mysql进阶篇之索引(二)
mysql进阶篇
- 二、索引
-
- 1、索引概述
- 2、索引结构
-
- 1、B+Tree索引
-
- 1、二叉树
- 2、B-Tree
- 3、B+Tree
- 2、Hash索引
- 3、索引分类
- 4、索引语法
- 5、SQL性能分析
-
- 1、SQL执行频率
- 2、慢查询日志
- 3、profile详情
- 4、explain执行计划
- 6、索引使用
- 7、索引设计原则
二、索引
1、索引概述
介绍
索引是帮助MySQL高效获取数据的数据结构(有序)。在数据之外。数据库系统害维护着满足特定查找算法的数据结构,这些数据结构一某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这些数据结构就是索引。
优缺点

2、索引结构
mysql的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要有:
| 索引 结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash索引 | 底层数据结构是用hash表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree(空间索引) | 空间索引是myisam引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用很少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
1、B+Tree索引
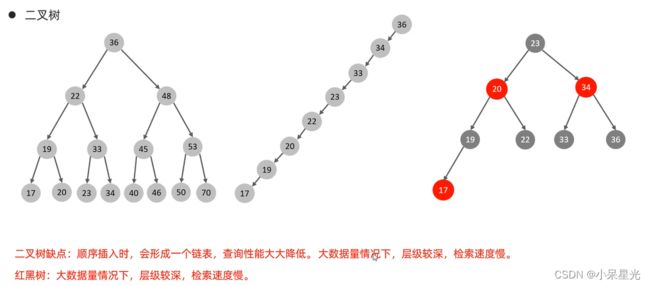
1、二叉树
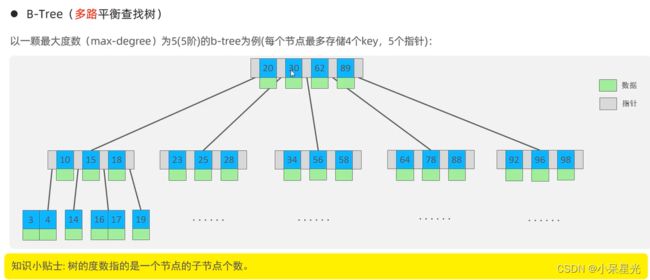
2、B-Tree

5阶 4个key 5个指针 够5个key 中间key向上提取分裂
3、B+Tree


相对于B-Tree区别:
1、所有的数据都会出现在叶子节点
2、叶子节点形成一个单向链表
MySQL索引数据结构相对经典的B=Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能

2、Hash索引
概念含义
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个或者多个键值,映射到一个相应的槽位上,他们就产生了hash冲突(hash碰撞),可以通过链表(HashMap)解决。
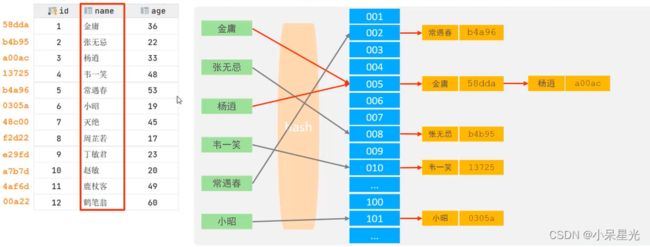
特点
1、hash索引只能用于对等比较(=,in),不能范围查询(between,< ,>)
2、无法利用索引完成排序操作(因为是无序的)
3、查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree
存储引擎支持
在MySQL中,支持hash索引的是memory引擎,而innodb具有自适应hash功能(根据SQL自动将B+Tree转换为hash索引),hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
问题

3、索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在innodb存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级(非聚集)索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
1、如果存在主键,主键索引就是聚集索引
2、如果不存在主键,将使用第一个唯一索引作为聚集索引
3、如果没有主键也没有唯一索引,innodb会自动生成一个rowid作为隐藏的聚集索引
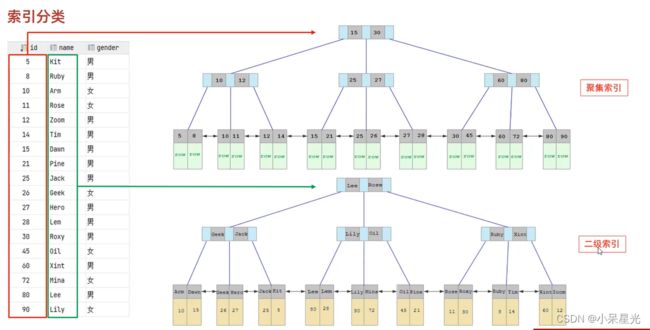
id是主键 针对id的就是聚集索引 而叶子节点存的id对应的是一整行数据
name是非聚集索引,叶子节点存的name值对应的那那一会的主键id
**eg:**select * from user where name=‘Arm’;
会拿name值去非聚集索引拿到对应的id 因为查询是所有 所以再去聚集索引中找到id对应的整行数据 先查询非聚集索引在查询聚集索引的过程称之为回表查询
问题
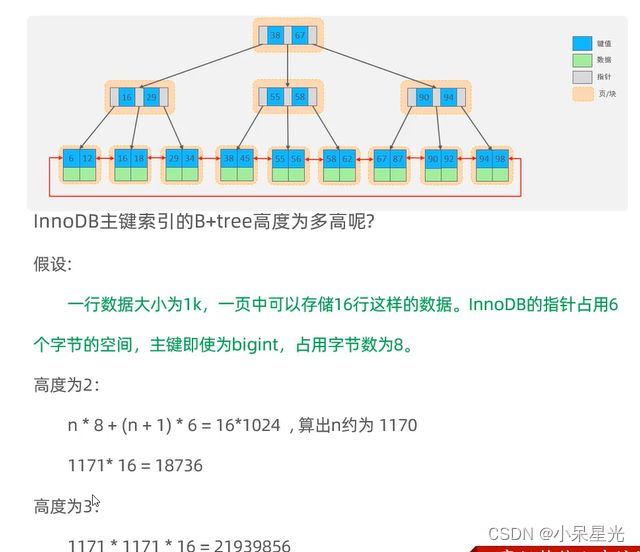
如果上亿数据考虑分库分表
4、索引语法
创建索引
create UNIQUE/FULLTEXT index index_name on 表名 (列,…) 不指定UNIQUE就是普通索引
查看索引
show index from 表名
删除索引
drop index index_name on 表名
5、SQL性能分析
1、SQL执行频率
使用show global status like 'Com_______'查看增删改查的频率
只看这四列即可
2、慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,默认10秒)的所有SQL语句的日志
MySQL的慢查询日志默认关闭,需要在MySQL的配置文件(/etc/my.cnf)中配置一下信息:
查看慢查询日志是否开启:
show variables like ‘slow_query_log’

