Android自问自答系列——持续更新ING
Hello,All,我是来自58同城的一名Android开发工程师,在58集团从事APP的开发工作。在日常的工作和学习过程中我经常会碰到一些好玩的和有意思的Android小知识点,有些知识可能都从未注意到过。通过一个多月的收集和整理,我发现通过不断地记录这些问题达到了非常好的复习效果,从而帮助了工作上的持续进步,今天我也是把平时收集到的这些东西发出来供大家一起学习,共同成长,如果感觉好,欢迎点击右侧的留言、点赞、加关注,您的支持是我最大的动力。
PS:关注,私信我,帮你内推58,常年招聘前端,移动端,后端,算法。
也欢迎关注我的公众号,在这里可以找到我,同时,这里会不定期地推送一些时下最热门的技术文章和互联网行业工作心路历程

——于2020年小年夜首发
——2020.2.5日更新
为什么android不允许在子线程中更新UI?
因为Android的UI控件不是线程安全的,采用加锁机制降低了UI访问效率,让UI访问变得复杂,所以最简单的做法就是用单线程模型。
ThreadLocal的使用以及其内部机制
final ThreadLocal
mThreadLocal.set("nameMain");
Log.d(TAG, "onResume: " + mThreadLocal.get());
new Thread(new Runnable() {
@Override
public void run() {
mThreadLocal.set("name1");
mThreadLocal.get();
Log.d(TAG, "run: " + mThreadLocal.get());
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
mThreadLocal.set("name2");
mThreadLocal.get();
Log.d(TAG, "run: " + mThreadLocal.get());
}
}).start();
内部机制:
使用Hashmap来存储数据,使用懒加载策略,将第一个key和value装入Entry中,
为什么使用threadLocal可以缓存不同线程的同一个变量?
在每个线程中都有一个独立的Hashmap副本来存储数据
ThreadLocal是一个线程吗?
不是,他只是提供了一种线程缓存对象的能力。是一个线程内部的数据存储类,使用它可以在指定的线程中存储数据,除了创建线程以外,其他线程无法访问到该线程的数据
Handler的使用及其内部原理?
Handler如何避免内存泄漏?
Message能传递的最大数据量是多少?
MessageQueue底层实现是什么?
单链表
Message的复用原理是什么?
使用了享元模式的单项链表
Url支持最大多少数据量承载
微信朋友圈图片加载怎样防止OOM?
Android消息机制是如何实现主子线程之间通信的?
以一次主线程建立Handler,在子线程sendMessage为例.在主线程建立Handler之后,子线程使用主线程的Handler对象sendMessage方法,最终调用到的是sendMessageAtTime方法,在该方法中又调用了enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis),这里重点关注两个传入参数,queue和msg,queue是在简历Looper的时候创建的,msg就是从应用层发送过来的msg,在这个方法里,又调用了queue的enqueueMessage方法,将msg加入到了queue的消息队列里
MessageQueue使用了什么设计模式?
生产者消费者设计模式
sendMessageDelayed 和sendMessageAtTime有何区别?
URI URN URL都有什么区别?
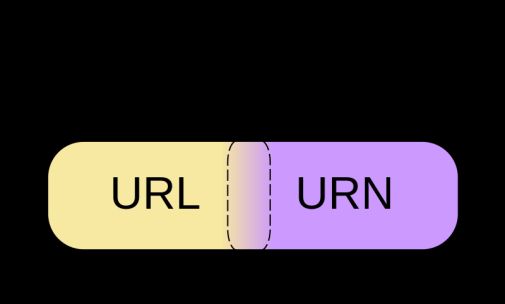
个人的身份证号就是URN,个人的家庭地址就是URL,URN可以唯一标识一个人,而URL可以告诉邮递员怎么把货送到你手里。
URI:universal resource identifier统一资源标识符
URN:universal resources Name统一资源名称
URL:Universal resources Location统一资源定位符
HTTP无状态协议这个概念怎样理解?
HTTP协议自身不对请求和相应之间的通信状态进行保存
无状态的目的是什么?
为了快速处理大量事物,确保协议的可伸缩性
Exception Throwable的区别以及在程序中应该如何去处理?
