2023前端面试问答_Node.js
请介绍一下node里的模块是什么
Node中,每个文件模块都是一个对象,它的定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
所有的模块都是 Module 的实例。可以看到,当前模块(module.js)也是 Module 的一个实例。
我们知道node导出模块有两种方式,一种是exports.xxx=xxx和Module.exports=}}有什么区别吗
module.exports vs exports
很多时候,你会看到,在Node环境中,有两种方法可以在一个模块中输出变量:
为什么用Nodejs,它有哪些缺点
事件驱动,通过闭包很容易实现客户端的生命活期。
不用担心多线程,锁,并行计算的问题
V8引擎速度非常快
对于游戏来说,写一遍游戏逻辑代码,前端后端通用
当然Nodejs也有一些缺点:
nodejs更新很快,可能会出现版本兼容
nodejs还不算成熟,还没有大制作
nodejs不像其他的服务器,对于不同的链接,不支持进程和线程操作
如何用Node监听80端口
这题有陷阱!在类Unix系统中你不应该去监听80端口,因为这需要超级用户权限。因此不推荐让你的应用直接监听这个端口。
目前,如果你一定要让你的应用80端口的话,你可以有通过在Node应用的前方再添加一层反向代理(例如nginx)来实现,如下图。否则,建议你直接监听大于1024的端口
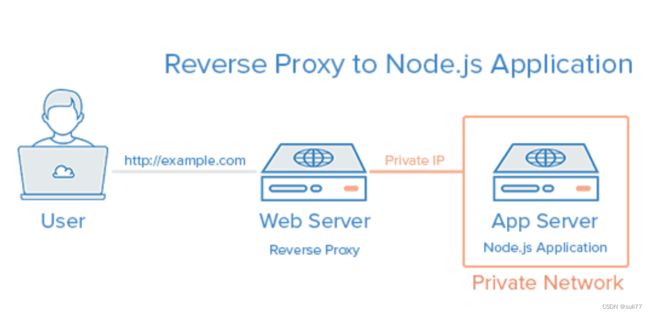
方向代理指的是以代理服务器来接收Internet上的连接请求,然后将请求转发给内部网络上的服务器, 并且将服务器返回的结果发送给客户端。
node.js有哪些常用模块
util是node 里面一个工具模块,node里面几乎所有的模块都会用到这个模块
功能:
1.实现继承这是主要功能
2.实现对象的完整输出
3.实现判断数据类型
path模块
功能:格式规范化路径
fs模块
功能:
1.操作文件
2.操作目录
http模块:用于搭建HTTP服务端和客户端
url模块:用户解析和处理URL字符串
url.parse(将url字符串解析并返回一个url的对象)
url.format(将url对象编程一个url字符串并返回)
url.resolve(将url中的参数用/进行拼接)
zlib模块:提供了用Gzip和Deflate/Inflate实现的压缩功能
socket.io: 实现客服端与服务端之间的实时通信方式
uglify-js: 用来压缩合并js文件
child_process:新建子进程。
querystring:解析URL中的查询字符串。
crypto:提供加密和解密功能。
node如何实现异步非阻塞(l/O)
在node中,I/O(输入输出)是异步非堵塞的关键,I/O操作通常比较耗时但不会独占CPU,典型的I/O比如文件读写,远程数据库读写,网络请求等,如果用同步API来进行I/O操作,在返回结果之前就只能等待,此时阻塞代码会霸占cpu,导致本进程所有代码都等待,而node.js里面的I/O API都是不会霸占CPU的(原因:node中的核心库libuv会将建立的所有I/O操作内容绑定到单个线程上。只要每个事件循环在不同的线程中,就可以运行多个事件循环,libuv为Node.js提供了跨平台、线程池、事件池、异步I/O等能力),所以是非阻塞的。拿JS中的setTimeout来打比方,当用户使用setTimeout时,JS会开辟出一个异步线程池,与主线程分开执行,结果就是之前的代码继续执行,setTimeout的代码延时执行,等成功后再调用主线程的方法
node中的exports如何实现的,它和module.exports有什么关系
exports实现:exports = module.exports = {};就好像是var a = { } var b = a,看上去没有太大区别,但使用起来却又不同module是一个对象,当我们在控制台输入node并执行,在node中执行module或者执行js文件打印module时会发现以下log
Module {
id: '',
path: '.',
exports: {},
parent: undefined,
filename: null,
loaded: false,
children: [],
paths: [
...
