kafka实战
流式计算就相当于扶梯,是可以源源不断的产生数据,源源不断的接收数据,没有边界。
流是Kafka Stream提出的最重要的抽象概念:它表示一个无限的,不断更新的数据集。流是一个有序的,可重放(反复的使用),不可变的容错序列,数据记录的格式是键值对(key-value)。
RabbitMQ消费完毕立马删除 kafka支持消息回溯。
如sf做生产压测记录kafka当前offset,然后重置offset到N天前,准备压测数据,压测完后再回复到当前offset
1.kafka常见命令
官网 https://kafka.apache.org/quickstart
(1)启动zooper
zookeeper-server-start.bat ./config/zookeeper.properties
(2)启动服务
kafka-server-start.sh ./config/server.properties
(3)创建主题
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic zsx
(4)创建生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic zsx
(5)创建消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
(6)查看主题信息
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic accountA
(7)主题上添加分区,分区只能添加,不能减少
./kafka-topics.sh --zookeeper localhost:2181 --alter --topic accountA --partitions
(8)查看组情况
./kafka-consumer-groups.sh --bootstrap-server 192.168.119.130:9092 --list
(9)查看组消费,见下图
./kafka-consumer-groups.sh --bootstrap-server 192.168.119.130:9092 --describe --group group
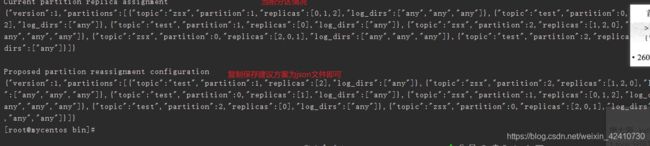
(10)添加副本
./kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file replica.json --execute
kafka自动生成建议的分配方案,见下一条,手写json文件格式如下:
{
"version": 1,
"partitions": [
{
"topic": "topic_20200805",
"partition": 0,
"replicas": [
0,1,2
]
},
{
"topic": "topic_20200805",
"partition": 1,
"replicas": [
0,1,2
]
}
]
}
参考官网:
https://kafka.apache.org/21/documentation.html#basic_ops_increase_replication_factor
(11)优雅停机
.kafka在后台运行时 正确的关闭方式:
.bin/kafka-server-stop.sh --命令会使得整个上所有的kafka实例都停止运行
(12)删除topic,需要设置broker的delete.topic.enable为true,高版本1.0以上都是默认为true的,另外删除topic是异步开启了线程操作,返回不代表已经完全删除
./kafka-topics.sh --delete --zookeeper localhost:2181 --topic zsx
(13)改变主题的属性,分区等
./kafka-topics.sh --alter --zookeeper localhost:2181 --partitions 4 --topic zsx
(14)kafka有broker改动时,添加新副本进行分区重平衡自动生成分区分配方案
将需要重平衡的主题保存成json文件
{"topics":[{"topic": "test"},{"topic": "zsx"}],"version":1}
开始生成分配方案:
./kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file move.json --broker-list '0,1,2' --generate 见下图结果
2.kafka安装在linux上后在windows上怎么连都连不上,一定一定要看看防火墙iptables和firewall的策略,是不是不允许某些端口进来
参考:https://blog.csdn.net/qq_38025219/article/details/103048793
3.kakfa搭建集群
kafka集群是一种主备集群,所有的数据都会首先在leader机器上,由leader统一对外读写,与redis的无主集群不同
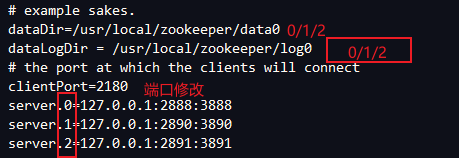
(1)搭建zookeeper集群:
i.修改zoo.cfg,复制zoo.cfg3个,修改dataDir和dataLogDir 以及clientPort 要不一样,然后在dataDir下分别写myid 里面记录0.1.2
参考:https://blog.csdn.net/vbirdbest/article/details/82688462
分别启动三个实例
../bin/zkServer.sh start ./zoo0.cfg
../bin/zkServer.sh start ./zoo1.cfg
../bin/zkServer.sh start ./zoo2.cfg
然后查看状态
../bin/zkServer.sh status ./zoo0.cfg
ii 搭kafka集群
修改kafka的配置server.properites
zk配置:zookeeper.connect=127.0.0.1:2180,127.0.0.1:2181,127.0.0.1:2182/kafka
zk提前分配给kafka一个路径
日志:log.dirs=/usr/local/kafka/kafka_u/kafka_logs/log1
复制三个server.properties命名为server1.priperties /server0.priperties/server2.priperties,
将其中的日志配置路径改为不同,然后启动三个实例
./kafka-server-start.sh ../config/server0.properties
./kafka-server-start.sh ../config/server2.properties
