word embedding的模型与测试
模型
text:
I like deep learning.
I like NLP.
I enjoy flying.one-hot

缺点:高维度,稀疏性,相似度无法衡量
co-occurrence
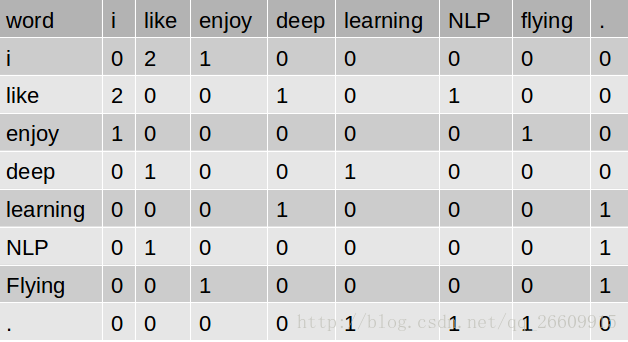
优点:相似度一定程度上可以衡量
缺点:高维度,稀疏性
SVD(降维)
观察发现,前10%甚至前10%的奇异值的和占了全部奇异值之和的99%以上
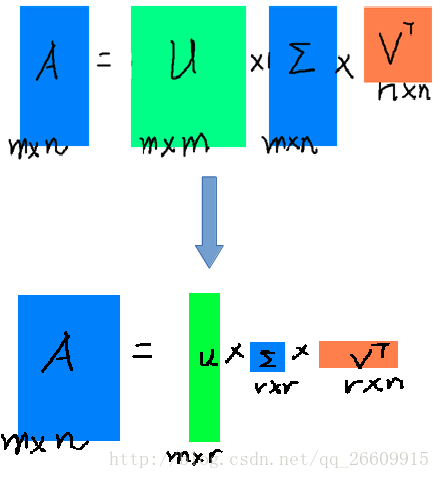
优点:改善了高纬度,稀疏性,相似度无法衡量问题
缺点:复杂度高 O(mn2)
word2vec
对原始的NNLM模型做如下改造:
- 移除前向反馈神经网络中非线性的hidden layer,直接将中间层的embedding layer与输出层的softmax layer连接;
- 忽略上下文环境的序列信息:输入的所有词向量均汇总到同一个embedding layer;
- 将future words纳入上下文环境
从数学上看,CBoW模型等价于一个词袋模型的向量乘以一个embedding矩阵,从而得到一个连续的embedding向量。这也是CBoW模型名称的由来。
CBoW模型依然是从context对target word的预测中学习到词向量的表达。反过来,我们能否从target word对context的预测中学习到word vector呢?答案显然是可以的:这个模型被称为Skip-gram模型(名称源于该模型在训练时会对上下文环境里的word进行采样)。
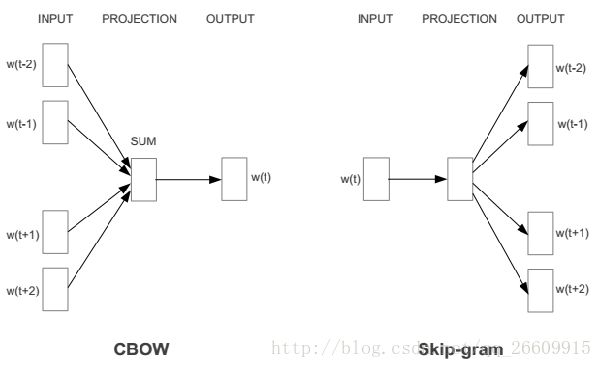
如果将Skip-gram模型的前向计算过程写成数学形式,我们得到:

Skip-gram模型的本质是计算输入word的input vector与目标word的output vector之间的余弦相似度,并进行softmax归一化。
疑问:为什么不用NNLM去训练词向量
答:NNLM存在的几个问题。NNLM的训练太慢了,NNLM模型只能处理定长的序列。
原始的NNLM模型的训练其实可以拆分成两个步骤:
1.用一个简单模型训练出连续的词向量;
2.基于词向量的表达,训练一个连续的Ngram神经网络模型。
word2vec实现的就是第一步。
疑问:模型输入的词向量都是随机的,如何训练模型的同时,训练这些词向量的?
