爬取51job职位信息--进行专业市场需求可视化分析(python、tableau、DBeaver)
爬取51job信管专业相关岗位的情况进行可视化分析。
采用工具:python、tableau(可视化)、DBeaver(数据库管理软件)
文章目录
- 一.数据爬取
-
- 1.1导入相关的库
- 1.2对每个岗位搜索的到的总页数进行爬取
- 1.3进行爬取数据相关函数的设计
- 1.4进行数据的爬取
- 1.5数据库爬取到的数据展示
- 二.数据清洗
-
- 2.1清洗相关函数的设计
- 2.2进行数据清洗
- 2.3清洗后数据展示
- 三.数据可视化
-
- 3.1 柱状图
- 3.2 树状图
- 3.3各岗位类型公司规模数量特征条形图
- 3.4 热力图
- 3.5 箱线图
- 3.6 职位薪资Sankey图
- 3.7 岗位工作待遇热词词云图
- 3.8 不同类型岗位更新数量的折线图
- 四.结合自身对信管职位的分析
-
- 4.1简介
- 4.2分析
- 4.3总结
一.数据爬取
数据爬取过程
考虑到requests库进行数据的请求容易被平台反扒发现,从而封锁ip导致数据不能正常爬取。因此采用selenium模拟浏览器,进行数据的采集。总共需要采集的岗位有30终类型,先通过selenium采集每种类型岗位需要采集的总页数。然后利用每种岗位的总页数信息,进行岗位数据的采集。通过模拟浏览器访问51job网页,获取页面的HTML文本,然后采用BeautifulSoup库进行需要采集数据点的的数据的获取,最终将获取到的数据写入数据库中进行存储。
1.1导入相关的库
import requests
from bs4 import BeautifulSoup
import pymysql
import random
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import re
import time
import requests
1.2对每个岗位搜索的到的总页数进行爬取

if __name__ == '__main__': #主函数
job=["产品经理","产品助理","交互设计","前端开发","软件设计","IOS开发","业务分析","安卓开发","PHP开发","业务咨询","需求分析","流程设计"
,"售后经理","售前经理","技术支持","ERP实施","实施工程师","IT项目经理","IT项目助理","信息咨询","数据挖掘","数据运营","数据分析","网络营销",
"物流与供应链","渠道管理","电商运营","客户关系管理","新媒体运营","产品运营"]
#总共30个职位的列表
#https://www.pexels.com/
option = ChromeOptions()
UA="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"
option.add_argument(f'user-agent={UA}')
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
web = webdriver.Chrome(chrome_options=option) # chrome_options=chrome_opt,,options=option
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
web.implicitly_wait(3)
url='https://search.51job.com/list/000000,000000,0000,00,9,99,%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86,2,2.html?'
web.get(url)
time.sleep(6)
page_list=[]
for j in job:
for i in range(1, 1 + 1):
#url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + j + ",2," + str(i) + ".html?"
url="https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html?".format(j, i)
web.get(url)
html = web.page_source
soup = BeautifulSoup(html, "lxml")
text = soup.find_all("script", type="text/javascript")[3].string
# 观察原始代码发现我们需要的数据在 engine_jds 后
page_te=eval(str(text).split("=", 1)[1])["total_page"]
page_list.append(page_te)
print(page_te)
#得到的page_te列表将用于之后的数据爬取时对应每个职位的爬取页数。
1.3进行爬取数据相关函数的设计
#定义 spider()函数,用于获取每个 url 的 html
def spider(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"}
try:
rep = requests.get(url, headers=headers)
rep.raise_for_status()
rep.encoding = rep.apparent_encoding
txt = rep.text
return txt
except:
print("解析失败")
#定义 jiexi()函数,用于解析得到的 html
def jiexi(html, info,name):
soup = BeautifulSoup(html, "lxml")
text = soup.find_all("script", type="text/javascript")[3].string
#观察原始代码发现我们需要的数据在 engine_jds 后
data = eval(str(text).split("=", 1)[1])["engine_jds"]
for d in data:
try:
job_name = d["job_name"].replace("\\", "") # 岗位名称
except:
job_name = " "
try:
company_name = d["company_name"].replace("\\", "") # 公司名称
except:
company_name = " "
try:
