \
"player668" -> "team200" \
SET end_year = end_year + 1 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| __NULL__ | 2011 |
+------------+----------+
如果边存在,且满足WHEN子句的条件,就会修改边的属性值。
nebula> MATCH (v:player{name:"Ben Simmons"})-[e:serve]-(v2) \
RETURN e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player149"->"team219" @0 {end_year: 2019, start_year: 2016}] |
+-----------------------------------------------------------------------+
nebula> UPSERT EDGE on serve \
"player149" -> "team219" \
SET end_year = end_year + 1 \
WHEN start_year == 2016 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 2016 | 2020 |
+------------+----------+
如果边存在,但是不满足WHEN子句的条件,修改不会生效
nebula> MATCH (v:player{name:"Ben Simmons"})-[e:serve]-(v2) \
RETURN e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player149"->"team219" @0 {end_year: 2020, start_year: 2016}] |
+-----------------------------------------------------------------------+
nebula> UPSERT EDGE on serve \
"player149" -> "team219" \
SET end_year = end_year + 1 \
WHEN start_year != 2016 \
YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 2016 | 2020 |
+------------+----------+
7-7. 通用查询语句
7-7-1. MATCH
MATCH语句提供基于模式(pattern)匹配的搜索功能。
一个MATCH语句定义了一个搜索模式,用该模式匹配存储在 NebulaGraph 中的数据,然后用RETURN子句检索数据。
nebula> MATCH (v) \
RETURN v \
LIMIT 3;
+-----------------------------------------------------------+
| v |
+-----------------------------------------------------------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("player115" :player{age: 40, name: "Kobe Bryant"}) |
+-----------------------------------------------------------+
nebula> MATCH (v:player) \
RETURN v \
LIMIT 3;
+-----------------------------------------------------------+
| v |
+-----------------------------------------------------------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("player115" :player{age: 40, name: "Kobe Bryant"}) |
+-----------------------------------------------------------+
...
# 使用属性 name 搜索匹配的点。
nebula> MATCH (v:player{name:"Tim Duncan"}) \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
nebula> MATCH (v) \
WITH v, properties(v) as props, keys(properties(v)) as kk \
LIMIT 10000 WHERE [i in kk where props[i] == "Tim Duncan"] \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
nebula> MATCH (v:player{name:"Tim Duncan"})--(v2) \
RETURN \
CASE WHEN v2.team.name IS NOT NULL \
THEN v2.team.name \
WHEN v2.player.name IS NOT NULL \
THEN v2.player.name END AS Name;
+---------------------+
| Name |
+---------------------+
| "Manu Ginobili" |
| "Manu Ginobili" |
| "Spurs" |
| "Dejounte Murray" |
...
nebula> MATCH ()-[e]->() \
WITH e, properties(e) as props, keys(properties(e)) as kk \
LIMIT 10000 WHERE [i in kk where props[i] == 90] \
RETURN e;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player125"->"player100" @0 {degree: 90}] |
| [:follow "player140"->"player114" @0 {degree: 90}] |
| [:follow "player133"->"player144" @0 {degree: 90}] |
| [:follow "player133"->"player114" @0 {degree: 90}] |
...
