2.4 一个案例带你了解Power Query常用操作
在本文中,我们将会使用一套简单的案例数据进行一次完整的清洗,尽量覆盖到Power Query中最常用的功能,这些数据也会在接下来建模和DAX语言的讲解中继续用来作为示例数据。
关于案例数据
我们从 世界银行 Indicators | Data 下载了如下四项指标:0-14岁的人口(占总人口的百分比)、15-64岁的人口(占总人口的百分比)、65岁和65岁以上的人口(占总人口的百分比)、人口总数。另外还有一张也是官方提供的维度表,是国家名称、编码、归属区域、收入等级等基础信息。
因为这些数据不涉及更新,为了本地文件管理方便,我将这些数据表合并在了同一个excel中,实际操作中使用独立的文件也完全没有问题、甚至是更加灵活。因为不论是一个excel中的多个工作表、还是独立的多个excel文件,在导入后都是每张工作表形成一个数据源,在数据源数量上没有区别,按照个人使用习惯即可。
如下图所示,这些指标数据都拥有相同的结构,即数据主体从单元格A4开始,包括Country Name、Country Code、Indicator Name、Indicator Code等四个维度字段,以及1960-2021之间62年的数据,每年单独为一列。

国家维度表的结构如下:

维度表的清洗
如下图所示,国家表在初导入时,表头并未被识别,因为power query是根据第一行数据与后面的数据之间的差异来判断是否是表头的,因为该表是纯文本的,差异不明显,因此会被误判,这时很简单,点击“将第一行用做标题”即可完成标题的提升。

然后观察这张表,通常只要有编码列,我们都推荐使用编码做为各数据表之间关联用的字段,因为它具有非重复性,字段名下方的统计信息中显示没有空值,目测该列信息是完整的。如果对编码的唯一性不放心,也可以在“转换-统计信息”中,对该列进行非重复计数,用于确认。
在该表中我们可以看到,国家名称有空值,经过观察可以发现,该字段为空的记录中,地区以及收入等级列也都是空,可以认为是无效数据,所以也可以对国家名称列进行筛选,过滤掉空值。(这步不做也不要紧,因为影响的数据量很小,而且在报表中过滤也能实现相同的效果)。
数据表的清洗(年龄分组的同构指标)
step1 删除多余行
以0-14岁的数据为例,当数据导入后,power query执行默认的操作步骤,将第一行提升为标题,因此从c列之后因为第一行为空,都被赋了column3……等一系列默认标题,而我们实际要用的标题还处于第3行。

从菜单栏中选择:主页-删除行-删除最前面的几行,输入2行,即可将前面的行删除。
事实上,目前已执行的“提升标题”步骤相当于是多余的,所以我们也可以先将它以及后面“更改的类型”这两步一起删除,既是让步骤栏更整洁,也是让程序少做一些重复的操作。
为什么要同时删除更改类型这步呢?观察下图的公式栏,可以看到“更改的类型”这步中,是按照字段标题对各列进行设置的,所以如果直接删除“提升的标题”,程序会找不到对应的列名,因而报错。
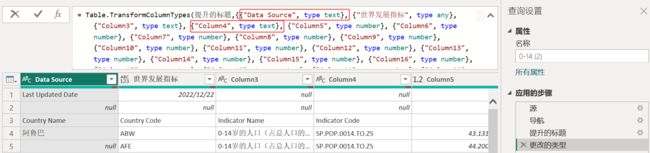
这里我们也补充一个小知识,假如数据底表中出现了字段名称变更、或是字段删除的情况,power query在刷新时由于有“更改的类型”步骤,就会出现找不到对应列的报错,此时可以在公式栏中找到对应字段名所在的位置,更改字段或称,或将对应的那组大括号及相邻的逗号删除即可,例如上图中的Data Source、Column4两个字段,画红框处就是要删除的完整范围。
如果按上述操作,先删除了多余的步骤的话,则需要删除的行数就要变更为3行。读者们也可以先做删除行操作之后,再做前述步骤删除,体验一下跳过步骤进行删除,反正效果是一样的。
step2 将首行提升为标题
在“主页”或“转换”选项卡中,点击“将第一行用作标题”,如下图所示,可以看到真正的标题出现在了表头位置,而且步骤栏中自动增加了接续的“更改的类型”步骤。

step3 更改数据类型
检查各列的数据类型是否识别准确,如果有需要变更的,可以点击列标题前的小图标来修改。在当前步骤就是类型更改时,如果再对个别字段进行类型更改,程序会弹窗要求确认是否将该操作生成一个新的步骤,如下图所示:

点击“替换当前转换”的话,该转换会直接记录在当前步骤中,选择“添加新步骤”的话则会生成一个新的步骤。通常都建议替换当前转换,这样可以让步骤更简洁。
例如我刚才选择了将1960列改为文本,并选择了“替换当前转换”,如下图所示,可以看到1960对应的类型变成了text,而其余的年份都还是number。如果我在公式栏中将“text”改为number,则该列的类型也会变回小数。