#开启MySQL慢日志查询开关
slow_query_log=1
#设置慢日志的时间为2秒(默认10秒),SQL语句执行超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
配置完成后重启mysql(systemctl restart mysqld):查看慢日志文件中记录的信息/var/lib/mysql/localhost-slow.log
3、profile详情
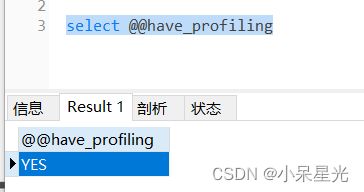
show profiles能够在做SQL优化是帮助我们了解时间都消耗在哪里。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:
select @@have_profiling
select @@profiling
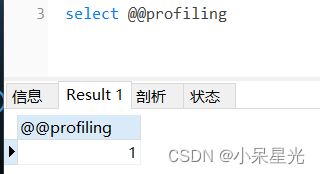
默认profiling是关闭的,可以通过set在session/global级别开启profiling:set profiling = 1;
show profiles

#查看每条SQL耗时情况
#查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query 10
#查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query 10
4、explain执行计划
explain 或者 desc命令获取MySQL如何执行select的信息,包括在select语句执行过程中表如何连接和连接顺序。
explain select * from 表名
6、索引使用
验证索引效率
在未建立索引之前,执行SQL语句,查看SQL的耗时
针对字段建立索引后:然后再次执行SQL,查看耗时
最左前缀法则
如果索引有多列(联合索引),要遵循最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳过某一列,索引将部分失效(后面的字段索引失效)。
范围查询
联合索引中,出现范围(<,>查询),范围查询右侧的列索引失效
允许的情况下,尽量使用>=
索引列运算
不要再索引列上进行运算操作,否则索引失效
字符串不加引号
字符串类型字段使用时,不加单引号,索引失效
模糊查询
如果仅仅是尾部模糊查询,索引不会失效。如果是头部模糊匹配,索引失效。
or连接条件
用or分割开的条件,如果or前的条件中有索引,后边列没有索引,那么涉及的索引都不会被用到,只有两边的列都有索引才会生效。
数据分布影响
如果MySQL评估使用索引比全表更慢,则不适用索引
例子:如果有10条数据 查询条件返回8条就不用 如果返回4个就用 返回数量较少的时候会走索引。
SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在索引中已经全部能够找到),减少select *。
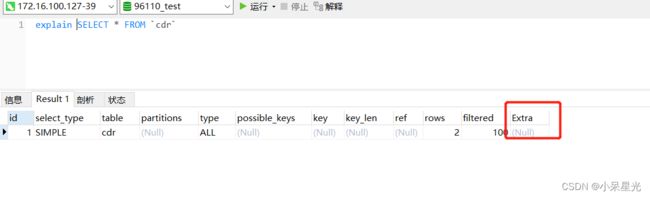
小贴士:
如果extra出现了:
using Index condision:查询使用了索引,但是需要回表查询数据
using where;using index:查询使用了索引,但是需要的数据都在索引列中能找到,索引不需要回表查询数据。
前缀索引
当字段类型为字符串(varchar text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:
create index idx_xxx on 表名(column(n)); n是字符串前边几位数
前缀长度:
可以根据索引的选择性来决定,儿选择性是指不重复的索引值(基数)喝数据表的记录总数的比值,索引选择性越高查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
单列索引与联合索引
单列索引:即一个索引只包含单个列
联合索引:即一个索引有多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时建议建立联合索引,而非单列索引
多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询
7、索引设计原则
1、针对于数据量较大(百万基本以上),且查询比较频繁的表建立索引
2、针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
3、尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
4、如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
5、尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
6、要控制索引的数量,索引并不是多多益善,索引越多,维护索引的代价也就越大,会影响增删改的效率
7、如果索引列不能存储NULL值,请在创建表示使用NOT NULL约束,当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引做有效的用于查询
索引详情