+----------------------------------------------------+
7-7-2. OPTIONAL MATCH
OPTIONAL MATCH通常与MATCH语句一起使用,作为MATCH语句的可选项去匹配命中的模式,如果没有命中对应的模式,对应的列返回NULL。
nebula> MATCH (m)-[]->(n) WHERE id(m)=="player100" \
OPTIONAL MATCH (n)-[]->(l) \
RETURN id(m),id(n),id(l);
+-------------+-------------+-------------+
| id(m) | id(n) | id(l) |
+-------------+-------------+-------------+
| "player100" | "team204" | __NULL__ |
| "player100" | "player101" | "team204" |
| "player100" | "player101" | "team215" |
| "player100" | "player101" | "player100" |
| "player100" | "player101" | "player102" |
| "player100" | "player101" | "player125" |
| "player100" | "player125" | "team204" |
| "player100" | "player125" | "player100" |
+-------------+-------------+-------------+
nebula> MATCH (m)-[]->(n) WHERE id(m)=="player100" \
MATCH (n)-[]->(l) \
RETURN id(m),id(n),id(l);
+-------------+-------------+-------------+
| id(m) | id(n) | id(l) |
+-------------+-------------+-------------+
| "player100" | "player101" | "team204" |
| "player100" | "player101" | "team215" |
| "player100" | "player101" | "player100" |
| "player100" | "player101" | "player102" |
| "player100" | "player101" | "player125" |
| "player100" | "player125" | "team204" |
| "player100" | "player125" | "player100" |
+-------------+-------------+-------------+
7-7-3. LOOKUP
LOOKUP根据索引遍历数据。用户可以使用LOOKUP实现如下功能:
-
根据
WHERE子句搜索特定数据。 -
通过 Tag 列出点:检索指定 Tag 的所有点 ID。
-
通过 Edge type 列出边:检索指定 Edge type 的所有边的起始点、目的点和 rank。
-
统计包含指定 Tag 的点或属于指定 Edge type 的边的数量。
nebula> CREATE TAG IF NOT EXISTS player(name string,age int);
nebula> CREATE TAG INDEX IF NOT EXISTS player_index on player();
nebula> REBUILD TAG INDEX player_index;
+------------+
| New Job Id |
+------------+
| 66 |
+------------+
nebula> INSERT VERTEX player(name,age) \
VALUES "player100":("Tim Duncan", 42), "player101":("Tony Parker", 36);
# 列出所有的 player。类似于 MATCH (n:player) RETURN id(n) /*, n */。
nebula> LOOKUP ON player YIELD id(vertex);
+-------------+
| id(VERTEX) |
+-------------+
| "player100" |
| "player101" |
...
# 从结果中返回最前面的 4 行数据。
nebula> LOOKUP ON player YIELD id(vertex) | LIMIT 4;
+-------------+
| id(VERTEX) |
+-------------+
| "player105" |
| "player109" |
| "player111" |
| "player118" |
+-------------+
nebula> CREATE EDGE IF NOT EXISTS follow(degree int);
nebula> CREATE EDGE INDEX IF NOT EXISTS follow_index on follow();
nebula> REBUILD EDGE INDEX follow_index;
+------------+
| New Job Id |
+------------+
| 88 |
+------------+
nebula> INSERT EDGE follow(degree) \
VALUES "player100"->"player101":(95);
# 列出所有的 follow 边。类似于 MATCH (s)-[e:follow]->(d) RETURN id(s), rank(e), id(d) /*, type(e) */。
nebula)> LOOKUP ON follow YIELD edge AS e;
+-----------------------------------------------------+
| e |
+-----------------------------------------------------+
| [:follow "player105"->"player100" @0 {degree: 70}] |
| [:follow "player105"->"player116" @0 {degree: 80}] |
| [:follow "player109"->"player100" @0 {degree: 80}] |
...
7-7-4. GO
GO从给定起始点开始遍历图。GO语句采用的路径类型是walk,即遍历时点和边都可以重复
# 返回 player102 所属队伍。
nebula> GO FROM "player102" OVER serve YIELD dst(edge);
+-----------+
| dst(EDGE) |
+-----------+
| "team203" |
| "team204" |
+-----------+
# 返回距离 player102 两跳的朋友。
nebula> GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player101" |
| "player125" |
| "player100" |
| "player102" |
| "player125" |
+-------------+
# 添加过滤条件。
nebula> GO FROM "player100", "player102" OVER serve \
WHERE properties(edge).start_year > 1995 \
YIELD DISTINCT properties($$).name AS team_name, properties(edge).start_year AS start_year, properties($^).name AS player_name;
+-----------------+------------+---------------------+
| team_name | start_year | player_name |
+-----------------+------------+---------------------+
| "Spurs" | 1997 | "Tim Duncan" |
| "Trail Blazers" | 2006 | "LaMarcus Aldridge" |
| "Spurs" | 2015 | "LaMarcus Aldridge" |
+-----------------+------------+---------------------+
# 返回 player100 入方向的邻居点。
nebula> GO FROM "player100" OVER follow REVERSELY \
YIELD src(edge) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player102" |
...