其实只要是Throwable和其子类都是可以throw和catch的,那么如果在需要统一处理异常的地方,我们应该catch (Throwable th) 还是 catch (Exception)呢?
这两种处理的区别在于,catch throwable会把Error和其他继承Throwable的类捕捉到。而catch Exception只会捕捉Exception极其子类,捕捉的范围更小。先不考虑有其他的类继承了Throwable的情况下,第一种catch相当于比第二种catch多捕捉了把Error和其子类。
那么究竟Error是否需要捕捉呢?JDK中Error类的的注释(如下)里提到过,Error是一种严重的问题,应用程序不应该捕捉它。
An Error is a subclass of Throwable that indicates serious problems that a reasonable application should not try to catch. Most such errors are abnormal conditions. The ThreadDeath error, though a “normal” condition, is also a subclass of Error because most applications should not try to catch it.
A method is not required to declare in its throws clause any subclasses of Error that might be thrown during the execution of the method but not caught, since these errors are abnormal conditions that should never occur.
Java Lanuage Spec 7 中也提到:Error继承自Throwable而不是继承自Exception,是为了方便程序可以使用 “catch (Exception)“来捕捉异常而不会把Error也捕捉在内,因为Exception发生后可以进行一些恢复工作的,但是Error发生后一般是不可恢复的。
The class Error is a separate subclass ofThrowable, distinct from Exception in the class
hierarchy, to allow programs to use the idiom “} catch (Exception e) { ” (§11.2.3)
to catch all exceptions from which recovery may be possible without catching errors from which recovery is typically not possible.
已经不难看出,Java本身设计思路就是希望大家catch Exception就足够了,如果有Error发生,catch了也不会有什么作用。
cookie是放在http报文的哪里?
消息头
Android设计模式:原型模式(深拷贝、浅拷贝)
try...catch和throws的区别
throws:java throws关键字是跟在方法名之后的,一个thrwos后面可以跟至少一个的异常类型,它的作用是:当前方法可能会抛出异常,但是不知道如何处理该异常,就将该异常交由调用这个方法的的上一级使用者处理,如果main方法也不知道如何处理这个异常的时候,就会交由JVM来处理这个异常
当一个方法使用了throws关键字之后,调用这个方法的使用者就应该显式地处理这个异常,要么使用try..catch来处理,要么也使用throws关键字,将异常继续交由上一层使用者处理
throws关键字的使用是有限制的,即子类声明的抛出异常不允许是父类声明抛出异常的父类异常,即如果子类声明抛出Exception,父类就不能声明抛出NullPointerException
try...catch:
出现异常之后立即处理
Integer的取值范围:
-2^32~2^32
java泛型中和有什么区别?
T 代表一种类型
T extends T2 指传的参数为T2或者T2的子类型。
?是通配符,泛指所有类型
? extends T 指T类型或T的子类型
? super T 指T类型或T的父类型
特例:带通配符的List仅表示它是各种泛型List的父类,并不能把元素加入其中,如下将引起编译错误:
List list = new ArrayList
list.add("aaa");
泛型只存在于编译时
Java获得Class对象的三种方式:
Class.forName();(该方法需要传入类的全限定名作为参数,且必须添加完整包名)
类的Class属性
调用对象的getClass属性
java 向上转型 向下转型
1、父类引用指向子类对象,而子类引用不能指向父类对象。
2、把子类对象直接赋给父类引用叫upcasting向上转型,向上转型不用强制转换吗,如:
Father f1 = new Son();3、把指向子类对象的父类引用赋给子类引用叫向下转型(downcasting),要强制转换,如:
f1 就是一个指向子类对象的父类引用。把f1赋给子类引用 s1 即 Son s1 = (Son)f1;
其中 f1 前面的(Son)必须加上,进行强制转换。
使用泛型,有2个好处:
1.不需要做强制类型转换
2.编译时更安全。如果使用Object类的话,你没法保证返回的类型一定是Foo,也许是其它类型。这时你就会在运行时得到一个类型转换异常(ClassCastException)
AOP和OOP区别