]
}`
不难发现,module是Module的实例,exports是其中一个属性,也就是说当你在node中执行一个js文件或者使用
require引入模块时,nodejs都会新建一个var module = new Module(),并执行exports = module.exports,
这也就是为什么直接打印exports和exports时,控制台不会报错,如果在node中执行以下代码,就能清楚的看出
这二者的引用关系了
谈谈Node.js加载模块机制
node.js中模块有两种类型:核心模块和文件模块
核心模块直接使用名称获取,文件模块只能按照路径加载(可以省略默认的.js拓展名,不是js文件的话需要显示声明书写)
模块加载规则:
核心模块优先级最高,直接使用名字加载,在有命名冲突的时候首先加载核心模块可通过绝对路径和相对路径查找查找node_modules目录,我们知道在调用 npm install 命令的时候会在当前目录下创建node_module目录(如果不存在) 安装模块,当 require 遇到一个既不是核心模块,又不是以路径形式表示的模块名称时,会试图 在当前目录下的 node_modules 目录中来查找是不是有这样一个模块。如果没有找到,则会 在当前目录的上一层中的 node_modules 目录中继续查找,反复执行这一过程,直到遇到根目录为止
Node.js的适用场景
实时应用:如在线聊天,实时通知推送等等(如socket.io)
分布式应用:通过高效的并行I/O使用已有的数据
工具类应用:海量的工具,小到前端压缩部署(如grunt),大到桌面图形界面应用程序
游戏类应用:游戏领域对实时和并发有很高的要求(如网易的pomelo框架)
利用稳定接口提升Web渲染能力
前后端编程语言环境统一:前端开发人员可以非常快速地切入到服务器端的开发(如著名的纯Javascript全栈式MEAN架构)
node中的Connect模块是什么,Koa与Express的中间件有什么区别
Connect是一个node中间件(middleware)框架,每个中间件在http处理过程中通过改写request或(和)response的数据、状态,实现了特定的功能Koa与Express中间件的区别:Express主要基于Connect中间件框架,中间件一个接一个的顺序执行,通常会将 response 响应写在最后一个中间件中而koa主要基于co中间件框架,它的中间件是通过 async await 实现的,中间件执行顺序是“洋葱圈”模型。执行效果类似于Promise.all
Node.js有什么优势
以下是Node.js的主要优点:
Node.js是异步的并且是事件驱动的。 Node.js库的所有API都是非阻塞的, 它的服务器不等待API返回数据。调用后它将移至下一个API, Node.js的事件通知机制将从上一个API调用响应服务器。
Node.js速度非常快, 因为它基于Google Chrome的V8 JavaScript引擎构建。它的库在代码执行方面非常快。
Node.js是单线程的, 但具有高度可扩展性。
Node.js提供了无缓冲的功能。它的应用程序从不缓冲任何数据。它分块输出数据。
两个 Node.js程序之间如何交互
通过fork实现父子程序之间的交互。子程序用 process.on、 process. send访问父程序,父程序用 child.on、 child.send访问子程序。
关于 parent. JS的示例代码如下。
var cp = require (' child_process' ) ;
var child= cp.fork ('./child. js' );
child .on('message', function(msg){
console.1og('子程序发送的数据:',msg )
})
child.send ( '来自父程序发送的数据' )
关于 child .js的示例代码如下。
process .on ( 'message' , function(msg){
conso1e.1og ( '父程序发送的数据: ' , msg )
process.send ( '来自子程序发送的数据' )
解释NodeJS中间件概念
一般来说,中间件是一个接收请求和响应对象的函数。换句话说,在应用程序的请求-响应循环中,这些函数可以访问各种请求和响应对象以及循环的下一个函数。中间件的 next 功能是借助一个变量来表示的,通常命名为 next。中间件功能最常执行的任务是:
