C++ 程序设计入门

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
个人主页:小嗷犬的个人主页
个人网站:小嗷犬的技术小站
个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
-
- 如何开始
-
- 环境配置
-
- 集成开发环境(IDE)
- 编译器
- 第一个 C++ 程序
- C++ 语法基础
-
- 代码框架
-
- 什么是 include
- 什么是 namespace
- 什么是 main 函数
- 注释
- 输入与输出
-
- cin 与 cout
- scanf 与 printf
- 扩展内容
-
- endl 与 '\n'
- C++ 中的空白字符
- define 命令
- 变量
-
- 数据类型
-
- 布尔类型
- 整数类型
- 字符类型
- 浮点类型
- 无类型
- 类型转换
-
- 数值提升
-
- 整数提升
- 浮点提升
- 数值转换
-
- 整数转换
- 浮点转换
- 浮点整数转换
- 布尔转换
- 定义变量
- 变量作用域
- 常量
- 运算
-
- 算术运算符
-
- 算术运算中的类型转换
- 位运算符
- 自增/自减 运算符
- 复合赋值运算符
- 条件运算符
- 比较运算符
- 逻辑运算符
- 逗号运算符
- 成员访问运算符
- C++ 运算符优先级总表
- 流程控制
-
- 分支结构
-
- if 语句
-
- 基本 if 语句
- if...else 语句
- else if 语句
- switch 语句
- 循环结构
-
- for 循环
- while 循环
- do...while 循环
- 三种循环的联系
- break 与 continue 语句
- 高级数据类型
-
- 数组
-
- 定义数组
- 访问数组元素
-
- 越界访问下标
- 多维数组
- 结构体
-
- 定义结构体
- 访问/修改成员元素
- 结构体的意义
- 结构体的弊端
- 指针
-
- 变量的地址、指针
- 指针的声明与使用
- 指针的偏移
-
- 使用指针偏移访问数组
- 空指针
- 指针的进阶使用
-
- 指针类型参数的使用
- 动态实例化
- 动态创建数组
- 二维数组
- 动态创建二维数组
- 指向函数的指针
- 函数
-
- 函数的声明
- 实现函数:编写函数的定义
- 函数的调用
- main 函数
- 文件操作
-
- 文件的概念
- 文件的操作步骤
- freopen 函数
-
- 函数简介
- 函数原型
- 参数说明
- 文件打开格式
- 使用方法
- 模板
- fopen 函数(选读)
-
- 函数原型
- 可用读写函数(基本)
- 使用方式
- C++ 的 ifstream / ofstream 文件输入输出流
-
- 使用方法
- 模板
- 参考资料
程序是算法与数据结构的载体,是计算机用以解决问题的工具。
而在程序设计比赛中,最主流的语言是 C++。
学习编程是学习程序设计最 基础 的部分。
如何开始
环境配置
工欲善其事,必先利其器。
集成开发环境(IDE)
IDE 是 Integrated Development Environment 的缩写,即集成开发环境。它包括了代码编辑器、编译器、调试器等程序从编写到运行的一系列工具。配置较为简单,适合入门玩家。
在竞赛中最常见的是 Dev-C++。Dev-C++ 的优点在于界面简洁友好,安装便捷,支持单文件编译,因此成为了许多入门程序设计选手以及 C++ 语言初学者的首选。
Dev-C++ 起源于 Colin Laplace 编写的 Bloodshed Dev-C++。该版本自 2005 年 2 月 22 日停止更新。后续又有 Orwell Dev-C++、Embarcadero Dev-C++ 等衍生版本。
以上的 Dev-C++ 分发都被认为是「官方的」。此外,在 2015 年 Orwell Dev-C++ 停止更新后,因为教学需要,一位来自中国的个人开发者 royqh1979 决定继续开发他的 Dev-C++ 个人分支,命名为小熊猫 Dev-C++,集成了智能提示和高版本的 MinGW64,非常便于国内的个人使用和学习,项目官网位于 小熊猫 Dev-C++,源代码托管于 Github。

小熊猫官网也提供了相应的 小熊猫 Dev-C++ 入门教程,本文推荐使用小熊猫 Dev-C++ 来进行 C++ 的学习。
编译器
除了使用 IDE 之外,我们也可以使用编译器来编译我们的代码。这么做的好处是可以分离程序的编写和编译过程,使得我们可以选择更加适合自己的代码编辑器;同时,也可以使用命令行更灵活地编译我们的代码。
常见的编译器有 GCC、Clang、MSVC 等。
配置相较于 IDE 来说稍微复杂一些,适合已经对 C++ 有一定理解的玩家。
第一个 C++ 程序
通过编写一个简单的示例程序来开始我们的 C++ 之旅吧!
#include 与它相对应的 C 语言版本如下:
#include 注意:本文的 C 语言代码仅做参考,C++ 基本上兼容 C 语言,并且拥有许多新的功能,可以让选手在赛场上事半功倍。
C++ 语法基础
代码框架
如果你不想深究背后的原理,初学时可以直接将这个「框架」背下来:
#include 什么是 include
#include 其实是一个预处理命令,意思为将一个文件放在这条语句处,被放的文件被称为头文件。也就是说,在编译时,编译器会复制头文件 iostream 中的内容,粘贴到 #include 这条语句处。这样,你就可以使用 iostream 中提供的 std::cin、std::cout、std::endl 等对象了。
如果你学过 C 语言,你会发现目前我们接触的 C++ 中的头文件一般都不带 .h 后缀,而那些 C 语言中的头文件 xx.h 都变成了 cxx,如 stdio.h 变成了 cstdio。因为 C++ 为了和 C 保持兼容,都直接使用了 C 语言中的头文件,为了区分 C++ 的头文件和 C 的头文件,使用了 c 前缀。
通常情况下,我们只需要 #include 自己所需的头文件,比如上文的 iostream 和 cstdio,引入它们就可以使用 std::cin、std::cout、scanf、printf 来进行输入输出了。
什么是 namespace
namespace 是命名空间的意思。C++ 的命名空间机制可以用来解决复杂项目中名字冲突的问题。
举个例子:C++ 标准库的所有内容均定义在 std 命名空间中,如果你定义了一个叫 cin 的变量,则可以通过 cin 来访问你定义的 cin 变量,通过 std::cin 访问标准库的 cin 对象,而不用担心产生冲突。
如果你不想每次都写 std::,可以使用 using namespace std; 来引入 std 命名空间,这样你就可以直接使用 cin、cout、endl 等对象了。
什么是 main 函数
可以理解为程序运行时就会执行 main() 中的代码。
实际上,main 函数是由系统或外部程序调用的。如,你在命令行中调用了你的程序,也就是调用了你程序中的 main 函数。
最后的 return 0; 表示程序运行成功。默认情况下,程序结束时返回 0 表示一切正常,否则返回值表示错误代码。这个值返回给谁呢?其实就是调用你写的程序的系统或外部程序,它会在你的程序结束时接收到这个返回值。如果不写 return 语句的话,程序正常结束默认返回值也是 0。
在 C 或 C++ 中,程序的返回值不为 0 会导致运行时错误(RE)。
注释
在 C++ 代码中,注释有两种写法:
- 单行注释:
// - 多行注释:
/* */
程序运行没有影响,可以用来解释程序的意思,还可以在让某段代码不执行(但是依然保留在源文件里)。
在工程开发中,注释可以便于日后维护、他人阅读。
在程序设计比赛中,很少有人写大段的注释,但注释可以便于在写代码的时候理清思路,或者便于日后复习。而且,如果要写题解、教程的话,适量的注释可以便于读者阅读,理解代码的意图。
因此,写注释是一个好习惯。
输入与输出
cin 与 cout
在 C++ 中,我们可以使用 cin 和 cout 来进行输入输出。
#include 上面程序中,cin 和 cout 分别是输入流和输出流的对象,>> 和 << 分别是输入运算符和输出运算符。
如何理解输入输出流呢?我们可以把数据流想象成水流,cin 是一个水龙头,cout 是一个排水口,变量 x 和 y 是两个容器,>> 和 << 是连接水龙头和容器、排水口和容器的管道。cin >> x 的意思就是将水龙头的水流输入到容器 x 中,cout << y 的意思就是将容器 y 中的水流输出到排水口,运算符的方向总是指向数据流的方向。
事实上,上述的比喻并不严谨,因为变量是有多种类型的,这意味着“容器”也有多种类型,自然数据流中就不会只有水这一种“液体”。
