Linux友人帐之进程管理
一、基本概念
1、在Liux中,每一个程序都是有自己的一个进程,每一个进程都有一个id号!
2、每一个进程呢,都会有一个父进程!
3、进程可以有两种存在方式:前台!后台运行!
4、一般的话服务都是后台运行的,基本的程序都是前台运行的!
1.1进程概念
对于我们的了解来说,什么是进程呢? 有的资料是这么说:一个运行起来的程序(加载到内存)叫做进程;在内存中的程序叫做进程。也就是说,进程和程序相比具有动态属性。
进程 = 内核数据结构(task_struct) + 进程对应的磁盘代码
对于之前我们通过C写出的进度条程序来说,其本质就是一个文件并且存放在磁盘中。但是其并没有真正的运行,当我们运行程序的时候,文件就会从磁盘加载到内存,但是磁盘中那么多的文件全部加载到内存中明显是不现实的并且我们也不需要其他文件加载到内存,这时候就需要操作系统对文件进行管理从而只让我们想要执行的程序加载到内存,那操作系统是如何管理的呢?
即先描述,再组织
1.2 进程的执行过程
通过上述的概念,我们了解的并不多,那么接下来就来分析一下:如果有很多这样的进程加载到内存中,操作系统要如何进行管理呢? 即利用先描述再组织的思想。
而所谓的先描述,这里引进了一个新的概念:PCB :进程控制块 struct task_struct{}
1. 那么什么是进程控制块呢?
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合,称之为PCB(process control block)在Linux中描述进程的结构体叫做task_struct。
在磁盘中的程序中,并没有进程控制块以及内部属性信息的存在,而是加载到内存之后通过操作系统的一系列的管理才出现的。
//进程控制块
struct task_struct
{
//该进程的所有属性
//该进程对应的代码和属性地址
struct task_struct *next;
};
2. 进程控制块如何对进程进行管理的呢?
- 磁盘中的可执行程序在将要运行时,所有的进程中的数据(并不是程序本身)加载到内存中,此时操作系统会建立起一个PCB来保存每一个程序的信息
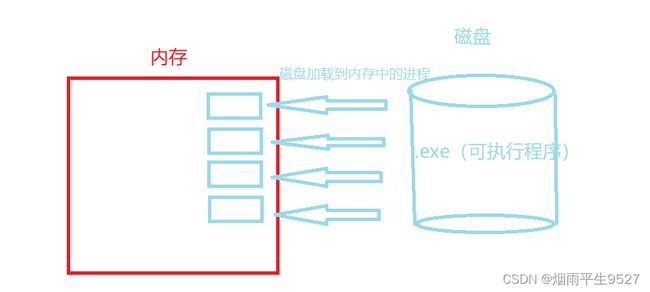
这个时候PCB就会对每一个进程都建立起相应的结构体(即进程控制块)将对应的进程的属性、代码等匹配的传到这个结构体中:(这就是先描述)
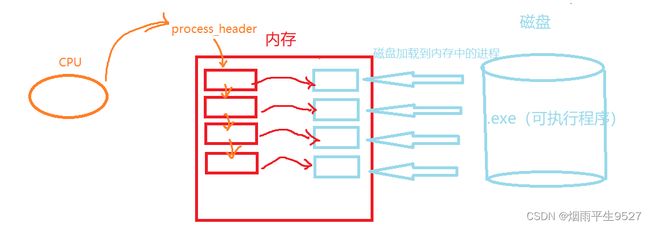
-
此时,操作系统就会将每一个进程控制块都连接起来,形成链表结构,并返回头结点。这样便通过数据结构的形式将进程的信息组织起来。
通过这样的先描述再组织的思想,当我们处理优先级高的进程时,我们就可以通过遍历头结点,找到优先级最高的那个节点的信息,并将这个进程的代码执行。
3.为什么要有进程控制块(PCB)呢?
对进程管理的核心是对数据进行管理,因此当我们加载程序到内存之前,我们必须拿到所有程序的数据,由于拿到的数据杂乱无章并且未进行分类,这时候就需要PCB将其归类,将对应的数据放到相应的进程控制块里!

