卷积神经网络(CNN)实现服装图像分类
活动地址:CSDN21天学习挑战赛

在上一个案例中没有讲到什么是卷积神经网络,接下来介绍一下
什么是卷积?
卷积神经网络(CNN),一般用来处理图像数据和时间序列数据。其中“卷积”是一种数学运算,一种特色的线性运算,至少在网络的一层中使用卷积运算替代一般的矩阵乘法运算的神经网络。
含义:
当你提供给计算机这一组数据后,他将输出描述该图像的某一特定分类的概率(比如:80%是猫、15%是狗、5%是年)。
我们人类是通过特征来区分猫和狗,现在用计算机来区分猫和狗的图片,就要计算机搞清楚猫猫狗狗各自的特征。计算机可以通过寻找诸如边缘和曲线之类的低级特点来分类图片,继而通过一系列卷积层构建出更为抽象的概念。这是CNN(卷积神经网络)工作方式的大体描述。
CNN架构
卷积层 conv2d
非线程变换层 relu/sigmoid/tanh
池化层 pooling2d
全连接层 w*x +b
卷积层
三个参数:
ksize 卷积核的大小
strides 卷积核移动的跨度
padding 边缘填充
非线性变换层(也就是激活函数):
relu
sigmoid
tanh
池化层:
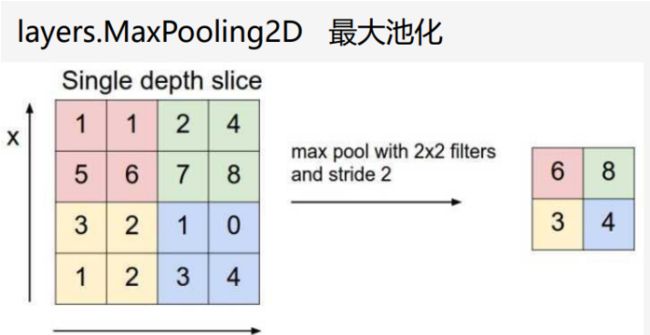
池化分为最大池化,平均池化,L2池化。
全连接层:
将最后的输出与全部特征链接,我们要使用全部的特征,为最后的分类做出决策,最后配合softmax进行分类
整体结构:
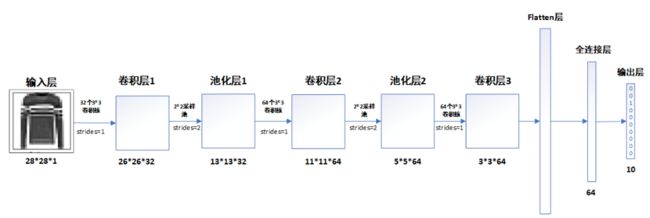
一、读取数据
Keras提供了数据集加载函数
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.fashion_mnist.load_data()
查看数据维度
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
'''
out:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
'''可以看到训练集有60000个28*28的图片,60000个标签,测试集有10000个28*28的图片,10000个标签。
plt.imshow(train_images[0])查看一下图片是一张图片
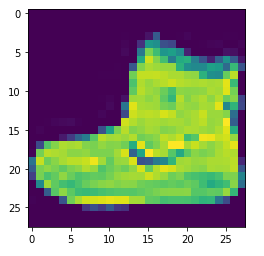
train_images[0]

那么其取值范围是[0 , 255]之间。
print(np.max(train_images))
print(np.min(train_images))
#255
#0那么其取值范围是[0 , 255]之间。我们接下来要进行归一化
二、数据预处理
1、在数据预处理时,首先采用reshape函数将每个图像矩阵扁平化成一个向量:
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
"""2、数据归一化,将输入值[0,255]归一化为[0,1]的取值范围:
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.03、数据可视化
plt.figure(figsize=(20,10))
for i in range(20):
plt.subplot(5,10,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(train_labels[i])
plt.show()
三、构建CNN神经网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),#卷积层1,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3
layers.MaxPooling2D((2, 2)), #池化层2,2*2采样
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取
layers.Dense(10) #输出层,输出预期结果
])
# 打印网络结构
model.summary()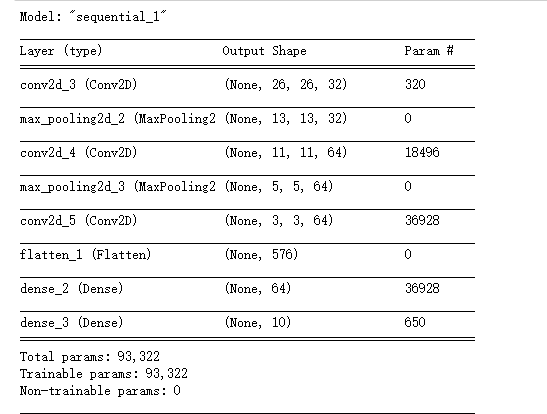
四、确定学习的目标
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])compile函数设置了学习的目标,其中:
loss:定义了损失函数,
optimizer:指定了优化算法,
metrics:是评价指标
五:模型训练
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))六、模型评估
调用evaluate函数对测试集进行评估,返回数组score,其中第一维是模型的损失值,第二维是模型评估的精度。

plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print("测试准确率为:",test_acc)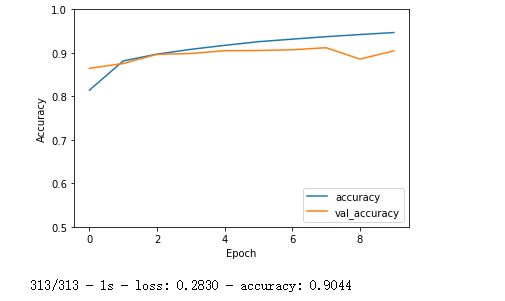
![]()
七、模型的预测
输出第一张测试集的预测结果
plt.imshow(test_images[1])
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果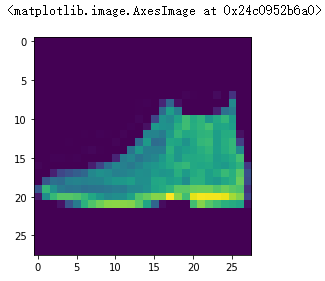

可以看到下标在9的位置值最大,所以预测的是Ankle boot
得到预测结果:
np.argmax([pre[0]])
#9
test_labels[0]
#9查看标签名字:
import numpy as np
pre = model.predict(test_images)
print(class_names[np.argmax(pre[0])])![]()
大家注意看了
>- 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw) 中的学习记录博客
>- 参考文章地址:深度学习100例-卷积神经网络(CNN)服装图像分类 | 第3天