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
nebula> MATCH (v)<-[e:follow]- (v2) WHERE id(v) == 'player100' \
RETURN id(v2) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player102" |
...
# 查询 player100 1~2 跳内的朋友。
nebula> GO 1 TO 2 STEPS FROM "player100" OVER follow \
YIELD dst(edge) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player125" |
...
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
nebula> MATCH (v) -[e:follow*1..2]->(v2) \
WHERE id(v) == "player100" \
RETURN id(v2) AS destination;
+-------------+
| destination |
+-------------+
| "player100" |
| "player102" |
...
# 分组并限制输出结果的行数。
nebula> $a = GO FROM "player100" OVER follow YIELD src(edge) AS src, dst(edge) AS dst; \
GO 2 STEPS FROM $a.dst OVER follow \
YIELD $a.src AS src, $a.dst, src(edge), dst(edge) \
| ORDER BY $-.src | OFFSET 1 LIMIT 2;
+-------------+-------------+-------------+-------------+
| src | $a.dst | src(EDGE) | dst(EDGE) |
+-------------+-------------+-------------+-------------+
| "player100" | "player125" | "player100" | "player101" |
| "player100" | "player101" | "player100" | "player125" |
+-------------+-------------+-------------+-------------+
7-7-5. FETCH
FETCH可以获取指定点或边的属性值。
nebula> FETCH PROP ON player "player101", "player102", "player103" YIELD properties(vertex);
+--------------------------------------+
| properties(VERTEX) |
+--------------------------------------+
| {age: 33, name: "LaMarcus Aldridge"} |
| {age: 36, name: "Tony Parker"} |
| {age: 32, name: "Rudy Gay"} |
+--------------------------------------+
# 创建新 Tag t1。
nebula> CREATE TAG IF NOT EXISTS t1(a string, b int);
# 为点 player100 添加 Tag t1。
nebula> INSERT VERTEX t1(a, b) VALUES "player100":("Hello", 100);
# 基于 Tag player 和 t1 获取点 player100 上的属性值。
nebula> FETCH PROP ON player, t1 "player100" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
+----------------------------------------------------------------------------+
nebula> FETCH PROP ON * "player100", "player106", "team200" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("team200" :team{name: "Warriors"}) |
+----------------------------------------------------------------------------+
# 获取连接 player100 和 team204 的边 serve 的所有属性值。
nebula> FETCH PROP ON serve "player100" -> "team204" YIELD properties(edge);
+------------------------------------+
| properties(EDGE) |
+------------------------------------+
| {end_year: 2016, start_year: 1997} |
+------------------------------------+
# 返回从点 player101 开始的 follow 边的 degree 值。
nebula> GO FROM "player101" OVER follow \
YIELD src(edge) AS s, dst(edge) AS d \
| FETCH PROP ON follow $-.s -> $-.d \
YIELD properties(edge).degree;
+-------------------------+
| properties(EDGE).degree |
+-------------------------+
| 95 |
| 90 |
| 95 |
+-------------------------+
7-7-6. SHOW
SHOW CHARSET语句显示当前的字符集
nebula> SHOW CHARSET;
+---------+-----------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-----------------+-------------------+--------+
| "utf8" | "UTF-8 Unicode" | "utf8_bin" | 4 |
+---------+-----------------+-------------------+--------+
SHOW COLLATION语句显示当前的排序规则
nebula> SHOW COLLATION;
+------------+---------+
| Collation | Charset |
+------------+---------+
| "utf8_bin" | "utf8" |
+------------+---------+
SHOW CREATE SPACE语句显示指定图空间的创建语句
nebula> SHOW CREATE SPACE basketballplayer;
+--------------------+---------------------------------------------------------------------------------------------------------------------------------------------+
| Space | Create Space |