假如在上述操作中,我选择了“添加新步骤”,那么如下图所示,我们会看到步骤栏中增加了一个新步骤“更改的类型1”,从公式中也可以看到,这步只操作了一列。这样操作的话,想要撤销的话只需直接×掉该步骤即可。可以根据个人习惯选择。

在这里再补充一下,步骤记录器中,在执行相同的操作指令时,会依次在步骤名称后面增加数字序号,在步骤较多时,就会容易记不清楚每步的操作,所以推荐在复杂清洗时,对一些关键步骤右键改一下显示名称,这样会比较方便查找。
step4 数据压缩
我们读入的数据并不是全都有用的,而Power BI中数据都是按列存储的,因此删除多余的列能精简模型,压缩数据大小。
另外,导入的数据是全量的,而我们的报表可能只需要其中的一部分数据,也可能导入的数据中有一些无效的数据,需要过滤掉。这里就需要使用筛选、或是删除空行、删除错误、删除重复项等。
在本例中,我们可以看到国家名称这里是有一些空值的,虽然在编码列有值,但在国家信息的维度表中,这些编码同样没有对应的国家名称,可以认为是无效的,所以可以直接按国家名称将空值过滤。方法是点击字段名称右侧的筛选箭头,在选项中取消null的勾选。

接下来,已有的这些列中,国家与国家编码理论上是一一对应的,而且通常编码会比名称更不易出错,且编码不会重复,所以国家名称列其实是可以不要的,同理指标名称和指标编码,也是只需要保留一个即可。虽然指标名称更直观,但为了后续演示文本提取功能,我们在这里选择保留带分隔符的指标编码列。
因此,选中country name 和indicator name,右键删除列,注意这里我们虽然要使用country name进行筛选过滤,但因为这一步是在前面操作的,因此后面再做字段删除也不会影响数据。
step5表格变换
目前每年的数据单独成一列,是很不方便分析的,因此我们需要使用到逆透视的功能,将这些列转回行。选中不需要操作的列 Country Code 和 Indicator Code,在菜单执行 转换-逆透视列-逆透视其他列,得到下方结果,可以看到年份被合并为“属性”列,对应的指标值填在“值”列中。

上图中,可以看到“值”列的数据类型未被确定,其中1960年的值是左对齐,其余年份则是右对齐。这是因为刚才我们演示类型转换时,将1960改为文本造成的。
此时回步骤记录中将刚才的“更改的类型1”×掉,或是直接在“值”字段上指定类型为小数,均可以将该字段变更为正确的类型,如下图所示。

个人推荐应该尽量去修改前面的步骤,因为当数据量增大时,这些多余步骤的反复操作会影响查询速度。
step6 数据拼接
使用上述步骤完成0-14岁指标的清洗后,使用相同的方法清洗15-64和65及以上,就得到了同构的三张数据表,可以使用追加的方式,将它们合并在一张表中。

补充小技巧:同构表的快速清洗
由于这几张表需要的清洗方法基本是相同的,如果不想顺次都操作一次,也可以将当前查询的高级编辑器中的内容复制出来,如下图所示,画框处是对应工作表的名称,将它们改为新的工作表名称,如"15-64",然后替换掉对应查询的高级编辑器中的内容,即可将前述的这些操作步骤完全在对应数据表上实现。

另外,如果最开始并没有导入全部的数据表,也可以直接在查询窗格中右键,新建一个空查询,然后把新修改完的代码直接填充到空查询的高级编辑器中,即可完成对应表的导入和清洗。
step7 数据修整、加工等
完成数据拼合后,我们再做一些最后的加工。
修改列标题:譬如将“属性”的标题修改为“年份”。
数据计算加工
有时原始数据还需要添加一些运算,可以通过自定义列的功能实现。譬如指标值中的占比都是百分数,假如想转为实际数值,即除以100。在自定义窗口中双击“值”列,在公式区加上除法操作,如下图所示,即可生成新的列。

添加辅助列:
例如我们想对百分比进行一些分层,可以使用 添加列-条件列,如下图,即可将按人口占比分为三个不同的档。


修整数据内容:例如指标编码不够直观,我们想要把年龄分段显示为14岁以下,15-64岁和65岁及以上。
方法一:使用“替换值”,因为只有三个编码,分别进行三次查找替换即可。
方法二:使用添加列-条件列,如下图所示,设置每个编码对应的输出值,创建一个新列。

方法三:前两种方法都有一个缺点,就是我们需要知道一共有多少指标,以及对应的编码到底是什么,更重要的是指标编码很复杂,输入时不能出错。那么现在我们换一个方法,观察编码列,发现是用小数点做分隔的多组字段。那么我们可以先尝试用小数点做分隔符来分列。
首先将所有分隔符都进行拆分,得到了Indicator Code.1-5的五列,分别点击每列的筛选下拉框,观察一下可以看到,只有第三列的内容有区别。所以删除其余列,只保留这列即可作为指标的标识。