./kafka-server-start.sh ../config/server1.properties
第一章 简介
1.消息引擎系统
(1)消息设计 一般都是结构化语言 JSON、XML、二进制等,kafka采用的是二进制结构化消息
(2)传输协议,Kafka自己有一套二进制传输协议
(3)消息引擎泛型常见的就是消息队列模型和发布/订阅模型
消息队列可用于进程/线程间通信,是一种p2p消息传递方式,每个消息只能由一个生产者产生,被一个消费者消费,一旦被消费就会被移除;
发布订阅有主题的概念,所有订阅了该主题的消费者都可以接收到topic下的所有消息
kafka既支持消息队列也支持发布订阅
(4)java消息服务 JMS,提供了一套API规范用于实现分布式系统的消息传递
2.kafka设计概要
(1)kafka实现高吞吐,低延时的做法:
i.kafka的消息消费机制使用的是零拷贝技术,读取效率很高
kafka的零拷贝用的sendfile,kafka本身不需要对数据做任何修改和加工,因此没有必要在内核和用户空间多一次拷贝
拷贝不经过用户空间,直接由内核读pagecache并交给socket
ii.大量使用OS页缓存,将大部分数据缓存在内存中,操作速度快,缓存命中率高
iii.不直接参与物理IO,而是通过OS完成
iv.操作物理磁盘时,采用追加写方式,顺序读写磁盘,效率比随机读写效率高
(2)kafka消息是要持久化的
解耦消息生产和消费,灵活的消息处理,如已经消费的消息再次消费
(3)kafka的伸缩性,即能够方便的扩容,kafka集群服务器的状态是保存在zookeeper上的,扩容的话只需要简单启动一台新的服务器 即可
3.基本概念和术语
(1)消息
i.包括消息头部和key以及value,如图:
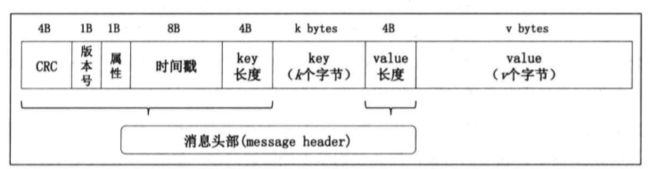
key消息键,决定消息被保存在某个topic下的partition;value:实际保存的消息数据;timestamp; CRC是一种冗余校验码,用于检验消息是否与存入的相同
ii.消息使用了紧凑的字节数组节省空间,消息保存在页缓存上,即便是broker进程崩溃了。页缓存的数据还在,重启后不用再次缓存
(2)topic和partition的关系
topic-partion-message 三级结构分散负载,如官网图:

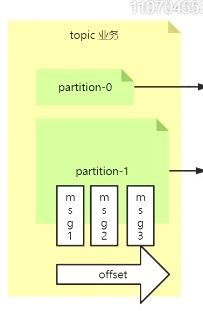
topic 可以表示一类消息,根据业务进行区分设置
partition一般从0开始有唯一专属的partition号,每个partition下每个消息也分配一个唯一序列号,从0开始递增,被称为offset位移
(3)offset位移
生产者的位移是固定的,消费者的位移能够随消费的进度不断前移
对于一条消息的定位可以用
(4)replica(副本)增加冗余备份多份日志,防止数据丢失
领导者副本负责响应客户端请求,追随者副本只能被动从领导者副本获取数据,用于备份
(5)Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题.,leader处理一切对partition的读写请求,每个分区在leader上都会存在,然后根据topic副本数,再备份到不同机器中,follower只能被动同步leader上的数据,leader如果挂了,follower会重新选主(通过zk),同一个分区的副本一定不会分配在同一个broker上,否则无法实现备份冗余的效果了,如图示意,副本本身包括leader,即副本数=3,则一共(包括leader)有3台保存该分区
(6)leader的选举
各客户端通过/kafka下创建leader节点,如/kafka/leader,来竞争leader节点,并且这个节点应该设置成ephemeral。
若创建leader节点成功,则该客户端成功竞选为leader若创建leader节点失败,则竞选leader失败。

在分区的维度上 互为follower和leader
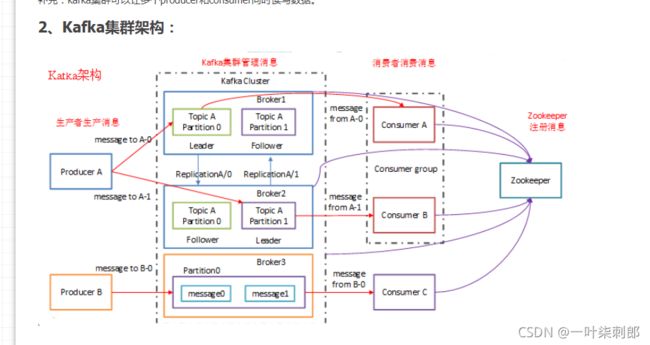
(6)ISR in-sync replica 对于副本维护的一个数组,只有在ISR中的副本才有机会被选举为leader
ISR 创建副本的单位是topic的分区,每个分区有1个leader和0到多个follower,也就是说每个分区都有leader+follower
4.kafka的参数设置
broker端参数 topic级别参数 JVM参数 OS参数
(1)broker端参数
broker.id 默认是-1 必须保证集群中该值唯一,一般从0开始
log.dirs 指定持久化消息的目录,可设置多个目录,一般推荐设置多个目录,kakfa会将日志负载均匀到多个目录下,提高吞吐能力,
如果不设置的话默认是/temp/kafka-logs
eg: log.dirs=/usr/local/kafka/kafka_u/kafka_logs,/kakfka_logs2
listeners 是broker监听的CSV列表,可以认为是broker开放给clients的监听端口,新版本的kafka有了listeners后不再需要配置port和hostname;目前支持的协议包括:PLAINTEXT,SSL等
eg:listeners=PLAINTEXT://192.168.43.152:9092
delete.topic.ennable 是否允许kafka删除topic ,默认是true,即允许,因为这样的操作会很方便
log.retention.{hours|minutes|ms} 控制消息数据保留的时间,同时设置的话 优先级为ms、minute、hours,默认7天
log.retention.bytes,设置了分区日志的最大保留字节数,即在设置保留的空间策略,默认是-1,表示不根据日志大小删除日志
min.insync.replicas 只有producer端设置acks=-1才生效,这个指定了某个leader broker成功响应客户端所发送的最少副本数,
eg: min.insync.replicas=2,当topic的分区副本为3个时,允许有一个broker宕机,即这个参数设置了高可用和一致性的平衡
num.network.threads 设置负责接收和响应网络中(如其他broker和clients等)的请求的线程数,这里的线程接收到请求后会转给后面的处理线程,默认的配置是3
num.io.threads 控制broker端实际处理网络请求的线程数,默认是8.message.max.bytes是broker能够接受的最大消息大小,默认不到1MB,实际中一般都需要调整
offsets.retention.minutes --默认10080,新版本下消费组会自动清理,当组内所有的consumer客户端退出时,消费组会在最后一个位移提交的时间上再加上该参数时间来临时自动清除,若组内有活跃成员,则消费组不允许手动或自动删除
