【Transformer 论文精读】……ViT……(TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE)
文章目录
- 一、Abstract(摘要)
- 二、Introduction(引言)
- 三、Related Work(相关工作)
- 四、Method(方法)
- 五、Experiments(实验)
- 六、Conclusion(结论)
- 七、小总结
论文题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
原文下载连接:https://arxiv.org/pdf/2010.11929.pdf
前两天读Transformer最原始的那个论文,基于NLP方向写的,全是NLP的知识点,给我读的痛苦死了,今天这终于来了个CV方向的。
论文题目前半段是 AN IMAGE IS WORTH 16X16 WORDS 就是将图片分解成16 * 16的网格,就像yolo的那个grid cell。这样的话可能将每个小格子当成一个单词来处理?用这样的方法将transformer迁移到图像任务中嘛?
一、Abstract(摘要)
这篇文章应该是基于Transformer原始的那一篇论文写的,作者说Transformer模型在NLP任务中已经大放异彩,并且在原始论文中已经证明,Transformer模型能够和当时主流的模型相媲美甚至比他们好,所以Vit这篇论文的作者想把Transformer模型迁移到CV方向。
作者在摘要中说现阶段的图像任务都是基于CNN为骨干,实际上是不必要的,可以像NLP那样,完全由Transformer代替,并且作者通过实验表明这样代替可以取得很好的效果(使用大量数据做预训练然后微调),并且所用计算计算更少。
state-of-the-art : 简称SOTA,表示现在最优的…(比如模型,或者某算法)
二、Introduction(引言)
引言部分作者将摘要中的点稍微展开说了一下。
首先就是按照惯例抨击前人工作。因为前人思路都是图片变成像素块(不是patch),然后按照处理单词的方式来进行,不过图片的2D要拉伸成1D处理,如果输入传统的224 * 224 = 50176 会导致序列很长复杂度很大,所以有两个解决这个问题的方向,一种是 CNN+注意力,一种是完全注意力。
后面又说了一些轴注意力,孤立注意力等,总是就是都不行,还是Resnet那种残差的效果最好。好家伙 作者是属于是借刀杀人吗?
然后就是印证题目,作者提出将一个图片分成16 * 16的网格块(patch),将patch输出transformer,处理方式于NLP的 tokens(单词 words) 相同。这样就大幅降低了超长序列的问题。
之后作者提出了Transformer现在在图像方面的一个问题,就是没办法包含cnn那样的归纳偏置 (inductive biases),比如平移不变性和局部性。
平移不变性老生常谈了,就是平移图片中的物体,依旧能识别出来。
文章中这说到的局部性就是,一张图的相邻物体或者元素是具有一定相关性的,比如鼠标和键盘通常一起出现。
关于 归纳偏置 (inductive biases):
通俗理解:归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则 (heuristics),然后对模型做一定的约束,从而可以起到 “模型选择” 的作用,类似贝叶斯学习中的 “先验”。
西瓜书解释:机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好,简称偏好。归纳偏好可以看作学习算法自身在一个庞大的假设空间中对假设进行选择的启发式或 “价值观”。
维基百科解释:如果学习器需要去预测 “其未遇到过的输入” 的结果时,则需要一些假设来帮助它做出选择。
广义解释:归纳偏置会促使学习算法优先考虑具有某些属性的解。
出处:CSDN博客
作者通过大规模数据集训练来规避缺少归纳偏置这个问题。
三、Related Work(相关工作)
第一段作者介绍了一下NLP方向的两个自监督主流模型,BERT和GPT。
第二段作者介绍将自注意力引用到图片的方法,就是将像素点当成元素,让他们俩俩自注意力,不过这个办法在引言中已经说过了,复杂度很高。二段中后就继续说前人的工作不行,就还是那个序列长的问题。
第三段开始作者介绍了一个和他工作相似的前人工作,ICLR 2020 的一篇论文中使用了和作者相同的方法,就是划分patch,只不过那一篇论文划分的是2 * 2 的网格,并在cifar-10这种小数据集上操作的,作者就是用了更多的patch和更大的数据集。
第五段又说了一下iGPT,就是image GPT,就是将NLP里主流的那个GPT模型放到图片上了,不过效果不好。(因为GPT也是用的transformer,和作者的工作相近,所以这里提了一下)
四、Method(方法)