+--------------------+---------------------------------------------------------------------------------------------------------------------------------------------+
| "basketballplayer" | "CREATE SPACE `basketballplayer` (partition_num = 10, replica_factor = 1, charset = utf8, collate = utf8_bin, vid_type = FIXED_STRING(32))" |
+--------------------+---------------------------------------------------------------------------------------------------------------------------------------------+
SHOW CREATE TAG语句显示指定 Tag 的基本信息。Tag 的更多详细信息
nebula> SHOW CREATE TAG player;
+----------+-----------------------------------+
| Tag | Create Tag |
+----------+-----------------------------------+
| "player" | "CREATE TAG `player` ( |
| | `name` string NULL, |
| | `age` int64 NULL |
| | ) ttl_duration = 0, ttl_col = """ |
+----------+-----------------------------------+
nebula> SHOW CREATE EDGE follow;
+----------+-----------------------------------+
| Edge | Create Edge |
+----------+-----------------------------------+
| "follow" | "CREATE EDGE `follow` ( |
| | `degree` int64 NULL |
| | ) ttl_duration = 0, ttl_col = """ |
+----------+-----------------------------------+
SHOW HOSTS语句可以显示集群信息,包括端口、状态、leader、分片、版本等信息,或者指定显示 Graph、Storage、Meta 服务主机信息
nebula> SHOW HOSTS;
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+
| "storaged0" | 9779 | "ONLINE" | 8 | "docs:5, basketballplayer:3" | "docs:5, basketballplayer:3" | "3.4.0" |
| "storaged1" | 9779 | "ONLINE" | 9 | "basketballplayer:4, docs:5" | "docs:5, basketballplayer:4" | "3.4.0" |
| "storaged2" | 9779 | "ONLINE" | 8 | "basketballplayer:3, docs:5" | "docs:5, basketballplayer:3" | "3.4.0" |
+-------------+-------+----------+--------------+----------------------------------+------------------------------+---------+
nebula> SHOW HOSTS GRAPH;
+-----------+------+----------+---------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+-----------+------+----------+---------+--------------+---------+
| "graphd" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.4.0" |
| "graphd1" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.4.0" |
| "graphd2" | 9669 | "ONLINE" | "GRAPH" | "3ba41bd" | "3.4.0" |
+-----------+------+----------+---------+--------------+---------+
nebula> SHOW HOSTS STORAGE;
+-------------+------+----------+-----------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+-------------+------+----------+-----------+--------------+---------+
| "storaged0" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.4.0" |
| "storaged1" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.4.0" |
| "storaged2" | 9779 | "ONLINE" | "STORAGE" | "3ba41bd" | "3.4.0" |
+-------------+------+----------+-----------+--------------+---------+
nebula> SHOW HOSTS META;
+----------+------+----------+--------+--------------+---------+
| Host | Port | Status | Role | Git Info Sha | Version |
+----------+------+----------+--------+--------------+---------+
| "metad2" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.4.0" |
| "metad0" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.4.0" |
| "metad1" | 9559 | "ONLINE" | "META" | "3ba41bd" | "3.4.0" |
+----------+------+----------+--------+--------------+---------+
SHOW INDEX STATUS语句显示重建原生索引的作业状态,以便确定重建索引是否成功
nebula> SHOW TAG INDEX STATUS;
+------------------------------------+--------------+
| Name | Index Status |
+------------------------------------+--------------+
| "date1_index" | "FINISHED" |
| "basketballplayer_all_tag_indexes" | "FINISHED" |