num.replica.fetchers follower副本同步leader分区数据发fecth请求的线程数,适当的该值能够提高broker之间同步的效率 默认是1,特别是当producer端的ack=all时,这个值就很重要了
9).其他参数设置见官网:http://kafka.apache.org/documentation/#brokerconfigs
(2)topic级别的参数,即上面broker级别的参数设置是全局的,每个topic可以设置自己不同的只针对自己有效的参数
第4章 producer的开发
1.producer端指定key的话能够分区器会根据key的hash值选择目标分区,这样同一个key的消息会被路由到相同分区中,如果不指定key则会轮询分区
2.producer端原理:用户启动一个用户线程将待发送的消息封装成一个ProducerRecord实例,然后进行序列化,再发送给分区器,然后分区器选定目标分区后会放入一块缓存中,随后会有负责发送的sender线程实时的将消息封装成一个批次batch,然后发送给broker,见图
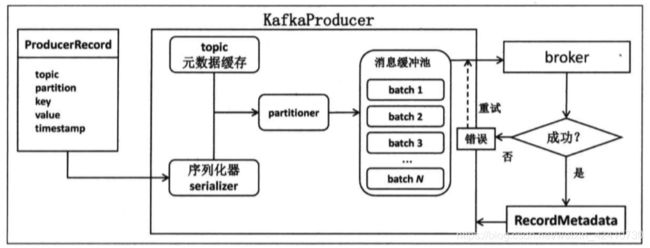
发送端的缓存
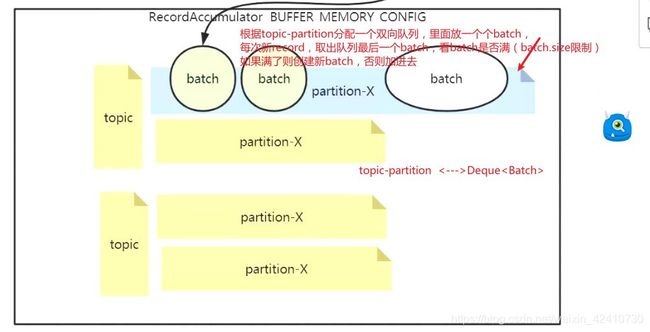
分区顺序在发送端的保证:
发送时从deque的队头拿batch发送,添加则是在队尾添加,保证顺序
kafka中也使用了Selector(epoll) 每个producer都维护了一个java.Nio.Selector
3.producer开发详解
(1)配置properties属性实例;(2)构造KakfaProducer类
(3)构造producerRecord对象;(4)发送消息;发送有三种方式,见下面代码,所有重试都有可能失败,失败的异常分为可重试异常和不可重试异常,发生可重试异常时,只要配置了重试次数就会重试,异常继承RetriableException,如networkException,如果重试还是没有成功,则会返回异常给send方法
(5)一定要关闭producer,调用close方法是优雅的退出
(6)发送方官方配置
http://kafka.apache.org/documentation/#producerconfigs
(7)producer端开发示例
1.构造properties
/**
* 生产端的属性封装
*/
public static Properties getProducerProperties(){
//属性
Properties props = new Properties();
/**
* 参数说明: props.put("bootstrap.servers", "192.168.43.152:9092,192.168.43.152:9093");
* 该参数指定连接的broker,如果集群中broker很多的话,只需要指定部分即可,指定多个的原因是因为怕其中一个挂了之后
* producer客户端还能通过其他的ip:port找到集群
* 必输
*/
props.put("bootstrap.servers", "192.168.43.152:9092");
props.put("retries", 0);
props.put("batch.size", 16384);
/**
* 参数是为消息做序列化用的,任何消息都必须是字节数组才能发送到broker上,
* 将一个String字符串转成字节数组
* 必输
*/
props.put("key.serializer", StringSerializer.class.getName());
/**
* 必输
*/
props.put("value.serializer", StringSerializer.class.getName());
return props;
}
//2.构造producer对象
Producer kafkaProducer = KafkaUtils.getKafkaProducer();
//3.构造producerRecord对象
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC, accountAjson);
/**
* 发送的三种方式:
* 1.直接调用send方法,无法获知发送成功与否,不被推荐
*
*/
// kafkaProducer.send(record);
/**
* 2.异步发送,通过回调函数实现onCompetion方法,
* 其中recordMetadata和exception只有一个为空,成功时后者为空,失败时前者为空
*/
kafkaProducer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//成功
if(recordMetadata!=null){
//处理成功
System.out.println("成功:"+recordMetadata.toString());
}else{
if(e instanceof RetriableException){
//可重试异常处理
}else{
//不可重试异常处理
}
//这里是失败
System.out.println("失败");
}
}
});
/**
* 第三种方式,同步调用,使用future的get无参方法,一直等待直到有返回结果,
* 要么是exception,要么是RecordMeta
*
*/
try {
kafkaProducer.send(record).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("发送一个---");
kafkaProducer.close();
}
(8)producer端的参数设置
ack——表示生产者在返回成功前要保证写入的副本数,控制这消息的持久性
0:表示完全不理睬leader broker的处理结果,一条发送后直接发送下一条,send方法的回调也没有任何作用,响应快,吞吐高
1:默认值,即发送完消息后会等待leader broker仅将消息保存在本地日志就返回 ,属于all和0的折中
-1/all:集群中必须所有ISR中的副本都保存消息后才返回成功,吞吐低,但是持久性更好
ps:kafka只保证已经成功保存的消息不会丢失,而对那些没有成功保存的消息不保证持久性
buffer.memory ——指定了producer端用于缓存消息的缓存区大小的设置,默认是32mb,单位是字节,缓存区作用见producer端发送的原理,buffer中的消息由专门的另外的线程从其中拿走发送,该参数指定该缓存区大小,如果太小的话往缓存区写的速度大于发送的速度,就会z阻塞,阻塞max.block.ms时长,如果还写不进去就会抛异常TimeOutException
compression.type——设置producer端消息是否压缩,压缩后能显著降低网络IO,但是producer端CPU会有额外开销,值有四种:none(默认不压缩)、GZIP、Snappy、LZ4;如果broker端写入时的压缩参数与producer不同,就会对消息进行解压重压缩过程,要注意。