关于变量的知识,我们将在后面的章节中进行介绍。
scanf 与 printf
scanf 与 printf 其实是 C 语言提供的函数。大多数情况下,它们的速度比 cin 和 cout 更快,并且能够方便地控制输入输出格式。
#include 其中,%d 表示读入/输出的变量是一个有符号整型(int 型)的变量。这样的符号称为格式控制符,用来控制输入输出的格式。
常用的控制符有:
| 控制符 | 说明 |
|---|---|
%s |
字符串 |
%c |
字符 |
%d |
有符号十进制整数 (int) |
%lld 或 %I64d (依系统而定) |
长整型 (long long) |
%lf |
双精度浮点数 (double) |
%u |
无符号十进制整数 (unsigned int) |
%llu 或 %I64u (依系统而定) |
无符号长整型 (unsigned long long) |
格式控制符除了能表示类型外,还能够控制格式,常用的有:
| 控制符 | 说明 |
|---|---|
%1d |
长度为 1 的整型。 在读入时,即使没有空格也可以逐位读入数字。 在输出时,若指定的长度大于数字的位数,就会在数字前用空格填充。若指定的长度小于数字的位数,就没有效果。 |
%.6lf |
用于输出,保留 6 位小数。 |
上面两个格式控制符相应位置填入不同数字就会有不同的效果,如 %.3lf 表示保留 3 位小数。
扩展内容
endl 与 ‘\n’
endl 是 C++ 中的一个 IO 操作符,它的作用是插入一个换行符,并刷新输出缓冲区。cout << endl; 事实上等价于 cout << '\n' << flush;。
大部分情况下 cout << '\n' 和 cout << endl 运行起来并无明显区别,除非题目要求你输出之后立即刷新缓冲区(说的就是你,交互题!)。
C++ 中的空白字符
在 C++ 中,所有空白字符(空格、制表符、换行),多个或是单个,都被视作是一样的。(当然,引号中视作字符串的一部分的不算。)
因此,你可以自由地使用任何代码风格(除了行内注释、字符串字面量与预处理命令必须在单行内),例如:
#include 这段程序和上文写的程序一样,能够完成相同的事情,读入两个整数,然后先输出第二个整数,再输出第一个整数,每输出一个整数换一行。
当然,这么做是不被推荐的。
define 命令
#define 是一种预处理命令,用于定义宏,本质上是文本替换。例如:
#include 宏可以带参数,带参数的宏可以像函数一样使用:
#include 但是带参数的宏和函数有区别。因为宏是文本替换,所以会引发许多问题。如:
#include 因此,使用 #define 是有风险的,应谨慎使用。
变量
数据类型
C++ 的类型系统主要由如下几部分组成:
- 基础类型(括号内为代表关键词/代表类型)
- 无类型/
void型 (void) - (C++11 起)空指针类型 (
std::nullptr_t) - 算术类型
- 整数类型 (
int) - 布尔类型/
bool型 (bool) - 字符类型 (
char) - 浮点类型 (
float,double)
- 整数类型 (
- 无类型/
- 复合类型1
布尔类型
一个 bool 类型的变量取值只可能为两种:true 和 false。
一般情况下,一个 bool 类型变量占有 1 字节(一般情况下,1 字节 = 8 位)的空间。
整数类型
用于存储整数,最基础的整数类型是 int。
整数类型一般按位宽有 5 个梯度:char, short, int, long, long long。
C++ 标准保证 1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long),但对于每种类型的位宽并没有做出具体的规定。
对于 int 关键字,可以使用如下修饰关键字进行修饰:
- 符号性
signed:有符号的(默认)unsigned:无符号的
- 大小
short:短整型long:长整型long long:长长整型
下表给出了各个类型的等价形式和位宽:
| 类型 | 等价形式 | 位宽(C++ 标准) | 位宽(常见) |
|---|---|---|---|
signed char |
signed char |
8 8 8 | |
unsigned char |
unsigned char |
8 8 8 | |
short, short int, signed short, signed short int |
short int |
≥ 16 \geq 16 ≥16 | 16 16 16 |
unsigned short, unsigned short int |
unsigned short int |
≥ 16 \geq 16 ≥16 | 16 16 16 |
int, signed, signed int |
int |
≥ 16 \geq 16 ≥16 | 32 32 32 |
unsigned, unsigned int |
unsigned int |
≥ 16 \geq 16 ≥16 | 32 32 32 |
long, long int, signed long, signed long int |
long int |
≥ 32 \geq 32 ≥32 | 32 32 32 |
unsigned long, unsigned long int |
unsigned long int |
≥ 32 \geq 32 ≥32 | 32 32 32 |
long long, long long int, signed long long, signed long long int |
long long int |
≥ 64 \geq 64 ≥64 | 64 64 64 |
unsigned long long, unsigned long long int |
unsigned long long int |
≥ 64 \geq 64 ≥64 | 64 64 64 |
对于整数类型,当位宽为 x x x 时,有符号类型的表示范围为 − 2 x − 1 ∼ 2 x − 1 − 1 -2^{x-1} \sim 2^{x-1}-1 −2x−1∼2x−1−1,无符号类型的表示范围为 0 ∼ 2 x − 1 0 \sim 2^x-1 0∼2x−1。
程序设计中最常用的两个整数类型是 int 和 long long。
字符类型
分为「窄字符类型」和「宽字符类型」,由于程序设计竞赛几乎不会用到宽字符类型,故此处仅介绍窄字符类型。
窄字符型位数一般为 8 位,实际上底层存储方式仍然是整数,一般通过 ASCII 编码 实现字符与整数的一一对应,有如下三种:
signed char:有符号字符表示的类型,表示范围在 − 128 ∼ 127 -128 \sim 127 −128∼127 之间。unsigned char:无符号字符表示的类型,表示范围在 0 ∼ 255 0 \sim 255 0∼255 之间。char:有符号或无符号字符表示的类型,具体由编译器决定。
事实上,只有 char 类型的变量才应该用于表示字符,signed char 和 unsigned char 类型通常被视为整数类型。
浮点类型
用于存储「实数」(注意并不是严格意义上的实数,而是实数在一定规则下的近似),包括以下三种:
float:单精度浮点类型。如果支持就会匹配 IEEE-754 binary32 格式。double:双精度浮点类型。如果支持就会匹配 IEEE-754 binary64 格式。long double:扩展精度浮点类型。如果支持就会匹配 IEEE-754 binary128 格式,否则如果支持就会匹配 IEEE-754 binary64 扩展格式,否则匹配某种精度优于 binary64 而值域至少和 binary64 一样好的非 IEEE-754 扩展浮点格式,否则匹配 IEEE-754 binary64 格式。
| 浮点格式 | 位宽 | 最大正数 | 精度位数 |
|---|---|---|---|
| IEEE-754 binary32 格式 | 32 32 32 | 3.4 × 1 0 38 3.4 \times 10^{38} 3.4×1038 | 6 ∼ 9 6 \sim 9 6∼9 |
| IEEE-754 binary64 格式 | 64 64 64 | 1.8 × 1 0 308 1.8 \times 10^{308} 1.8×10308 | 15 ∼ 17 15 \sim 17 15∼17 |
| IEEE-754 binary64 扩展格式 | ≥ 80 \geq 80 ≥80 | ≥ 1.2 × 1 0 4932 \geq 1.2 \times 10^{4932} ≥1.2×104932 | ≥ 18 ∼ 21 \geq 18 \sim 21 ≥18∼21 |