| "any_shape_geo_index" | "FINISHED" |
+------------------------------------+--------------+
nebula> SHOW EDGE INDEX STATUS;
+----------------+--------------+
| Name | Index Status |
+----------------+--------------+
| "follow_index" | "FINISHED" |
+----------------+--------------+
SHOW INDEXES语句可以列出当前图空间内的所有 Tag 和 Edge type(包括属性)的索引
nebula> SHOW TAG INDEXES;
+------------------+----------+----------+
| Index Name | By Tag | Columns |
+------------------+----------+----------+
| "player_index_0" | "player" | [] |
| "player_index_1" | "player" | ["name"] |
+------------------+----------+----------+
nebula> SHOW EDGE INDEXES;
+----------------+----------+---------+
| Index Name | By Edge | Columns |
+----------------+----------+---------+
| "follow_index" | "follow" | [] |
+----------------+----------+---------+
SHOW PARTS语句显示图空间中指定分片或所有分片的信息
nebula> SHOW PARTS;
+--------------+--------------------+--------------------+-------+
| Partition ID | Leader | Peers | Losts |
+--------------+--------------------+--------------------+-------+
| 1 | "192.168.2.1:9779" | "192.168.2.1:9779" | "" |
| 2 | "192.168.2.2:9779" | "192.168.2.2:9779" | "" |
| 3 | "192.168.2.3:9779" | "192.168.2.3:9779" | "" |
| 4 | "192.168.2.1:9779" | "192.168.2.1:9779" | "" |
| 5 | "192.168.2.2:9779" | "192.168.2.2:9779" | "" |
| 6 | "192.168.2.3:9779" | "192.168.2.3:9779" | "" |
| 7 | "192.168.2.1:9779" | "192.168.2.1:9779" | "" |
| 8 | "192.168.2.2:9779" | "192.168.2.2:9779" | "" |
| 9 | "192.168.2.3:9779" | "192.168.2.3:9779" | "" |
| 10 | "192.168.2.1:9779" | "192.168.2.1:9779" | "" |
+--------------+--------------------+--------------------+-------+
nebula> SHOW PARTS 1;
+--------------+--------------------+--------------------+-------+
| Partition ID | Leader | Peers | Losts |
+--------------+--------------------+--------------------+-------+
| 1 | "192.168.2.1:9779" | "192.168.2.1:9779" | "" |
+--------------+--------------------+--------------------+-------+
SHOW ROLES语句显示分配给用户的角色信息
nebula> SHOW ROLES in basketballplayer;
+---------+-----------+
| Account | Role Type |
+---------+-----------+
| "user1" | "ADMIN" |
+---------+-----------+
SHOW SNAPSHOTS语句显示所有快照信息
nebula> SHOW SNAPSHOTS;
+--------------------------------+---------+-----------------------------------------------------+
| Name | Status | Hosts |
+--------------------------------+---------+-----------------------------------------------------+
| "SNAPSHOT_2020_12_16_11_13_55" | "VALID" | "storaged0:9779, storaged1:9779, storaged2:9779" |
| "SNAPSHOT_2020_12_16_11_14_10" | "VALID" | "storaged0:9779, storaged1:9779, storaged2:9779" |
+--------------------------------+---------+-----------------------------------------------------+
SHOW SPACES语句显示现存的图空间。
nebula> SHOW SPACES;
+---------------------+
| Name |
+---------------------+
| "docs" |
| "basketballplayer" |
+---------------------+
SHOW STATS语句显示最近一次SUBMIT JOB STATS作业收集的图空间统计信息
# 选择图空间。
nebula> USE basketballplayer;
# 执行 SUBMIT JOB STATS。
nebula> SUBMIT JOB STATS;
+------------+
| New Job Id |
+------------+
| 98 |
+------------+
# 确认作业执行成功。
nebula> SHOW JOB 98;
+----------------+---------------+------------+----------------------------+----------------------------+-------------+
| Job Id(TaskId) | Command(Dest) | Status | Start Time | Stop Time | Error Code |
+----------------+---------------+------------+----------------------------+----------------------------+-------------+
| 98 | "STATS" | "FINISHED" | 2021-11-01T09:33:21.000000 | 2021-11-01T09:33:21.000000 | "SUCCEEDED" |