执行任何类型的代码
更新或修改请求和响应对象
完成请求-响应循环
调用堆栈中的下一个中间件
Node.js 中 readFile 和 createReadStream的区别
Node.js 提供了两种读取和执行文件的方式,分别是使用 readFile 和 CreateStream。readFile() 是一个完全缓冲的进程,只有当完整的文件被推入缓冲区并被读取时才返回响应。这是一个内存密集型过程,在大文件的情况下,处理速度可能非常慢。而 createReadStream 是部分缓冲的,它将整个过程视为一个事件系列。整个文件被分成块,然后被处理并作为响应一一发回。完成后,它们最终会从缓冲区中删除。与 readFile 不同,createReadStream 对于大文件的处理非常有效。
有什么nodejs类库可以直接指定时区吗
主要表现在各种日期数据转换和存储上面。前后端在传递和存储日期时都有几种选择回:
1,unix的时间戳。
2,格式化后的字符串格式,如2012-04-01 10:00:00等。
3,直接存储日期类型.mongoose中。
容易出现问题的是驱动在处理不同日期格式上的差异。
目前在做一个小应用中碰到了这方面的问题。
当然这个也可能是自己的了解不深入,写在这里也希望有更多的人能讲解一下日期、时区等方面的知识。
问题表现在mysql中。mongo的时间是utc时间的,不带时区信息。
如果做数据转换工具得注意这些问题了。
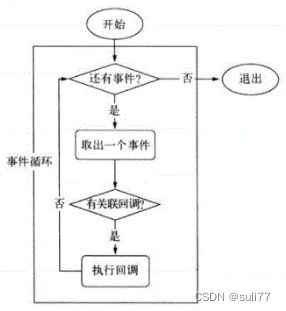
请介绍一下Node事件循环的流程
在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们成为Tick。
每个Tick的过程就是查看是否有事件待处理。如果有就取出事件及其相关的回调函数。然后进入下一个循环,如果不再有事件处理,就退出进程。
请问实现一个node子进程被杀死,然后自动重启代码的思路
在创建子进程的时候就让子进程监听exit事件,如果被杀死就重新fork一下
var createWorker = function(){
var worker = fork(__dirname + 'worker.js')
worker.on('exit', function(){
console.log('Worker' + worker.pid + 'exited');
// 如果退出就创建新的worker
createWorker()
})
}
如果使用过koa、egg这两个Node框架,请简述其中的中间件原理,最好用代码表示一下

- 上面是在网上找的一个示意图,就是说中间件执行就像洋葱一样,最早use的中间件,就放在最外层。处理顺序从左到右,左边接收一个request,右边输出返回response
- 一般的中间件都会执行两次,调用next之前为第一次,调用next时把控制传递给下游的下一个中间件。当下游不再有中间件或者没有执行next函数时,就将依次恢复上游中间件的行为,让上游中间件执行next之后的代码
- 例如下面这段代码
const Koa = require('koa')
const app = new Koa()
app.use((ctx, next) => {
console.log(1)
next()
console.log(3)
})
app.use((ctx) => {
console.log(2)
})
app.listen(3001)
执行结果是1=>2=>3
koa中间件实现源码大致思路如下:
// 注意其中的compose函数,这个函数是实现中间件洋葱模型的关键
// 场景模拟
// 异步 promise 模拟
const delay = async () => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, 2000);
});
}
// 中间间模拟
const fn1 = async (ctx, next) => {
console.log(1);
await next();
console.log(2);
}
const fn2 = async (ctx, next) => {
console.log(3);
await delay();
await next();
console.log(4);
}
const fn3 = async (ctx, next) => {
console.log(5);
}