AOP的典型语言:AspectJ,他支持Java,是Java的扩展
从Java7开始,允许在构造器后不需要带完整的泛型信息,只需要给出一对尖括号即可。例:ArrayList
Android源码设计模式一书中将责任链设计模式和广播结合起来,通过onReceive和setResultExtras来进行责任链调用,避免了过多类的创建,值得借鉴。
Activity AppCompatActivity FragmentActivity区别
-
Fragmentactivity 继承自activity,用来解决android3.0 之前没有fragment的api,所以在使用的时候需要导入support包,同时继承fragmentActivity,这样在activity中就能嵌入fragment来实现你想要的布局效果
2.AppcompaActivity相对于Activity的主要的两点变化;
1,主界面带有toolbar的标题栏;
2,theme主题只能用android:theme=”@style/AppTheme (appTheme主题或者其子类),而不能用android:style。
3,Activity以上两类的基类
什么是序列化
序列化,表示将一个对象转换成可存储或可传输的状态。序列化后的对象可以在网络上进行传输,也可以存储到本地
Parcelable和Serializable的区别和比较
Parcelable和Serializable都是实现序列化并且都可以用于Intent间传递数据,Serializable是Java的实现方式,可能会频繁的IO操作,所以消耗比较大,但是实现方式简单 Parcelable是Android提供的方式,效率比较高,但是实现起来复杂一些 , 二者的选取规则是:内存序列化上选择Parcelable, 存储到设备或者网络传输上选择Serializable(当然Parcelable也可以但是稍显复杂)
选择序列化方法的原则
1)在使用内存的时候,Parcelable比Serializable性能高,所以推荐使用Parcelable。
2)Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。
3)Parcelable不能使用在要将数据存储在磁盘上的情况,因为Parcelable不能很好的保证数据的持续性在外界有变化的情况下。尽管Serializable效率低点,但此时还是建议使用Serializable 。
Parcelable接口使用:
1.选择序列化方法的原则
1)在使用内存的时候,Parcelable比Serializable性能高,所以推荐使用Parcelable。
2)Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。
3)Parcelable不能使用在要将数据存储在磁盘上的情况,因为Parcelable不能很好的保证
数据的持续性在外界有变化的情况下。尽管Serializable效率低点,但此时还是建议使
用Serializable 。
2.使用场景:
需要在多个部件(Activity或Service)之间通过Intent传递一些数据,简单类型(如:数字、
字符串)的可以直接放入Intent。复杂类型必须实现Parcelable接口。
3.使用Parcelable步骤:
1)implements Parcelable
2)重写writeToParcel方法,将你的对象序列化为一个Parcel对象,即:将类的数据写入
外部提供的Parcel中,打包需要传递的数据到Parcel容器保存,以便从 Parcel容器获取数据
3)重写describeContents方法,内容接口描述,默认返回0就可以
4)实例化静态内部对象CREATOR实现接口Parcelable.Creator
public static final Parcelable.Creator
如何实现关闭多个Activity?
方法一:在每个Activity启动时将实例传给Activity内部持有的一个静态变量,关闭时直接进行关闭
方法二:将Activity注册进List中进行管理,关闭时进行list轮询
创建Java线程一共有几种方式?
-
Thread
-
Runnable
-
线程池
-
Callable
Thread和Runnable,Callable对比:
1.Thread是一个类,Callable,Runnable是接口,接口可以多实现,类只能单继承
2.Callable结合FutureTask实现的方式下,多线程可以实现共享同一个FutureTask对象,适合多个线程处理同一份资源的情况
3.Callable编程稍复杂,在Thread实现下,使用this即可访问当前线程对象,而Callable需要使用Thread.currentThread();
线程在什么情况下会阻塞?
-
调用了线程的sleep方法,但该方法不会放弃锁
-
调用了阻塞式IO方法,在方法返回之前,线程被阻塞
-
线程试图获得同步监视器,但该同步监视器正在被其他线程持有
-
线程正在等待通知
-
调用了线程的suspend方法将线程挂起,但这个方法容易导致死锁。
线程让步(yield):
-
暂停当前正在执行的线程对象,并执行其他线程。
-
意思就是调用yield方法会让当前线程交出CPU权限,让CPU去执行其他的线程。它跟sleep方法类似,同样不会释放锁。
-
但是yield不能立刻交出CPU,会出现同一个线程一直执行的情况,另外,yield方法只能让拥有相同优先级的线程有获取CPU执行时间的机会。
-
注意调用yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态,它只需要等待重新获取CPU执行时间,这一点是和sleep方法不一样的
线程池的核心线程数怎样设置?
CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。
因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,只能增加上下文切换的次数,因此会带来额外的开销。
IO密集型任务
可以使用稍大的线程池,一般为2*CPU核心数。
IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候去处理别的任务,充分利用CPU时间。
线程池的执行策略:
step1.调用ThreadPoolExecutor的execute提交线程,首先检查CorePool,如果CorePool内的线程小于CorePoolSize,新创建线程执行任务。
step2.如果当前CorePool内的线程大于等于CorePoolSize,那么将线程加入到BlockingQueue。
step3.如果不能加入BlockingQueue,在小于MaxPoolSize的情况下创建线程执行任务。
step4.如果线程数大于等于MaxPoolSize,那么执行拒绝策略。
什么是CAS?
使用锁时,线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的时候同时也会阻塞其他线程获取该锁。而CAS操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,既然不会出现冲突自然而然就不会阻塞其他线程的操作。因此,线程就不会出现阻塞停顿的状态。那么,如果出现冲突了怎么办?无锁操作是使用CAS(compare and swap)又叫做比较交换来鉴别线程是否出现冲突,出现冲突就重试当前操作,直到没有冲突为止。
syntronized和CAS区别?
Synchronized VS CAS
元老级的Synchronized(未优化前)最主要的问题是:在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。而CAS并不是武断的间线程挂起,当CAS操作失败后会进行一定的尝试,而非进行耗时的挂起唤醒的操作,因此也叫做非阻塞同步。这是两者主要的区别。
Atomic类的原理是什么呢?
atomic类是通过自旋CAS操作volatile变量实现的。
Java如何创建线程池?
通过实现ThreadPoolExecutor,并向其中设置coreSize,MAX_SIZE,等值来实现线程池的设置,最后调用execute来执行任务。
android版本更新简介:
android 10:
支持折叠屏、5G网络,暗黑模式(AppCompat实现),手势导航,用户隐私设置(用户可以通过新的权限选项更好地控制他们的位置数据;现在,他们可以允许应用仅在实际使用(在前台运行)时访问位置信息。对于大部分应用来说,这提供了足够的访问级别;而对于用户来说,这在确保透明度和控制权方面是一项重大改进。)
外部存储访问权限范围限定为应用文件和媒体。
默认情况下,对于以 Android 10 及更高版本为目标平台的应用,其访问权限范围限定为外部存储,即分区存储。此类应用可以查看外部存储设备内以下类型的文件,无需请求任何与存储相关的用户权限:
特定于应用的目录中的文件(使用getExternalFilesDir()访问)。
应用创建的照片、视频和音频片段(通过媒体库访问)。
Intent传递对象的最大限制是多少?
1MB
为什么是1MB?
Intent内部使用了Binder传输机制,Binder的事务缓冲区限制了传递数据的大小。并且,这1MB大小不是当前操作独享的,而是由整个进程共享的。由于共享的特性,不是传递1MB以下的数据就绝对安全,要视情况而定。对于体积较大的数据,可以从数据源考虑,传递URL等方式,或者先持久化数据再还原,也可以使用EventBus黏性事件来解决。
双检查单例模式(DCL)有没有什么更好的写法?


线程安全单例的枚举实现方式:

View真的不可用在子线程进行更新吗?
不是,View只是不允许在非创建UI的线程中进行更新
Android 窗口的分类

状态机设计模式就是使用一个A类来管理其他状态子类,并在A中根据状态的不同持有其他子类的引用,当操作A的动作时也就是操作最新状态子类的动作
android WindowManagerService ActivityManagerService
android中每个view都有自己的坐标系,都是view左上角作为原点的
Android自定义View:
canvas:绘制view的底板
canvas.drawRect,
drawCircle,
drawLine
,drawOval(画椭圆),
drawPoint,
drawPoints,
drawRoundRect(圆角矩形)
drawArc
drawPath(自定义画笔轨迹)
Paint画笔,可以设置画笔颜色,抗锯齿等参数
Path:自定义轨迹
path.addCircle,
path.addOval,
path.addRect,
path.addRoundRect
path.addPath(添加自定义轨迹)
path.lineTo/rlineTo
path.moveTo(因为默认是从view的左上角开始绘制,可以用这个方法将画笔移动)
path.close(封闭图形)
Path还可以设置辅助填充方式
为什么阿里巴巴开发者手册中强制不允许在Application中缓存变量?