| 0 | "storaged2" | "FINISHED" | 2021-11-01T09:33:21.000000 | 2021-11-01T09:33:21.000000 | "SUCCEEDED" |
| 1 | "storaged0" | "FINISHED" | 2021-11-01T09:33:21.000000 | 2021-11-01T09:33:21.000000 | "SUCCEEDED" |
| 2 | "storaged1" | "FINISHED" | 2021-11-01T09:33:21.000000 | 2021-11-01T09:33:21.000000 | "SUCCEEDED" |
| "Total:3" | "Succeeded:3" | "Failed:0" | "In Progress:0" | "" | "" |
+----------------+---------------+------------+----------------------------+----------------------------+-------------+
# 显示图空间统计信息。
nebula> SHOW STATS;
+---------+------------+-------+
| Type | Name | Count |
+---------+------------+-------+
| "Tag" | "player" | 51 |
| "Tag" | "team" | 30 |
| "Edge" | "follow" | 81 |
| "Edge" | "serve" | 152 |
| "Space" | "vertices" | 81 |
| "Space" | "edges" | 233 |
+---------+------------+-------+
-
SHOW TAGS语句显示当前图空间内的所有 Tag。 -
SHOW EDGES语句显示当前图空间内的所有 Edge type。
nebula> SHOW TAGS;
+----------+
| Name |
+----------+
| "player" |
| "star" |
| "team" |
+----------+
nebula> SHOW EDGES;
+----------+
| Name |
+----------+
| "follow" |
| "serve" |
+----------+
SHOW USERS语句显示用户信息。
nebula> SHOW USERS;
+---------+-----------------+
| Account | IP Whitelist |
+---------+-----------------+
| "root" | "" |
| "user1" | "" |
| "user2" | "192.168.10.10" |
+---------+-----------------+
- 登录 NebulaGraph 数据库时,会创建对应会话,用户可以查询会话信息。
nebula> SHOW SESSIONS;
nebula> SHOW SESSION 1635254859271703;
SHOW QUERIES语句可以查看当前 Session 中正在执行的查询请求信息。
nebula> SHOW LOCAL QUERIES;
nebula> SHOW QUERIES;
nebula> SHOW QUERIES | ORDER BY $-.DurationInUSec DESC | LIMIT 10;
SHOW META LEADER语句显示当前 Meta 集群的 leader 信息
nebula> SHOW META LEADER;
+------------------+---------------------------+
| Meta Leader | secs from last heart beat |
+------------------+---------------------------+
| "127.0.0.1:9559" | 3 |
+------------------+---------------------------+
8. 配置文件常用配置参数
nebula-graphd.conf:包含有关 Graph 服务的配置项。
nebula-metad.conf:包含有关 Meta Service 的配置项。
nebula-storaged.conf:包含有关 Storage Service 的配置项。
8-1. nebula-graphd.conf
| 配置参数 | 描述 | 常见配置值 |
|---|---|---|
| host | Graph 服务的监听地址。 | 0.0.0.0 |
| port | Graph 服务的监听端口。 | 9669 |
| meta_server_addrs | Meta Server 的地址列表,用于与 Meta 服务通信。 | [“127.0.0.1:9559”] |
| num_accept_threads | 用于接受客户端请求的线程数。 | 4 |
| num_worker_threads | 用于处理客户端请求的工作线程数。 | 16 |
| client_idle_timeout_secs | 客户端空闲连接的超时时间。 | 0 |
| heartbeat_interval_secs | 心跳间隔,用于与 Meta 服务保持连接。 | 10 |
| session_idle_timeout_secs | 会话空闲超时时间,指定多长时间后会话将被关闭。 | 0 |
| session_reclaim_interval_secs | 会话回收间隔时间,控制会话资源的回收。 | 3600 |
| enable_authorize | 是否启用授权认证,用于限制客户端访问。 | false |
| authorize_path | 授权文件的路径,包含用户角色和权限信息。 | “” |
| max_connections | 最大客户端连接数。 | 10000 |
| minloglevel | 日志级别,控制日志的详细程度。 | 2 |
| log_dir | 日志文件存储目录。 | “/var/log/nebula” |
| logbufsecs | 日志缓冲时间,控制日志的刷新频率。 | 0 |
8-2. nebula-metad.conf
| 配置参数 | 描述 | 常见配置值 |
|---|---|---|
| host | Meta Service 监听地址。 | 0.0.0.0 |
| port | Meta Service 监听端口。 | 9559 |
| data_path | Meta 数据存储路径。 | /var/lib/nebula/meta |
| election_timeout_ms | Meta 选举超时时间(毫秒)。 | 1000 |
| raft_heartbeat_interval_secs | Raft 心跳间隔时间(秒)。 | 1 |
| raft_heartbeat_timeout_ms | Raft 心跳超时时间(毫秒)。 | 3000 |
| rocksdb_db_options | RocksDB 数据库选项配置。 | “…” |
| rocksdb_column_family_options | RocksDB 列族选项配置。 | “…” |
| minloglevel | 日志级别。 | 2 |
| log_dir | 日志文件存储目录。 | /var/log/nebula/meta |
| logbufsecs | 日志缓冲时间(秒)。 | 0 |
8-3. nebula-storaged.conf
| 配置参数 | 描述 | 建议配置值 |
|---|---|---|
| host | Storage Service 监听地址。 | 0.0.0.0 |
| port | Storage Service 监听端口。 | 9779 |