retries——重试次数,为了方式因为瞬时可重试后恢复的异常导致的消息丢失,一般都会设置重试测试,默认是0。
batch.size——producer会将多条消息先放进一个个batch(双端队列中的batch)中,等到batch慢了或者延迟时间到了就发送,太小的batch会导致一次性发送的消息少,降低吞吐量,太大的话消耗内存,因为不管能够填满,producer都会给batch分配那么大的内存,默认16KB,单位是字节。
linger.ms——控制消息发送的延时,即延时到了不管batch是否满都发送,默认是0;一般可以设置几毫秒的延迟,来使得消息尽量积攒一定的数量,然后一次性发送,从而能有效增加吞吐量(每秒的发送量),当一条消息大于batch.size时直接发送
max.request.size——控制发送的消息大小,包含消息头
request.timeout.ms——当请求发送给broker后,需要broker在一段时间内返回处理结果,默认30s,如果30s内没给出响应,则producer会认为请求超时,然后抛出超时异常
4.消息序列化
(1)默认序列化
i.kakfa支持给broker 发送任意类型的消息如字符串、数组、或者其他任务类型,
producerRecord构造函数的value是V,即任何类型
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}
ii.kafka默认提供了很多序列化器,用来序列化对应的类型,如果value不是序列化器对应的类型则无法序列化,对于实体类可以转为json然后指定String类型的序列器,或者自定义一个序列器,需要使用第三方jar包

6.无消息丢失配置
(1)解决的问题:异步发送时,send方法将消息丢进缓存区后,如果专属IO线程发送前producer端挂掉,那缓存中的消息就会丢失; 重试机制有可能导致消息变的无序
(2)具体配置:
producer端:
max.block.ms——该配置控制将阻塞的时间KafkaProducer.send()和KafkaProducer.partitionsFor()长度。由于缓冲区已满或元数据不可用,可以阻塞这些方法。在用户提供的序列化程序或分区程序中的阻塞将不计入此超时;或者0.9版本以前配置为block.on.buffer.full=true——配置当内存缓冲区填满时,producer处于阻塞状态并停止接受新消息而非抛出异常
acks=all
retries=Integer.MAX_VALUE无限重试,kafka只会重试那些可重试异常
max.in.flight.requests.per.connection=1防止乱序问题,限制了producer在未收到响应时能够发送的未响应请求的数量,该参数设置1,即在某个broker发送响应前producer将无法再发送新的请求
使用带回调函数的send方法
broker端配置:
unclean.leader.election.enable=false,不允许非ISR中的副本被选举为leader
replication.factor>=3 这个是配置一份消息使用多个副本来保存
min.insync.replicas>1——控制某条消息至少被写入多少个副本才算成功,producer端ack=all/-11才有意义
7.消息压缩
producer端可以配置消息压缩的类型,一般来说producer端压缩,broker保存,consumer端解压缩;压缩虽然减少网络IO资源,但是会对CPU消耗大一些,因此要衡量生产环境,如果cpu资源不紧张则可以考虑压缩,否则不压缩
第五章 consumer开发
consumer分为消费者组和单个消费者
1.消费者组(consumer group)
(1)kafka就是通过consumer group实现对队列和发布订阅两种引擎的支持;一个consumer group可以有多个consumer,一个topic消息也会被发送到多个group中;但是组内一个消息只能被发送到其中的一个consumer实例上
(2)队列模型和发布订阅模型的区分:
所有consumer实例都属于相同group——实现队列模型;每条消息组内只能被一个consumer处理
所有实例都属于不同的group,即一个实例一个组——实现发布订阅模型,所有消息都会被广播到consumer实例上
eg:
消费者1:
./kafka-console-consumer.sh --bootstrap-server 192.168.43.152:9092 --topic accountA --group accountA --from-beginning
消费者2:
./kafka-console-consumer.sh --bootstrap-server 192.168.43.152:9092 --topic accountA --group accountA --from-beginning
topic下有两个分区,kafka能够保证消费组里的消费者对分区是公平消费的,结果为:
发送方没有设置key,两个分区轮询存储消息,消费的时候一个客户端对应一个分区进行公平消费

(3)consumer group的作用是实现高伸缩性和高容错性,组内多个consumer,一旦一个consumer挂掉了,会立即将其负责的分区交给其他consumer负责,保证全组还能正常工作,即重平衡
(4)kafka可以保证消费组内的消费者公平的消费分区中的消息,这种公平是对整个集群而言的如图:
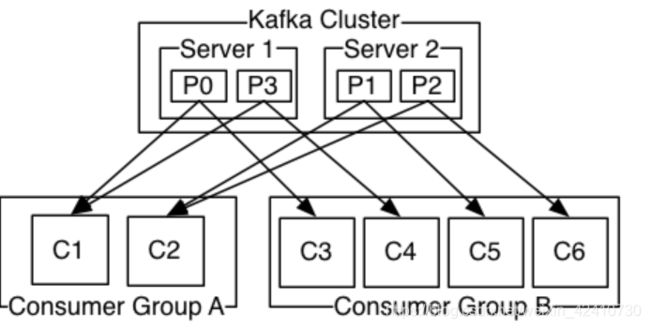
ps:kafka目前只提供单个分区内的消息顺序,对于全局的消息顺序不做保证,如果要实现全局的顺序消费,那一个topic只搞一个分区即可,这样的话一个消费组也只需要一个客户端
(5)group.id 唯一标示一个consumer group
2.位移 offset
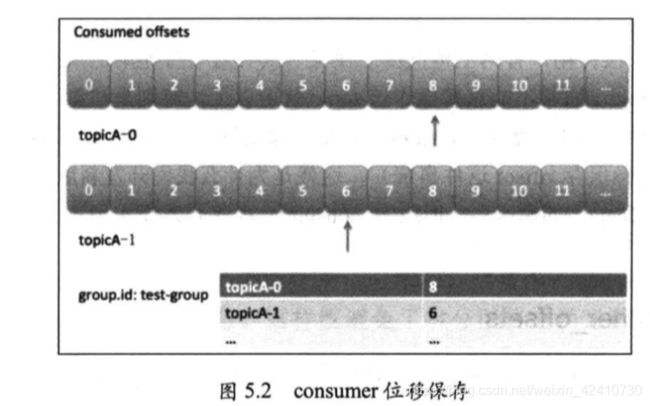
(1)每个consumer实例都为其消费的分区维护一个属于自己的位置信息记录当前消费了多少条消息,即位移
(2)consumer在内部使用一个map来保存其消费的分区的offset,类似:put(“topicA-0”,8)这样,如图
3 位移提交
consumer客户单定期向集群汇报自己消费的进度,保存在服务端;旧版本保存在zookeeper下的节点;新版本则直接将位移提交到一个内部topic,命名为(_consumer_offsets),在kafka的消息日志下就能看到,不能随便动,如图:

位移提交的请求会往_consumer_offsets下追加一条消息,消息的key就是所消费的groupid、topic和分区,value就是消费的位移,见上面的图,只有最新提交的位移是有效的数据,之前的其实都已过期