providesalary_text = d["providesalary_text"].replace("\\", "") # 薪资
except:
providesalary_text = " "
try:
workarea_text = d["workarea_text"].replace("\\", "") #工作地点
except:
workarea_text = " "
try:
updatedate = d["updatedate"].replace("\\", "") #更新时间
except:
updatedate = " "
try:
jobwelf = d["jobwelf"].replace("\\", "") # 工作待遇
except:
jobwelf = " "
try:
companyind_text = d["companyind_text"].replace("\\", "") # 公司类型
except:
companyind_text = " "
try:
companysize_text = d["companysize_text"].replace("\\", "") # 公司规模
except:
companysize_text = " "
try:
at = d["attribute_text"] # 工作要求
s = ''
for i in range(0, len(at)):
s = s + at[i] + ','
attribute_text = s[:-1]
except:
attribute_text = " "
#将每一条岗位数据爬取下的内容以及传入参数 name 作为一个列表,依此加入到 info 列表中
info.append( [ name,job_name, updatedate, company_name, companyind_text, companysize_text, workarea_text, providesalary_text, attribute_text, jobwelf])
#将数据存到 MySQL 中名为“51job”的数据库中
def save(info):
#将数据保存到数据库表中对应的列
for data in info :
present_job = data[0] # 当前爬取岗位
job_name = data[1] #岗位
updatedate = data[2] #更新时间
company_name = data[3] # 公司名称
companyind_text = data[4] #公司类型
companysize_text = data[5] #公司规模
workarea_text = data[6] #工作地点
providesalary_text = data[7] #薪资
attribute_text = data[8] #工作要求
jobwelf = data[9] #工作待遇
# 创建 sql 语句
sql = "insert into jobs(当前爬取岗位,岗位,更新时间,公司名称,公司类型,公司规模,工作地点,薪资,工作要求,工作待遇) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行 sql 语句
cursor.execute(sql, [present_job, job_name, updatedate, company_name, companyind_text, companysize_text,
workarea_text, providesalary_text, attribute_text, jobwelf])
db.commit() # 提交数据
1.4进行数据的爬取
if __name__ == '__main__': #主函数
job=["产品经理","产品助理","交互设计","前端开发","软件设计","IOS开发","业务分析","安卓开发","PHP开发","业务咨询","需求分析","流程设计"
,"售后经理","售前经理","技术支持","ERP实施","实施工程师","IT项目经理","IT项目助理","信息咨询","数据挖掘","数据运营","数据分析","网络营销",
"物流与供应链","渠道管理","电商运营","客户关系管理","新媒体运营","产品运营"]
#利用1.2获得的每个岗位对应的总页码数。
page_list=['1141', '62', '169', '619', '356', '61', '229', '64', '56', '356', '1379', '147', '62', '29', '2000', '173', '184', '10', '2', '396', '221', '115', '2000', '381', '5', '295', '1233', '280', '699', '352']
#https://www.pexels.com/
option = ChromeOptions()
UA="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"
option.add_argument(f'user-agent={UA}')
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
web = webdriver.Chrome(chrome_options=option) # chrome_options=chrome_opt,,options=option
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
web.implicitly_wait(10)
url='https://search.51job.com/list/000000,000000,0000,00,9,99,%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86,2,2.html?'
web.get(url)
time.sleep(6)
le=len(job)
#连接数据库
db = pymysql.connect( # 连接数据库host="127.0.0.1", #MySQL 服务器名
user="root", # 用户名
password="12345678", # 密码
database="python上机", # 操作的数据库名称charset="utf8"
)
cursor = db.cursor()
for j in range(23,le):
for i in range(1,int(page_list[j])):#页面
info = []