| IEEE-754 binary128 格式 | 128 128 128 | ≥ 1.2 × 1 0 4932 \geq 1.2 \times 10^{4932} ≥1.2×104932 | 33 ∼ 36 33 \sim 36 33∼36 |
IEEE-754 浮点格式的最小负数是最大正数的相反数。
因为 float 类型表示范围较小,且精度不高,实际应用中常使用 double 类型表示浮点数。
除此之外,浮点类型可以支持一些特殊值:
- 正负无穷:
INFINITY/-INFINITY - 负零:
-0.0,例如1.0 / 0.0 == INFINITY,1.0 / -0.0 == -INFINITY - 非数 (
NaN):std::nan,NAN, 一般可以由0.0 / 0.0之类的运算产生。它与任何值(包括自身)比较都不相等,C++11 后可以 使用std::isnan判断一个浮点数是不是NaN
无类型
void 类型为无类型,与上面几种类型不同的是,不能将一个变量声明为 void 类型。但是函数的返回值允许为 void 类型,表示该函数无返回值。
类型转换
在一些时候(比如某个函数接受 int 类型的参数,但传入了 double 类型的变量),我们需要将某种类型,转换成另外一种类型。
C++ 中类型的转换机制较为复杂,这里主要介绍对于基础数据类型的两种转换:数值提升和数值转换。
数值提升
数值提升过程中,值本身保持不变,不会产生精度损失。
整数提升
小整数类型(如 char)的纯右值2可转换成较大整数类型(如 int)的纯右值。
具体而言,算术运算符不接受小于 int 的类型作为它的实参,而在左值到右值转换后,如果适用就会自动实施整数提升。
具体地,有如下规则:
- 源类型为
signed char、signed short/short时,可提升为int。 - 源类型为
unsigned char、unsigned short时,若int能保有源类型的值范围,则可提升为int,否则可提升为unsigned int。 char的提升规则取决于其底层类型是signed char还是unsigned char。bool类型可转换到int:false变为0,true变为1。- 若目标类型的值范围包含源类型,且源类型的值范围不能被
int和unsigned int包含,则源类型可提升为目标类型3。
浮点提升
位宽较小的浮点数可以提升为位宽较大的浮点数(例如 float 类型的变量和 double 类型的变量进行算术运算时,会将 float 类型变量提升为 double 类型变量),其值不变。
数值转换
数值转换过程中,值可能会发生改变,可能会产生精度损失。
注意:数值提升优先于数值转换。如 bool->int 时是数值提升而非数值转换。
整数转换
- 如果目标类型为位宽为 x x x 的无符号整数类型,则转换结果是原值 m o d 2 x \bmod 2^x mod2x 后的结果。
- 若目标类型位宽大于源类型位宽:
- 若源类型为有符号类型,一般情况下需先进行符号位扩展再转换。
- 若源类型为无符号类型,则需先进行零扩展再转换。
- 若目标类型位宽不大于源类型位宽,则需先截断再转换。
- 若目标类型位宽大于源类型位宽:
- 如果目标类型为位宽为 x x x 的带符号整数类型,则 一般情况下,转换结果可以认为是原值 m o d 2 x \bmod 2^x mod2x 后的结果。
- 如果目标类型是
bool,则是 布尔转换。 - 如果源类型是
bool,则false转为对应类型的0,true转为对应类型的1。
浮点转换
位宽较大的浮点数转换为位宽较小的浮点数,会将该数舍入到目标类型下最接近的值。
浮点整数转换
- 浮点数转换为整数时,会舍弃浮点数的全部小数部分。
如果目标类型是bool,则是 布尔转换。 - 整数转换为浮点数时,会舍入到目标类型下最接近的值。
如果该值不能适应到目标类型中,那么行为未定义。
如果源类型是bool,那么false转换为0,而true转换为1。
布尔转换
将其他类型转换为 bool 类型时,零值转换为 false,非零值转换为 true。
定义变量
简单来说4,定义一个变量,需要包含类型说明符(指明变量的类型),以及要定义的变量名。
例如,下面这几条语句都是变量定义语句:
int hello;
double swufe;
char acm = '6';
在目前我们所接触到的程序段中,定义在花括号内部的变量是局部变量,而定义在所有花括号外部的变量是全局变量。实际有例外,但是现在不必了解。
定义时没有初始化值的全局变量会被初始化为 0。而局部变量没有这种特性,需要手动赋初始值,否则可能引起难以发现的 bug。
变量作用域
变量的作用域是指变量在程序中有效的范围。
- 全局变量的作用域:自其定义之处开始,至文件结束位置为止。
- 局部变量的作用域:自其定义之处开始,至代码块结束位置为止。
由一对大括号括起来的若干语句构成一个代码块。
int x = 6; // 定义全局变量
int main()
{
int x = 555; // 定义局部变量
printf("%d\n", x); // 输出 x
return 0;
}
如果一个代码块的内嵌块中定义了相同变量名的变量,则内层块中将无法访问外层块中相同变量名的变量。
例如上面的代码中,输出的 x 的值将是 555。因此为了防止出现意料之外的错误,请尽量避免局部变量与全局变量重名的情况。
常量
常量,又称常变量,值为固定值,在程序执行期间不会改变。
常量的值在定义后不能被修改。定义时加一个 const 关键字即可。
const double Pi = 3.1415926;
Pi = 4;
如果修改了常量的值,在编译环节就会报错:error: assignment of read-only variable‘Pi’。
运算
算术运算符
| 运算符 | 功能 |
|---|---|
+ (单目) |
取正 |
- (单目) |
取负 |
* |
乘法 |
/ |
除法 |
% |
取模 |
+ |
加法 |
- |
减法 |
单目运算符(又称一元运算符)指被操作对象只有一个的运算符,而双目运算符(又称二元运算符)的被操作对象有两个。例如 1 + 2 中加号就是双目运算符,它有 1 和 2 两个被操作数。
算术运算符中有两个单目运算符(取正、取负)以及五个双目运算符(乘法、除法、取模、加法、减法),其中单目运算符的优先级最高。
其中取模运算符 % 意为计算两个整数相除得到的余数,即求余数。
C++ 中的算术运算遵循数学中加减乘除的优先规律,首先进行优先级高的运算,同优先级自左向右运算,括号提高优先级。
算术运算中的类型转换
对于双目算术运算符,当参与运算的两个变量类型相同时,不发生类型转换,运算结果将会用参与运算的变量的类型容纳,否则会发生类型转换,以使两个变量的类型一致。
转换的规则如下:
- 先将
char、bool、short等类型提升至int(或unsigned int,取决于原类型的符号性)类型; - 若存在一个变量类型为
long double,会将另一变量转换为long double类型; - 否则,若存在一个变量类型为
double,会将另一变量转换为double类型; - 否则,若存在一个变量类型为
float,会将另一变量转换为float类型; - 否则(即参与运算的两个变量均为整数类型):
- 若两个变量符号性一致,则将位宽较小的类型转换为位宽较大的类型;
- 否则,若无符号变量的位宽不小于带符号变量的位宽,则将带符号数转换为无符号数对应的类型;
- 否则,若带符号操作数的类型能表示无符号操作数类型的所有值,则将无符号操作数转换为带符号操作数对应的类型;
- 否则,将带符号数转换为相对应的无符号类型。
例如,对于一个整型 int 变量 x 和另一个双精度浮点型 double 类型变量 y:
x/5的结果将会是整型int;x/5.0的结果将会是双精度浮点型double;x/y的结果将会是双精度浮点型double;x*2/5的结果将会是整型int;x*2.0/5的结果将会是双精度浮点型double;
位运算符
| 运算符 | 功能 |
|---|---|
~ (单目) |
按位非 |
& |
按位与 |
| |
按位或 |
^ |
按位异或 |
<< |
按位左移 |
>> |
按位右移 |
位运算就是基于整数的二进制表示进行的运算。由于计算机内部就是以二进制来存储数据,位运算是相当快的。
需要注意的是,位运算符的优先级低于普通的算数运算符。
自增/自减 运算符
有时我们需要让变量进行增加 1(自增)或者减少 1(自减),这时自增运算符 ++ 和自减运算符 -- 就派上用场了。