4.构建消费者consumer
(1)构造properties对象(2)构造kafkaConsumer对象(3)订阅topic列表(4)调用poll方法从topic中拿数据
(5)处理consumerRecord对象,即处理业务逻辑,如果逻辑复杂,可以放其他线程中处理,主线程只负责消费数据
/**
* 第一步,消费端的属性
* @return
*/
public static Properties getConsumerProperties(){
//属性
Properties props = new Properties();
/**
* 连接broker用,同producer端配置,不用连太多broker,只需要连接其中几个,
* 使得某个broker挂掉后仍能连上集群,必输
*/
props.put("bootstrap.servers", "192.168.43.152:9092");
/**
* 消费组名称必输,一般指定一个有业务含义的名称
*/
props.put("group.id", "group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("max.poll.records", 1000);
props.put("auto.offset.reset", "earliest");
/**
* 解序列化,使用的类要与producer端使用的相对应,必输
*/
props.put("key.deserializer", StringDeserializer.class.getName());
//同上 必输
props.put("value.deserializer", StringDeserializer.class.getName());
return props;
}
public void consumerAccountA() throws Exception{
/**
* 第二步获取一个kafkaconsumer
*/
Consumer<String,String> kafkaConsumer = KafkaUtils.getKafkaConsumer();
/**
* 第三步订阅topic,订阅不是增量的,如果订阅两次,后面会覆盖前面
* kafkaConsumer.subscribe("t1","t2");
* kafkaConsumer.subscribe("t3","t4"); 最终订阅的是t3和t4
*/
kafkaConsumer.subscribe(Arrays.asList(TOPIC)); //subscribe方法接受的是一個Topic列表作為參數,所以需要先創建一個主題列表。方法的參數也可以使用正則表達式匹配多個主題,比如傳入"mytopic.*"進行匹配。
try {
while(true){
/**
* 第四步调用poll方法,从topic中拿数据,得设置超时时间,一般设置的较大,除非有特别需求
*/
//必须使用Duration这个参数接口,不能使用弃用接口,否则无法获得生产的数据
ConsumerRecords<String,String> consumerRecord = kafkaConsumer.poll(Duration.ofSeconds(1));
System.out.println("数量====="+consumerRecord.count());
/**
* 第五步,处理consumerRecord对象,如果处理的逻辑
*/
for (ConsumerRecord<String, String> record : consumerRecord) {
System.out.println(record.key()+record.value());
}
}
} finally {
/**
* 关闭socket,线程等资源,如果是单例的话应该不用关闭
*/
kafkaConsumer.close();
}
(6)springboot中consumer的使用
@Component
public class SbmStoreConsumer {
@Autowired
BasicDataTableService basicDataTableService;
这里可以监听多个topics
@KafkaListener(topics={"SSCT.MASTER_DATA.SSCT_STORE"})
public void receiveSBM_STORE(String message ){
soutmessaged打印
}
}
配置:springboot中kafka的消费端配置,表示对于每一个@KafkaListener而言,构造的kafkaconsumer客户端的数量,如设置5,则表示线程池大小为5,5个线程里每个线程都维护一个kafkaconsumer,
5个客户端的配置包括group都一样,对于每个kafkaconsumer而言还是单线程运作的,如果有两个@KafkaListener,则会开5*2=10个消费者客户端
spring:
kafka:
listener:
concurrency: 5 这个值应该与所监听的topic的partition数量一样,如果小于partions,会有消费端负载不均衡,如果>partitions,则会有consumer没有分配到分区,造成浪费
consumer:
enable-auto-commit: false
group-id: SBM
auto-offset-reset: earliest
bootstrap-servers:ip1:9092,ip2:9092,ip3:9092
5.consumer客户端的参数
注意 消费端到broker是主动拉取,以下的参数多是调节拉取过程
session.timeout.ms——consumer coordinator检验消费组内成员崩溃或者宕机的间隔时间,
consumer客户端周期性向broker发送心跳,证明自己存活,如果超过该参数设置的时间broker还没收到,则认为consumer 宕掉了
,就会rebalance,该参数应该在broker的group.min.session.timeout.ms 和group.max.session.timeout.ms之间默认10s
max,poll.interval.ms——在分区里有消息的情况下,consumer客户端两次poll之间的最大时间间隔,
即消息处理的最大时间间隔,如果消息处理的逻辑比较复杂,则改时间可以设置大点,
默认300s,超过了该参数,就会rebalance,分区中后续消息就会全部发送到同组内其他的consumer
auto.offset.reset——指定无位移信息或者位移不在合理范围内时kafka的应对策略,满足以上两条件之一时参数才有效果,
位移的提交是一个组针对分区的提交,不管组内怎么rebalace,只要组内对分区提交过,那下次开始时就会从提交的位移开始消费