# url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + j + ",2," + str(i) + ".html?"
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html?".format(job[j], i)
web.get(url)
ht = web.page_source
soup = BeautifulSoup(ht, "lxml")
jiexi(ht, info,job[j])
print('岗位{}:{}/{}'.format(j,i,page_list[j]))
time.sleep(2)
save(info)
time.sleep(3)
cursor.close()
# 关闭连接
db.close()
1.5数据库爬取到的数据展示

二.数据清洗
2.1清洗相关函数的设计
#引入 pymysql 包
import pymysql
#连接 MySQL 数据库
db = pymysql.connect(
host="127.0.0.1",
user="root", password="12345678",
database="python上机", charset="utf8"
)
def pipei():
cursor = db.cursor() # 获取操作游标
cursor.execute("select * from jobs") # 从 jobs 表中查询所有内容并保存
results = cursor.fetchall() # 接受全部的返回结果
after_pipei = [] # 建立一个空列表,用来存储匹配后数据
for each_result in results:
if each_result[-1] == '物流与供应链':
if '物流' in each_result[0] or '供应链' in each_result[0]:
after_pipei.append(each_result)
elif each_result[-1] == '新媒体运营' or each_result[-1] == '电商运营':
if '运营' in each_result[0]:
after_pipei.append(each_result)
# 由于在以关键词“电商运营”或“新媒体运营”搜索的岗位信息中包含大量具体电商或新媒体平台名称的岗位名称,如“拼多多运营”“抖音运营”等,因此在这两类岗位名称匹配时我们认为只要岗位名称中包含“运营”就算匹配成功。
elif each_result[-1] == '客户关系管理':
if'客户关系' in each_result[0]:
after_pipei.append(each_result)
elif each_result[-1] == '安卓开发':
if '安卓' in each_result[0] or 'Android' in each_result[0]:
after_pipei.append(each_result)
# 由于在很多公司的招聘岗位中“安卓”会以“Android”英文形式出现,因此,在以“安卓开发”为关键词进行搜索时,我们认为只要包含“安卓”或“Android”开发就算匹配成功。
elif each_result[-1][:-2] in each_result[0] and each_result[-1][-2:]:
after_pipei.append(each_result)