自增/自减运算符可放在变量前或变量后面,在变量前称为前缀,在变量后称为后缀,单独使用时前缀后缀无需特别区别,如果需要用到表达式的值则需注意,具体可看下面的例子。
i = 10;
x1 = i++; // x1 = 10。先 x1 = i,然后 i = i + 1
i = 10;
x2 = ++i; // x2 = 11。先 i = i + 1,然后赋值 x2
i = 10;
x3 = i--; // x3 = 10。先赋值 x3,然后 i = i - 1
i = 10;
x4 = --i; // x4 = 9。先 i = i - 1,然后赋值 x4
复合赋值运算符
复合赋值运算符实际上是表达式的缩写形式。可分为复合算术运算符 +=、-=、*=、/=、%= 和复合位运算符 &=、|=、^=、<<=、>>=。
例如,x = x + 2 可写为 x += 2,x = x - 2 可写为 x -= 2,x = x * 2 可写为 x *= 2。
条件运算符
条件运算符可以看作 if 语句的简写,a ? b : c 中如果表达式 a 成立,那么这个条件表达式的结果是 b,否则条件表达式的结果是 c。
条件运算符是 C++ 中唯一的三目运算符,所以平常说的三目运算符就是指条件运算符。
比较运算符
| 运算符 | 功能 |
|---|---|
> |
大于 |
>= |
大于等于 |
< |
小于 |
<= |
小于等于 |
== |
等于 |
!= |
不等于 |
其中特别需要注意的是要将等于运算符 == 和赋值运算符 = 区分开来,这在判断语句中尤为重要。
if (x=1) 与 if (x==1) 看起来类似,但实际功能却相差甚远。第一条语句是在对 x 进行赋值,若赋值为非 0 时为真值,表达式的条件始终是满足的,无法达到判断的作用;而第二条语句才是对 x 的值进行判断。
逻辑运算符
| 运算符 | 功能 |
|---|---|
&& |
逻辑与 |
|| |
逻辑或 |
! |
逻辑非 |
c = a && b; // 当 a 与 b 都为真时则 c 为真
c = a || b; // 当 a 或 b 其中一个为真时则 c 为真
c = !a; // 当 a 为假时则 c 为真
逗号运算符
逗号运算符可将多个表达式分隔开来,被分隔开的表达式按从左至右的顺序依次计算,整个表达式的值是最后的表达式的值。逗号表达式的优先级在所有运算符中的优先级是 最低 的。
x1, x2, x3; // 最后的值为 x3 的运算结果。
x = 1 + 2, 3 + 4, 5 + 6; //得到 x 的值为 3 而不是 11
// 因为赋值运算符 "=" 的优先级比逗号运算符高,先进行了赋值运算才进行逗号运算。
x = (1 + 2, 3 + 4, 5 + 6); // 得到 x 的值为 11
// 若要让 x 的值得到逗号运算的结果,则应将整个表达式用括号提高优先级。
成员访问运算符
| 运算符 | 功能 |
|---|---|
[] |
数组下标 |
. |
对象成员 |
& (单目) |
取地址/获取引用 |
* (单目) |
间接寻址/解引用 |
-> |
指针成员 |
这些运算符用来访问对象的成员或者内存。这里还省略了两个很少用到的运算符 .* 和 ->* ,其具体用法可以参见 C++ 语言手册。
auto result1 = arr[1]; // 获取 arr 中下标为 1 的对象
auto result2 = p.q; // 获取 p 对象的 q 成员
auto result3 = p -> q; // 获取 p 指针指向的对象的 q 成员,等价于 (*p).q
auto result4 = &v; // 获取指向 v 的指针
auto result5 = *v; // 获取 v 指针指向的对象
C++ 运算符优先级总表
来自 C++ 运算符优先级 - cppreference,有修改。
| 优先级 | 运算符 | 描述 | 结合性 |
|---|---|---|---|
| 1 | :: |
作用域解析 | 从左到右 |
| 2 | ++--type()、type{}f()a[].、-> |
后缀自增 后缀自减 函数风格转型 函数调用 下标访问 成员访问 |
从左到右 |
| 3 | ++a--a+a-a!~(type)*a&asizeofnewnew[]deletedelete[] |
前缀自增 前缀自减 取正 取负 逻辑非 按位非 C 风格转型 间接寻址/解引用 取地址/获取引用 返回类型大小 动态元素类型分配 动态数组类型分配 动态析构元素内存 动态析构数组内存 |
从右到左 |
| 4 | .*->* |
类对象成员引用 类指针成员引用 |
从左到右 |
| 5 | */% |
乘法 除法 取模 |
从左到右 |
| 6 | +- |
加法 减法 |
从左到右 |
| 7 | <<>> |
左移 右移 |
从左到右 |
| 8 | <=> |
三路比较 | 从左到右 |
| 9 | <<=>>= |
小于 小于等于 大于 大于等于 |
从左到右 |
| 10 | ==!= |
等于 不等于 |
从左到右 |
| 11 | & |
按位与 | 从左到右 |
| 12 | ^ |
按位异或 | 从左到右 |
| 13 | | |
按位或 | 从左到右 |
| 14 | && |
逻辑与 | 从左到右 |
| 15 | || |
逻辑或 | 从左到右 |
| 16 | ?:throw=+=-=*=/=%=<<=>>=&=^=|= |
条件运算符 抛出异常 赋值 加赋值 减赋值 乘赋值 除赋值 取模赋值 左移赋值 右移赋值 按位与赋值 按位异或赋值 按位或赋值 |
从右到左 |
| 17 | , |
逗号 | 从左到右 |
流程控制
分支结构
一个程序默认是按照代码的顺序执行下来的,有时我们需要选择性的执行某些语句,这时候就需要分支的功能来实现。选择合适的分支语句可以提高程序的效率。
if 语句
基本 if 语句
if (条件)
{
主体;
}
if 语句通过对条件进行求值,若结果为真(非 0),执行语句,否则不执行。
如果主体中只有单个语句的话,花括号可以省略。
if…else 语句
if (条件)
{
主体1;
}
else
{
主体2;
}
if…else 语句和 if 语句类似,else 不需要再写条件。当 if 语句的条件满足时会执行 if 里的语句,if 语句的条件不满足时会执行 else 里的语句。同样,当主体只有一条语句时,可以省略花括号。
else if 语句
if (条件1)
{
主体1;
}
else if (条件2)
{
主体2;
}
else if (条件3)
{
主体3;
}
else
{
主体4;
}
else if 语句是 if 和 else 的组合,对多个条件进行判断并选择不同的语句分支。在最后一条的 else 语句不需要再写条件。例如,若条件 1 为真,执行主体 1,条件 3 为真而条件 1 和条件 2 都为假,执行主体 3,所有的条件都为假才执行主体 4。
实际上,这一个语句相当于第一个 if 的 else 分句只有一个 if 语句,就将花括号省略之后放在一起了。如果条件相互之间是并列关系,这样写可以让代码的逻辑更清晰。
switch 语句
switch (选择句)
{
case 标签1:
主体1;
case 标签2:
主体2;
default:
主体3;
}
switch 语句执行时,先求出选择句的值,然后根据选择句的值选择相应的标签,从标签处开始执行。其中,选择句必须是一个整数类型表达式,而标签都必须是整数类型的常量。例如:
int i = 1; // 这里的 i 的数据类型是整型 ,满足整数类型的表达式的要求
switch (i)
{
case 1:
cout << "SWUFE" << endl;
}
char i = 'A';
// 这里的 i 的数据类型是字符型 ,但 char
// 也是属于整数的类型,满足整数类型的表达式的要求
switch (i)
{
case 'A':
cout << "SWUFE" << endl;
}
switch 语句中还要根据需求加入 break 语句进行中断,否则在对应的 case 被选择之后接下来的所有 case 里的语句和 default 里的语句都会被运行。具体例子可看下面的示例。
char i = 'B';
switch (i)
{
case 'A':
cout << "SWUFE" << endl;
break;
case 'B':
cout << "ACM" << endl;
default:
cout << "Hello World" << endl;
}
以上代码运行后输出的结果为 ACM 和 Hello World,如果不想让下面分支的语句被运行就需要 break 了,具体例子可看下面的示例。
char i = 'B';
switch (i)
{
case 'A':
cout << "SWUFE" << endl;