方法四:方法三虽然很直观,但先分列再删除用了两步。假设很明确要提取文本中的一部分时,更适宜的是使用“提取”,我们可以选择从“转换”选项卡中进入,直接修改当前列,也可以在“添加列”选项卡中使用同名操作,生成一个新的辅助列。
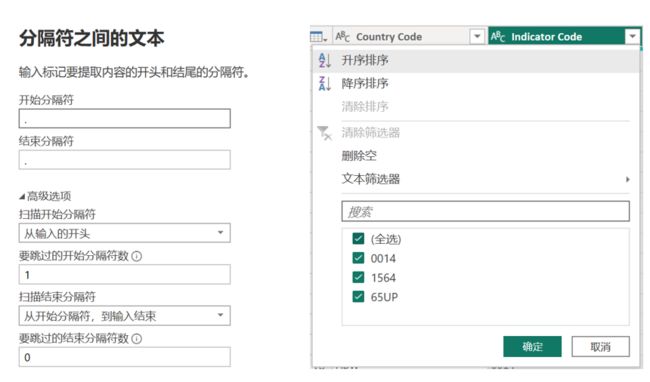
如下图左侧所示,我们使用转换-提取-分隔符之间的文本,起止分隔符都定义为小数点,在高级选项中选择从开头扫描,跳过第一个,因此从第二个小数点开始扫描,获取了它与第三个小数点之间的内容,如下右图所示。
结构重构:
例如我们现在想要将各个指标显示为列,那么就可以对年龄分段列进行透视。
选中刚才提取出的结果Indicator Code列,点击 转换-透视列,将“百分比”字段设置为值列,聚合方式按默认的求和(注意在执行此透视操作时,要将不再需要的列删除,包括原始的值、刚才示例的占比分级,否则会影响聚合),得到如下结果:

可以对各列再进行一次改名,如下图:

step8 复查
做完各项操作后,再最后检视一下得到的数据,目前各字段均是完整有效的。这时我们会注意到,年份字段还是文本,这样在用做坐标轴时会影响排序,所以可以再补充一步,将它变更为整数。实际在查漏补缺时,如果对各类操作比较熟悉,这些后补的操作也可以选择插入在前面的一些位置,以实现整体流程的简洁有效。
当然这一步不做也没有问题,在后续制作报表的过程中,如果发现问题,再随时回到power query中进行修改并应用即可。
数据表的清洗(人口总数指标)
人口总数指标的数据结构其实与另外三个完全一致,可以套用刚才的快速清洗的小技术,将对应的步骤复制到该查询中,可以得到以下的表格:

由于该表中只有一个指标,所以可以直接删除指标编码列,将“属性”列改名为“年份”,“值”列改名为“人口总数”即可。
清洗方案的补充说明
关于操作步骤的选择:
前面我们在清洗过程中,为了尽量覆盖常用操作,做了一些譬如添加辅助条件列、运算列等操作,在实际运用中,这类操作也可以在Power BI中通过写dax公式实现,方法没有高低好坏的差异,因个人习惯而异。
关于数据拼接方法:
在将三个年龄段占比的数据拼在一起时,我们先使用了追加查询,然后再做透视。而不是使用合并查询,按照国家+年份的方式进行拼接,是因为实际分析过程中,不是所有的数据都质量有保障的,很可能不同数据表之间的维度组合只是部分交叉重合,在拼接时如果连接方式选择不当,就可能造成数据丢失。
利用追加查询+透视的方法拼接,可以保留维度项的全量信息,比使用合并查询的方法一个个拼合,既省力又安全。
合并查询更多是用于将维度表上的附加信息拼合进数据表中。当然未来通过power pivot建模操作,我们可以不必把所有的维度都拼进数据表中,这些在后面的文章中会有涉及。
关于数据结构设计:
在本例中,我最后又将三个年龄段占比的指标透视到了列上,这是为了在未来讲解dax时做准备,实际上这类分层占比的指标,把年龄分段留在维度项上是更为常用的做法。
反之,如果我们一开始追加到一起的指标是完全不同的指标(譬如是人口和gpd),那么将它们透视到列上之后,做图表以及写公式时则会便利得多。
关于模型设计:
在本例中,我们最终留下了两张数据表,这是为了未来讲解模型时做准备。通常在维度不统一的时候会推荐使用多张数据表,譬如年龄占比数据如果我们不做透视,会比人口总数表多一个年龄分段的维度,这时如果强行拼在一个表里虽然也无大碍,但对新手来说可能会有点不易理解。
在清洗的过程中,因为有编码了,所以我们曾经把国家名称删除掉。不过在实际操作中,其实不推荐把字段删除得太过干净。因为编码毕竟不够直观,假如在报表制作的过程中,偶尔有需要数据核验时,假如还需要先看一下对应国家的编码后,再在数据视图里查找的话,也有点影响效率。
所以正常做报表时,虽然推荐优先用编码列做关联字段,但对比较重要的关键维度字段,还是可以适当保留的。譬如假如原始数据中,除了国家名称、编码外,还有其余的那些区域、收入等级等附加属性列,往往可以把那些列删除。