auto-offset-reset配置成earliest和latest只会对新的起效果,因为新分组是没有提交过任何offset的,一旦第一次组新建后,就会根据配置将offset设置为0或者对应的新的位移
正常情况下consumer会提交自己目前消费到的位移信息,因此会无视该参数,
比如第一次消费时就是会使用该参数
取值:earliest:从最早的位移开始消费,最早不一定是0; lates:最近处位移消费;none:抛异常,几乎不用
enable.auto.commit——设置consumer的位移是否自动提交,默认true
fetch.max.bytes——指定了consumer单次能够获取的数据的最大字节,消息大于该参数无法消费,官网指定至少1024b
max.poll.records——指定一次poll方法调用返回的最大消息记录数,也就是说调用一次poll不是只消费一条消息的,
而是由这个参数指定的,consumer能够根据消费速度调整每次拉取的数量,同时防止内存溢出
heartbeat.interval.ms——当发生rebalance时,当前的consumer多久能够知道需要重新加入组,显然越小越好
connections.max.idle,ms——空闲socket连接关闭的超时时间,即超过该参数时连接没被使用就会被close,默认9分钟,如果不在乎socket开销,则可设置为-1,永不关闭
位移的提交是一个组针对分区的提交,不管组内怎么rebalace,只要组内对分区提交过,那下次开始时就会从提交的位移开始消费,一旦第一次组新建后,就会根据配置将offset设置为0或者对应的新的位移
![]()
6.消息订阅的方式
(1)消息订阅不是增量的,连续订阅后面会覆盖前面
eg: kafkaConsumer.subscribe(“t1”,“t2”);
kafkaConsumer.subscribe(“t3”,“t4”); 最终订阅的是t3和t4
(2)基于正则表达式的订阅
kafkaConsumer.subscribe(Pattern.compile(“acco.*”));
7.消息轮询
(1)poll内部原理
consumer采取了类似linux的IO的poll,使用一个线程同时监听多个socket连接,一旦consumer订阅了topic,所有的消费逻辑都会在主方法poll中被一次调用执行;新版kafka是一个双线程的java进程,创建kafkaconsumer的线程为主线程,还有一个心跳线程,消费者的rebalance。消息获取,位移提交等操作都是运行在用户主线程中的
(2**)kafkaConsumer并非线程安全,目前一个实例不能再多线程中使用,会报异常**,除了consumer.wakeup()方法例外,暂未测试
(3)不应该将非常繁重的消息处理逻辑放在poll方法的主线程中
8.位移管理
(1)consumer位移
i.consumer向kafka提交自己的位移信息,该位移信息其实是下一条待消费的消息位置,若已经消费了N条,那提交的位移就是N,由于位移从0开始计数,则N代表第N+1条消息,kafka默认提供的最少消费一次的保证,即消息不会丢失,但可能被处理多次
ii.consumer相关位置信息,如图:
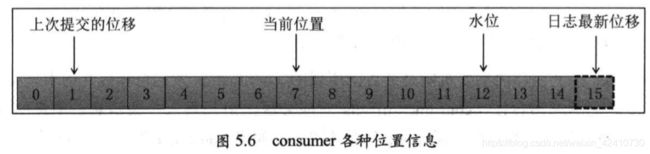
上次提交位移:consumer最近一次提交的offset值
当前位置:consumer已读取但未提交时的位置
水位:属于分区日志的概念,水位之下的消息可读取,之上无法读取
(2)手动提交和自动提交
自动提交降低了用户开发成本,默认情况下会自动提交消息的位移信息,但是有些场景可能要求必须执行完某些业务操作之后,才能提交,防止本次业务操作失败,而消息已经消费完了,提交了下次消费的位移,出现了消息丢失,业务处理失败或者每处理完,就已经提交了自己的位移
ps:经测试,如果自动提交关闭,虽然broker上位移不会变化,但是当前consumer由于本地内存中保存了当前已经消费到的位移,因此已经消费过的就不会再消费,即同一个消费者实例无法消费已经消费过的消息,除非创建新的实例或者同组内其他消费者才能消费
手动提交的方式:
props.put("enable.auto.commit", "false");
Consumer<String,String> kafkaConsumer = KafkaUtils.getKafkaConsumer();
kafkaConsumer.subscribe(Arrays.asList(TOPIC));
for (ConsumerRecord<String, String> record : consumerRecord) {
//这里业务处理成功后,再提交,避免未处理成功的情况下本次消息消费完
bussinessProcess();
kafkaConsumer.commitAsync();
}

9.重平衡
(1)为同一组内消费者分配分区的过程就成为重平衡,kafka的borker会被选为组协调者,当组内成员发生变化时,coordinator就会达成新的分区分配方案
(2) 重平衡的触发条件:
i.组成员发生变化时,即consumer增加或者减少或者down机
ii.订阅的主题数量发生变化时
iii.人为改变了主题分区的数量时,如使用命令行
ps:常见触发是第一种情况某个consumer挂掉了,或者consumer的主线程处理逻辑太重,两次poll之间的时间间隔超过了设置的参数max.poll.interval.ms,就会频发发生rebalance
(3)rebalance一次broker的开销很大,要能够尽量避免
(4)rebalance分区策略
range:将单个topic的分区按照顺序排列,将分区段依次分配给每个consumer;round-robin是每个分区轮训分配,默认是range,可通过partition.assignment.strategy调整
(5)rebalance generation
重平衡代,每次rebalance这个generation就会+1,用于区分每一代,比如rebalance前有consumer延迟提交位移,
那么rebalance后该位移就不能再提交,因为已经隔代了
(6**)kafka在组内重平衡的最小单位是分区,分配某个分区到了consumer后,该分区上的消息都只会被该consumer消费,不可能做到分区上的上一条消息被一个consumer消费,下一条消息又被另一个consumer消费**
10多线程消费的两种模型
(1)每个线程里使用一个consumer实例
(2)全局使用一个consumer实例只负责消费,然后将处理消息的逻辑改成线程池调用,reactor模型

11独立 consumer
不隶属于任何一个组,即便是属性里指定了某个组也无用,可以指定该独立消费者消费某个分区,原本使用的subscribe换成assign
List<PartitionInfo> partitionInfos = kafkaConsumer.partitionsFor(topic);