break;
case 'B':
cout << "ACM" << endl;
break;
default:
cout << "Hello World" << endl;
}
以上代码运行后输出的结果为 ACM,因为 break 的存在,接下来的语句就不会继续被执行了。最后一个语句不需要 break,因为下面没有语句了。
处理入口编号不能重复,但可以颠倒。也就是说,入口编号的顺序不重要。各个 case(包括 default)的出现次序可任意。例如:
char i = 'B';
switch (i)
{
case 'B':
cout << "ACM" << endl;
break;
default:
cout << "Hello World" << endl;
break;
case 'A':
cout << "SWUFE" << endl;
}
switch 的 case 分句中也可以选择性的加花括号。不过要注意的是,如果需要在 switch 语句中定义变量,花括号是必须要加的。例如:
char i = 'B';
switch (i)
{
case 'A':
{
int i = 1, j = 2;
cout << "SWUFE" << endl;
ans = i + j;
break;
}
case 'B':
{
int x = 3;
cout << "ACM" << endl;
ans = x * x;
break;
}
default:
{
cout << "Hello World" << endl;
}
}
循环结构
有时,我们需要做一件事很多遍,为了不写过多重复的代码,我们需要循环。
有时,循环的次数不是一个常量,那么我们无法将代码重复多遍,必须使用循环。
for 循环
for (初始化; 判断条件; 更新)
{
循环体;
}
流程图:

例如:
// 读入 n 个数
for (int i = 0; i < n; ++i)
{
cin >> a[i];
}
for 循环的三个部分中,任何一个部分都可以省略。其中,若省略了判断条件,相当于判断条件永远为真。
while 循环
while (判断条件)
{
循环体;
}
流程图:

例如:
// 验证科拉茨猜想
while (x > 1)
{
if (x % 2 == 1)
{
x = 3 * x + 1;
}
else
{
x = x / 2;
}
}
do…while 循环
do
{
循环体;
} while (判断条件);
流程图:
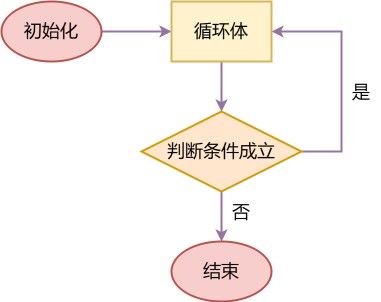
与 while 语句的区别在于,do…while 语句是先执行循环体再进行判断的。
// 枚举排列
do
{
// do someting...
} while (next_permutation(a + 1, a + n + 1));
三种循环的联系
// for 循环
for (statement1; statement2; statement3)
{
statement4;
}
// while 循环
statement1;
while (statement2)
{
statement4;
statement3;
}
在 statement4 中没有 continue 语句(见下文)的时候是等价的,但是下面一种方法很少用到。
// while 循环
statement1;
while (statement2)
{
statement1;
}
// do...while 循环
do
{
statement1;
} while (statement2);
在 statement1 中没有 continue 语句的时候这两种方式也也是等价的。
while (1)
{
// do something...
}
for (;;)
{
// do something...
}
do
{
// do something...
} while (1);
这三种方式都是永远循环下去,可以使用 break(见下文)退出。
可以看出,三种循环可以彼此代替,但一般来说,循环的选用遵守以下原则:
- 循环过程中有个固定的增加步骤(最常见的是枚举)时,使用 for 循环;
- 只确定循环的终止条件时,使用 while 循环;
- 使用 while 循环时,若要先执行循环体再进行判断,使用 do…while 循环。一般很少用到,常用场景是用户输入。
break 与 continue 语句
break 语句的作用是退出循环。
continue 语句的作用是跳过循环体的余下部分。下面以 continue 语句在 do…while 语句中的使用为例:
do
{
// do something...
continue; // 等价于 goto END;
// do something...
END:;
} while (statement);
break 与 continue 语句均可在三种循环语句的循环体中使用。
一般来说,break 与 continue 语句用于让代码的逻辑更加清晰,例如:
// 逻辑较为不清晰,大括号层次复杂
for (int i = 1; i <= n; ++i)
{
if (i != x)
{
for (int j = 1; j <= n; ++j)
{
if (j != x)
{
// do something...
}
}
}
}
// 逻辑更加清晰,大括号层次简单明了
for (int i = 1; i <= n; ++i)
{
if (i == x)
continue;
for (int j = 1; j <= n; ++j)
{
if (j == x)
continue;
// do something...
}
}
// for 语句判断条件复杂,没有体现「枚举」的本质
for (int i = l; i <= r && i % 10 != 0; ++i)
{
// do something...
}
// for 语句用于枚举,break 用于「到何时为止」
for (int i = l; i <= r; ++i)
{
if (i % 10 == 0)
break;
// do something...
}
// 语句重复,顺序不自然
statement1;
while (statement3)
{
statement2;
statement1;
}
// 没有重复语句,顺序自然
while (1)
{
statement1;
if (!statement3)
break;
statement2;
}
高级数据类型
数组
数组是存放相同类型对象的容器,数组中存放的对象没有名字,而是要通过其所在的位置访问。数组的大小是固定的,不能随意改变数组的长度。
定义数组
数组的声明形如 a[n],其中,a 是数组的名字,n 是数组中元素的个数。在编译时,n 应该是已知的,也就是说,n 应该是一个整型的常量表达式。
unsigned int n1 = 42;
const int n2 = 42;
int arr1[n1]; // 错误:n1 不是常量表达式
int arr2[n2]; // 正确:arr2 是一个长度为 42 的数组
不能将一个数组直接赋值给另一个数组:
int arr1[3];
int arr2 = arr1; // 错误
arr2 = arr1; // 错误
应该尽量将较大的数组定义为全局变量。因为局部变量会被创建在栈区中,过大(大于栈的大小)的数组会爆栈,进而导致 RE。如果将数组声明在全局作用域中,就会在静态区中创建数组。
访问数组元素
可以通过下标运算符 [] 来访问数组内元素,数组的索引(即方括号中的值)从 0 开始。以一个包含 10 个元素的数组为例,它的索引为 0 到 9,而非 1 到 10。但在程序设计中,为了使用方便,我们通常会将数组开大一点,不使用数组的第一个元素,从下标 1 开始访问数组元素。
例1
从标准输入中读取一个整数 n n n,再读取 n n n 个数,存入数组中。其中, n ≤ 1000 n\leq 1000 n≤1000。
#include 例2
(接例 1)求和数组 arr 中的元素,并输出和。满足数组中所有元素的和小于等于 2 31 − 1 2^{31}-1 231−1
#include 越界访问下标
数组的下标 i d x \mathit{idx} idx 应当满足 0 ≤ i d x < s i z e 0\leq \mathit{idx}< \mathit{size} 0≤idx<size,如果下标越界,则会产生不可预料的后果,如段错误(Segmentation Fault),或者修改预期以外的变量。
多维数组
多维数组的实质是「数组的数组」,即外层数组的元素是数组。一个二维数组需要两个维度来定义:数组的长度和数组内元素的长度。访问二维数组时需要写出两个索引:
int arr[5][4]; // 一个长度为 5 的数组,它的元素是「元素为 int 的长度为的 4 的数组」
arr[2][3] = 1; // 访问二维数组
我们经常使用嵌套的 for 循环来处理二维数组。
例
从标准输入中读取两个数 n n n 和 m m m,分别表示黑白图片的高与宽,满足 n , m ≤ 1000 n,m\leq 1000 n,m≤1000。对于接下来的 n n n 行数据,每行有用空格分隔开的 m m m 个数,代表这一位置的亮度值。现在我们读取这张图片,并将其存入二维数组中。
const int maxn = 1001;
int pic[maxn][maxn];
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; ++i)
for (int j = 1; j <= m; ++j)
cin >> pic[i][j];
类似地,你可以定义三维、四维,以及更高维的数组。
结构体
结构体(struct),可以看做是一系列称为成员元素的组合体。
可以看做是自定义的数据类型。
本节描述的 struct 不同于 C 中 struct,在 C++ 中 struct 被扩展为类似 class 的类说明符。
定义结构体
struct Object
{
int weight;
int value;
} e[array_length];
const Object a;
Object b, B[array_length], tmp;
Object *c;
上例中定义了一个名为 Object 的结构体,两个成员元素 value、weight,类型都为 int。
在 } 后,定义了数据类型为 Object 的常量 a,变量 b,变量 tmp,数组 B,指针 c。对于某种已经存在的类型,都可以使用这里的方法进行定义常量、变量、指针、数组等。
访问/修改成员元素
可以使用 变量名.成员元素名 进行访问。
如:输出 var 的 v 成员:cout << var.v。
也可以使用 指针名->成员元素名 或者 使用 (*指针名).成员元素名 进行访问。
如:将结构体指针 ptr 指向的结构体的成员元素 v 赋值为 tmp:(*ptr).v = tmp 或者 ptr->v = tmp。
结构体的意义
首先,条条大路通罗马,可以不使用结构体达到相同的效果。结构体的意义在于,它能够显式地将成员元素(在程序设计比赛中通常是变量)捆绑在一起,如本例中的 Object 结构体,便将 value、weight 放在了一起(定义这个结构体的实际意义是表示一件物品的重量与价值)。这样的好处边是限制了成员元素的使用。
想象一下,如果不使用结构体而使用两个数组 value[]、weight[],很容易写混淆。但如果使用结构体,能够减轻出现使用变量错误的几率。
并且不同的结构体(结构体类型,如 Object 这个结构体)或者不同的结构体变量(结构体的实例,如上方的 e 数组)可以拥有相同名字的成员元素(如 tmp.value、b.value),同名的成员元素相互独立(拥有独自的内存,比如说修改 tmp.value 不会影响 b.value 的值)。
这样的好处是可以使用尽可能相同或者相近的变量去描述一个物品。比如说 Object 里有 value 这个成员变量;我们还可以定义一个 Car 结构体,同时也拥有 value 这个成员;如果不使用结构体,或许我们就需要定义 valueOfObject[],valueOfCar[] 等不同名称的数组来区分。
如果想要更详细的描述一种事物,还可以定义成员函数。C++ 中的类就是为此而生的。
结构体的弊端
为了访问内存的效率更高,编译器在处理结构体中成员的实际存储情况时,可能会将成员对齐在一定的字节位置,也就意味着结构体中有空余的地方。因此,该结构体所占用的空间可能大于其中所有成员所占空间的总和。
指针
变量的地址、指针
在程序中,我们的数据都有其存储的地址。在程序每次的实际运行过程中,变量在物理内存中的存储位置不尽相同。不过,我们仍能够在编程时,通过一定的语句,来取得数据在内存中的地址。
地址也是数据。存放地址所用的变量类型有一个特殊的名字,叫做「指针变量」,有时也简称做「指针」。
指针变量的大小与机器的位数有关,32 位机器上的指针变量通常是 4 字节,64 位机器上的指针变量通常是 8 字节。
地址只是一个刻度一般的数据,为了针对不同类型的数据,「指针变量」也有不同的类型,比如,可以有 int 类型的指针变量,其中存储的地址(即指针变量存储的数值)对应一块大小为 32 位的空间的起始地址;有 char 类型的指针变量,其中存储的地址对应一块 8 位的空间的起始地址。
事实上,用户也可以声明指向指针变量的指针变量。
假如用户自定义了一个结构体:
struct TwoInt
{
int a;
int b;
};
则 TwoInt 类型的指针变量,对应着一块 2 × 32 = 64 bit 的空间。
指针的声明与使用
C/C++ 中,指针变量的类型为类型名后加上一个星号 *。比如,int 类型的指针变量的类型名即为 int*。
我们可以使用 & 符号取得一个变量的地址。
要想访问指针变量地址所对应的空间(又称指针所 指向 的空间),需要对指针变量进行 解引用(dereference),使用 * 符号。
int main()
{
int a = 123; // a: 123
int *pa = &a;
*pa = 321; // a: 321
}
对结构体变量也是类似。如果要访问指针指向的结构中的成员,需要先对指针进行解引用,再使用 . 成员关系运算符。不过,更推荐使用「箭头」运算符 -> 这一更简便的写法。
struct TwoInt
{
int a;
int b;
};
int main()
{
TwoInt x{1, 2}, y{6, 7};
TwoInt *px = &x;
(*px) = y; // x: {6,7}
(*px).a = 4; // x: {4,7}
px->b = 5; // x: {4,5}
}
指针的偏移
指针变量也可以和整数进行加减操作。对于 int 型指针,每加 1(递增 1),其指向的地址偏移 32 位(即 4 个字节);若加 2,则指向的地址偏移 2 × 32 = 64 位。同理,对于 char 型指针,每次递增,其指向的地址偏移 8 位(即 1 个字节)。
使用指针偏移访问数组
我们前面说过,数组是一块连续的存储空间。而在 C/C++ 中,直接使用数组名,得到的是数组的起始地址。
int main()
{
int a[3] = {0, 1, 2};
int *p = a; // p 指向 a[0]
*p = 4; // a: [4, 1, 2]
p = p + 1; // p 指向 a[1]
*p = 5; // a: [4, 5, 2]
p++; // p 指向 a[2]
*p = 6; // a: [4, 5, 6]
}
当通过指针访问数组中的元素时,往往需要用到「指针的偏移」,换句话说,即通过一个基地址(数组起始的地址)加上偏移量来访问。
我们常用 [] 运算符来访问数组中某一指定偏移量处的元素。比如 a[1] 或者 p[3]。这种写法和对指针进行运算后再引用是等价的,即 p[5] 和 *(p + 5) 是等价的两种写法。
空指针
在 C++11 之前,C++ 和 C 一样使用 NULL 宏表示空指针常量,C++ 中 NULL 的实现一般如下:
// C++11 前
#define NULL 0
空指针和整数 0 的混用在 C++ 中会导致许多问题,比如:
// 函数重载
int f(int x);
int f(int* p);
在调用 f(NULL) 时,实际调用的函数的类型是 int(int) 而不是 int(int *)。
为了解决这些问题,C++11 引入了 nullptr 关键字作为空指针常量。
C++ 规定 nullptr 可以隐式转换为任何指针类型,这种转换结果是该类型的空指针值。
nullptr 的类型为 std::nullptr_t,称作空指针类型,可能的实现如下:
namespace std
{
typedef decltype(nullptr) nullptr_t;
}
另外,C++11 起 NULL 宏的实现也被修改为了:
// C++11 起
#define NULL nullptr
指针的进阶使用
使用指针,使得程序编写者可以操作程序运行时中各处的数据,而不必局限于作用域。
指针类型参数的使用
在 C/C++ 中,调用函数(过程)时使用的参数,均以拷贝的形式传入子过程中(引用除外,会在后续介绍)。默认情况下,函数仅能通过返回值,将结果返回到调用处。但是,如果某个函数希望修改其外部的数据,或者某个结构体/类的数据量较为庞大、不宜进行拷贝,这时,则可以通过向其传入外部数据的地址,便得以在其中访问甚至修改外部数据。