这章开头作者写下目标,尽可能的不改动transformer模型,直接拿过来用。
直接来看作者给出的vit模型:
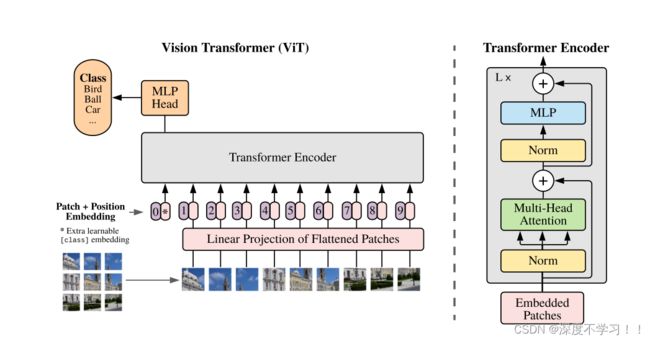
图中一个紫色一个粉色的小方块,前面紫色的小块是位置信息。
位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量是可以学习的,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768。
对于位置编码,他的初始化时随机的,不带任何信息。作者在最后附录里记录了他做消融实验的过程,表明,当没有位置编码的时候,精度在61%左右,加入位置编码后变成64%左右,也没有差很多。作者也给出了他认为的原因,就是因为本身这个vit模型是针对patch的,而不是针对像素块的,所以对于每个小patch的位置信息是很好分辨的,加入专用的位置信息就是为了保持和原来的transformer一致。
看过程之前先明确一个问题,这里我踩坑了,我以为是分成16 * 16 个patch,结果作者所说的是分成16 * 16 的patch是指分成N个大小的块,这个块叫patch,每个patch是16 * 16像素的,就离谱。
过程:
假设输入图片大小为224 * 224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成(224x224)/(16x16)=196个patch,即输入序列长度为196,每个patch维度16x16x3=768。
图中粉色的长条叫线性投射层,就是全连接层,维度 768 * 768,因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768,因为图片是要分类的,这里还需要加上一个特殊字符cls,因此最终的维度是197x768。此时,已经通过patch embedding将一个视觉问题转化为了一个NLP问题。
之后layer norm(LN) 输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接(concat)起来,输出维度是197x768,然后在过一层LN,维度依然是197x768。
再通过MLP 将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768。
最后会将特殊字符cls对应的输出作为encoder的最终输出 ,
一个block输入输出维度相同,都是197x768,因此可以堆叠多个block。
后面作者给出的这个公式:
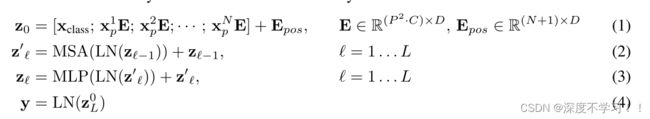
- X p E X_pE XpE 就是一个一个的patch块, x c l a s s x_{class} xclass就是拼接的分类token,后面的 E p o s E_{pos} Epos就是加上的位置编码。
- Z 0 Z_0 Z0 就是整个transformer的输入了。
- 然后过MSA多头注意力,做MSA之前先过LN,出来的结果再加上残差链接。
- 再过MLP,也是先LN,最后加上残差。
- Z L 0 Z^0_L ZL0 就是最后一层输出结果的第一个class token信息。
五、Experiments(实验)
详细细节略过,直接结论:
- 先在较大的数据集上预训练,然后再对特定的较小数据集进行微调,效果优于 ResNet。
- 在大数据下,ViT 可能会发挥更大的优势。
- ybrid混合模型,就是将传统CNN特征提取和Transformer进行结合(前面CNN后面Transformer)。在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
- 随着数据集的增大 VIt没有饱和的迹象。
- 自注意力可以在刚开始的时候就顾到全局信息,而CNN一开始不可以。
六、Conclusion(结论)
结论按照惯例,又是车轱辘话来回说,最后说一下展望。
作者说本文的模型于其他的不同,他们都是 CNN+注意力,或者直接纯注意力,作者是直接把Transformer搬过来用到CV里了,直接将图片分成图像块当成一个一个的单词送入模型去做分类。
模型和大规模预训练数据结合可以很好规避之前说的那个归纳偏置。取得很好的效果。
后面一段作者说了一下展望,作者期待了一下后续人将transformer应用到分割和检测领域,最后展望了一下自监督的训练方式。
七、小总结
作者想将Transformer尽可能原生的搬运到CV领域,并且通过一系列实验表明效果还不错,在中等规模的数据集上略微弱于cnn,在大规模的数据集上表象更好。
大体步骤:图片分成16 * 16像素的小块(patch) N个。这些小块和分类token拼接,再加上位置编码,组成一串token,然后就走transformer encoder那一套。