答:
会先跟据语料建立一个词汇表,所有的训练样本应该是(前n-1个词的索引,第n个词的索引),对应一个C表,|V|*m, m是词向量的维度,|V|是词汇表的词量。训练的时候,更新语言模型的同时,也更新C表,这样,每个词对应的词向量就更新了。
手绘word2vec实现原理图,手残见谅。
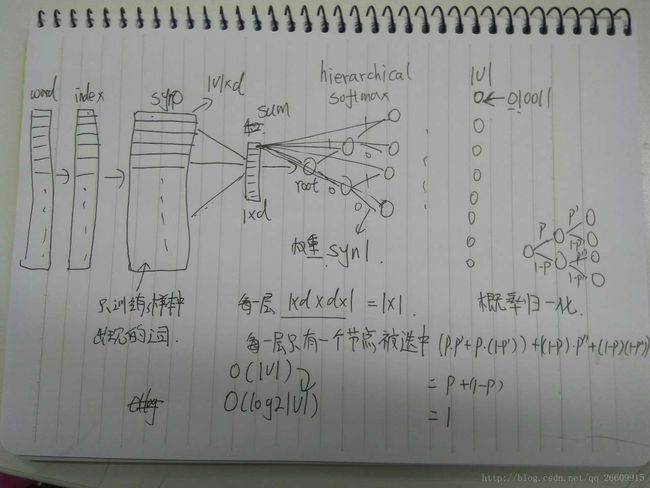
首先,它的结构就是一个三层网络——输入层、隐层(也可称为映射层),输出层。
输入层读入窗口内的词,将它们的向量(K维,初始随机)加和在一起,形成隐藏层K个节点。输出层是一个巨大的二叉树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。而这整颗二叉树构建的算法就是Huffman树。这样,对于叶节点的每一个词,就会有一个全局唯一的编码,形如”010011”。我们可以记左子树为1,右子树为0。接下来,隐层的每一个节点都会跟二叉树的内节点有连边,于是对于二叉树的每一个内节点都会有K条连边,每条边上也会有权值。
在训练阶段,当给定一个上下文,要预测中心词(Wn)的时候,实际上我们知道要的是哪个词(Wn),而Wn是肯定存在于二叉树的叶子节点的,因此它必然有一个二进制编号,如”010011”,那么接下来我们就从二叉树的根节点一个个地去便利,而这里的目标就是预测这个词的二进制编号的每一位!即对于给定的上下文,我们的目标是使得预测词的二进制编码概率最大。形象地说,我们希望(词向量和)与(节点相连边的权重)经过logistic计算得到的概率尽量接近0;在第二层,概率尽量接近1……这么一直下去,我们把一路上计算得到的概率相乘,即得到目标词Wn在当前网络下的概率(P(Wn)),那么对于当前这个sample的残差就是1-P(Wn)。于是就可以SGD优化各种权值了。
按照目标词的二进制编码计算到最后的概率值就是归一化的,这也是为啥它被称作hierarchical softmax的原因。传统的softmax,就需要对|V|中的每一个词都算一遍,这个过程时间复杂度是O(|V|)的。而使用了二叉树(如word2vec中的Huffman树),其时间复杂度就降到了O(log2(|V|)),速度大大地加快了。
Glove
全局的共现矩阵求法举例:
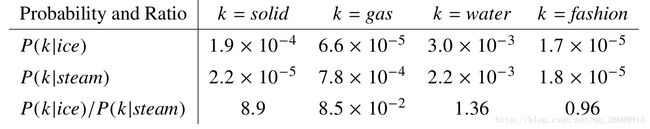
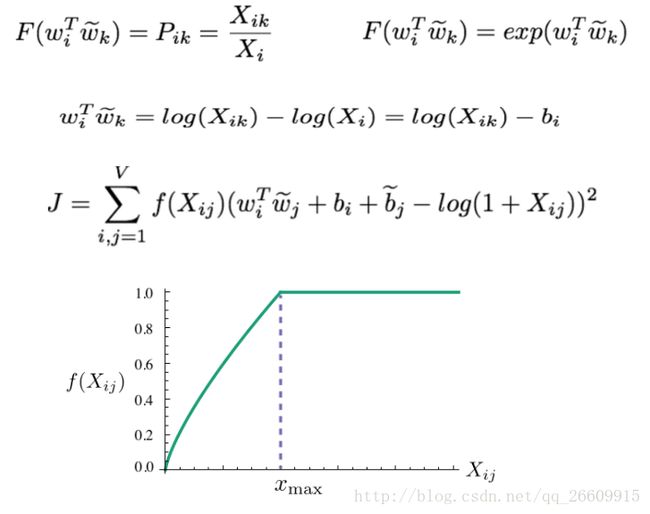
公式:
测试
分为内部测试和外部测试:
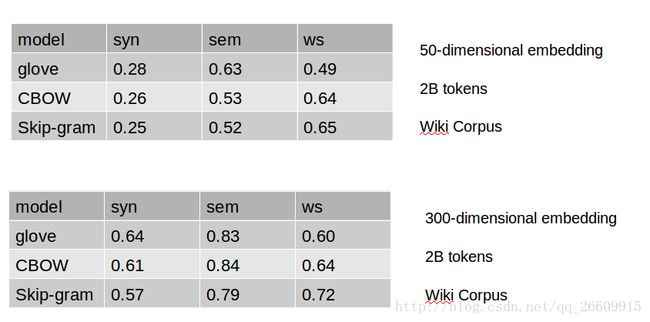
内部测试:测试语法,语义,词义。
论文实验结果:

本实验结果:
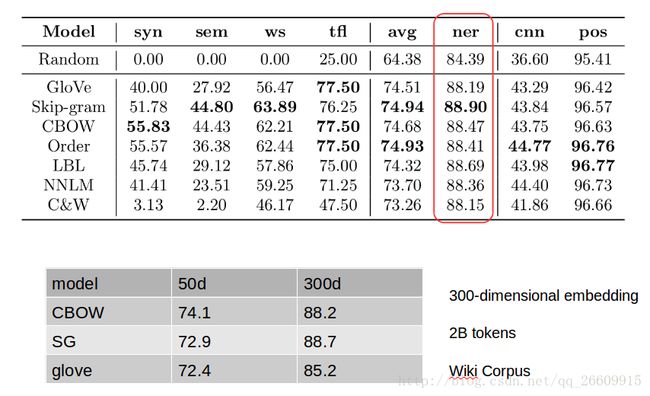
内部测试:NER(命名实体识别)
实验结果:
结果
经过实验对比,三个模型的效果同等条件下差别不大,最终选择CBOW模型训练,原因如下:
1:CBOW有成熟的开源工具包gensim.word2vec,可以提供分布式训练
2:word2vec可以在线训练,glove不可以
3:CBOW比SG训练速度快
word2vec训练方法
从英文维基百科下载了数据(时间2015-03-01,大概11g):
https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
目前word2vec是支持online的,但是,再训练的语料要和之前的语料分布相同。