即加载进程的时候,操作系统为了方便管理会new一个struct task_struct也就是进程控制块的结构体,然后一点点的将上面加载的数据填充到这里的内部属性(状态,标记,追踪等),因此这里再一次强调了:进程不是程序加载到内存,而是在内存中new了task_struct结构体!
二、进程的基本操作
2.1查看进程
ps命令
Linux ps命令是用来显示当前进程的状态的,类似于Windows的任务管理器。ps命令有很多参数,可以用来控制输出的格式和内容。ps命令的基本语法是:
ps [options] [–help]
其中,options可以是以下几种:
- a:显示所有与终端相关的进程
- u:显示进程的用户及内存等信息
- x:显示没有控制终端的进程
- aux:相当于au+x,显示所有包含其他用户的进程
- l:显示长格式的信息,包括优先级、父进程ID等
- e:显示所有进程
ps命令输出的信息包括以下几个字段:
- USER:进程的所有者
- PID:进程的ID
- %CPU:进程占用的CPU百分比
- %MEM:进程占用的内存百分比
- VSZ:进程占用的虚拟内存大小(单位KB)
- RSS:进程占用的物理内存大小(单位KB)
- TTY:进程运行的终端
- STAT:进程的状态
- START:进程开始的时间
- TIME:进程占用CPU的运行时间
- COMMAND:产生此进程的命令
其中,STAT字段表示进程的状态,有以下几种可能:
- D:无法中断的休眠状态(通常是I/O操作)
- R:正在运行或可运行的状态
- S:静止状态,可被唤醒
- T:暂停或被追踪的状态
- Z:僵尸状态,已终止但未被回收
- <:高优先级的进程
- N:低优先级的进程
- L:有内存分页分配并锁在内存中(实时系统或I/O操作)
- s:父进程(有子进程存在)
- l:多线程的进程
- +:前台运行的进程

grep命令
Linux grep命令是一个强大的文本搜索工具,它可以使用正则表达式来匹配文件或标准输入中的文本。grep命令的基本语法是:
grep [选项] [模式] [文件]
其中,选项可以控制grep命令的行为,如是否忽略大小写,是否显示行号,是否递归搜索等。模式是要匹配的字符串或正则表达式。文件是要搜索的文件名,可以是多个文件,如果省略文件参数,则默认从标准输入中读取数据。
grep命令有两个变体,分别是egrep和fgrep。egrep命令相当于grep -E,它使用扩展的正则表达式来匹配文本。fgrep命令相当于grep -F,它使用固定的字符串来匹配文本,不解释正则表达式中的特殊字符。
pstree命令
Linux pstree命令是用来显示当前进程的状态的,类似于Windows的资源管理器。pstree命令可以使用ASCII字符或UTF-8字符来显示进程之间的树状结构,清楚地表达进程之间的相互关系。pstree命令的基本语法是:
pstree [选项] [pid|user]
其中,选项可以是以下几种:
- -p:显示进程的PID
- -u:显示进程的所属用户
- -a:显示进程的完整命令和参数
- -c:不合并相同名称的进程
- -n:按照PID排序进程
- -l:使用长格式输出,不截断长名称
- -A:使用ASCII字符连接进程树
- -U:使用UTF-8字符连接进程树
- -h:高亮显示指定的PID或用户的进程树
- -H:高亮显示指定的PID或用户的进程树,并隐藏其他进程
如果不指定pid或user参数,则默认显示所有进程,以init或systemd为根节点。如果指定pid参数,则只显示该进程及其子进程。如果指定user参数,则只显示该用户拥有的进程。

2.2 结束进程
结束进程有两种方式,下面就来介绍:
1.通过指令结束进程
Linux的kill,它可以让您控制和管理您的系统上运行的进程。kill命令的基本语法是:
kill [options] pid其中,
options是可选的参数,用于指定要发送给进程的信号,pid是要终止的进程的标识符。您可以使用不同的信号来影响进程的行为,例如:
- 1 (HUP):重新加载进程。
- 9 (KILL):强制杀死一个进程。
- 15 (TERM):正常停止一个进程。
2.通过ctrl + c快捷键
通过快捷键ctrl + c也可以结束进程。
2.3进程的系统调用
getpid函数
Linux的getpid函数是一个系统调用,它用于获取当前进程的进程标识符(PID)。PID是一个非负整数,用于唯一标识一个进程。getpid函数的原型如下:
pid_t getpid(void);其中,pid_t是一个整型类型,定义在sys/types.h头文件中。getpid函数没有参数,返回值是调用进程的PID。如果发生错误,getpid函数不会失败,也不会设置errno变量。
getpid函数的一个常见用途是生成唯一的临时文件名,例如:
char filename[20];sprintf(filename, "tmp.%d", getpid());这样可以保证不同的进程不会产生相同的临时文件名。另一个用途是在调试或日志记录中输出进程的信息,例如:
printf("Process %d started.\n", getpid());这样可以方便地追踪进程的运行状态。
getppid函数
除了getpid函数,还有一个相关的函数是getppid函数,它用于获取当前进程的父进程的PID。父进程是指创建当前进程的进程,通常通过fork或vfork函数来创建子进程。getppid函数的原型如下:
pid_t getppid(void);它和getpid函数类似,没有参数,返回值是父进程的PID。如果当前进程没有父进程,或者父进程已经终止,那么返回值是1,表示init进程。init进程是系统中第一个启动的进程,它负责初始化系统和启动其他服务。
getppid函数的一个常见用途是在子进程中判断父进程是否还存活,例如:
if (getppid() == 1) {printf("Parent process is dead.\n");exit(1);}这样可以避免子进程成为孤儿进程,或者处理一些异常情况。