# 剩余岗位需要两个关键词都存在岗位名称中,例如包含“数据”或“分析”在以“数据分析” 为关键词搜索的岗位名称种,我们就认为匹配成功。
cursor.close() # 关闭游标
return after_pipei # 返回匹配后的列
def split_city(data):
after_split_city = [] #建立一个空列表,用来存储匹配后数据
for each_date in data:
each_date_list = list(each_date)
each_date_list[5] = each_date_list[5].split('-')[0] #将数据表中工作地点列以'-'进行切割,选取第一个元素替换
after_split_city.append(each_date_list)
return after_split_city
#返回筛除后的数据
def salary(data):
after_salary=[] #建立一个空列表,用来存储匹配后数据
for each_data in data:
each_data=list(each_data)
if each_data[6] != '' and each_data[6][-1] != '时' and each_data[6][-3] != '下' and each_data[6][-4:-2] != '以下' and each_data[6][-3] != '上':
# 筛除缺失值,以小时计费,给出的薪资表达为在“……以下”及“……以上”等难以计算数据的工作岗位
# 统一量纲(单位:千/月)
if each_data[6][-1] == '年':
each_data[6] = str(round((float(each_data[6].split('万')[0].split('-')[0]) + float(each_data[6].split('万')[0].split('-')[1])) * 5/12,1)) + '千 / 月'
elif each_data[6][-1] == '天':
each_data[6] = str(round((float(each_data[6].split('元')[0]) * 30/1000),1)) +'千 / 月'
elif each_data[6][-3] == '万':
each_data[6] = str(round((float(each_data[6].split('万')[0].split('-')[0]) + float(each_data[6].split('万')[0].split('-')[1])) * 5,1)) + '千/月'
else:
each_data[6] = str(round((float(each_data[6].split('千')[0].split('-')[0]) + float(each_data[6].split('千')[0].split('-')[1]) /2),1 )) + '千 / 月'
after_salary.append(each_data)
return after_salary
# 返回平均工资后的数据
def job_attribute_text(data):
for each_data in data:
if len(each_data[7].split(',')) == 3:
if ' 经验' in each_data[7].split(',')[1] or ' 在校生' in each_data[7].split(',')[1]:
each_data[7] = each_data[7].split(',')[1] + ','