for (PartitionInfo partitionInfo : partitionInfos) {
//如果分区数是2 则消费
if(partitionInfo.partition()==2){
partitions.add(new TopicPartition(partitionInfo.topic(),partitionInfo.partition()));
};
}
kafkaConsumer.assign(partitions);
一般用于该进程高可用,能够自动重启等机器上,否则还是以组的形式出现的好
第六章 kafka设计原理简介
1.broker端设计
(1)集群管理
i.集群成员管理
kafka将自己注册在zookeeper的一个节点下,路径为(chroot)/brokers/ids/
的get拿到节点信息;看图:
这是获得的broker的信息
![]()
broker向zookeeper注册信息以json保存,信息如下:
listener_security_protocol_map 该broker与外界的通讯协议,plaintext为明文,也可SSL
rack机架,暂不懂, jmx_port :Kafka监控broker的端口 ;host和port,timestamp是broker启动时间,version是broker当前版本号,目前最新是4
kafka通过zookeeper的临时节点管理brokers,临时节点一般与会话绑定,同时又监听器监听该节点状态,broker一启动,监听器就会同步所有broker信息到当前broker,
而该broker一旦崩溃,拿会话信息就会删除,监听器就会触发,处理崩溃后的事
ii.kafka在zookeeper中的节点路径
这是zookeeper下关于kafka的一些节点信息

iii. zookeeper的作用:主要是多个broker协调选主(选controller的过程),另外保存些topic信息等
(2)副本与ISR设计
1).ISR中的副本才有可能被选为leader,只有副本与leader的副本同步后,才会被放到ISR数组中,也就是数据太旧的副本是不能做leader的,leader的副本总是包括的ISR中的,ISR中所有的副本都被写入数据后,producer的一条消息才算已提交
2)ISR实现的leader选举与redis的多数选举不一样,冗余3低,比如容错一台,kafka最低需要两台机器,而需要三台,容错两台则kafka需要三台,redis需要5台
副本及ISR也是针对topic而言的 给每个topic都维护一个副本及,只要ISR中有, 就能够容器能够使用更少的broker去容错
2).follower副本同步
i.follower与leader不同步的原因是有3个:
请求速度跟不上,leader中副本的产生速度大于follower请求的速度
follower进程卡住,follower在相当长一段时间没有向leader请求数据
新创建了副本,集群中新加入broker,新broke在追赶leader的时间内是落后的
ii.0.9版本后使用参数 replica.lag.time.max.ms

默认30000ms,对于以上三种情况均使用这个超时参数,只要不是持续落后,就不从ISR中移除该副本broker,否则会被从ISR移除
(3)高水位水印(HW,木桶的短板)和结束位移LogEndOff(LEO),消费者能消费的是小于等于HW位移的消息(即完全提交和备份成功的消息)
1)每个kafka副本对象都有高水印和末端位移

末端位移LEO 记录副本对象日志文件中下一条位移值,eg:LEO=10则表示该副本上已经保存了10条日志,0-9,下一条从10开始保存,即LEO的位置上其实是没消息的,只是指向下一条消息待写入的位置
HW高水印值<=LEO,小于HW的消息则表示已经备份或者提交,只有所有ISR中的副本都接受到消息时(这个得看producer端的ack设置,如果ack是1的话,那可能只需要leader的副本 了HW就+1),HW才能+1,表示该条消息已全部同步,producer端ack设置为all时,该条消息才算提交成功,而大于HW位置的消息属于未完全备份或者说未提交成功,是无法被消费的
2)leader的LEO和HW的更新与follower机制不同
(4)日志存储
1)日志文件的结构
i**.创建topic时,会在log文件夹里以topic-分区号创建对应子目录**,如图: 有topic是test有三个分区,进去目录就是索引和日志段
2)kafka自己定义了消息格式并序列化成紧凑的二进制字节保存,消息体+必要的封装构成一条record;日志设计以分区为单位;每个日志又分为日志段和日志索引,如图: .log就是日志消息,index结尾的就是 索引
ps:kafka日志索引有两种:timestamp索引和offset索引,前者提供时间检索方式,后者提供按位移检索的方式
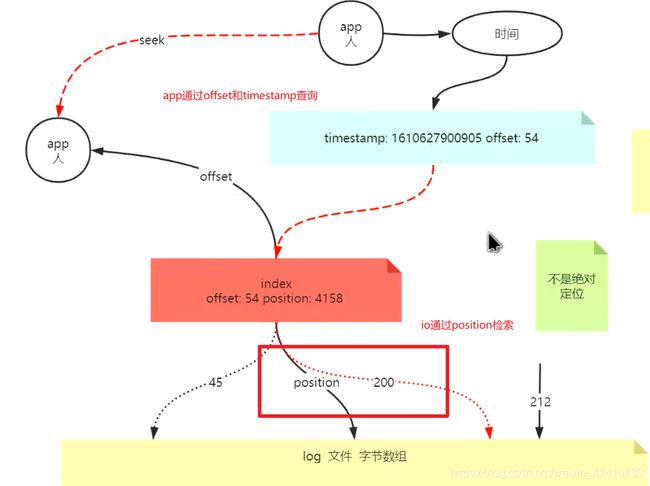
kafka的索引日志:记录 offset—>position实际存储时的字节下标,通过索引加快io检索效率
使用命令查看
/home/appdeploy/redis/kafka/kafka_2.11-1.0.0/bin/kafka-run-class.sh kafka.tools.DumpLogSegments -files ./00000000000000000000.index
indextime
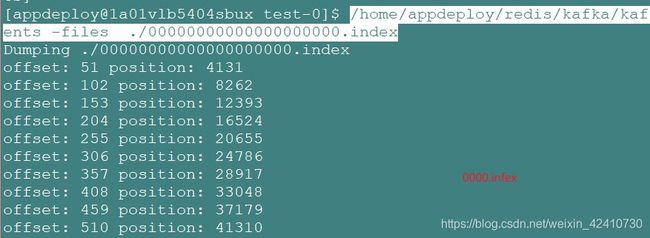
kafka的timeindex日志,记录timesatmp–>offset 对应关系
3).log日志包含了一段位移范围的记录**,该文件使用包含的第一条记录的位移作为名称的**,因此新分区下一定有0.log的日志
4)一段日志被写满后,会再写另一段日志,日志默认1G大小,broker的参数 log.segment.bytes控制,写满的日志就不能再写了,kafka会对日志进行切割归档,当前正在写的就是激活日志段
5)日志留存,kafka会定期以日志段为单位清除日志和对应的两个索引文件,目前提供两种策略
i:基于时间的策略:默认清除7天日志段,即kafka默认保留7天消息,broker端参数配置该时间 log.retention.{hours|minutes|ms} 优先级依次递增,ms最高
ii.基于大小的策略 log.rentention.bytes设置,-1则不受限制
ps:日志清除是异步过程,有单独的线程处理,日志清除对当前日志段不生效,如果日志段最大文件大小设置过大导致无法切割,则kafka永远不会清除日志
(5)通讯协议
1).kafka所有的请求都是TCP的二进制协议
2).kafka客户端与broker通信时,通常只需要在与其连接的broke上维持一个长socket连接传输消息,客户端采用了类似epoll的实现,在一个连接上不断轮训查看broker是否可读或者可写
3).一个broker只有一个socket连接能够 对请求顺序处理,然后返回响应结果,客户端需要自行保证消息的顺序