如果在Application中缓存了变量,当App退到后台,但在后台被杀死,重新启动之后Application对象会被重建,导致数据丢失
如何进行布局优化?

NestedScroolView支持嵌套滑动,可以作为一个普通的scrollView来使用
MessageQueue在什么时候被创建?
在Looper.prepareMainLooper时候被创建,在prepareMainLooper中通过ThreadLocal set进去了一个Looper这个Looper是被new出来的,其中,new Looper的过程中就包含了创建MessageQueue的过程,并且得到了当前线程的引用。然后,在Looper.loop中开启了for(;;)循环,开始不断地轮询messageQueue中的消息
享元模式与单例模式的区别?
享元模式可以再次创建对象 也可以取缓存对象
单例模式则是严格控制单个进程中只有一个实例对象
享元模式可以通过自己实现对外部的单例 也可以在需要的使用创建更多的对象
单例模式是自身控制 需要增加不属于该对象本身的逻辑
Android中的进程间通信方式?
Intent,基于Binder的Messenger,AIDL,Socket,ContentProvider,文件共享,数据库。。。
如何在Android中开启多进程?
给四大组件指定android:process属性
Android中一个App(一个进程)被分配的内存大小?
早期版本中,内存最大被限制为16M,且根据设备不同,大小也不一样。
Android设备出厂以后,Java虚拟机对单个应用的内存分配就固定下来了,超出这个值就会OOM。这个属性值定义在 /system/build.prop中
可以通过ActivityManager来查看这个值:
ActivityManager am = (ActivityManager) context.getSystemService(Context.ACTIVITY_SERVICE);
int heapGrowthLimit = am.getMemoryClass(); // 192,以m为单位
在应用开发中,如果要使用大堆,可在manifest文件中指定android:largeHeap为true,这样dalvik的堆内存可以达到heapsize。
为什么Android中每个应用需要单独开Dalvik虚拟机?
android上的应用是带有独立虚拟机的,也就是每开一个应用就会打开一个独立的虚拟机。这样设计的优点就是在单个程序崩溃的情况下不会导致整个系统的崩溃。
Android View中X,Y,translationX,translationY都指的是什么
X,Y是View左上角相对于远点的坐标
而translationX,translationY是在左上角坐标原点可变的情况下的偏移量


TouchSlop是什么?
Android操作系统所能识别的最小滑动距离, 
GestrueDetector(收拾识别),Scroller(弹性滑动)
View实现滑动一共有几种方法?

Android 事件分发机制:
点击事件的三个重要方法:
onTouchEvent,dispatchTouchEvent,onInterceptTouchEvent
点击事件的分发可以用如下的伪代码表示:
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
if (this.interceptTouchEvent){
onTouchEvent(event);
return true;
} else {
child.dispatchTouchEvent();
return false;
}
return super.dispatchTouchEvent(ev);
}
点击事件的传递过程:
Activity——》Window——》顶级View
当一个View设置了onTouchListener,且返回值为true,则代表当前事件被Listener消费,不会传递到View自身的onTouchEvent
如何在activity中获取准确的View宽高?
(1)onWindowFocusChanged
(2)view.post(runnable)
(3) viewTreeObserver的回调方法:onGlobalLayoutListener,onGlobalLayout


LinearLayout RelativeLayout有什么区别?
LinearLayout会onMeasure一次,根据横向和纵向的不同,只measure一次。而RelativeLayout会横向和纵向都measure一次,性能上不如LinearLayout。
onDraw过程是怎样的?

