基于Stable Diffusion的图像合成数据集
当前从文本输入生成合成图像的模型不仅能够生成非常逼真的照片,而且还能够处理大量不同的对象。 在论文“评估使用稳定扩散生成的合成图像数据集”中,我们使用“稳定扩散”模型来研究哪些对象和类型表现得如此逼真,以便后续图像分类正确地分配它们。 这使我们能够根据现实表现对模型进行评估。

推荐:用 NSDT编辑器 快速搭建可编程3D场景。
上面的照片使用足球的例子来表明,不仅生成了非常逼真的照片,而且从精确的文本提示开始,创建了非常不同的对象表示。
1、数据的生成
作为图像生成的基础,我们使用“稳定扩散”1.4 模型以及 Huggingface Diffusers 库的实现。 该模型允许根据文本提示创建和修改图像。 它是在 LION5B 文本到图像数据集的子集(LAION-Aesthetics)上训练的潜在扩散模型。
下图显示了根据文本提示生成的图像示例
Haflinger horse with short legs standing in water.
该示例表明,生成器模型可以表示具有不同属性的不同概念,并将它们组合在一种设置中。

我们创建了一个包含各种不同概念的图像的数据集。 对于文本输入,我们使用Wordnet中包含的信息。 Wordnet 将概念组织成所谓的“同义词集”,它对应于一个或多个具有相同含义的单词的含义。 因此,一个具有不同含义的词可以属于多个同义词集。 例如,“苹果”一词具有水果和计算机品牌的含义,并且每个术语都有一个同义词集。
从 Wordnet 同义词集“object.n.01”开始,通过递归调用“下位词”(比适用于它的一般或上位术语具有更具体含义的单词)创建了 26,204 个名词同义词集的列表。 对于每个名词,我们使用 Wordnet 中同义词集的描述来生成图像。
此类提示的示例是:(狗的同义词)
a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds
对于每个同义词集,生成 10 个图像并以该同义词集的名称存储并附加编号。 我们的数据集总共有 262,040 张图像。
与每个同义词集的 10 个图像一起,保存一个文本文件,其中包含所使用的提示、同义词集的名称(例如“dog.n.01”)和 wordnet 编号(例如“n12345678”)。 该记录可以从 Kaggle 下载。
2、数据评估
为了对数据集的子集进行系统评估,我们使用 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 数据集。
我们使用 Pytorch 实现的视觉 Transformer 模型来验证生成的图像是否可以正确分类,该模型在 ImageNet 数据上的 top-1 准确度为 88.55%,top-5 准确度为 98.69%。
对所考虑的子集中的所有 8610 个图像进行审查后,平均正确分类为每类 4.16 个图像(最多 10 个),所有类的平均标准差为 3.74。 下面的直方图显示了正确分类数量的巨大分布。 NSFW 过滤器产生的黑色图像是统计数据的一部分。

可以看出,虽然大多数类别 (73%) 至少生成了一张正确识别的图像,但只有 14% 的类别识别出了全部 10 张图像。 这也反映了文章开头的观察,即一个类的生成图像差异很大。 这使得分类过程的任务变得复杂。
现在让我们考虑一些对象组的识别率。 在Wordnet的层次结构下,总结了一些术语组的相关类别,并确定了每个术语的平均识别率。 下表显示了结果。

不同对象类别的识别率
值得注意的是建筑物的良好识别率。 下图显示了“Greenhouse”的所有 10 张图像均被正确识别。

“温室”——作者使用稳定扩散创建的图像
“动物”类别的分类率低于平均水平。 如果我们更仔细地观察这个群体,我们会发现对于 162 个动物类别,没有图像根本无法被识别。 看看具体的例子,例如以下术语“黑足雪貂”和“叶蝉”的例子,“稳定扩散”显然揭示了动物科学的重大缺陷。

“黑足雪貂” — 稳定扩散创建的图像
创建术语“地图”,显示哪些由稳定扩散生成的图像可以被视觉Transformer模型正确识别,并且每种情况下的识别率有多好,我们将术语按语义放置在 2D 中,并按子组对它们进行着色。 圆圈的大小表示正确分类的图像的数量。 为了确定该地图上的位置,我们使用单词嵌入来表示类的名称。
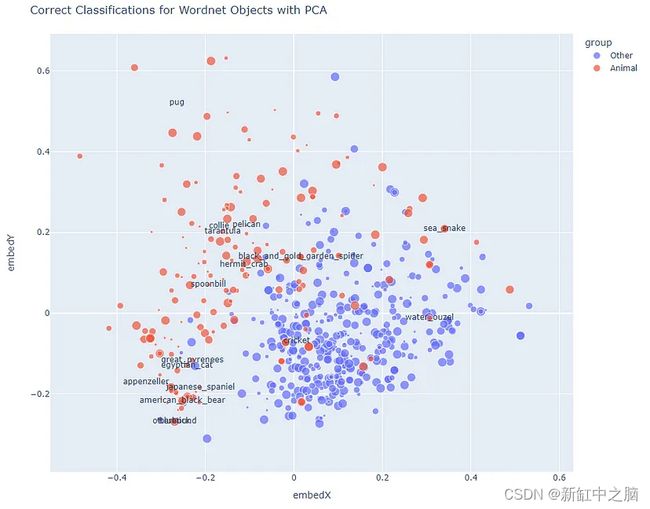
分类率“地图”
在这里,许多未被正确识别的动物类别小红点也很明显。
3、类似项目
Lexica是一个提供对稳定扩散生成的合成图像数据的访问的项目。 它是一个搜索引擎,可从超过 1000 万张图像中返回某个词条的结果。 不过这里的整个数据库无法下载,而且没有分类。

Lexica
DiffusionDB提供并描述了一个包含 200 万张图像的大型数据库,也可以作为开源下载和使用。
除了图像之外,DiffusionDB数据集还包含用于生成每个图像的文本提示。 作者通过爬行 Stable Diffusion 的 Discord 服务器并提取包括提示在内的图像来创建数据收集。
原文链接:稳定扩散合成数据集 — BimAnt