下面的 swap 方法,通过接收两个 int 型的指针,在函数中使用中间变量,完成对两个 int 型变量值的交换。
void swap(int *x, int *y)
{
int t;
t = *x;
*x = *y;
*y = t;
}
int main()
{
int x = 5, y = 4;
swap(&x, &y);
// 调用后,main 函数中 x 变量的值变为 4,y 变量的值变为 5
}
C++ 中引入了引用的概念,相对于指针来说,更易用,也更安全。
动态实例化
除此之外,程序编写时往往会涉及到动态内存分配,即,程序会在运行时,向操作系统动态地申请或归还存放数据所需的内存。当程序通过调用操作系统接口申请内存时,操作系统将返回程序所申请空间的地址。要使用这块空间,我们需要将这块空间的地址存储在指针变量中。
在 C++ 中,我们使用 new 运算符来获取一块内存,使用 delete 运算符释放某指针所指向的空间。
int* p = new int(100);
/* ... */
delete p;
上面的语句使用 new 运算符向操作系统申请了一块 int 大小的空间,将其中的值初始化为 100,并声明了一个 int 型的指针 p 指向这块空间。
同理,也可以使用 new 开辟新的对象:
class A
{
int a;
public:
A(int a_) : a(a_) {}
};
int main()
{
A *p = new A(100);
/* ... */
delete p;
}
如上,「new 表达式」将尝试开辟一块对应大小的空间,并尝试在这块空间上构造这一对象,并返回这一空间的地址。
struct TwoInt
{
int a;
int b;
};
int main()
{
TwoInt *p = new TwoInt{3, 2};
/* ... */
delete p;
}
{} 运算符可以用来初始化没有构造函数的结构。除此之外,使用 {} 运算符可以使得变量的初始化形式变得统一,详见 列表初始化 (C++11 起) - cppreference。
需要注意,当使用 new 申请的内存不再使用时,需要使用 delete 释放这块空间。不能对一块内存释放两次或以上。而对空指针 nullptr 使用 delete 操作是合法的。
动态创建数组
也可以使用 new[] 运算符创建数组,这时 new[] 运算符会返回数组的首地址,也就是数组第一个元素的地址,我们可以用对应类型的指针存储这个地址。释放时,则需要使用 delete[] 运算符。
int *p = new int[50];
delete[] p;
数组中元素的存储是连续的,即 p + 1 指向的是 p 的后继元素。
二维数组
在存放矩阵形式的数据时,可能会用到「二维数组」这样的数据类型。从语义上来讲,二维数组是一个数组的数组。而计算机内存可以视作一个很长的一维数组。要在计算机内存中存放一个二维数组,便有「连续」与否的说法。
所谓「连续」,即二维数组的任意一行(row)的末尾与下一行的起始,在物理地址上是毗邻的,换言之,整个二维数组可以视作一个一维数组;反之,则二者在物理上不一定相邻。
对于「连续」的二维数组,可以仅使用一个循环,借由一个不断递增的指针即可遍历数组中的所有数据。而对于非连续的二维数组,由于每一行不连续,则需要先取得某一行首的地址,再访问这一行中的元素。
这种按照「行(row)」存储数据的方式,称为行优先存储;相对的,也可以按照列(column)存储数据。由于计算机内存访问的特性,一般来说,访问连续的数据会得到更高的效率。因此,需要按照数据可能的使用方式,选择「行优先」或「列优先」的存储方式。
动态创建二维数组
在 C/C++ 中,我们可以使用类似下面这样的语句声明一个 N 行(row)M 列(column)5的二维数组,其空间在物理上是连续的。
int a[N][M];
这种声明方式要求 N 和 M 为在编译期即可确定的常量表达式。
在 C/C++ 中,数组的第一个元素下标为 0,因此 a[r][c] 这样的式子代表二维数组 a 中第 r + 1 行的第 c + 1 个元素,我们也称这个元素的下标为 (r,c)。
不过,实际使用中,(二维)数组的大小可能不是固定的,需要动态内存分配。
常见的方式是声明一个长度为 N × M 的 一维数组6,并通过下标 r * M + c 访问二维数组中下标为 (r, c) 的元素。
int* a = new int[N * M];
这种方法可以保证二维数组是 连续的。
此外,亦可以根据「数组的数组」这一概念来进行内存的获取与使用。对于一个存放的若干数组的数组,实际上为一个存放的若干数组的首地址的数组,也就是一个存放若干指针变量的数组。
我们需要一个变量来存放这个「数组的数组」的首地址——也就是一个指针的地址。这个变量便是一个「指向指针的指针」,有时也称作「二重指针」,如:
int** a = new int*[5];
接着,我们需要为每一个数组申请空间:
for (int i = 0; i < 5; i++)
{
a[i] = new int[5];
}
至此,我们便完成了内存的获取。而对于这样获得的内存的释放,则需要进行一个逆向的操作:即先释放每一个数组,再释放存储这些数组首地址的数组,如:
for (int i = 0; i < 5; i++)
{
delete[] a[i];
}
delete[] a;
需要注意,这样获得的二维数组,不能保证其空间是连续的。
还有一种方式,需要使用到「指向数组的指针」。
int main()
{
int(*a)[5] = new int[5][5];
int *p = a[2];
a[2][1] = 1;
delete[] a;
}
这种方式获得到的也是连续的内存,但是可以直接使用 a[n] 的形式获得到数组的第 n + 1 行(row)的首地址,因此,使用 a[r][c] 的形式即可访问到下标为 (r, c) 的元素。
由于指向数组的指针也是一种确定的数据类型,因此除数组的第一维外,其他维度的长度均须为一个能在编译器确定的常量。不然,编译器将无法翻译如 a[n] 这样的表达式(a 为指向数组的指针)。
指向函数的指针
关于函数的介绍请参见本文 函数 章节。
简单地说,要调用一个函数,需要知晓该函数的参数类型、个数以及返回值类型,这些也统一称作接口类型。
可以通过函数指针调用函数。有时候,若干个函数的接口类型是相同的,使用函数指针可以根据程序的运行 动态地 选择需要调用的函数。换句话说,可以在不修改一个函数的情况下,仅通过修改向其传入的参数(函数指针),使得该函数的行为发生变化。
假设我们有若干针对 int 类型的二元运算函数,则函数的参数为 2 个 int,返回值亦为 int。下边是一个使用了函数指针的例子:
#include 可以使用 typdef 关键字声明函数指针的类型。
typedef int (*p_bi_int_op)(int, int);
这样我们就可以在之后使用 p_bi_int_op 这种类型,即指向「参数为 2 个 int,返回值亦为 int」的函数的指针。
函数
函数的声明
编程中的函数(function)一般是若干语句的集合。我们也可以将其称作「子过程(subroutine)」。在编程中,如果有一些重复的过程,我们可以将其提取出来,形成一个函数。函数可以接收若干值,这叫做函数的参数。函数也可以返回某个值,这叫做函数的返回值。
声明一个函数,我们需要返回值类型、函数的名称,以及参数列表。
// 返回值类型 int
// 函数的名称 function
// 参数列表 int, int
int function(int, int);
如上图,我们声明了一个名为 function 的函数,它需要接收两个 int 类型的参数,返回值类型也为 int。可以认为,这个函数将会对传入的两个整数进行一些操作,并且返回一个同样类型的结果。
实现函数:编写函数的定义
只有函数的声明(declaration)还不够,他只能让我们在调用时能够得知函数的 接口 类型(即接收什么数据、返回什么数据),但其缺乏具体的内部实现,也就是函数的 定义(definition)。我们可以在 声明之后的其他地方 编写代码 实现(implement)这个函数(也可以在另外的文件中实现,但是需要将分别编译后的文件在链接时一并给出)。
如果函数有返回值,则需要通过 return 语句,将值返回给调用方。函数一旦执行到 return 语句,则直接结束当前函数,不再执行后续的语句。
int function(int, int); // 声明
/* some other code here... */
int function(int x, int y)
{ // 定义
int result = 5 * x + y;
return result;
result = 4; // 这条语句不会被执行
}