# 以“,”切割后的列表长度为 3,若不包含“经验”元素,则保留“,学历”形式内容
else:
each_data[7] = ',' + each_data[7].split(',')[1]
# 以“,”切割后的列表长度为 4,选取中间两个元素,保留“经验,学历”形式内容
elif len(each_data[7].split(',')) == 4:
each_data[7] = each_data[7].split(',')[1] + ',' + each_data[7].split(',')[2]
else:
each_data[7] = ''
return data
#将清洗后的数据保存到数据库中 after_clean 表中,代码和保存爬取数据时类似
def save(data):
cursor = db.cursor()
for each_data in data:
job_name = each_data[0]
updatedate = each_data[1]
company_name = each_data[2]
companyind_text = each_data[3]
companysize_text = each_data[4]
workarea_text = each_data[5]
providesalary_text = each_data[6]
attribute_text = each_data[7]
jobwelf = each_data[8]
present_job = each_data[9]
sql = "insert into after_clean(当前爬取岗位, 岗位,更新时间,公司名称 ,公司类型,公司规模,工作地点,薪资,工作要求,工作待遇) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,
[present_job, job_name, updatedate,company_name, companyind_text,
companysize_text, workarea_text,
providesalary_text, attribute_text, jobwelf])
db.commit()
cursor.close()
db.close()
2.2进行数据清洗
if __name__ == "__main__":
data = pipei()
data1 = split_city(data)
data2 = salary(data1)
data3 = job_attribute_text(data2)
#将清洗后的数据存储到数据库的另一个表格中
save(data3)
2.3清洗后数据展示
清洗后的数据:薪资、工作要求、工作地点等进行了统一格式

三.数据可视化
采用工具:tableau+python
3.1 柱状图
绘制界面:
图形:
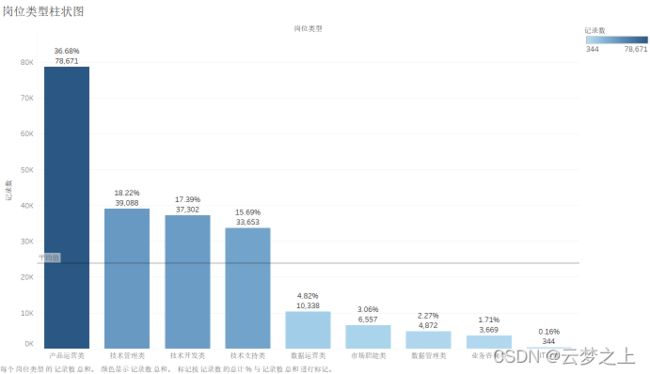
分析:
对于职位的类型的占比可以看出,产品运营类岗位占据了最大的份额,说明信管专业的学生在这类岗位中需求最多,往后的求职过程中可关注此类岗位的职位。此外,技术管理类、技术开发类、技术支持类岗位的占比也在平均值以上,此类岗位也可以多加关注。
3.2 树状图
绘制界面:
绘制图形:
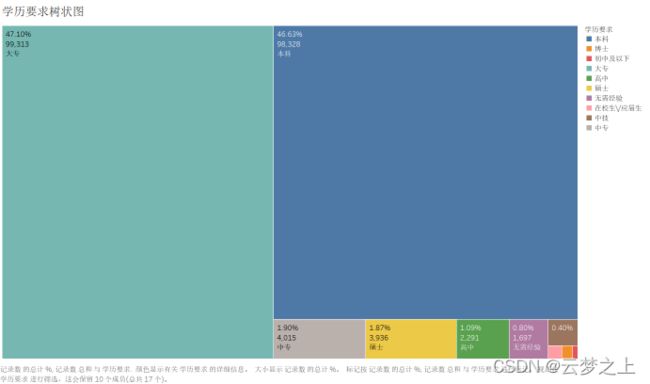
分析:
从学历要求的树状图可以看出,市场上的大部分与信管相关职位的需求是大专和本科均占据47%左右,对于硕士和博士等更高学历的要求分别占据0.0754066%、1.86667%,说明信管专业相关职业的学历门槛并不会太高。