| data_path | 数据存储路径。 | /var/lib/nebula/storage |
| rocksdb_db_options | RocksDB 数据库选项配置。 | “…” |
| rocksdb_column_family_options | RocksDB 列族选项配置。 | “…” |
| heartbeat_interval_secs | 心跳间隔时间(秒)。 | 10 |
| heartbeat_timeout | 心跳超时时间(秒)。 | 60 |
| session_idle_timeout_secs | 会话空闲超时时间(秒)。 | 0 |
| session_reclaim_interval_secs | 会话资源回收间隔时间(秒)。 | 3600 |
| minloglevel | 日志级别。 | 2 |
| log_dir | 日志文件存储目录。 | /var/log/nebula/storage |
9.Nebula服务便捷式一键启停脚本
[root@wangting ~]# cat mynebula
#!/bin/bash
if [ $# -eq 0 ]
then
echo -e "请输入参数:\nstart 启动Nebula集群;\nstop 关闭Nebula集群;\nstatus 查看Nebula集群"&&exit
fi
case $1 in
"start")
echo " ------------------- 启动 hdt-dmcp-ops01 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops01 "/opt/module/nebula/scripts/nebula.service start all"
echo " ------------------- 启动 hdt-dmcp-ops02 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops02 "/opt/module/nebula/scripts/nebula.service start all"
echo " ------------------- 启动 hdt-dmcp-ops03 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops03 "/opt/module/nebula/scripts/nebula.service start all"
echo " ------------------- 启动 hdt-dmcp-ops04 组件:graphd|storaged -------------------"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service start graphd"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service start storaged"
echo " ------------------- 启动 hdt-dmcp-ops05 组件:graphd|storaged -------------------"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service start graphd"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service start storaged"
;;
"stop")
echo " ------------------- 关闭 hdt-dmcp-ops01 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops01 "/opt/module/nebula/scripts/nebula.service stop all"
echo " ------------------- 关闭 hdt-dmcp-ops02 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops02 "/opt/module/nebula/scripts/nebula.service stop all"
echo " ------------------- 关闭 hdt-dmcp-ops03 组件:graphd|storaged|metad -------------------"
ssh hdt-dmcp-ops03 "/opt/module/nebula/scripts/nebula.service stop all"
echo " ------------------- 关闭 hdt-dmcp-ops04 组件:graphd|storaged -------------------"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service stop graphd"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service stop storaged"
echo " ------------------- 关闭 hdt-dmcp-ops05 组件:graphd|storaged -------------------"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service stop graphd"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service stop storaged"
;;
"status")
echo " ------------------- 查看 hdt-dmcp-ops01 组件状态 -------------------"
ssh hdt-dmcp-ops01 "/opt/module/nebula/scripts/nebula.service status all"
echo " ------------------- 查看 hdt-dmcp-ops02 组件状态 -------------------"
ssh hdt-dmcp-ops02 "/opt/module/nebula/scripts/nebula.service status all"
echo " ------------------- 查看 hdt-dmcp-ops03 组件状态 -------------------"
ssh hdt-dmcp-ops03 "/opt/module/nebula/scripts/nebula.service status all"
echo " ------------------- 查看 hdt-dmcp-ops04 组件状态 -------------------"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service status graphd"
ssh hdt-dmcp-ops04 "/opt/module/nebula/scripts/nebula.service status storaged"
echo " ------------------- 查看 hdt-dmcp-ops05 组件状态 -------------------"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service status graphd"
ssh hdt-dmcp-ops05 "/opt/module/nebula/scripts/nebula.service status storaged"
;;
*)
echo -e "请输入参数:\nstart 启动Nebula集群;\nstop 关闭Nebula集群;\nstatus 查看Nebula集群"&&exit
;;
esac