4).kafka通讯规定中的请求有三种: client-broker,集群中的controller-brokers,follower副本所在的broker leader副本broker进行fetch请求
5).java客户端请求处理流程,消费端也类似

(6)controller设计
1)某个broker会被选举出来 集群的控制器,来协调整个集群
2)controller的职责包括 更新集群元数据,创建删除opic 重新分区,分区扩展,broker加入或崩溃等
3)controller启动时会为每一个broker创建一个专属的socket连接
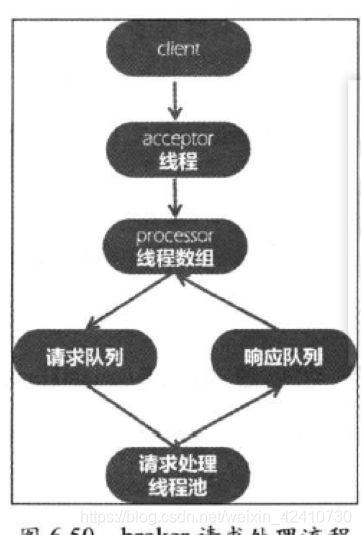
(7)broker请求处理
- reactor模式:使用两个组件acceptor和processor线程,acceptor监听事件,有事件准备好时分发给processor执行并返回给client结果,跟selector的NIO模式类似
2)broker端是典型的多线程 一个acceptor和多个processor,broker的参数num.network.threads控制processor数量,
3)acceptor线程处理逻辑很轻,一般不会成为瓶颈,processor会处理acceptor提交的socket连接事件,processor是线程组,将请求 放入broker全局唯一的请求队列,然后交由requestHandler线程池处理
4)broker的请求队列大小由参数 queued.max.requests控制,默认500,即broker最多保存500个未处理请求,否则client向broker发的请求会阻塞,直到队列非满
5)kafkarequestHandler线程池的大小由参数num.io.thread控制,默认是8,以下是broker请求流程图
6)broker端的processor线程组 NIO多路复用的体现,processor使用了Java的selector,acceptor 拿到的socket事件会被processor注册到selector实例中,然后一直轮训监听

(8)producer端设计
1)基本数据结构
i.ProducerRecord封装一条待发送的消息记录
2)基本流程

(9)consumer端设计
1)consumer group 状态机
消费者组的管理工作又broker端coordinator 负责,而分区分配工作则在consumer端,有一个leader consumer负责
一个group有5个状态,都在consumer中以实体类形式存在
Empty :组内务任何活跃consumer,RreparingRebalance表明正准备进行group rebalance,可能此时正在有新的组成员加入或者离开;awaitingSync:表明所有成员已加入组并等待 分区分配方案,不能提交位移;table正常消费状态,dead表明组被废除,没有活跃消费者,也没有任务元数据,跟empty不同
2)group管理协议
coordinator管理有两阶段,加入阶段和状态同步阶段,第一阶段主要选出leader,leader consumer一般是第一个加入group的consumer,然后获取所有成员都支持的分配策略(默认支持range、round-robin和sticky),如果有成员自定义其他成员不支持的分配策略,则不会加入组,最后coordinator会将所有成员的元数据发送给leader consumer
第二阶段主要指定分配策略后进行分区分配,每个consumer向coordinator发送sycGroup请求,然后会受到分配给自己的分区
3)实现精确一次处理
i)producer端提供的是至少一次的语义即 at least once,
原因是producer端若发送请求崩溃,则重试机制会使消息在重试次数内发送成功,单若在response过程发生崩溃,则重试会导致消息重复
ii)consumer则看提交位移的时机,若位移先提交,再处理消息,则处理过程崩溃的话实现的是最多一次语义 at most once,消息面临丢失风险;若先处理完消息再提交位移,则在处理中出错时实现的是最少一次,消息面临重复风险,at least once
iii)幂等性producer 同一条消息被producer因为重试而发送多次,单broker端只写入一次,kafka 0.11版本以后已经在producer端实现了精确一次且有序,即便是broker或者producer挂了,再次重启后发送来的消息leader也能够判断消息是否重复,原理是每个消息包含了一个序列号,enable.idempotence=true
该参数设置要求acks=all,retries>0 ,max.in.flight.requests.per.connection<5 官网要求,否则抛异常,producer会对消息生成序列号并保存到日志,该序列号总是单调递增,用于消息去重,
producer每个都会有pid,pid、分区和序列号的关系类似map,key是(pid,分区号),value是序列号,因此幂等性,只能在一个producer的情况下生效,多个producer的pid会不同,没办法保证 精确一次
iv) kafka如何实现精确语义,精确一次?
producer端设置ack=all,同时开启幂等producer;消费端关闭自动提交,在业务处理完后进行提交,同时做好幂等性处理,最少一次+幂等性处理去重=精确一次
第七章 kafka调优
1.调优流程:根据问题确定目标–>调整对一个参数–>测试是否满足–>循环以上流程
2.集群基础调优
(1)调优吞吐量
1)最重要的就是 producer端的linger.ms和batch.size,同时compresstion.type压缩batch能够极大减少网络传输
2)通常来说分区数越多TPS越好,producer能够同时向多个分区发送消息,但是分区太多也有弊端:
i.batch是分区级别的,使用缓存区为分区缓存消息,那分区越多producer内存越高
ii.broker端要为分区保存元数据
iii.由于分区都有专属日志目录和文件,索引文件和日志段文件,目前kafka打开这个日志文件后就不会关闭,分区越多占的文件句柄就越多,因此要小心too many files open
3)如果能够忍受消息丢失,那么producer端的ack可以为0 ,retries也可为0 ,这样能减少消息发送的时间
4)buffer.size设置的合适能够使得每次缓存的分区消息更多,一次性发送的也就能更多,提高TPS
5)一个组内的consumer数量最好与待消费的分区数相同, 每个消费者都能分配一个分区
6)

3.kafka削峰使用:两边处理请求或者数据的速度有差异,且允许异步非实时处理,即请求提交一个,本来就应该有一个线程处理请求,但这样系统压力会很大,而放kafka,可以立即返回,然后单独用几个线程慢慢处理kafka中的累计消息