3.3各岗位类型公司规模数量特征条形图
绘制界面:
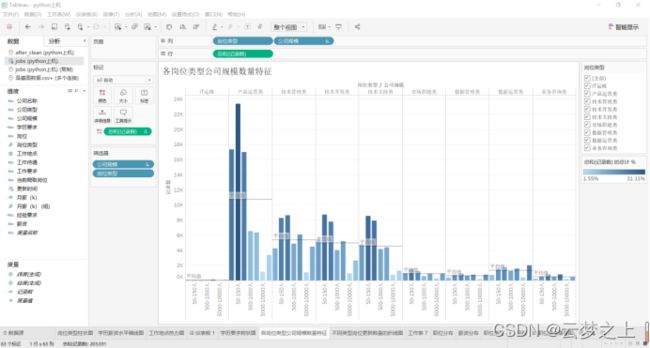
绘制图形:
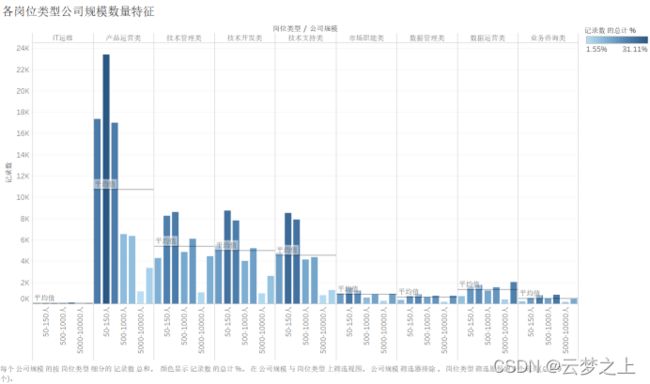
分析:
各岗位类型公司规模数量特征条形图可以看出,对于产品运营类职位,公司的规模规模主要为500人以下的公司。数据运营类、技术管理类、数据管理类公司大厂10000人以上的大厂占比较高,如果你想去大厂,那么可以选择这类职位发展。
3.4 热力图
绘制界面:
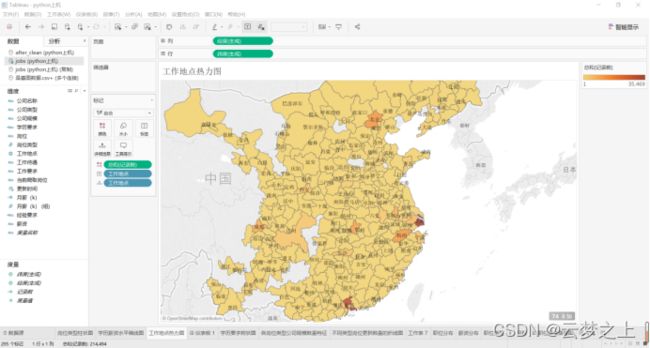
绘制图形:

分析:
通过对信管所有相关岗位的热力图分析可知,信管专业的工作地点在:上海、北京、成都、杭州、武汉、南京、深圳、广州、重庆、等地较多,其中在上海、广州、深圳3地的最多。此外,郑州、西安、长沙、合肥等地的职位也相对较多,所以如果想避免竞争的激烈,可以考虑这些地方。
3.5 箱线图
绘图界面:
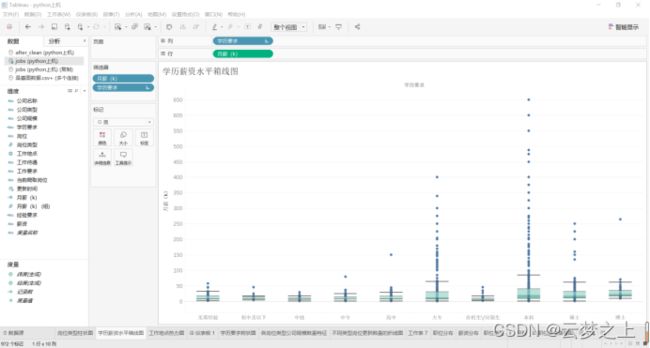
绘制图形:
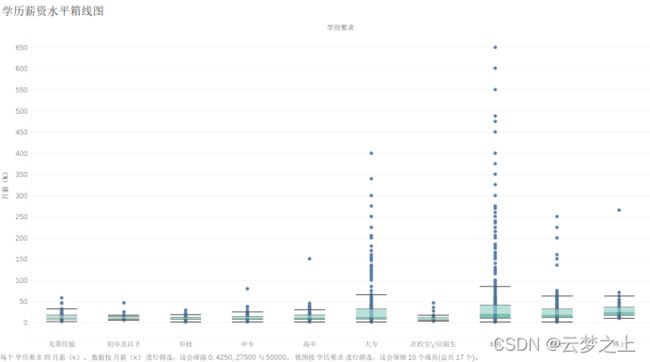
分析:
从学历的薪资水平箱线图可以看出:随着学历的上升,薪资的平均水平逐步提升,说明学历对于薪资是具有一定的影响的,学历越高,薪资的平均水平越高。此外,对于大专、本科、硕士类学历的专业,我们可以看到许多在箱线图以外的点,这些点表明这些职位的薪资大大超出平均水平,说明在某些职位,对于学历的要求并不是很重要,重要的是个人的其他方面的能力,比如说专业的机能等方面。为此,无论我们在那个阶段,要多加关注自己的职业技能,只要我们的学历和能力不是虚涨的,有实实在在的能力和产出做支撑,就不会有:大学生毕业了找不到工作这种焦虑。
3.6 职位薪资Sankey图
绘制界面:
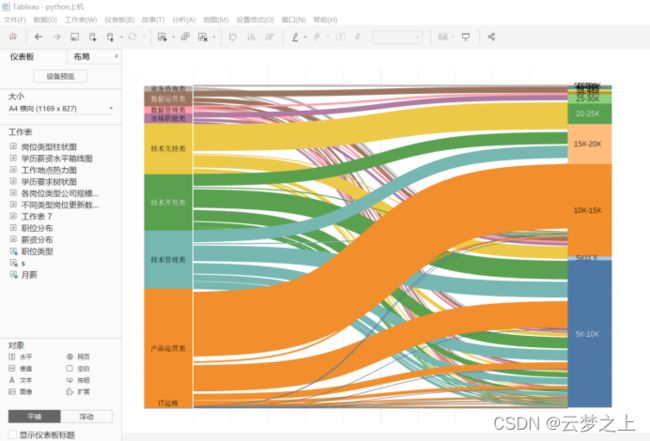
绘制图形:
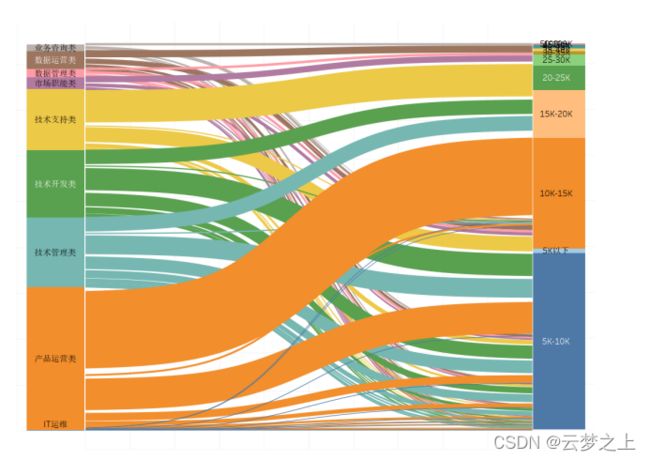
分析:
通过职位薪资的桑基图可以看出:月薪,产品运营类职位的薪资大部分在10-15K,其余集中在5-10k;技术管理类与技术开发类,部分达到15-20k,其余集中在10-15K;技术支持类大约二分之一达到20-25k;对于25k以上的高薪职位主要集中在业务咨询、数据运营、数据管理、技术支持类职业。其中月薪在40k及以上,基本分布在业务咨询、数据运营类职位,所以有超高薪职位目标的同学,可以考虑往这类职业发展。
3.7 岗位工作待遇热词词云图
代码:
#设计词频统计函数
def wordcount(txt):
#转化为列表
# 统计词频的字典
word_freq = dict()
# 装载停用词,此处需将资料中给出的hit_stopwords.txt 文件放到本代码所在路径下
with open(r"D:\Users\yunmeng\PycharmProjects\小项目\大数据和上机二_数据可视化课程\相关文件\stopwords.txt", "r", encoding='utf-8') as f1:
# 读取我们的待处理本文
txt1 = f1.readlines()
stoplist = []
for line in txt1:
stoplist.append(line.strip('\n'))
# 切分、停用词过滤、统计词频
for w in list(jieba.cut(txt)):
if len(w) > 1 and w not in stoplist:
if w not in word_freq:
word_freq[w] = 1
else:
word_freq[w] = word_freq[w] + 1
return word_freq
#连接数据库
db = pymysql.connect(
host="127.0.0.1",
user="root", password="12345678",
database="python上机", charset="utf8"
)
cursor = db.cursor()
cursor.execute("SELECT `工作待遇` FROM `after_clean`")
results = cursor.fetchall()
txt = ''
for each_result in results:
txt = txt + each_result[0]
word_dict=wordcount(txt)
da = pd.DataFrame({'word': word_dict.keys(), 'count': word_dict.values()})
#将词频统计的结果导出
da.to_csv(r'D:\Users\RK\PycharmProjects\小项目\大数据和上机二_数据可视化课程\代码文件\word_count.csv')
#将导出的词频文件导入到tableau进行词云图的绘制
绘制图形:
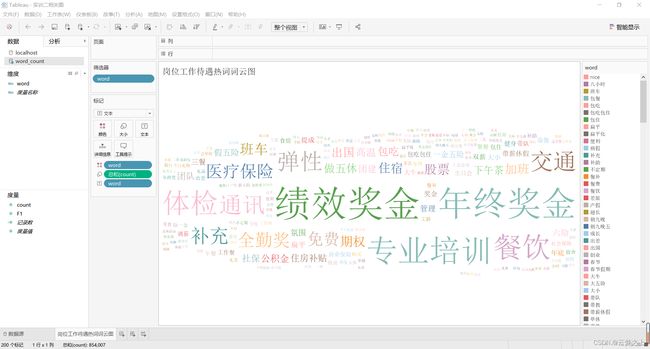
分析:
通过岗位工作待遇热词词云图可以看到,工作待遇之中,企业最常提到的是:绩效奖金、年终奖、专业培训、餐饮、交通、弹性、体检、通勤、医疗保险、期权等。说明了,我们求职时,考虑岗位时不要只单单看给的薪资是多少,其中涉及的对于绩效奖金、交通、医疗、餐饮、期权等与我们每日生活相关的衣、食、住、行和个人工作,个人晋升等多方面的条件都需要我们进行综合的考虑加以衡量,最终找出适合自己期望的职位。
3.8 不同类型岗位更新数量的折线图
绘制图形:
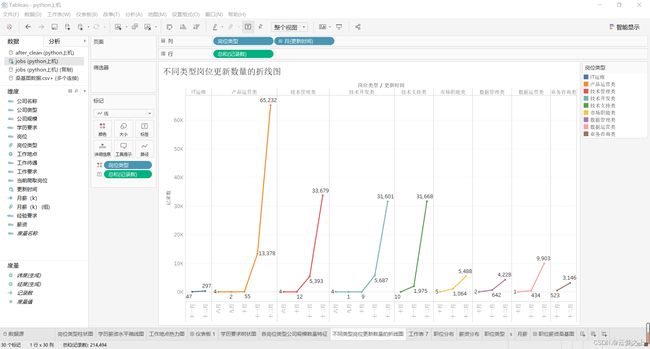
分析:
从不同类型岗位更新数量的折线图可以看出,各类型职位从10月份开始,均有扩大招聘数量的趋势,并且在11-12月增长速度最快。产品运营、技术管理、技术开发、技术支持等类的职位需求增长相对较多,其中产品运营类增长最多。因此,有求职意向的同学,求职时要多加注意10月开始的这个岗位需求增长的浪潮,最为注意的是11月-12月期间。在此期间准备充分,争取拿到心仪offers。
四.结合自身对信管职位的分析
4.1简介
求职目标:高薪、学历本科、大厂
对数据进行筛选
筛选条件:
①岗位类型:根据3.6 职位薪资Sankey图其中月薪在40k及以上,基本分布在业务咨询、数据运营类职位,所以对这类岗位类型进行筛选
②学历要求:本科、在校生or应届生
③月薪类别:40k+
绘制图形:

4.2分析
在40k以上的职位,根据薪资的方差,如果寻求平稳,那么可以选择数据运营类的职位,包括数据运营、数据分析岗位;如果有追求更高薪资水平的想法,可以尝试数据管理类职位,包括信息咨询与数据挖掘岗位。
此外:对筛选出的数据运营与数据管理类岗位进行导出到:结合自身对信管职位的分析筛选出的目标岗位.csv文件
数据结果如下:

对其中的公司名称进行词云图展现

可以看到:目标职业对应的主要公司是:腾讯和字节跳动。
4.3总结
如果你的求职目标是:高薪、学历本科、大厂。如果寻求平稳,那么可以选择数据运营类的职位,包括数据运营、数据分析岗位;如果有追求更高薪资水平的想法,可以尝试数据管理类职位,包括信息咨询与数据挖掘岗位,求职对应的主要公司是:腾讯和字节跳动。