import multiprocessing
from gensim.models import Word2Vec
def train_model1(corpusfilename, modelfilenamebin, modelfilenametxt, size):
"""训练一个词向量模型"""
model = Word2Vec(MySentences(corpusfilename),
hs=1, size=size, window=5, min_count=10, iter=10, workers=multiprocessing.cpu_count())
model.save(modelfilenamebin)
model.wv.save_word2vec_format(modelfilenametxt, binary=False)参数解释:
1.sg=1是skip-gram算法,对低频词敏感;默认sg=0为CBOW算法。
2.size是输出词向量的维数,值太小会导致词映射因为冲突而影响结果,值太大则会耗内存并使算法计算变慢,一般值取为100到300之间。
3.window是句子中当前词与目标词之间的最大距离,3表示在目标词前看3-b个词,后面看b个词(b在0-3之间随机)。
4.min_count是对词进行过滤,频率小于min-count的单词则会被忽视,默认值为5。
5.negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值为1e-3。
6.workers控制训练的并行,此参数只有在安装了Cpython后才有效,否则只能使用单核。
word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测。对于每一条输入文本,我们选取一个上下文窗口和一个中心词,并基于这个中心词去预测窗口里其他词出现的概率。因此,word2vec模型可以方便地从新增语料中学习到新增词的向量表达,是一种高效的在线学习算法(online learning)。
def retrain(corpusfilename,modelfilenamebin,remodelfilenamebin,remodelfilenametxt):
model = Word2Vec.load(modelfilenamebin)
model.build_vocab(MySentences(corpusfilename), update=True)
model.train(MySentences(corpusfilename), total_examples=model.corpus_count, epochs=10)
model.save(remodelfilenamebin)
model.wv.save_word2vec_format(remodelfilenametxt, binary=False)参考文献
- Distributed Representations of Words and Phrases and their Compositionality
- Efficient Estimation of Word Representations in Vector Space
- GloVe Global Vectors forWord Representation
- 参考了一些博客网站,不一一列表,但非常感谢