在定义时,我们给函数的参数列表的变量起了名字。这样,我们便可以在函数定义中使用这些变量了。
如果是同一个文件中,我们也可以直接将 声明和定义合并在一起,换句话说,也就是在声明时就完成定义。
int function(int x, int y) { return 5 * x + y; }
如果函数不需要有返回值,则将函数的返回值类型标为 void;如果函数不需要参数,则可以将参数列表置空。同样,无返回值的函数执行到 return; 语句也会结束执行。
void say_happy()
{
cout << "happy!\n";
cout << "happy!\n";
cout << "happy!\n";
return;
cout << "happy!\n"; // 这条语句不会被执行
}
函数的调用
和变量一样,函数需要先被声明,才能使用。使用函数的行为,叫做「调用(call)」。我们可以在任何函数内部调用其他函数,包括这个函数自身。函数调用自身的行为,称为 递归(recursion)。
在大多数语言中,调用函数的写法,是 函数名称加上一对括号 (),如 f()。如果函数需要参数,则我们将其需要的参数按顺序填写在括号中,以逗号间隔,如 f(1, 2)。函数的调用也是一个表达式,函数的返回值 就是 表达式的值。
函数声明时候写出的参数,可以理解为在函数 当前次调用的内部 可以使用的变量,这些变量的值由调用处传入的值初始化。看下面这个例子:
void f(int, int);
/* ... */
void f(int x, int y)
{
x = x * 2;
y = y + 3;
}
/* ... */
a = 1;
b = 1;
// 调用前:a = 1, b = 1
f(a, b); // 调用 f
// 调用后:a = 1, b = 1
在上面的例子中,f(a, b) 是一次对 f 的调用。调用时,f 中的 x 和 y 变量,分别由调用处 a 和 b 的值初始化。因此,在 f 中对变量 x 和 y 的修改,并不会影响到调用处的变量的值。
如果我们需要在函数(子过程)中修改变量的值,则需要采用「传引用」的方式。
void f(int &x, int &y)
{
x = x * 2;
y = y + 3;
}
/* ... */
a = 2;
b = 2;
// 调用前:a = 2, b = 2
f(a, b); // 调用 f
// 调用后:a = 4, b = 5
上述代码中,我们看到函数参数列表中的「int」后面添加了一个「&(and 符号)」,这表示对于 int 类型的 引用(reference)。在调用 f 时,调用处 a 和 b 变量分别初始化了 f 中两个对 int 类型的引用 x 和 y。在 f 中的 x 和 y,可以理解为调用处 a 和 b 变量的「别名」,即 f 中对 x 和 y 的操作,就是对调用处 a 和 b 的操作。
main 函数
特别的,每个 C/C++ 程序都需要有一个名为 main 的函数。任何程序都将从 main 函数开始运行。
main函数也可以有参数,通过main函数的参数,我们可以获得外界传给这个程序的指令(也就是「命令行参数」),以便做出不同的反应。
下面是一段调用了函数(子过程)的代码:
#include 文件操作
文件的概念
文件是根据特定的目的而收集在一起的有关数据的集合。C/C++ 把每一个文件都看成是一个有序的字节流,每个文件都是以 文件结束标志(EOF)结束,如果要操作某个文件,程序应该首先打开该文件,每当一个文件被打开后(请记得关闭打开的文件),该文件就和一个流关联起来,这里的流实际上是一个字节序列。
C/C++ 将文件分为文本文件和二进制文件。文本文件就是简单的文本文件(重点),另外二进制文件就是特殊格式的文件或者可执行代码文件等。
文件的操作步骤
- 打开文件,将文件指针指向文件,决定打开文件类型;
- 对文件进行读、写操作(比赛中主要用到的操作,其他一些操作暂时不写);
- 在使用完文件后,关闭文件。
freopen 函数
函数简介
函数用于将指定输入输出流以指定方式重定向到文件,包含于头文件 stdio.h (cstdio) 中,该函数可以在不改变代码原貌的情况下改变输入输出环境,但使用时应当保证流是可靠的。
函数主要有三种方式:读、写和附加。
函数原型
FILE* freopen(const char* filename, const char* mode, FILE* stream);
参数说明
filename: 要打开的文件名mode: 文件打开的模式,表示文件访问的权限stream: 文件指针,通常使用标准文件流 (stdin/stdout) 或标准错误输出流 (stderr)- 返回值:文件指针,指向被打开文件
文件打开格式
r:以只读方式打开文件,文件必须存在,只允许读入数据 (常用)r+:以读/写方式打开文件,文件必须存在,允许读/写数据rb:以只读方式打开二进制文件,文件必须存在,只允许读入数据rb+:以读/写方式打开二进制文件,文件必须存在,允许读/写数据rt+:以读/写方式打开文本文件,允许读/写数据w:以只写方式打开文件,文件不存在会新建文件,否则清空内容,只允许写入数据 (常用)w+:以读/写方式打开文件,文件不存在将新建文件,否则清空内容,允许读/写数据wb:以只写方式打开二进制文件,文件不存在将会新建文件,否则清空内容,只允许写入数据wb+:以读/写方式打开二进制文件,文件不存在将新建文件,否则清空内容,允许读/写数据a:以只写方式打开文件,文件不存在将新建文件,写入数据将被附加在文件末尾(保留 EOF 符)a+:以读/写方式打开文件,文件不存在将新建文件,写入数据将被附加在文件末尾(不保留 EOF 符)at+:以读/写方式打开文本文件,写入数据将被附加在文件末尾ab+:以读/写方式打开二进制文件,写入数据将被附加在文件末尾
使用方法
读入文件内容:
freopen("data.in", "r", stdin);
// data.in 就是读取的文件名,要和可执行文件放在同一目录下
输出文件内容:
freopen("data.out", "w", stdout);
// data.out 就是输出文件的文件名,和可执行文件在同一目录下
关闭标准输入/输出流:
fclose(stdin);
fclose(stdout);
注:printf / scanf / cin / cout 等函数默认使用 stdin / stdout,将 stdin / stdout 重定向后,这些函数将输入/输出到被定向的文件。
模板
#include fopen 函数(选读)
函数大致与 freopen 相同,函数将打开指定文件并返回打开文件的指针。程序设计中不常用到。
函数原型
FILE* fopen(const char* path, const char* mode)
各项参数含义同 freopen。
可用读写函数(基本)
fread/fwritefgetc/fputcfscanf/fprintffgets/fputs
使用方式
FILE *in, *out; // 定义文件指针
in = fopen("data.in", "r");
out = fopen("data.out", "w");
/*
do what you want to do
*/
fclose(stdin);
fclose(stdout);
C++ 的 ifstream / ofstream 文件输入输出流
使用方法
读入文件内容:
ifstream fin("data.in");
// data.in 就是读取文件的相对位置或绝对位置
输出到文件:
ofstream fout("data.out");
// data.out 就是输出文件的相对位置或绝对位置
关闭标准输入/输出流
fin.close();
fout.close();
模板
#include 参考资料
- OI Wiki: https://oi-wiki.org/
- C++ Reference: https://zh.cppreference.com/
复合类型包括数组类型、引用类型、指针类型、类类型、函数类型等。由于本文是面向初学者的,故不在本文做具体介绍。具体请参阅 类型 - cppreference.com ↩︎
详见 值类别 - cppreference。 ↩︎
不包含宽字符类型、位域和枚举类型,详见 整型转换 - cppreference。 ↩︎
定义一个变量时,除了类型说明符之外,还可以包含其他说明符。详见 声明 - cppreference。 ↩︎
更通用的方式是使用第 n 维(dimension)的说法。对于「行优先」的存储形式,数组的第一维长度为 N,第二维长度为 M。 ↩︎
实际上,数据在内存中都可以视作线性存放的,因此在一定的规则下,通过动态开辟一维数组的空间,即可在其上存储 n 维的数组。 ↩︎