自定义View的分类
drawable的知识点:
获取drawable的宽高:getIntrinsicWidth,getIntrinsicHeight
drawable一般用来实现一些简单的view效果
bitmap与drawable的区别和联系
https://blog.csdn.net/qq1263292336/article/details/78867461
Activity使用反射的方法进行创建,在创建过程中使用了StrictMode
final类和final方法:
1. final类
final类不能被继承,因此final类的成员方法没有机会被覆盖,默认都是final的。在设计类时候,如果这个类不需要有子类,类的实现细节不允许改变,并且确信这个类不会载被扩展,那么就设计为final类。
2. final方法
如果一个类不允许其子类覆盖某个方法(即不允许被子类重写),则可以把这个方法声明为final方法。
使用final方法的原因有二:
-
把方法锁定,防止任何继承类修改它的意义和实现。
-
高效。编译器在遇到调用final方法时候会转入内嵌机制,大大提高执行效率。
官方建议,在activity可见性方面,最好使用onActivityFocusChanged这个回调而不要使用onResume,而onResume最好用于开启摄像机,开启动画等功能。
setContentView都做了什么?
-
检测是否有ViewGroup也就是ViewParent,如果没有,则生成一个,如果有ViewParent则把之前存在的View都移除
-
然后把加载进来的Layout(xml)inflate出来
-
回调onContentChanged
addContentView都做了什么?
-
检测ViewParent(ViewGroup)是否为空?如果为空则install一个
-
调用ViewGroup的addView
LayoutInflator.inflate都做了什么?
最终调用到了addView
addView都做了什么?
先将父布局layout好(requestLayout),然后依次去调用子元素的requestLayout(innerRequestLayout)
Activity的setContentView和addContentView有什么区别?
1. 以添加UI组件是否被移除
setContentView() 会导致先前添加的被移除, 即替换性的;
而 addContentView() 不会移除先前添加的UI组件,即是累积性的
2. 是否控制布局参数
addContentView() 有两个参数, 可以控制布局参数; 你指出的这个setContentView 没有接受布局参数,
默认使用MATCH_PARENT; 不过setContentView()也有带两个参数的版本, 可以控制布局参数。
为什么在子线程中创建Handler时候没有创建Looper会报错?
因为通过new的方式创建Handler的时候会检测是否创建了Looper,因为子线程在创建时默认不创建looper,所以会报错。而主线程在ActivityThread中默认会创建mainLooper
Android pie(28)无法支持HTTPS,APP该如何适配?
方案一:与服务端协商将http改为https
方案二:废弃http接口
方案三:在manifest文件,application中添加属性android:usesCleartextTraffic="true"
从加密解密的角度来解释公钥和私钥在传输过程中的作用?
公钥和私钥就是俗称的不对称加密方式,是从以前的对称加密(使用用户名与密码)方式的提高。非对称密码算法:又称为公钥加密算法,是指加密和解密使用不同的密钥(公开的公钥用于加密,私有的私钥用于解密)。比如A发送,B接收,A想确保消息只有B看到,需要B生成一对公私钥,并拿到B的公钥。于是A用这个公钥加密消息,B收到密文后用自己的与之匹配的私钥解密即可。反过来也可以用私钥加密公钥解密。也就是说对于给定的公钥有且只有与之匹配的私钥可以解密,对于给定的私钥,有且只有与之匹配的公钥可以解密。
android四大启动模式?
standard:标准启动模式,每次开启activity都会创建新实例
singgleTop:栈顶复用模式,如果启动的实例不在栈顶,就创建一个
singgleInstance:单实例模式,启动activity会新建任务栈
singgleTask:栈内复用模式,如果启动栈中有实例,则把其之上的实例都销毁
CA证书是什么?及其在https中的作用和加密原理
CA 是 PKI 系统中通信双方信任的实体,被称为可信第三方(Trusted Third Party,简称TTP)。 CA 证书,顾名思义,就是 CA 颁发的证书。
CA 的初始是为了解决上面非对称加密被劫持的情况,服务器申请 CA 证书时将服务器的“公钥”提供给 CA,CA 使用自己的“私钥”将“服务器的公钥”加密后(即:CA证书)返回给服务器,服务器再将“CA 证书”提供给客户端。一般系统或者浏览器会内置 CA 的根证书(公钥)
客户端获取到“CA 证书”会进行本地验证,即使用本地系统或者浏览器中的公钥进行解密,每个“CA 证书”都会有一个证书编号可用于解密后进行比对
https://blog.csdn.net/freekiteyu/article/details/76423436